spacy streamlit
v1.0.6
이 패키지에는 Spacy 모델을 시각화하고 Streamlit을 사용하여 대화식 스페이시 구동 앱을 구축하는 유틸리티가 포함되어 있습니다. 여기에는 구문 의존성을 위한 시각화기, 이름이 지정된 엔티티 , 텍스트 분류 , 단어 벡터를 통한 시맨틱 유사성 , 토큰 속성 등과 같은 다양한 빌딩 블록이 포함되어 있습니다.
PIP에서 spacy-streamlit 설치할 수 있습니다.
pip install spacy-streamlit 패키지에는 간소화로 호출하고 필요한 모든 요소를 설정하는 빌딩 블록이 포함되어 있습니다. 개별 구성 요소를 직접 사용하여 앱의 다른 요소와 결합하거나 visualize 기능을 호출하여 전체 시각화를 포함 할 수 있습니다.
시작하려면 Spacy의 영어 모델을 다운로드하십시오.
python -m spacy download en_core_web_sm그런 다음 다음 예제 코드를 파일에 넣습니다.
# streamlit_app.py
import spacy_streamlit
models = [ "en_core_web_sm" , "en_core_web_md" ]
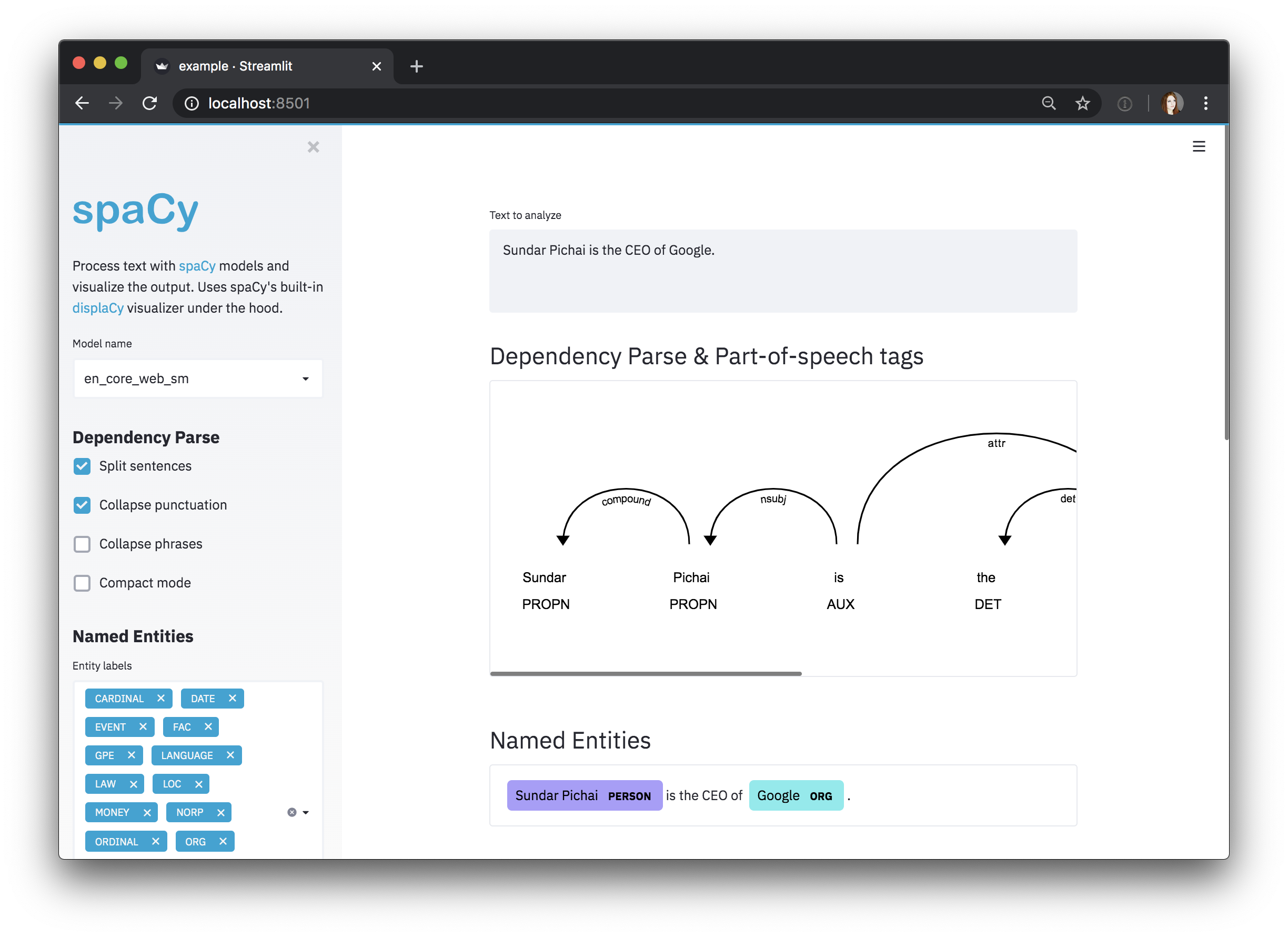
default_text = "Sundar Pichai is the CEO of Google."
spacy_streamlit . visualize ( models , default_text ) 그런 다음 streamlit run streamlit_app.py 로 앱을 실행할 수 있습니다. 앱은 웹 브라우저에서 팝업해야합니다. ?
01_out-of-the-box.py내장 된 시각화를 사용하여 내장 시각화를 사용하십시오.
streamlit run https://raw.githubusercontent.com/explosion/spacy-streamlit/master/examples/01_out-of-the-box.py02_custom.py기존 앱에서 개별 구성 요소를 사용하십시오.
streamlit run https://raw.githubusercontent.com/explosion/spacy-streamlit/master/examples/02_custom.py 이러한 기능은 간단한 앱에서 사용할 수 있습니다. 그들은 후드 아래에서 streamlit 으로 호출하고 필요한 요소를 설정합니다.
visualize선택한 구성 요소로 전체 시각화를 포함시킵니다.
import spacy_streamlit
models = [ "en_core_web_sm" , "/path/to/model" ]
default_text = "Sundar Pichai is the CEO of Google."
visualizers = [ "ner" , "textcat" ]
spacy_streamlit . visualize ( models , default_text , visualizers )| 논쟁 | 유형 | 설명 |
|---|---|---|
models | 목록 [str] / dict [str, str] | 로드 가능한 스파이 모델 (경로 또는 패키지 이름)의 이름. 모델은 드롭 다운을 통해 선택할 수 있습니다. 드롭 다운에 표시하기 위해 이름 목록 또는 설명에 맵핑 된 이름 일 수 있습니다. |
default_text | str | 부하에서 분석 할 기본 텍스트. 기본값으로 "" . |
default_model | 선택적 [str] | 기본 모델의 선택 이름. 설정하지 않으면 models 목록의 첫 번째 모델이 사용됩니다. |
visualizers | List [str] | 표시 할 시각화 이름. ["parser", "ner", "textcat", "similarity", "tokens"] 에 대한 기본값. |
ner_labels | 선택적 [목록 [str]] | 포함 할 NER 라벨. 설정하지 않으면 "ner" 파이프 라인 구성 요소에 존재하는 모든 레이블이 사용됩니다. |
ner_attrs | List [str] | 지명 된 엔티티의 표에 표시된 속성. 기본값은 visualizer.py 참조하십시오. |
token_attrs | List [str] | 토큰 비주얼 라이저에 표시 할 토큰 속성. 기본값은 visualizer.py 참조하십시오. |
similarity_texts | 튜플 [str, str] | 유사성 시각화에서 비교할 기본 텍스트. 기본값으로 ("apple", "orange") . |
show_json_doc | 부 | Doc 의 JSON 표현을 전환하려면 버튼 표시. 기본값은 True . |
show_meta | 부 | 현재 파이프 라인의 meta.json 전환하려면 버튼을 표시하십시오. 기본값은 True . |
show_config | 부 | 현재 파이프 라인의 config.cfg 전환하려면 버튼을 표시하십시오. 기본값은 True . |
show_visualizer_select | 부 | 사이드 바 드롭 다운을 표시하여 표시 할 시각화를 선택하여 활성화 된 시각화를 기반으로합니다. 기본값으로 False . |
sidebar_title | 선택적 [str] | 사이드 바에 표시된 제목입니다. 기본값은 None . |
sidebar_description | 선택적 [str] | 설명 사이드 바에 표시됩니다. Markdown 형식 텍스트를 허용합니다. |
show_logo | 부 | 사이드 바에 스파크 로고를 표시하십시오. 기본값은 True . |
color | 선택적 [str] | 실험 : 일부 주요 UI 요소에 사용할 기본 색상 (해킹을 비활성화 할 None ). "#09A3D5" 로 기본값. |
get_default_text | Callable [[언어], str] | 현재로드 된 nlp 객체를 가져 와서 기본 텍스트를 반환하는 선택적 호출 가능. 언어 별 기본 텍스트를 제공하는 데 사용할 수 있습니다. 함수가 None 반환하면 default_text 의 값이 사용됩니다. 기본값은 None . |
visualize_parser Spacy의 displacy Visualizer를 사용하여 종속성 구문 분석 및 부분-연설 태그를 시각화하십시오.
import spacy
from spacy_streamlit import visualize_parser
nlp = spacy . load ( "en_core_web_sm" )
doc = nlp ( "This is a text" )
visualize_parser ( doc )| 논쟁 | 유형 | 설명 |
|---|---|---|
doc | Doc | Spacy Doc 객체는 시각화합니다. |
| 키워드 전용 | ||
title | 선택적 [str] | Visualizer 블록의 제목. |
key | 선택적 [str] | 레이블을 선택하기 위해 간단한 구성 요소에 사용되는 키입니다. |
manual | 부 | DOC 인수가 DOC 객체인지 또는 구문 분석 정보가 포함 된 접시 목록인지를 나타내는 플래그. |
displacy_options | 선택적 [dict] | HTML을 생성하기위한 옵션 렌더 메소드로 전달되는 옵션의 사전. 참조 : https://spacy.io/api/top-level#options-dep을 참조하십시오 |
visualize_ner Spacy의 displacy Visualizer를 사용하여 Doc 의 명명 된 엔티티를 시각화하십시오.
import spacy
from spacy_streamlit import visualize_ner
nlp = spacy . load ( "en_core_web_sm" )
doc = nlp ( "Sundar Pichai is the CEO of Google." )
visualize_ner ( doc , labels = nlp . get_pipe ( "ner" ). labels )| 논쟁 | 유형 | 설명 |
|---|---|---|
doc | Doc | Spacy Doc 객체는 시각화합니다. |
| 키워드 전용 | ||
labels | 시퀀스 [str] | 레이블 드롭 다운에 표시되는 레이블. |
attrs | List [str] | 엔티티 테이블에 표시 할 스팬 속성. |
show_table | 부 | 엔티티 테이블과 그 속성을 보여줄지 여부. 기본값은 True . |
title | 선택적 [str] | Visualizer 블록의 제목. |
colors | dict [str, str] | 엔티티의 색상 사전은 키를 레이블로, 해당 색상으로 값으로 시각화하기 위해 사용됩니다. 이 주장은 곧 더 이상 사용되지 않을 것입니다. 미래에 Colors Arg는 "색상"의 displacy_options arg arg에 전달되어야합니다.) |
key | 선택적 [str] | 레이블을 선택하기 위해 간단한 구성 요소에 사용되는 키입니다. |
manual | 부 | DOC 인수가 DOC 객체인지 또는 엔티티 스팬을 포함하는 접시 목록인지를 나타내는 플래그 |
| 정보. | ||
displacy_options | 선택적 [dict] | HTML을 생성하기위한 옵션 렌더 메소드로 전달되는 옵션의 사전. https://spacy.io/api/top-level#displacy_options-ent를 참조하십시오. |
visualize_spans Spacy의 displacy Visualizer를 사용하여 Doc 의 스팬을 시각화하십시오.
import spacy
from spacy_streamlit import visualize_spans
nlp = spacy . load ( "en_core_web_sm" )
doc = nlp ( "Sundar Pichai is the CEO of Google." )
span = doc [ 4 : 7 ] # CEO of Google
span . label_ = "CEO"
doc . spans [ "job_role" ] = [ span ]
visualize_spans ( doc , spans_key = "job_role" , displacy_options = { "colors" : { "CEO" : "#09a3d5" }})| 논쟁 | 유형 | 설명 |
|---|---|---|
doc | Doc | Spacy Doc 객체는 시각화합니다. |
| 키워드 전용 | ||
spans_key | 시퀀스 [str] | 스파를 렌더링하는 키가 있습니다. 기본값은 "SC"입니다. |
attrs | List [str] | 엔티티의 속성은 레이블이 붙어 있습니다. 속성은 show_table 인수가 참일 때만 표시됩니다. |
show_table | 부 | 스팬 테이블과 그 속성을 보여줄지 여부. 기본값은 True . |
title | 선택적 [str] | Visualizer 블록의 제목. |
manual | 부 | DOC 인수가 DOC 객체인지 또는 엔티티 스팬 정보를 포함하는 접시 목록인지를 나타내는 플래그. |
displacy_options | 선택적 [dict] | HTML을 생성하기위한 옵션 렌더 메소드로 전달되는 옵션의 사전. https://spacy.io/api/top-level#displacy_options-span을 참조하십시오. |
visualize_textcat훈련 된 텍스트 분류기에 의해 예측 된 텍스트 범주를 시각화합니다.
import spacy
from spacy_streamlit import visualize_textcat
nlp = spacy . load ( "./my_textcat_model" )
doc = nlp ( "This is a text about a topic" )
visualize_textcat ( doc )| 논쟁 | 유형 | 설명 |
|---|---|---|
doc | Doc | Spacy Doc 객체는 시각화합니다. |
| 키워드 전용 | ||
title | 선택적 [str] | Visualizer 블록의 제목. |
visualize_similarity모델의 단어 벡터를 사용하여 시맨틱 유사성을 시각화합니다. 모델에 벡터가없는 경우 경고가 표시됩니다.
import spacy
from spacy_streamlit import visualize_similarity
nlp = spacy . load ( "en_core_web_lg" )
visualize_similarity ( nlp , ( "pizza" , "fries" ))| 논쟁 | 유형 | 설명 |
|---|---|---|
nlp | Language | 벡터가있는로드 된 nlp 객체. |
default_texts | 튜플 [str, str] | 부하에서 비교할 기본 텍스트. 기본값으로 ("apple", "orange") . |
| 키워드 전용 | ||
threshold | 뜨다 | "유사한"것으로 간주되는 임계 값. 유사성 점수가 임계 값보다 크면 결과가 유사하게 표시됩니다. 기본값은 0.5 입니다. |
title | 선택적 [str] | Visualizer 블록의 제목. |
visualize_tokens Doc 와 그 속성에서 토큰을 시각화하십시오.
import spacy
from spacy_streamlit import visualize_tokens
nlp = spacy . load ( "en_core_web_sm" )
doc = nlp ( "This is a text" )
visualize_tokens ( doc , attrs = [ "text" , "pos_" , "dep_" , "ent_type_" ])| 논쟁 | 유형 | 설명 |
|---|---|---|
doc | Doc | Spacy Doc 객체는 시각화합니다. |
| 키워드 전용 | ||
attrs | List [str] | 사용할 토큰 속성의 이름. 기본값은 visualizer.py 참조하십시오. |
title | 선택적 [str] | Visualizer 블록의 제목. |
이 도우미는로드 된 모델을 캐시하려고 시도하고 Doc 객체를 생성했습니다.
process_text 주어진 이름의 모델로 텍스트를 처리하고 Doc 객체를 만듭니다. 모델을로드하기 위해 load_model 도우미로 호출됩니다.
import streamlit as st
from spacy_streamlit import process_text
spacy_model = st . sidebar . selectbox ( "Model name" , [ "en_core_web_sm" , "en_core_web_md" ])
text = st . text_area ( "Text to analyze" , "This is a text" )
doc = process_text ( spacy_model , text )| 논쟁 | 유형 | 설명 |
|---|---|---|
model_name | str | 로드 가능한 스파크 모델 이름. 경로 또는 패키지 이름 일 수 있습니다. |
text | str | 처리 할 텍스트. |
| 보고 | Doc | 처리 된 문서. |
load_model 경로 또는 설치된 패키지에서 스파이 모델을로드하고로드 된 nlp 객체를 반환하십시오.
import streamlit as st
from spacy_streamlit import load_model
spacy_model = st . sidebar . selectbox ( "Model name" , [ "en_core_web_sm" , "en_core_web_md" ])
nlp = load_model ( spacy_model )| 논쟁 | 유형 | 설명 |
|---|---|---|
name | str | 로드 가능한 스파크 모델 이름. 경로 또는 패키지 이름 일 수 있습니다. |
| 보고 | Language | 로드 된 nlp 객체. |


