spacy streamlit
v1.0.6
このパッケージには、スペイシーモデルを視覚化し、インタラクティブなスペイシー駆動のアプリを流れるためのユーティリティが含まれています。これには、構文依存関係の視覚化装置、名前付きエンティティ、テキスト分類、単語ベクトルによるセマンティックな類似性、トークン属性など、独自の流線アプリで使用できるさまざまなビルディングブロックが含まれています。
PIPからspacy-streamlitをインストールできます。
pip install spacy-streamlitこのパッケージには、Streamlitを呼び出して必要なすべての要素をセットアップするビルディングブロックが含まれています。個々のコンポーネントを直接使用して、アプリ内の他の要素と組み合わせるか、 visualize機能全体を埋め込んで視覚化機能を呼び出すことができます。
Spacyから英語モデルをダウンロードして開始します。
python -m spacy download en_core_web_sm次に、次の例をファイルに配置します。
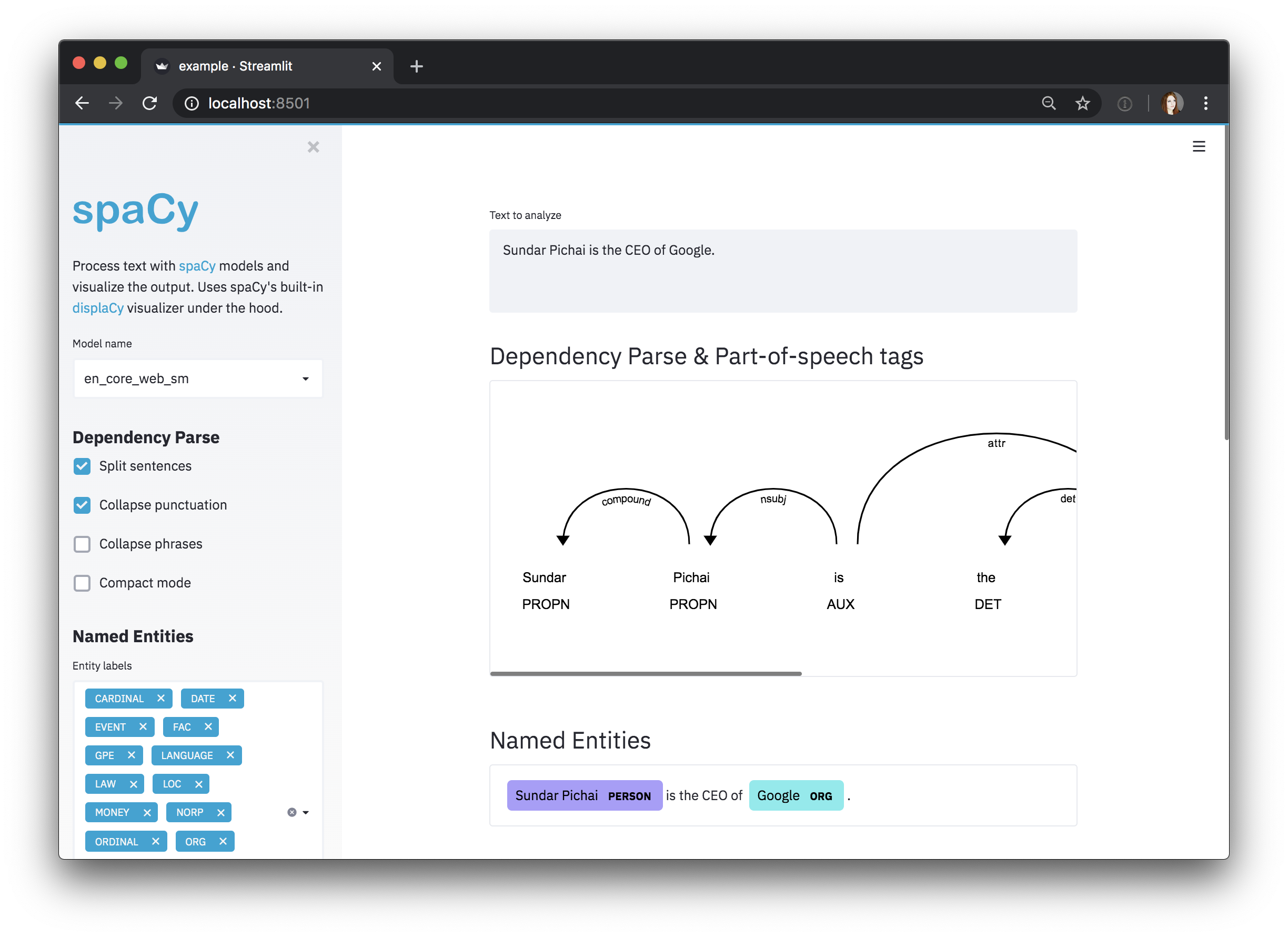
# streamlit_app.py
import spacy_streamlit
models = [ "en_core_web_sm" , "en_core_web_md" ]
default_text = "Sundar Pichai is the CEO of Google."
spacy_streamlit . visualize ( models , default_text )その後、 streamlit run streamlit_app.pyでアプリを実行できます。アプリはWebブラウザにポップアップする必要があります。 ?
01_out-of-the-box.pyすぐにカスタム設定を使用して組み込みのVisualizerを使用します。
streamlit run https://raw.githubusercontent.com/explosion/spacy-streamlit/master/examples/01_out-of-the-box.py02_custom.py既存のアプリで個々のコンポーネントを使用します。
streamlit run https://raw.githubusercontent.com/explosion/spacy-streamlit/master/examples/02_custom.pyこれらの機能は、retrylidアプリで使用できます。彼らはボンネットの下にstreamlitに照らして呼び出し、必要な要素をセットアップします。
visualize選択したコンポーネントを備えた完全なVisualizerを埋め込みます。
import spacy_streamlit
models = [ "en_core_web_sm" , "/path/to/model" ]
default_text = "Sundar Pichai is the CEO of Google."
visualizers = [ "ner" , "textcat" ]
spacy_streamlit . visualize ( models , default_text , visualizers )| 口論 | タイプ | 説明 |
|---|---|---|
models | リスト[str] / dict [str、str] | ロード可能なスペイシーモデル(パスまたはパッケージ名)の名前。モデルはドロップダウンを介して選択可能になります。ドロップダウンで表示する説明にマッピングされた名前のリストまたは名前のいずれかにすることができます。 |
default_text | str | ロードで分析するデフォルトのテキスト。デフォルトは""になります。 |
default_model | オプション[str] | デフォルトモデルのオプション名。設定されていない場合、 modelsのリストの最初のモデルが使用されます。 |
visualizers | リスト[str] | 表示する視覚化装置の名前。デフォルトは["parser", "ner", "textcat", "similarity", "tokens"]になります。 |
ner_labels | オプション[list [str]] | 含めるNERラベル。設定されていない場合、 "ner"パイプラインコンポーネントに存在するすべてのラベルが使用されます。 |
ner_attrs | リスト[str] | 名前付きエンティティの表に示されているスパン属性。デフォルトについては、 visualizer.py参照してください。 |
token_attrs | リスト[str] | トークンビジュアライザーに表示するトークン属性。デフォルトについては、 visualizer.py参照してください。 |
similarity_texts | タプル[str、str] | 類似性Visualizerで比較するデフォルトのテキスト。デフォルトは("apple", "orange")になります。 |
show_json_doc | ブール | [ DocのJSON表現を切り替える]ボタンを表示します。デフォルトはTrueです。 |
show_meta | ブール | 現在のパイプラインのmeta.jsonを切り替えるボタンを表示します。デフォルトはTrueです。 |
show_config | ブール | 現在のパイプラインのconfig.cfg切り替えるボタンを表示します。デフォルトはTrueです。 |
show_visualizer_select | ブール | サイドバードロップダウンを表示して、表示する視覚化装置を選択します(有効なビジュアライザーに基づいて)。デフォルトはFalseになります。 |
sidebar_title | オプション[str] | サイドバーに表示されているタイトル。デフォルトはNone 。 |
sidebar_description | オプション[str] | サイドバーに表示されている説明。 Markdown-formattedテキストを受け入れます。 |
show_logo | ブール | サイドバーにスペイシーロゴを表示します。デフォルトはTrueです。 |
color | オプション[str] | 実験:主要なUI要素の一部に使用する一次色(ハックを無効にするものはNone )。デフォルトは"#09A3D5"になります。 |
get_default_text | 呼び出す[[言語]、str] | 現在ロードされているnlpオブジェクトを取得し、デフォルトのテキストを返すオプションの呼び出し可能。言語固有のデフォルトテキストを提供するために使用できます。関数None返される場合、利用可能な場合はdefault_textの値が使用されます。デフォルトはNone 。 |
visualize_parser Spacy's displacy Visualizerを使用して、依存関係の分割と一部のスピーチタグを視覚化します。
import spacy
from spacy_streamlit import visualize_parser
nlp = spacy . load ( "en_core_web_sm" )
doc = nlp ( "This is a text" )
visualize_parser ( doc )| 口論 | タイプ | 説明 |
|---|---|---|
doc | Doc | 視覚化するスペイシーDocオブジェクト。 |
| キーワードのみ | ||
title | オプション[str] | ビジュアライザーブロックのタイトル。 |
key | オプション[str] | ラベルを選択するためのretrylitコンポーネントに使用されるキー。 |
manual | ブール | ドキュメント引数がDOCオブジェクトであるか、解析情報を含むDICTのリストであるかを示すフラグ。 |
displacy_options | オプション[dict] | オプションの辞書は、レンダリングされるHTMLを生成するためのディスプレイレンダリング方法に渡されます。参照:https://spacy.io/api/top-level#options-dep |
visualize_ner Spacy's displacy Visualizerを使用して、 Doc内の指名されたエンティティを視覚化します。
import spacy
from spacy_streamlit import visualize_ner
nlp = spacy . load ( "en_core_web_sm" )
doc = nlp ( "Sundar Pichai is the CEO of Google." )
visualize_ner ( doc , labels = nlp . get_pipe ( "ner" ). labels )| 口論 | タイプ | 説明 |
|---|---|---|
doc | Doc | 視覚化するスペイシーDocオブジェクト。 |
| キーワードのみ | ||
labels | シーケンス[str] | ラベルのドロップダウンで表示するラベル。 |
attrs | リスト[str] | エンティティテーブルに表示するスパン属性。 |
show_table | ブール | エンティティとその属性のテーブルを表示するかどうか。デフォルトはTrueです。 |
title | オプション[str] | ビジュアライザーブロックのタイトル。 |
colors | dict [str、str] | エンティティの色の辞書は、視覚化に及び、キーはラベルとして、対応する色を値として使用します。この議論はまもなく廃止されます。将来的には、キー「色」とともにdisplacy_options argで渡す必要があります。 |
key | オプション[str] | ラベルを選択するためのretrylitコンポーネントに使用されるキー。 |
manual | ブール | doc引数がdocオブジェクトであるか、エンティティスパンを含むdictsのリストであるかを示すフラグ |
| 情報。 | ||
displacy_options | オプション[dict] | オプションの辞書は、レンダリングされるHTMLを生成するためのディスプレイレンダリング方法に渡されます。 https://spacy.io/api/top-level#displacy_options-entを参照してください。 |
visualize_spans Spacy's displacy Visualizerを使用して、 Docのスパンを視覚化します。
import spacy
from spacy_streamlit import visualize_spans
nlp = spacy . load ( "en_core_web_sm" )
doc = nlp ( "Sundar Pichai is the CEO of Google." )
span = doc [ 4 : 7 ] # CEO of Google
span . label_ = "CEO"
doc . spans [ "job_role" ] = [ span ]
visualize_spans ( doc , spans_key = "job_role" , displacy_options = { "colors" : { "CEO" : "#09a3d5" }})| 口論 | タイプ | 説明 |
|---|---|---|
doc | Doc | 視覚化するスペイシーDocオブジェクト。 |
| キーワードのみ | ||
spans_key | シーケンス[str] | キーにスパンするためにスパンをレンダリングします。デフォルトは「SC」です。 |
attrs | リスト[str] | エンティティの属性には、ラベルが付いています。属性は、 show_table引数がtrueの場合にのみ表示されます。 |
show_table | ブール | スパンのテーブルとその属性を表示するかどうか。デフォルトはTrueです。 |
title | オプション[str] | ビジュアライザーブロックのタイトル。 |
manual | ブール | DOC引数がDOCオブジェクトであるか、エンティティを含むDICTのリストが情報に及ぶかどうかを示すフラグ。 |
displacy_options | オプション[dict] | オプションの辞書は、レンダリングされるHTMLを生成するためのディスプレイレンダリング方法に渡されます。 https://spacy.io/api/top-level#displacy_options-spanを参照してください。 |
visualize_textcat訓練されたテキスト分類子によって予測されるテキストカテゴリを視覚化します。
import spacy
from spacy_streamlit import visualize_textcat
nlp = spacy . load ( "./my_textcat_model" )
doc = nlp ( "This is a text about a topic" )
visualize_textcat ( doc )| 口論 | タイプ | 説明 |
|---|---|---|
doc | Doc | 視覚化するスペイシーDocオブジェクト。 |
| キーワードのみ | ||
title | オプション[str] | ビジュアライザーブロックのタイトル。 |
visualize_similarityモデルの単語ベクトルを使用して、セマンティックの類似性を視覚化します。モデルにベクトルが存在しない場合、警告が表示されます。
import spacy
from spacy_streamlit import visualize_similarity
nlp = spacy . load ( "en_core_web_lg" )
visualize_similarity ( nlp , ( "pizza" , "fries" ))| 口論 | タイプ | 説明 |
|---|---|---|
nlp | Language | ベクトル付きのロードされたnlpオブジェクト。 |
default_texts | タプル[str、str] | 負荷で比較するデフォルトのテキスト。デフォルトは("apple", "orange")になります。 |
| キーワードのみ | ||
threshold | フロート | 「同様」と見なされるもののしきい値。類似性スコアがしきい値よりも大きい場合、結果は類似しています。デフォルトは0.5です。 |
title | オプション[str] | ビジュアライザーブロックのタイトル。 |
visualize_tokens Docとその属性のトークンを視覚化します。
import spacy
from spacy_streamlit import visualize_tokens
nlp = spacy . load ( "en_core_web_sm" )
doc = nlp ( "This is a text" )
visualize_tokens ( doc , attrs = [ "text" , "pos_" , "dep_" , "ent_type_" ])| 口論 | タイプ | 説明 |
|---|---|---|
doc | Doc | 視覚化するスペイシーDocオブジェクト。 |
| キーワードのみ | ||
attrs | リスト[str] | 使用するトークン属性の名前。デフォルトについては、 visualizer.py参照してください。 |
title | オプション[str] | ビジュアライザーブロックのタイトル。 |
これらのヘルパーは、ロードされたモデルをキャッシュし、 Docオブジェクトを作成しようとします。
process_text特定の名前のモデルを使用してテキストを処理し、 Docオブジェクトを作成します。 load_modelヘルパーを呼び出してモデルをロードします。
import streamlit as st
from spacy_streamlit import process_text
spacy_model = st . sidebar . selectbox ( "Model name" , [ "en_core_web_sm" , "en_core_web_md" ])
text = st . text_area ( "Text to analyze" , "This is a text" )
doc = process_text ( spacy_model , text )| 口論 | タイプ | 説明 |
|---|---|---|
model_name | str | ロード可能なスペイシーモデル名。パスまたはパッケージ名にすることができます。 |
text | str | 処理するテキスト。 |
| 返品 | Doc | 処理されたドキュメント。 |
load_modelパスまたはインストールされたパッケージからスペイシーモデルをロードし、ロードされたnlpオブジェクトを返します。
import streamlit as st
from spacy_streamlit import load_model
spacy_model = st . sidebar . selectbox ( "Model name" , [ "en_core_web_sm" , "en_core_web_md" ])
nlp = load_model ( spacy_model )| 口論 | タイプ | 説明 |
|---|---|---|
name | str | ロード可能なスペイシーモデル名。パスまたはパッケージ名にすることができます。 |
| 返品 | Language | ロードされたnlpオブジェクト。 |


