star shaped
1.0.0
repo นี้มีการใช้งาน Pytorch อย่างเป็นทางการสำหรับรูปแบบความน่าจะเป็นแบบ denoising denoising รูปแบบดาวกระดาษ-วิธีการสร้างแบบจำลองการแพร่กระจายแบบเกาส์เซียนที่ใช้บังคับกับท่อร่วมที่ไม่ใช่ Euclidean ต่างๆ
โดย Andrey Okhotin*, Dmitry Molchanov*, Vladimir Arkhipkin, Grigory Bartosh, Viktor Ohanesian, Aibek Alanov, Dmitry Vetrov
ผู้ช่วย: Sergei Kholkin
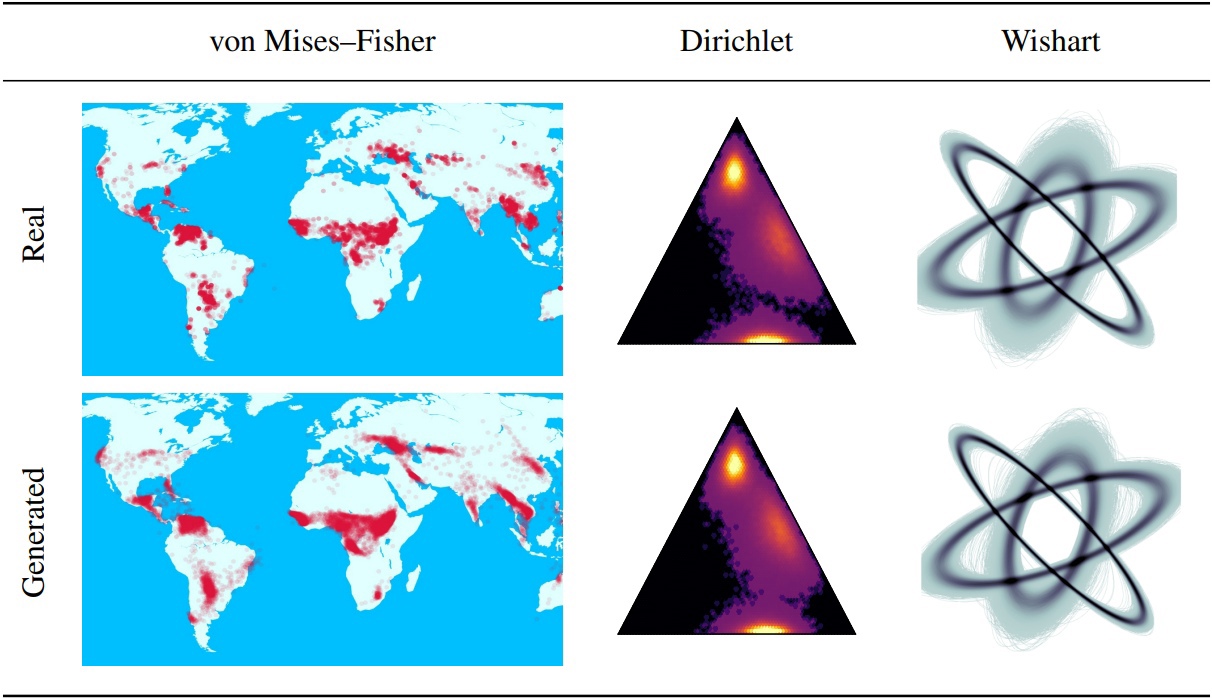
Denoising Diffusion Probabilistic Model (DDPMS) เป็นรากฐานสำหรับการพัฒนาล่าสุดในการสร้างแบบจำลองการกำเนิด โครงสร้าง Markovian ของพวกเขาทำให้ยากที่จะกำหนด DDPMS ด้วยการแจกแจงนอกเหนือจากเกาส์เซียนหรือไม่ต่อเนื่อง ในบทความนี้เราแนะนำ DDPM รูปดาว (SS-DDPM) กระบวนการแพร่กระจายรูปดาวช่วยให้เราสามารถข้ามความจำเป็นในการกำหนดความน่าจะเป็นในการเปลี่ยนผ่านหรือคำนวณโปสเตอร์ เราสร้างความเป็นคู่ระหว่างการแพร่กระจายของ Markovian รูปดาวและเฉพาะสำหรับตระกูลเอ็กซ์โปเนนเชียลของการแจกแจงและอัลกอริทึมที่มีประสิทธิภาพสำหรับการฝึกอบรมและการสุ่มตัวอย่างจาก SS-DDPMS ในกรณีของการแจกแจงแบบเกาส์เซียน SS-DDPM เทียบเท่ากับ DDPM อย่างไรก็ตาม SS-DDPMS ให้สูตรง่ายๆสำหรับการออกแบบแบบจำลองการแพร่กระจายด้วยการแจกแจงเช่นเบต้า, von Mises-Fisher, Dirichlet, Wishart และอื่น ๆ ซึ่งมีประโยชน์อย่างยิ่งเมื่อข้อมูลอยู่บนท่อร่วม เราประเมินโมเดลในการตั้งค่าที่แตกต่างกันและค้นหาว่ามันมีการแข่งขันแม้ในข้อมูลภาพที่ Beta SS-DDPM ได้ผลลัพธ์ที่เทียบเท่ากับ Gaussian DDPM
ตรรกะ SS-DDPM หลักที่อธิบายไว้ในไดเรกทอรี "LIB/DIAPLIAGE" อาจเพียงพอถ้าคุณต้องการ
นอกจากนี้คุณยังสามารถค้นหาตัวอย่างของการใช้ SS-DDPM บนข้อมูลทางภูมิศาสตร์และข้อมูลสังเคราะห์ในไดเรกทอรี "โน้ตบุ๊ก" หากคุณต้องการทำซ้ำผลลัพธ์ของเราคุณสามารถค้นหาตัวอย่างของคำสั่งการประหารชีวิตสำหรับการทดลองเกี่ยวกับ CIFAR10 และ TEXT8
โครงสร้าง repo:
repo นี้ทดสอบด้วยไฟฉาย == 1.12.0+CU113 Torchvision == 0.13.0+CU113
git clone https://github.com/andrey-okhotin/star-shaped
cd star-shaped
pip install -r requirements.txt
# only if you don't have pytorch or your pytorch version < 1.11
pip install torch==1.12.0+cu113 torchvision==0.13.0+cu113 --extra-index-url https://download.pytorch.org/whl/cu113
# only for experiments with synthetic data, otherwise you can just comment all 'import npeet'
git clone https://github.com/gregversteeg/NPEET.git && cd NPEET && pip install . && cd ../ && rm -rf NPEETการดาวน์โหลดโฟลเดอร์เนื้อหาของ ชุดข้อมูล - จำเป็นสำหรับท่อทั้งหมด คำสั่งนี้อาจใช้เวลาประมาณ 5 นาที
pip install py7zr gdown
rm -rf star-shaped/datasets
gdown --fuzzy https://drive.google.com/file/d/1ndXOmbNXR6pwoJ5qs1gVP0eAKU_RAl6E/view ? usp=sharing
py7zr x datasets.7z && rm datasets.7z && mv datasets star-shaped/datasetsการดาวน์โหลดเนื้อหาของโฟลเดอร์ pretrained_models - ไม่จำเป็นสำหรับการฝึกอบรมท่อ คำสั่งนี้อาจใช้เวลาประมาณ 3 นาที
pip install py7zr gdown
rm -rf star-shaped/pretrained_models
gdown --fuzzy https://drive.google.com/file/d/1Lebmsti31CwOFg4LYJYlWmlS7rGYQfVi/view ? usp=sharing
py7zr x pretrained_models.7z && rm pretrained_models.7z && mv pretrained_models star-shaped/pretrained_modelsพร้อมใช้งานสำหรับการรันจาก Jupyter-Notebook ในไดเรกทอรี SS_DDPM/Notebooks คุณสามารถค้นหาตัวอย่างของการฝึกอบรมและการสุ่มตัวอย่างได้
พร้อมใช้งานสำหรับการรันจาก Bash in Directory SS_DDPM
คำสั่งเรียกใช้:
python lib/run_pipeline -gpu < gpu0_idx > _ < gpu1_idx > _ < gpu2_idx > -pipeline < pipeline_name > -logs_file < name_of_txt_file_to_write_execution_info > -port < available_port_for_processes_sync > . . . " other_pipeline_arguments "ตัวอย่างการใช้งานสั้น ๆ สำหรับการทำงานบน 3 GPUs บนโหนดเดียว:
python lib/run_pipeline -gpu 0_1_2 -pipeline train_cifar10 -logs_file logs_train_cifar10.txt -port 8890 . . . " other_pipeline_arguments " การฝึกอบรมเบต้า SS-DDPM ใน 4 NVIDIA V100 (ต้องการหน่วยความจำ GPU 32GB) จุดตรวจจะถูกบันทึกในไดเรกทอรี "จุดตรวจ/Train_Beta_SS_CIFAR10" กราฟิกการสูญเสียจะถูกบันทึกไว้ในไดเรกทอรี "ผลลัพธ์/train_beta_ss_cifar10"
python lib/run_pipeline.py -gpu 0_1_2_3 -port 8900 -pipeline training_cifar10 -diffusion beta_ss -loss KL_rescaled -save_folder train_beta_ss_cifar10 -logs_file logs_training_beta_ss_cifar10.txt
cp checkpoints/training_beta_ss_cifar10/NCSNpp_episode0_epoch1050_model.pt pretrained_models/ncsnpp-cifar10_beta-ss.ptการสุ่มตัวอย่างเบต้า SS-DDPM ใน 2 NVIDIA V100 ผลลัพธ์จะถูกบันทึกในไดเรกทอรี "ผลลัพธ์/sampling_beta_ss_cifar10/generated_samples"
python lib/run_pipeline.py -gpu 0_1 -port 8900 -pipeline sampling_cifar10 -diffusion beta_ss -num_sampling_steps 1000 -pretrained_model ncsnpp-cifar10_beta-ss.pt -num_samples 50000 -save_folder sampling_beta_ss_cifar10 -logs_file logs_sampling_beta_ss.txt
python -m pytorch_fid datasets/FID_cifar10_pack50000 results/sampling_beta_ss_cifar10/generated_samplesหากคุณรันคำสั่งเดียวกันคุณจะได้รับ fid ~ 3.24
การฝึกอบรมหมวดหมู่ SS-DDPM ใน 4 NVIDIA A100 (ต้องการหน่วยความจำ GPU ~ 150GB) จุดตรวจจะถูกบันทึกในไดเรกทอรี "จุดตรวจ/การฝึกอบรม _categorical_ss_text8" กราฟิกการสูญเสียจะถูกบันทึกไว้ในไดเรกทอรี "ผลลัพธ์/การฝึกอบรม _categorical_ss_text8"
python lib/run_pipeline.py -gpu 0_1_2_3 -port 8900 -pipeline training_text8 -diffusion categorical_ss -loss KL -save_folder training_categorical_ss_text8 -logs_file logs_training_categorical_ss.txt
cp checkpoints/training_categorical_ss_text8/T5Encoder_episode0_epoch2016_model.pt pretrained_models/t5base-text8_categorical-ss_fully-trained.ptการประมาณ NLL ใน SS-DDPM หมวดหมู่ใน 3 NVIDIA A100 ผลลัพธ์จะถูกบันทึกไว้ในไดเรกทอรี "ผลลัพธ์/nll_estimations"
python lib/run_pipeline.py -gpu 0_1_2 -port 8900 -pipeline estimating_nll_text8 -diffusion categorical_ss -pretrained_model t5base-text8_categorical-ss_fully-trained.pt -num_samples -1 -batch_size 1536 -dataset_part test -num_iwae_trajectories 1 -save_folder nll_text8_categorical-ss -logs_file logs_nll_text8_categorical_ss.txtหากคุณรันคำสั่งเดียวกันคุณจะได้รับ NLL ~ 1.61
@ inproceedings { okhotin2023star ,
author = { Andrey Okhotin , Dmitry Molchanov , Vladimir Arkhipkin , Grigory Bartosh , Viktor Ohanesian , Aibek Alanov and Dmitry Vetrov },
title = { Star - Shaped Denoising Diffusion Probabilistic Models },
booktitle = { Advances in Neural Information Processing Systems },
volume = { 36 },
year = { 2023 }
}

