star shaped
1.0.0
Ce repo contient la mise en œuvre officielle de Pytorch pour les modèles probabilistes de diffusion en forme d'étoile en forme d'étoile - approche pour créer des modèles de diffusion non gaussiens applicables à divers collecteurs non euclidiens.
Par Andrey Okhotin *, Dmitry Molchanov *, Vladimir Arkhipkin, Grigory Bartosh, Viktor Ohanesian, Aibek Alanov, Dmitry Vetrov
Assistant: Sergei Kholkin
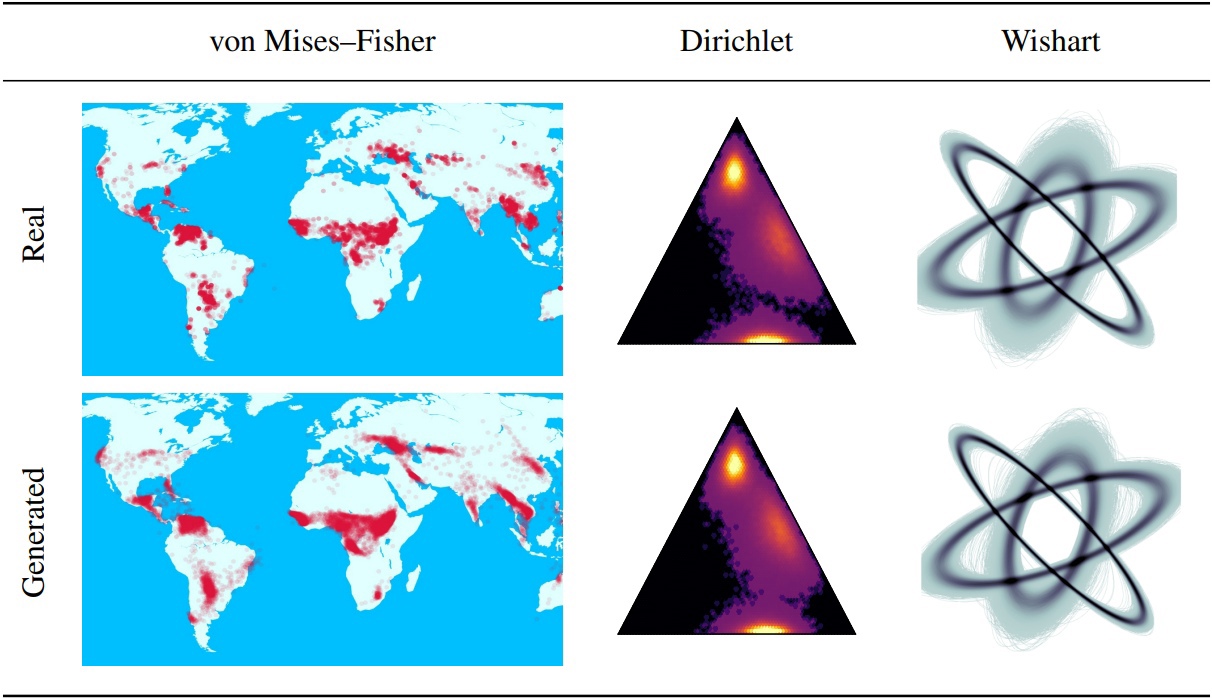
Les modèles probabilistes de diffusion de débrail (DDPMS) fournissent la base des récentes percées dans la modélisation générative. Leur structure markovienne rend difficile la définition du DDPMS avec des distributions autres que gaussiennes ou discrètes. Dans cet article, nous introduisons le DDPM en forme d'étoile (SS-DDPM). Son processus de diffusion en forme d'étoile nous permet de contourner la nécessité de définir les probabilités de transition ou de calculer les postérieurs. Nous établissons la dualité entre les diffusions markoviennes en forme d'étoile et spécifiques pour la famille exponentielle des distributions, et dérivons des algorithmes efficaces pour la formation et l'échantillonnage à partir de SS-DDPMS. Dans le cas des distributions gaussiennes, SS-DDPM équivaut à DDPM. Cependant, les SS-DDPMS fournissent une recette simple pour la conception de modèles de diffusion avec des distributions telles que la bêta, le von Mises - Fisher, Dirichlet, Wishart et autres, ce qui peut être particulièrement utile lorsque les données se trouvent sur un collecteur contraint. Nous évaluons le modèle dans différents paramètres et le trouvons compétitifs même sur les données d'image, où Beta SS-DDPM obtient des résultats comparables à un DDPM gaussien.
Logique principale SS-DDPM décrite dans le répertoire "lib / diffusion". Cela peut être suffisant si vous voulez
Vous pouvez également trouver des exemples d'utilisation de SS-DDPM sur des données géodésiques et synthétiques dans le répertoire "Notebooks". Si vous souhaitez reproduire nos résultats, vous pouvez trouver des exemples d'exécutions de commandes pour des expériences sur CIFAR10 et Text8.
Structure de repo:
Ce repo a été testé avec Torch == 1.12.0 + Cu113 TorchVision == 0.13.0 + Cu113
git clone https://github.com/andrey-okhotin/star-shaped
cd star-shaped
pip install -r requirements.txt
# only if you don't have pytorch or your pytorch version < 1.11
pip install torch==1.12.0+cu113 torchvision==0.13.0+cu113 --extra-index-url https://download.pytorch.org/whl/cu113
# only for experiments with synthetic data, otherwise you can just comment all 'import npeet'
git clone https://github.com/gregversteeg/NPEET.git && cd NPEET && pip install . && cd ../ && rm -rf NPEETTéléchargement du contenu du dossier DataSets - nécessaire pour tous les pipelines. Cette commande peut prendre environ 5 minutes.
pip install py7zr gdown
rm -rf star-shaped/datasets
gdown --fuzzy https://drive.google.com/file/d/1ndXOmbNXR6pwoJ5qs1gVP0eAKU_RAl6E/view ? usp=sharing
py7zr x datasets.7z && rm datasets.7z && mv datasets star-shaped/datasetsTéléchargement du contenu du dossier Pretrained_Models - Pas nécessaire pour la formation des pipelines. Cette commande peut prendre environ 3 minutes.
pip install py7zr gdown
rm -rf star-shaped/pretrained_models
gdown --fuzzy https://drive.google.com/file/d/1Lebmsti31CwOFg4LYJYlWmlS7rGYQfVi/view ? usp=sharing
py7zr x pretrained_models.7z && rm pretrained_models.7z && mv pretrained_models star-shaped/pretrained_modelsDisponible pour l'exécution à partir de Jupyter-noteBook dans Directory SS_DDPM / Notebooks. Vous pouvez trouver des exemples de formation et d'échantillonnage pour
Disponible pour l'exécution de Bash dans Directory SS_DDPM
Commande en cours d'exécution:
python lib/run_pipeline -gpu < gpu0_idx > _ < gpu1_idx > _ < gpu2_idx > -pipeline < pipeline_name > -logs_file < name_of_txt_file_to_write_execution_info > -port < available_port_for_processes_sync > . . . " other_pipeline_arguments "Exemple d'utilisation courte pour fonctionner sur 3 GPU sur un seul nœud:
python lib/run_pipeline -gpu 0_1_2 -pipeline train_cifar10 -logs_file logs_train_cifar10.txt -port 8890 . . . " other_pipeline_arguments " Formation Beta SS-DDPM sur 4 NVIDIA V100 (Besoin de ~ 32 Go de mémoire GPU). Les points de contrôle seront enregistrés dans le répertoire "Checkpoints / Train_BETA_SS_CIFAR10". Les graphiques de perte seront enregistrés dans le répertoire "Résultats / Train_BETA_SS_CIFAR10".
python lib/run_pipeline.py -gpu 0_1_2_3 -port 8900 -pipeline training_cifar10 -diffusion beta_ss -loss KL_rescaled -save_folder train_beta_ss_cifar10 -logs_file logs_training_beta_ss_cifar10.txt
cp checkpoints/training_beta_ss_cifar10/NCSNpp_episode0_epoch1050_model.pt pretrained_models/ncsnpp-cifar10_beta-ss.ptÉchantillonnage bêta SS-DDPM sur 2 Nvidia V100. Les résultats seront enregistrés dans le répertoire "Résultats / Sampling_BETA_SS_CIFAR10 / GENERATED_SMELLES".
python lib/run_pipeline.py -gpu 0_1 -port 8900 -pipeline sampling_cifar10 -diffusion beta_ss -num_sampling_steps 1000 -pretrained_model ncsnpp-cifar10_beta-ss.pt -num_samples 50000 -save_folder sampling_beta_ss_cifar10 -logs_file logs_sampling_beta_ss.txt
python -m pytorch_fid datasets/FID_cifar10_pack50000 results/sampling_beta_ss_cifar10/generated_samplesSi vous exécutez exactement les mêmes commandes, vous obtiendrez FID ~ 3.24.
Formation Catégorielle SS-DDPM sur 4 NVIDIA A100 (Besoin d'environ 150 Go de mémoire GPU). Les points de contrôle seront enregistrés dans le répertoire "Checkpoints / Training_Categorical_SS_Text8". Les graphiques de perte seront enregistrés dans le répertoire "Results / Training_Categorical_SS_text8".
python lib/run_pipeline.py -gpu 0_1_2_3 -port 8900 -pipeline training_text8 -diffusion categorical_ss -loss KL -save_folder training_categorical_ss_text8 -logs_file logs_training_categorical_ss.txt
cp checkpoints/training_categorical_ss_text8/T5Encoder_episode0_epoch2016_model.pt pretrained_models/t5base-text8_categorical-ss_fully-trained.ptEstimation du NLL dans le SS-DDPM catégorique sur 3 NVIDIA A100. Les résultats seront enregistrés dans le répertoire "Résultats / Nll_Stimations".
python lib/run_pipeline.py -gpu 0_1_2 -port 8900 -pipeline estimating_nll_text8 -diffusion categorical_ss -pretrained_model t5base-text8_categorical-ss_fully-trained.pt -num_samples -1 -batch_size 1536 -dataset_part test -num_iwae_trajectories 1 -save_folder nll_text8_categorical-ss -logs_file logs_nll_text8_categorical_ss.txtSi vous exécutez exactement les mêmes commandes, vous obtiendrez NLL ~ 1.61.
@ inproceedings { okhotin2023star ,
author = { Andrey Okhotin , Dmitry Molchanov , Vladimir Arkhipkin , Grigory Bartosh , Viktor Ohanesian , Aibek Alanov and Dmitry Vetrov },
title = { Star - Shaped Denoising Diffusion Probabilistic Models },
booktitle = { Advances in Neural Information Processing Systems },
volume = { 36 },
year = { 2023 }
}

