star shaped
1.0.0
このレポは、さまざまな非ユークリッドマニホールドに適用される非ガウス拡散モデルを作成するためのアプローチである紙星型の拡散確率モデルのための公式のPytorch実装が含まれています。
Andrey Okhotin*、Dmitry Molchanov*、Vladimir Arkhipkin、Grigory Bartosh、Viktor Ohanesian、Aibek Alanov、Dmitry Vetrov
アシスタント:セルゲイ・ホルキン
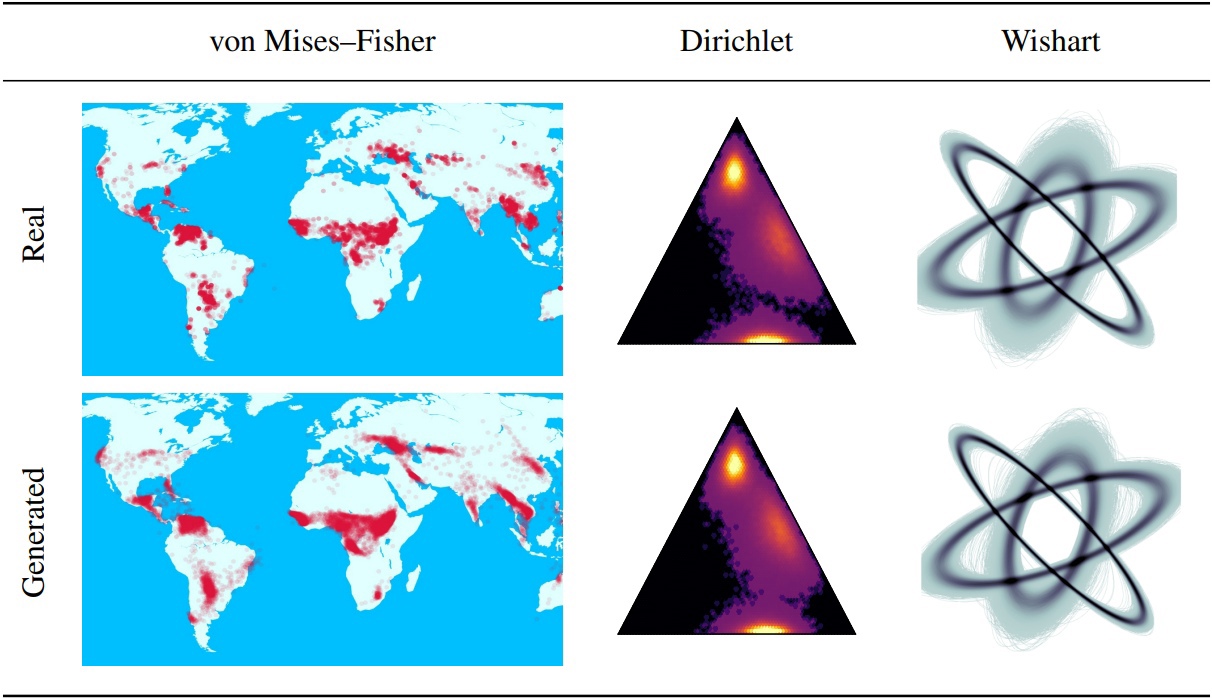
拡散確率モデル(DDPMS)を除去すると、生成モデリングにおける最近のブレークスルーの基盤が提供されます。それらのマルコフの構造により、ガウスまたは個別以外の分布でDDPMを定義することが困難になります。この論文では、星型のDDPM(SS-DDPM)を紹介します。その星型の拡散プロセスにより、遷移確率を定義したり、事後を計算する必要性をバイパスすることができます。私たちは、指数分布のファミリーに対して星型と特定のマルコフ拡散の間に二重性を確立し、SS-DDPMからトレーニングとサンプリングのための効率的なアルゴリズムを導き出します。ガウス分布の場合、SS-DDPMはDDPMに相当します。ただし、SS-DDPMSは、ベータ、フォンミーゼスなどの分布で拡散モデルを設計するための簡単なレシピを提供します。さまざまな設定でモデルを評価し、ベータSS-DDPMがガウスDDPMに匹敵する結果を達成する画像データでも競争力があることがわかります。
「lib/diffusion」ディレクトリで説明されているメインSS-DDPMロジック。必要に応じてこれで十分です
また、ディレクトリ「ノートブック」の測地基と合成データでSS-DDPMを使用する例を見つけることができます。結果を再現したい場合は、CIFAR10およびText8での実験のコマンド実行の例を見つけることができます。
レポ構造:
Torch == 1.12.0+Cu113 TorchVision == 0.13.0+Cu113でテストされたこのレポはテストされました
git clone https://github.com/andrey-okhotin/star-shaped
cd star-shaped
pip install -r requirements.txt
# only if you don't have pytorch or your pytorch version < 1.11
pip install torch==1.12.0+cu113 torchvision==0.13.0+cu113 --extra-index-url https://download.pytorch.org/whl/cu113
# only for experiments with synthetic data, otherwise you can just comment all 'import npeet'
git clone https://github.com/gregversteeg/NPEET.git && cd NPEET && pip install . && cd ../ && rm -rf NPEETデータセットフォルダーのコンテンツのダウンロード - すべてのパイプラインに必要です。このコマンドには約5分かかる場合があります。
pip install py7zr gdown
rm -rf star-shaped/datasets
gdown --fuzzy https://drive.google.com/file/d/1ndXOmbNXR6pwoJ5qs1gVP0eAKU_RAl6E/view ? usp=sharing
py7zr x datasets.7z && rm datasets.7z && mv datasets star-shaped/datasetsPretrained_Modelsフォルダーのコンテンツのダウンロード - パイプラインのトレーニングには必要ありません。このコマンドは約3分かかる場合があります。
pip install py7zr gdown
rm -rf star-shaped/pretrained_models
gdown --fuzzy https://drive.google.com/file/d/1Lebmsti31CwOFg4LYJYlWmlS7rGYQfVi/view ? usp=sharing
py7zr x pretrained_models.7z && rm pretrained_models.7z && mv pretrained_models star-shaped/pretrained_modelsjupyter-notebookからディレクトリss_ddpm/ノートブックから実行できます。そこでは、トレーニングとサンプリングの例を見つけることができます
ディレクトリSS_DDPMでBashから実行できます
実行中のコマンド:
python lib/run_pipeline -gpu < gpu0_idx > _ < gpu1_idx > _ < gpu2_idx > -pipeline < pipeline_name > -logs_file < name_of_txt_file_to_write_execution_info > -port < available_port_for_processes_sync > . . . " other_pipeline_arguments "単一のノードで3つのGPUで実行するための短い使用例:
python lib/run_pipeline -gpu 0_1_2 -pipeline train_cifar10 -logs_file logs_train_cifar10.txt -port 8890 . . . " other_pipeline_arguments " 4 NVIDIA V100でのベータSS-DDPMのトレーニング(〜32GB GPUメモリが必要)。チェックポイントは、ディレクトリ「チェックポイント/train_beta_ss_cifar10」に保存されます。損失グラフィックは、ディレクトリ「results/train_beta_ss_cifar10」に保存されます。
python lib/run_pipeline.py -gpu 0_1_2_3 -port 8900 -pipeline training_cifar10 -diffusion beta_ss -loss KL_rescaled -save_folder train_beta_ss_cifar10 -logs_file logs_training_beta_ss_cifar10.txt
cp checkpoints/training_beta_ss_cifar10/NCSNpp_episode0_epoch1050_model.pt pretrained_models/ncsnpp-cifar10_beta-ss.pt2 NVIDIA V100のベータSS-DDPMのサンプリング。結果は、ディレクトリ「results/sampling_beta_ss_cifar10/generated_samples」に保存されます。
python lib/run_pipeline.py -gpu 0_1 -port 8900 -pipeline sampling_cifar10 -diffusion beta_ss -num_sampling_steps 1000 -pretrained_model ncsnpp-cifar10_beta-ss.pt -num_samples 50000 -save_folder sampling_beta_ss_cifar10 -logs_file logs_sampling_beta_ss.txt
python -m pytorch_fid datasets/FID_cifar10_pack50000 results/sampling_beta_ss_cifar10/generated_samplesまったく同じコマンドを実行すると、fid〜3.24が得られます。
4 NVIDIA A100でのカテゴリSS-DDPMのトレーニング(〜150GB GPUメモリが必要)。チェックポイントは、ディレクトリ「CheckPoints/Training_Categorical_SS_TEXT8」に保存されます。損失グラフィックは、ディレクトリ「results/training_categorical_ss_text8」に保存されます。
python lib/run_pipeline.py -gpu 0_1_2_3 -port 8900 -pipeline training_text8 -diffusion categorical_ss -loss KL -save_folder training_categorical_ss_text8 -logs_file logs_training_categorical_ss.txt
cp checkpoints/training_categorical_ss_text8/T5Encoder_episode0_epoch2016_model.pt pretrained_models/t5base-text8_categorical-ss_fully-trained.pt3 NVIDIA A100のカテゴリSS-DDPMでNLLを推定します。結果は、ディレクトリ「結果/nll_estimations」に保存されます。
python lib/run_pipeline.py -gpu 0_1_2 -port 8900 -pipeline estimating_nll_text8 -diffusion categorical_ss -pretrained_model t5base-text8_categorical-ss_fully-trained.pt -num_samples -1 -batch_size 1536 -dataset_part test -num_iwae_trajectories 1 -save_folder nll_text8_categorical-ss -logs_file logs_nll_text8_categorical_ss.txtまったく同じコマンドを実行すると、nll〜1.61が取得されます。
@ inproceedings { okhotin2023star ,
author = { Andrey Okhotin , Dmitry Molchanov , Vladimir Arkhipkin , Grigory Bartosh , Viktor Ohanesian , Aibek Alanov and Dmitry Vetrov },
title = { Star - Shaped Denoising Diffusion Probabilistic Models },
booktitle = { Advances in Neural Information Processing Systems },
volume = { 36 },
year = { 2023 }
}

