nanoflann
v1.6.2
Nanoflann -это библиотека только C ++ 11, только для создания KD-деревей наборов данных с различными топологиями: R 2 , R 3 (точка облака), поэтому (2) и поэтому (3) (2D и 3D-группы вращения). Не предоставляется поддержка приблизительного NN. Nanoflann не требует компиляции или установки. Вам просто нужно #include <nanoflann.hpp> в вашем коде.
Эта библиотека является вилкой библиотеки Фланна Мариуса Муджа и Дэвида Дж. Лоу, и родилась в детском проекте MRPT. После исходных условий лицензии Nanoflann распределяется по лицензии BSD. Пожалуйста, для ошибок используйте кнопку «Проблемы» или «Вилка» и откройте запрос на тягу.
Цитировать как:
@misc{blanco2014nanoflann,
title = {nanoflann: a {C}++ header-only fork of {FLANN}, a library for Nearest Neighbor ({NN}) with KD-trees},
author = {Blanco, Jose Luis and Rai, Pranjal Kumar},
howpublished = {url{https://github.com/jlblancoc/nanoflann}},
year = {2014}
}
Смотрите релиз Changelog для списка изменений проекта.
include/nanoflann.hpp для использования, где он вам нужен.$ sudo apt install libnanoflann-devnanoflann с Homebrew с: $ brew install brewsci/science/nanoflann$ brew tap brewsci/science
$ brew install nanoflann$ sudo port install nanoflannbrew install homebrew/science/nanoflannХотя сам нанофланн не должен быть составлен, вы можете построить несколько примеров и тестов с:
$ sudo apt-get install build-essential cmake libgtest-dev libeigen3-dev
$ mkdir build && cd build && cmake ..
$ make && make testПросмотрите документацию доксигена.
Важное примечание: если используются нормы L2, обратите внимание, что радиус поиска и все пройденные и возвращенные расстояния на самом деле являются квадратными расстояниями .
knnSearch() и radiusSearch() : pointcloud_kdd_radius.cppEigen::Matrix<> : matrix_example.cppstd::vector<std::vector<T> > или std::vector<Eigen::VectorXd> : vector_of_vectors_example.cppMakefile для использования через pkg-config (например, после выполнения «Make Install» или после установки из репозитории Ubuntu): example_with_pkgconfig/mrpt-gui , например, sudo apt install libmrpt-gui-dev ):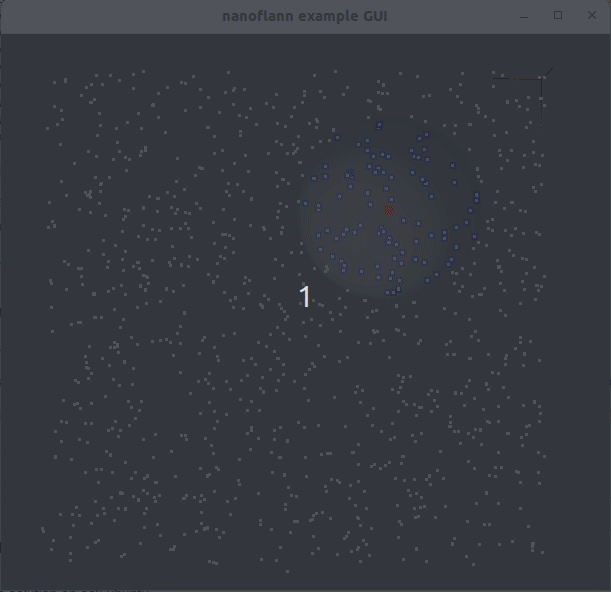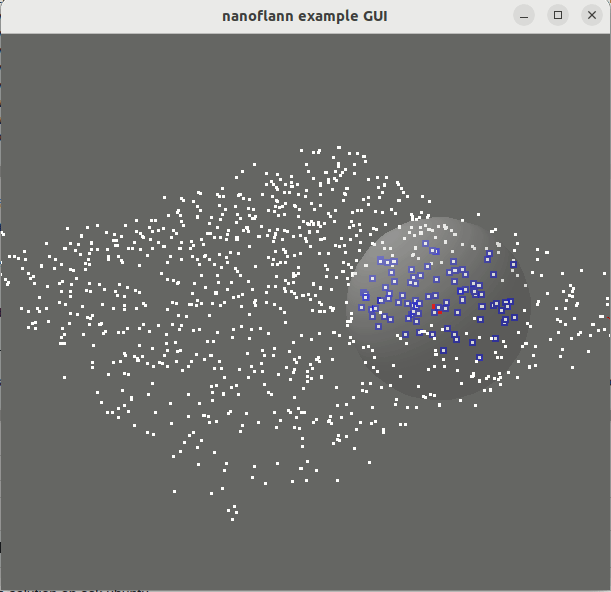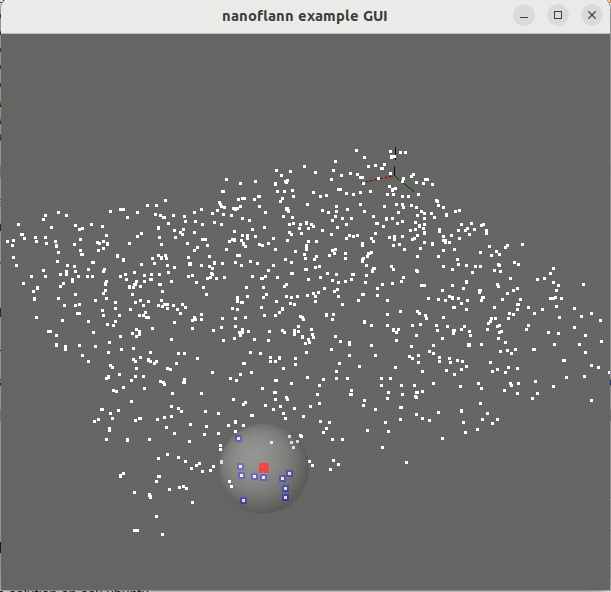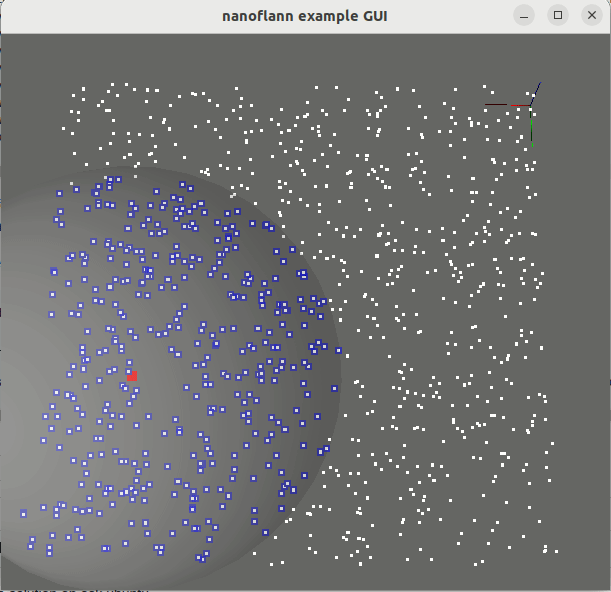
Эффективность времени выполнения :
flann происходит от возможности выбора между различными алгоритмами ANN. Стоимость этой гибкости-это объявление чистых виртуальных методов, которые (в некоторых обстоятельствах) навязывают штрафы за время выполнения. В nanoflann все эти виртуальные методы были заменены комбинацией любопытно повторяющегося шаблона (CRTP) и вставленных методов, которые намного быстрее.radiusSearch() нет необходимости вызовать, чтобы определить количество точек в радиусе, а затем вызовать его снова, чтобы получить данные. Используя контейнеры STL для выходных данных, контейнеры автоматически изменяются.nanoflann позволяет пользователям предоставлять предварительно рассчитанное ограничивающее ящику данных, если таковые имеются, чтобы избежать рекомпьютации.int в size_t , что удаляет ограничение при обработке очень больших наборов данных. Эффективность памяти : Вместо того, чтобы сделать копию всего набора данных в пользовательскую матрицу, подобную flann , перед созданием индекса KD -Tree, nanoflann позволяет прямой доступ к вашим данным через интерфейс адаптера , который должен реализовать в вашем классе.
Обратитесь к примерам ниже или к API C ++ Nanoflann :: Kdtreesingleindexadaptor <> для получения дополнительной информации.
::knnSearch()num_closest для query_point[0:dim-1] . Их индексы хранятся внутри объекта результата. См. Пример кода использования.::radiusSearch()query_point[0:dim-1] в пределах максимального радиуса. Выход дается как вектор пар, из которых первый элемент является точечным индексом, а второй - соответствующее расстояние. См. Пример кода использования.::radiusSearchCustomCallback()Eigen::Matrix<> (матрицы и векторы векторов).R^N : евклидовые пространства:L1 (Манхэттен)L2 ( квадратная евклидовая норма, предпочитающая оптимизацию SSE2).L2_Simple ( квадратная евклидовая норма, для наборов данных о низкой размерности, таких как точечные облака).SO(2) : 2D ротационная группаmetric_SO2 : абсолютная угловая динамика.SO(3) : 3D ротационная группа (лучше предоставить в будущих выпусках)metric_SO3 : внутренний продукт между кватернионами. Вы можете напрямую отбросить файл nanoflann.hpp в свой проект. В качестве альтернативы, стандартный метод Cmake также доступен:
CMAKE_INSTALL_PREFIX на правильный путь, а затем выполните make install (Linux, OSX) или создайте цель INSTALL (Visual Studio). # Find nanoflannConfig.cmake:
find_package (nanoflann)
add_executable (my_project test .cpp)
# Make sure the include path is used:
target_link_libraries (my_project nanoflann::nanoflann)conan Вы можете установить предварительно построенные двоичные файлы для nanoflann или построить его из источника с помощью Conan. Используйте следующую команду для установки последней версии:
$ conan install --requires= " nanoflann/[*] " --build=missingДля получения подробных инструкций о том, как использовать Conan, пожалуйста, обратитесь к документации CONAN.
Рецепт nanoflann Conan актуально актуально со стороны CONAN Savingers и сообщества. Если версия устарела, пожалуйста, создайте проблему или запрос на вытягивание в репозитории ConancenterIndex.
vcpkgВы можете скачать и установить Nanoflann, используя VCPKG DevingDency Manager:
$ git clone https://github.com/Microsoft/vcpkg.git
$ cd vcpkg
$ ./bootstrap-vcpkg.sh
$ ./vcpkg integrate install
$ ./vcpkg install nanoflannПорт Nanoflann в VCPKG обновляется членами команды Microsoft и участниками сообщества. Если версия установлена на устаре, пожалуйста, создайте проблему или запрос на вытягивание в репозитории VCPKG.
NANOFLANN_FIRST_MATCH : если определено, а две точки имеют одинаковое расстояние, то, что с самой низкой индексом, будет возвращена сначала. В противном случае нет особого порядка.NANOFLANN_NO_THREADS : если определены, возможности многопоточного чтения будут отключены, так что библиотека можно использовать без связывания с Pthreads. Если кто -то попытается использовать несколько потоков, будет брошено исключение. KDTreeSingleIndexAdaptorParams::leaf_max_sizeКД-дерево ... ну, дерево :-). И как таковой, он имеет корневой узел, набор посреднических узлов и, наконец, «листовые» узлы, которые имеют неработники.
Точки (или, правильно, точечные индексы) хранятся только в листовых узлах. Каждый лист содержит список, какой точки попадают в его диапазон.
Построение дерева, узлы рекурсивно делятся до тех пор, пока количество точек внутри не будет равным или ниже некоторого порога. Это leaf_max_size . При выполнении запросов «алгоритм дерева» заканчивается выбором узлов листьев, затем выполняя линейный поиск (один за один) для ближайшей точки к запросу во всех тех, кто находится в листе.
Итак, leaf_max_size должен быть установлен как компромисс :
Какое число выбрать действительно зависит от приложения и даже от размера памяти кэша процессора, поэтому в идеале вы должны сделать некоторый сравнительный анализ для максимизации эффективности.
Но чтобы помочь выбрать хорошую ценность, как правило, я предоставляю следующие два теста. Каждый график представляет временные районы дерева (горизонтальный) и запрос (вертикальный) для различных значений leaf_max_size от 1 до 10K (как 95% эллипсов неопределенности, деформированные из -за логарифмической шкалы).
float ):scan_071_points.dat из набора данных Campus 360 Freiburg, каждая точка имеет координаты float (x, y, z): Таким образом, кажется, что leaf_max_size от 10 до 50 будет оптимальным в приложениях, где доминирует стоимость запросов (например, ICP). В настоящее время его значение по умолчанию составляет 10.
KDTreeSingleIndexAdaptorParams::checks Этот параметр действительно игнорируется в nanoflann , но был оставлен для обратной совместимости с исходным интерфейсом Flann. Просто игнорируйте это.
KDTreeSingleIndexAdaptorParams::n_thread_build Этот параметр определяет максимальное количество резьбов, которые можно назвать одновременно во время построения дерева KD. Значение по умолчанию составляет 1. Когда параметр установлен на 0, nanoflann автоматически определяет количество потоков для использования.
Посмотрите на этот запрос на притяжение для некоторого сравнительного анализа, показывающего, что использование максимального количества потоков не всегда является наиболее эффективным подходом. Сделайте сравнительный анализ на своих данных!
nanoflann : быстрее и меньше использования памяти См. "Почему вилка?" Раздел выше для основных идей оптимизации, стоящих за nanoflann .
Обратите внимание, что в nanoflann нет явных оптимизаций SSE2/SSE3, но интенсивное использование inline и шаблонов на практике превращается в автоматически SSE-оптимизированный код, генерируемый компилятором.
flann vs nanoflannСамая трудоемкая часть многих облачных алгоритмов точечных облаков (например, ICP)-запросить KD-дерево для ближайших соседей. Поэтому эта операция является наиболее важной.
nanoflann обеспечивает ~ 50% сэкономить время по отношению к исходной реализации flann (время на этой диаграмме находится в микросекундах для каждого запроса):
Хотя большая часть усиления поступает из запросов (из-за большого количества из них в любой типичной операции с точками), существует также некоторое время, которое сохранено при создании индекса KD-дерева, из-за температурного кода, а также для устранения дублирования данных в вспомогательной матрице (время в следующем диаграмме находится в миллисекундах):
Эти тестирование производительности являются лишь репрезентативными для нашего тестирования. Если вы хотите их повторить, прочитайте инструкции в perf-tests
Примечание: логотип проекта связан с Cedareed
Участники


