nanoflann
v1.6.2
Nanoflann هي مكتبة C ++ 11 رأس فقط لبناء أشجار KD من مجموعات البيانات مع طوبولوجيا مختلفة: R 2 ، R 3 (النقاط السحب) ، لذلك (2) وهكذا (3) (مجموعات الدوران 2D و 3D). لا يتم توفير أي دعم لل NN التقريبي. لا يتطلب Nanoflann التجميع أو التثبيت. تحتاج فقط إلى #include <nanoflann.hpp> في الكود الخاص بك.
هذه المكتبة هي شوكة لمكتبة Flann من تأليف ماريوس موجة وديفيد ج. لوي ، ولدت كمشروع طفل ل MRPT. بعد شروط الترخيص الأصلية ، يتم توزيع Nanoflann بموجب ترخيص BSD. من فضلك ، للأخطاء ، استخدم زر المشكلات أو الشوكة وفتح طلب سحب.
استشهد بـ:
@misc{blanco2014nanoflann,
title = {nanoflann: a {C}++ header-only fork of {FLANN}, a library for Nearest Neighbor ({NN}) with KD-trees},
author = {Blanco, Jose Luis and Rai, Pranjal Kumar},
howpublished = {url{https://github.com/jlblancoc/nanoflann}},
year = {2014}
}
راجع الإصدار changelog للحصول على قائمة بتغييرات المشروع.
include/nanoflann.hpp للاستخدام حيث تحتاجه.$ sudo apt install libnanoflann-devnanoflann مع Homebrew مع: $ brew install brewsci/science/nanoflann$ brew tap brewsci/science
$ brew install nanoflann$ sudo port install nanoflannbrew install homebrew/science/nanoflannعلى الرغم من أن Nanoflann نفسها لا يجب تجميعها ، يمكنك بناء بعض الأمثلة والاختبارات مع:
$ sudo apt-get install build-essential cmake libgtest-dev libeigen3-dev
$ mkdir build && cd build && cmake ..
$ make && make testتصفح وثائق doxygen.
ملاحظة مهمة: إذا تم استخدام قواعد L2 ، لاحظ أن نصف قطر البحث وجميع المسافات التي تم تمريرها وإرجاعها تكون مسافات مربعة بالفعل.
knnSearch() و radiusSearch() : pointcloud_kdd_radius.cppEigen::Matrix<> : matrix_example.cppstd::vector<std::vector<T> > أو std::vector<Eigen::VectorXd> : vector_of_vectors_example.cppMakefile للاستخدام من خلال pkg-config (على سبيل المثال ، بعد القيام "بإجراء تثبيت" أو بعد التثبيت من مستودعات Ubuntu): example_with_pkgconfig/mrpt-gui ، eg sudo apt install libmrpt-gui-dev ):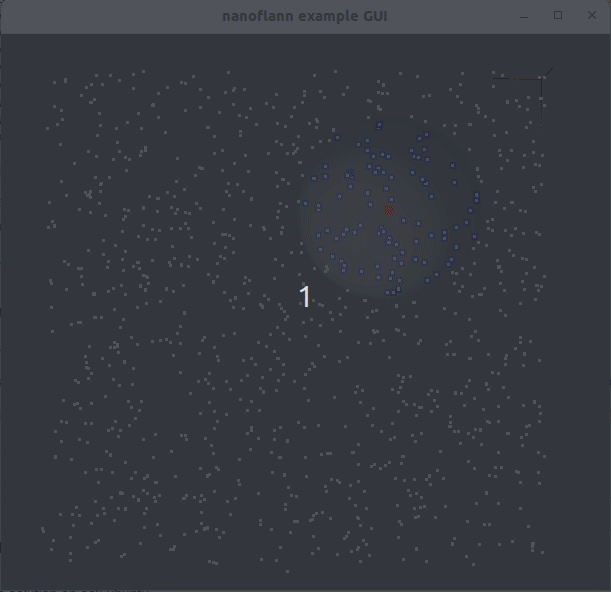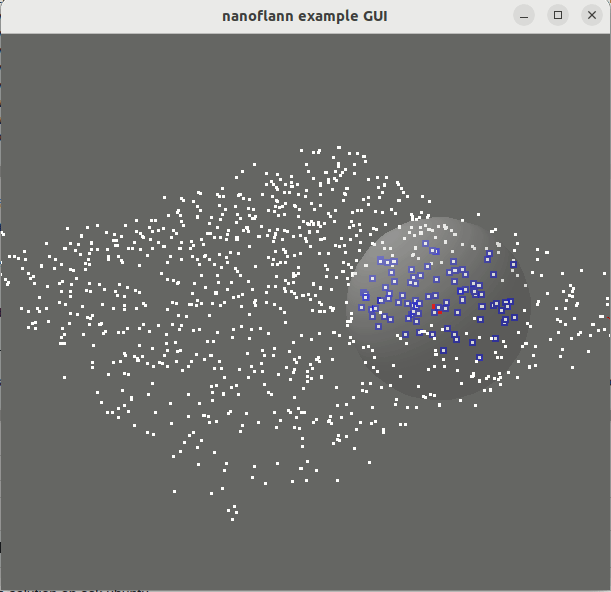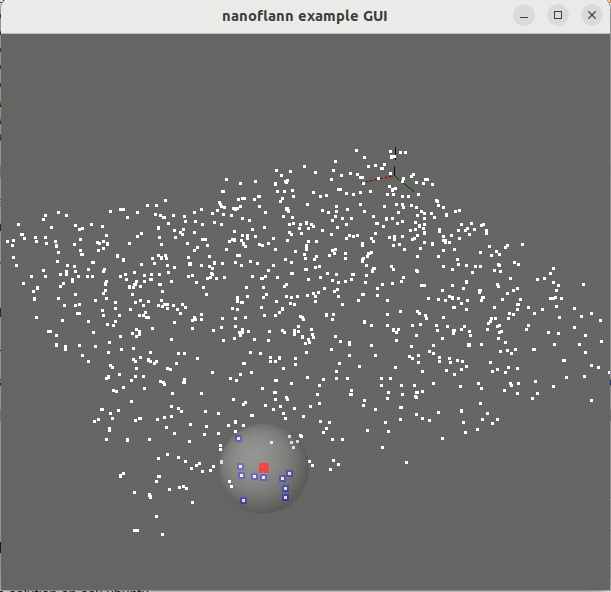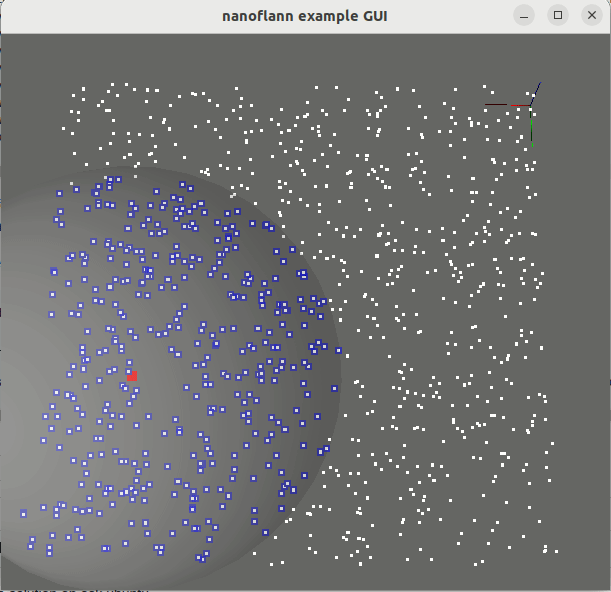
كفاءة وقت التنفيذ :
flann الأصلية من إمكانية الاختيار بين خوارزميات ANN المختلفة. تكلفة هذه المرونة هي إعلان الأساليب الافتراضية الخالصة التي (في بعض الظروف) تفرض عقوبات في وقت التشغيل. في nanoflann تم استبدال جميع هذه الأساليب الافتراضية بمجموعة من نمط القالب المتكرر الغريب (CRTP) والطرق المضمّنة ، والتي تكون أسرع بكثير.radiusSearch() ، ليست هناك حاجة لإجراء مكالمة لتحديد عدد النقاط داخل نصف القطر ثم اتصل بها مرة أخرى للحصول على البيانات. باستخدام حاويات STL لبيانات الإخراج ، يتم تغيير حجم الحاويات تلقائيًا.nanoflann للمستخدمين بتوفير مربع ملزم مسبقًا للبيانات ، إن وجدت ، لتجنب إعادة التثبيت.int إلى size_t ، والتي تزيل الحد الأقصى عند التعامل مع مجموعات البيانات الكبيرة جدًا. كفاءة الذاكرة : بدلاً من إنشاء نسخة من مجموعة البيانات بأكملها في مصفوفة مثل flann المخصصة قبل إنشاء فهرس KD Tree ، يسمح nanoflann بالوصول المباشر إلى بياناتك عبر واجهة محول يجب تنفيذها في فئتك.
ارجع إلى الأمثلة أدناه أو إلى C ++ API من Nanoflann :: KdtreeSingleIndexAdaptor <> لمزيد من المعلومات.
::knnSearch()num_closest إلى query_point[0:dim-1] . يتم تخزين مؤشراتهم داخل كائن النتيجة. انظر مثال رمز الاستخدام.::radiusSearch()query_point[0:dim-1] داخل نصف قطرها القصوى. يتم إعطاء الإخراج كمتجه للأزواج ، والذي يكون العنصر الأول هو فهرس النقطة والثاني المسافة المقابلة. انظر مثال رمز الاستخدام.::radiusSearchCustomCallback()Eigen::Matrix<> فئات (المصفوفات والمتجهات في المجالات).R^N : المساحات الإقليدية:L1 (مانهاتن)L2 (قاعدة إقليدية مربعة ، لصالح تحسين SSE2).L2_Simple (قاعدة الإقليدية التربيعة ، لمجموعات بيانات الأبعاد المنخفضة مثل السحب النقطة).SO(2) : مجموعة الدوران 2Dmetric_SO2 : الاختلاف الزاوي المطلق.SO(3) : مجموعة الدوران ثلاثية الأبعاد (من الأفضل أن يتم توفيرها في الإصدارات المستقبلية)metric_SO3 : المنتج الداخلي بين الرباعي. يمكنك إسقاط ملف nanoflann.hpp مباشرة في مشروعك. بدلاً من ذلك ، تتوفر طريقة Cmake Standard أيضًا:
CMAKE_INSTALL_PREFIX إلى مسار مناسب ثم تنفيذ make install (Linux ، OSX) أو إنشاء هدف INSTALL (Visual Studio). # Find nanoflannConfig.cmake:
find_package (nanoflann)
add_executable (my_project test .cpp)
# Make sure the include path is used:
target_link_libraries (my_project nanoflann::nanoflann)conan يمكنك تثبيت ثنائيات تم إنشاؤها مسبقًا لـ nanoflann أو إنشاءها من المصدر باستخدام Conan. استخدم الأمر التالي لتثبيت أحدث إصدار:
$ conan install --requires= " nanoflann/[*] " --build=missingللحصول على إرشادات مفصلة حول كيفية استخدام كونان ، يرجى الرجوع إلى وثائق كونان.
يتم الحفاظ على وصفة nanoflann Conan من قبل محفوظات Conan والمساهمين في المجتمع. إذا كان الإصدار قديمًا ، فيرجى إنشاء مشكلة أو سحب طلب على مستودع ConancenSerIndex.
vcpkgيمكنك تنزيل وتثبيت Nanoflann باستخدام مدير التبعية VCPKG:
$ git clone https://github.com/Microsoft/vcpkg.git
$ cd vcpkg
$ ./bootstrap-vcpkg.sh
$ ./vcpkg integrate install
$ ./vcpkg install nanoflannيتم الحفاظ على ميناء Nanoflann في VCPKG من قبل أعضاء فريق Microsoft والمساهمين في المجتمع. إذا كان الإصدار قديمًا ، فيرجى إنشاء مشكلة أو سحب طلب على مستودع VCPKG.
NANOFLANN_FIRST_MATCH : إذا تم تحديدها ونقطتين لهما نفس المسافة ، فسيتم إرجاع النقطتين ذات المؤتمر الأدنى أولاً. وإلا لا يوجد ترتيب معين.NANOFLANN_NO_THREADS : إذا تم تحديد إمكانات التعددية المعدلة ، بحيث يمكن استخدام المكتبة دون الارتباط باستخدام pthreads. إذا حاول المرء استخدام مؤشرات ترابط متعددة ، فسيتم طرح استثناء. KDTreeSingleIndexAdaptorParams::leaf_max_sizeشجرة KD هي ... حسنا ، شجرة :-). وعلى هذا النحو ، فإنه يحتوي على عقدة جذر ، ومجموعة من العقد الوسيطة وأخيراً ، العقد "الأوراق" التي هي تلك التي لا تحتوي على أطفال.
يتم تخزين النقاط (أو بشكل صحيح ، مؤشرات النقاط) فقط في العقد الأوراق. تحتوي كل ورقة على قائمة تندرج فيها النقاط ضمن نطاقها.
أثناء بناء الشجرة ، يتم تقسيم العقد بشكل متكرر حتى يكون عدد النقاط الموجودة في الداخل متساوية أو أقل من بعض العتبة. هذا هو leaf_max_size . أثناء إجراء الاستعلامات ، تنتهي "خوارزمية الأشجار" عن طريق اختيار العقد الورقية ، ثم إجراء بحث خطي (واحدًا تلو الآخر) لأقرب نقطة إلى الاستعلام داخل جميع تلك الموجودة في الورقة.
لذلك ، يجب تعيين leaf_max_size كمدافع :
يعتمد الرقم الذي يجب تحديده حقًا على التطبيق وحتى على حجم ذاكرة ذاكرة التخزين المؤقت للمعالج ، لذلك من الناحية المثالية ، يجب عليك القيام ببعض المعايير لزيادة الكفاءة.
ولكن للمساعدة في اختيار قيمة جيدة كقاعدة عامة ، أقدم المعايير التالية. يمثل كل رسم بياني بناء الأشجار (الأفقي) والاستعلام (العمودي) لقيم leaf_max_size مختلفة بين 1 و 10 كيلو (مثل 95 ٪ من حالات عدم اليقين ، مشوهة بسبب المقياس اللوغاريتمي).
float ):scan_071_points.dat من مجموعة بيانات Freiburg Campus 360 ، تحتوي كل نقطة على float (x ، y ، z) لذلك ، يبدو أن leaf_max_size بين 10 و 50 سيكون الأمثل في التطبيقات التي تهيمن فيها تكلفة الاستعلامات (مثل ICP). في الوقت الحاضر ، قيمتها الافتراضية هي 10.
KDTreeSingleIndexAdaptorParams::checks يتم تجاهل هذه المعلمة حقًا في nanoflann ، ولكن تم الاحتفاظ بها للتوافق المتخلف مع واجهة Flann الأصلية. فقط تجاهلها.
KDTreeSingleIndexAdaptorParams::n_thread_build تحدد هذه المعلمة الحد الأقصى لعدد الخيوط التي يمكن استدعاؤها بشكل متزامن أثناء بناء شجرة KD. القيمة الافتراضية هي 1. عند ضبط المعلمة على 0 ، تحدد nanoflann تلقائيًا عدد مؤشرات الترابط المراد استخدامها.
راجع طلب السحب هذا لبعض المقاييس التي توضح أن استخدام الحد الأقصى لعدد المواضيع ليس دائمًا هو النهج الأكثر كفاءة. هل القياس على بياناتك!
nanoflann : استخدام ذاكرة أسرع وأقل الرجوع إلى "لماذا شوكة؟" القسم أعلاه لأفكار التحسين الرئيسية وراء nanoflann .
لاحظ أنه لا توجد تحسينات صريحة SSE2/SSE3 في nanoflann ، ولكن الاستخدام المكثف inline والقوالب في الممارسة العملية يتحول إلى رمز محسّن SSE تلقائيًا الذي تم إنشاؤه بواسطة برنامج التحويل البرمجي.
flann الأصلي مقابل nanoflannالجزء الأكثر استهلاكًا للوقت من العديد من خوارزميات Cloud Cloud (مثل ICP) هو الاستعلام عن شجرة KD لأقرب الجيران. وبالتالي فإن هذه العملية هي الأكثر أهمية.
يوفر nanoflann توفير الوقت بنسبة 50 ٪ فيما يتعلق بتنفيذ flann الأصلي (الأوقات في هذا المخطط في Microseconds لكل استعلام):
على الرغم من أن معظم المكاسب تأتي من الاستعلامات (بسبب العدد الكبير منها في أي عملية نموذجية مع غيوم النقطة) ، هناك أيضًا بعض الوقت المحفوظ أثناء بناء مؤشر الشجرة KD ، بسبب الكود المعبد ، وأيضًا لتجنب تكرار البيانات في مصفوفة الإفراطية (الأوقات في الرسم القادم في Milliseconds):
اختبارات الأداء هذه تمثل فقط اختبارنا. إذا كنت ترغب في تكرارها ، فاقرأ التعليمات في اختبارات perf
ملاحظة: شعار المشروع ناتج عن Cedarseed
المساهمين


