nanoflann
v1.6.2
Nanoflann es una biblioteca de encabezado C ++ 11 para construir KD-árboles de conjuntos de datos con diferentes topologías: R 2 , R 3 (nubes de puntos), entonces (2) y así (3) (grupos de rotación 2D y 3D). No se proporciona soporte para NN aproximado. Nanoflann no requiere compilar o instalar. Solo necesita #include <nanoflann.hpp> en su código.
Esta biblioteca es una bifurcación de la biblioteca de Flann de Marius Muja y David G. Lowe, y nació como un proyecto infantil de MRPT. Siguiendo los términos originales de la licencia, Nanoflann se distribuye bajo la licencia BSD. Por favor, para obtener errores, use el botón de problemas o la bifurcación y abra una solicitud de extracción.
Citar como:
@misc{blanco2014nanoflann,
title = {nanoflann: a {C}++ header-only fork of {FLANN}, a library for Nearest Neighbor ({NN}) with KD-trees},
author = {Blanco, Jose Luis and Rai, Pranjal Kumar},
howpublished = {url{https://github.com/jlblancoc/nanoflann}},
year = {2014}
}
Consulte el lanzamiento ChangeLog para una lista de cambios en el proyecto.
include/nanoflann.hpp para su uso donde lo necesita.$ sudo apt install libnanoflann-devnanoflann con HomeBrew con: $ brew install brewsci/science/nanoflann$ brew tap brewsci/science
$ brew install nanoflann$ sudo port install nanoflannbrew install homebrew/science/nanoflannAunque Nanoflann en sí no tiene que ser compilado, puede construir algunos ejemplos y pruebas con:
$ sudo apt-get install build-essential cmake libgtest-dev libeigen3-dev
$ mkdir build && cd build && cmake ..
$ make && make testExplore la documentación de Doxygen.
Nota importante: Si se usan normas L2, observe que el radio de búsqueda y todas las distancias pasadas y devueltas son en realidad distancias cuadradas .
knnSearch() y radiusSearch() : pointcloud_kdd_radius.cppEigen::Matrix<> : matrix_example.cppstd::vector<std::vector<T> > o std::vector<Eigen::VectorXd> : vector_of_vectors_example.cppMakefile para el uso a través de pkg-config (por ejemplo, después de hacer una "Instalar" o después de instalar desde repositorios de Ubuntu): Ejemplo_with_pkgconfig/mrpt-gui , por ejemplo sudo apt install libmrpt-gui-dev ):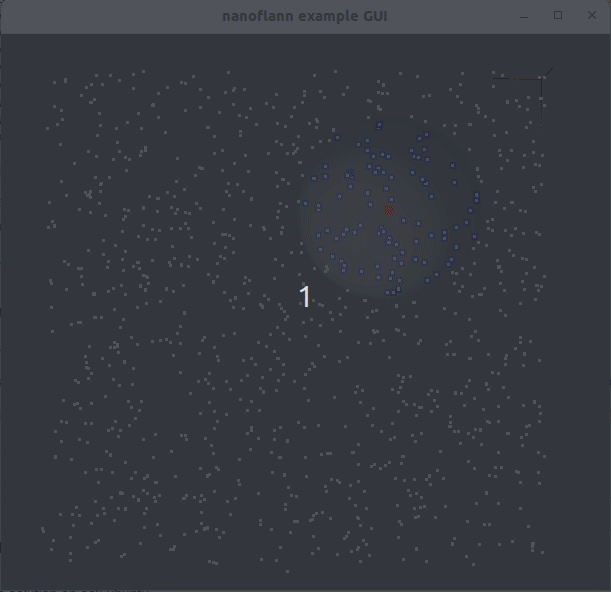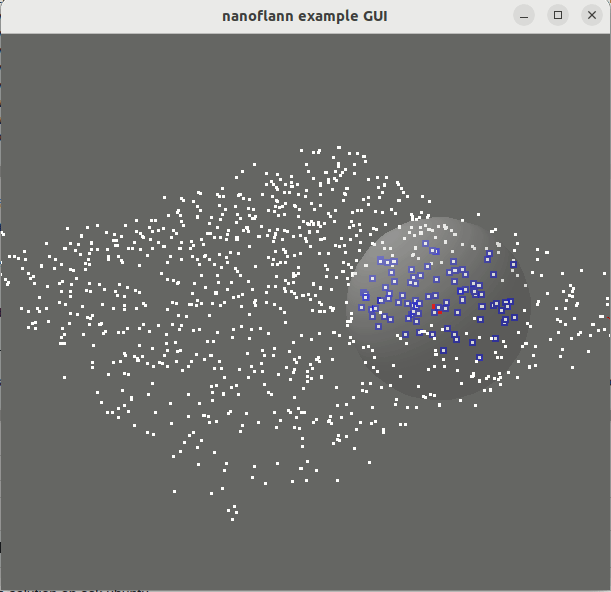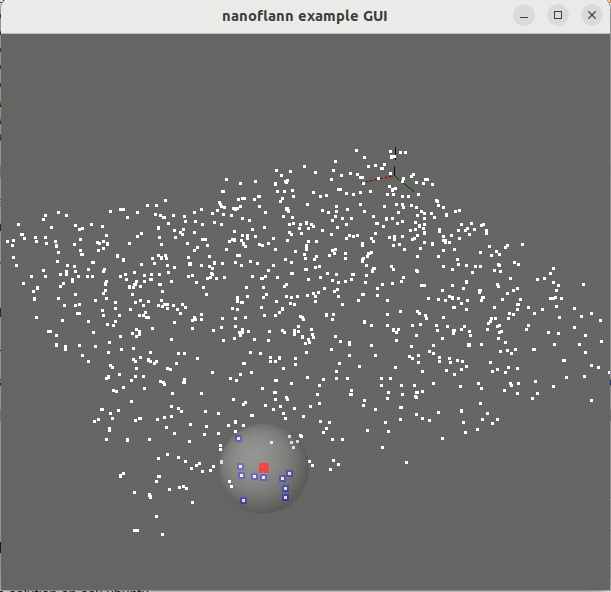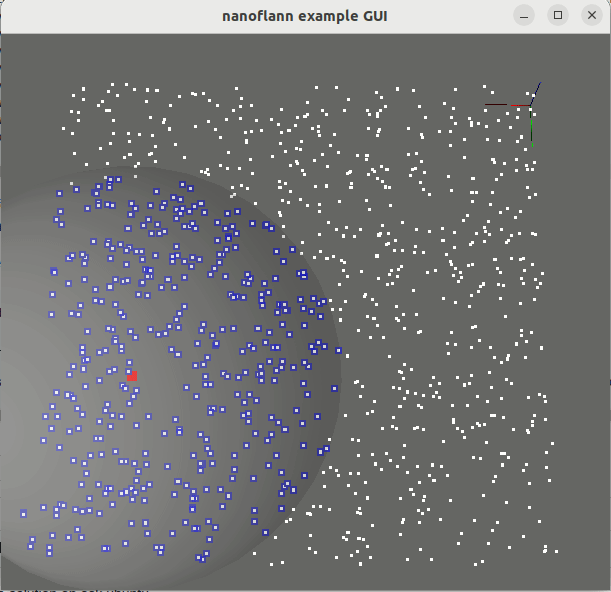
Eficiencia de tiempo de ejecución :
flann original proviene de la posibilidad de elegir entre diferentes algoritmos ANN. El costo de esta flexibilidad es la declaración de métodos virtuales puros que (en algunas circunstancias) imponen sanciones en tiempo de ejecución. En nanoflann todos esos métodos virtuales han sido reemplazados por una combinación del patrón de plantilla curiosamente recurrente (CRTP) y los métodos en línea, que son mucho más rápidos.radiusSearch() , no es necesario hacer una llamada para determinar el número de puntos dentro del radio y luego llamarlo nuevamente para obtener los datos. Mediante el uso de contenedores STL para los datos de salida, los contenedores se cambian automáticamente.nanoflann permite a los usuarios proporcionar un cuadro limitado precomputado de los datos, si están disponibles, para evitar la recomputación.int a size_t , que elimina un límite al manejar conjuntos de datos muy grandes. Eficiencia de la memoria : en lugar de hacer una copia de todo el conjunto de datos en una matriz personalizada de forma de flann antes de construir un índice KD -Tree, nanoflann permite el acceso directo a sus datos a través de una interfaz adaptadora que debe implementarse en su clase.
Consulte los ejemplos a continuación o a la API C ++ de Nanoflann :: KdtreeSingleindexAdaptor <> para obtener más información.
::knnSearch()num_closest a query_point[0:dim-1] . Sus índices se almacenan dentro del objeto de resultado. Ver un ejemplo de código de uso.::radiusSearch()query_point[0:dim-1] dentro de un radio máximo. La salida se da como un vector de pares, de los cuales el primer elemento es un índice de puntos y el segundo la distancia correspondiente. Ver un ejemplo de código de uso.::radiusSearchCustomCallback()Eigen::Matrix<> clases (matrices y vectores de vectores).R^N : espacios euclidianos:L1 (Manhattan)L2 (Norma euclidiana al cuadrado , favoreciendo la optimización de SSE2).L2_Simple (Norma euclidiana al cuadrado , para conjuntos de datos de baja dimensionalidad como nubes puntuales).SO(2) : Grupo de rotación 2Dmetric_SO2 : Diferencia angular absoluta.SO(3) : Grupo de rotación 3D (mejor support que se proporcionará en futuras versiones)metric_SO3 : producto interno entre cuaterniones. Puede soltar directamente el archivo nanoflann.hpp en su proyecto. Alternativamente, el método estándar CMake también está disponible:
CMAKE_INSTALL_PREFIX en una ruta adecuada y luego ejecute make install (Linux, OSX) o cree el destino INSTALL (Visual Studio). # Find nanoflannConfig.cmake:
find_package (nanoflann)
add_executable (my_project test .cpp)
# Make sure the include path is used:
target_link_libraries (my_project nanoflann::nanoflann)conan Puede instalar binarios preconstruidos para nanoflann o construirlo desde la fuente usando Conan. Use el siguiente comando para instalar la última versión:
$ conan install --requires= " nanoflann/[*] " --build=missingPara obtener instrucciones detalladas sobre cómo usar Conan, consulte la documentación de Conan.
La receta de nanoflann Conan se mantiene actualizada por los mantenedores de Conan y los contribuyentes de la comunidad. Si la versión está desactualizada, cree un problema o extraiga la solicitud en el repositorio de ConancenterIndex.
vcpkgPuede descargar e instalar Nanoflann utilizando el Administrador de dependencias VCPKG:
$ git clone https://github.com/Microsoft/vcpkg.git
$ cd vcpkg
$ ./bootstrap-vcpkg.sh
$ ./vcpkg integrate install
$ ./vcpkg install nanoflannEl puerto de Nanoflann en VCPKG se mantiene actualizado por los miembros del equipo de Microsoft y los contribuyentes comunitarios. Si la versión está desactualizada, cree un problema o extraiga la solicitud en el repositorio de VCPKG.
NANOFLANN_FIRST_MATCH : si se define y dos puntos tienen la misma distancia, el que con el índice más bajo se devolverá primero. De lo contrario, no hay orden en particular.NANOFLANN_NO_THREADS : si se define, las capacidades multithreading se deshabilitarán, de modo que la biblioteca se pueda usar sin vincular con pThreads. Si uno intenta usar múltiples hilos, se lanzará una excepción. KDTreeSingleIndexAdaptorParams::leaf_max_sizeUn árbol KD es ... bueno, un árbol :-). Y como tal tiene un nodo raíz, un conjunto de nodos intermediarios y finalmente, nodos de "hoja" que son aquellos sin hijos.
Los puntos (o, correctamente, índices de puntos) solo se almacenan en nodos de hoja. Cada hoja contiene una lista de las cuales los puntos se encuentran dentro de su rango.
Mientras construye el árbol, los nodos se dividen recursivamente hasta que el número de puntos en el interior sea igual o por debajo de algún umbral. Eso es leaf_max_size . Mientras realiza consultas, el "algoritmo de árbol" termina seleccionando nodos de hoja, luego realizando una búsqueda lineal (uno por uno) para el punto más cercano a la consulta dentro de todos los de la hoja.
Entonces, leaf_max_size debe establecerse como una compensación :
Qué número para seleccionar realmente depende de la aplicación e incluso del tamaño de la memoria de caché del procesador, por lo que idealmente debe hacer algo de evaluación comparativa para maximizar la eficiencia.
Pero para ayudar a elegir un buen valor como regla general, proporciono los siguientes dos puntos de referencia. Cada gráfico representa los tiempos de construcción del árbol (horizontal) y consulta (vertical) para diferentes valores de leaf_max_size entre 1 y 10k (como elipses de incertidumbre del 95%, deformadas debido a la escala logarítmica).
float ):scan_071_points.dat desde el conjunto de datos del campus de Friburgo 360, cada punto tiene (x, y, z) coordenadas float ): Entonces, parece que un leaf_max_size entre 10 y 50 sería óptimo en aplicaciones donde domina el costo de las consultas (por ejemplo, ICP). En la actualidad, su valor predeterminado es 10.
KDTreeSingleIndexAdaptorParams::checks Este parámetro realmente se ignora en nanoflann , pero se mantuvo para la compatibilidad hacia atrás con la interfaz Flann original. Solo ignóralo.
KDTreeSingleIndexAdaptorParams::n_thread_build Este parámetro determina el número máximo de hilos que se pueden llamar simultáneamente durante la construcción del árbol KD. El valor predeterminado es 1. Cuando el parámetro se establece en 0, nanoflann determina automáticamente el número de subprocesos a usar.
Vea esta solicitud de extracción de alguna evaluación comparativa que muestra que usar el número máximo de subprocesos no siempre es el enfoque más eficiente. ¡Benchmarking en sus datos!
nanoflann : más rápido y menos uso de memoria Consulte el "¿Por qué un bifurcado?" Sección anterior para las principales ideas de optimización detrás de nanoflann .
Observe que no hay optimizaciones SSE2/SSE3 explícitas en nanoflann , pero el uso intensivo de inline y plantillas en la práctica se convierte en un código optimizado SSE automáticamente generado por el compilador.
flann vs nanoflannLa parte más lento de muchos algoritmos de nubes de puntos (como ICP) es consultar un árbol KD para los vecinos más cercanos. Por lo tanto, esta operación es la más crítica del tiempo.
nanoflann proporciona un ahorro de tiempo de ~ 50% con respecto a la implementación original flann (los tiempos en este cuadro están en microsegundos para cada consulta):
Aunque la mayor parte de la ganancia proviene de las consultas (debido a la gran cantidad de ellos en cualquier operación típica con nubes de puntos), también se ahorra algo de tiempo mientras se construye el índice de árbol KD, debido al código platizado, pero también para evitar la duplicación de los datos en una matriz auxiliar (tiempos en el siguiente dia
Estas pruebas de rendimiento solo son representativas de nuestras pruebas. Si desea repetirlos, lea las instrucciones en pruebas de perforación
Nota: El logotipo del proyecto se debe a cedrar
Colaboradores


