mdb search
1.0.0
TL; DR: Взломанное веб -приложение с бэкэнд Atlas MongoDB с использованием различных поисковых запросов.
Предложение отличного опыта поиска пользователей в приложениях может быть трудным, но не должно быть.
Это приложение объединяет несколько методов поиска, доступных в MongoDB, в эксплуатационном наборе данных фильмов. MongoDB-очень популярная база данных документов, известную своей мощной транзакционной и аналитической способностью по структурированным и полуструктурированным данным в структуре, подобной JSON. Добавление поиска актуальности и семантического поиска вектора на той же платформе и языке запросов очень прост и прост в использовании, без особой сложности. В качестве векторной базы данных, теперь она также хранит неструктурированные данные, такие как текст, изображения или аудио, в векторных встраиваниях (высокомерные векторы), чтобы облегчить его поиск и получение аналогичных объектов.
MongoDB ),Lucene ),text-embedding-ada-002 ),clip-ViT-B-32 ), Поиск атласа обеспечивает возможности поиска и оценки релевантности на основе индексов Lucene с открытым исходным кодом. Здесь я использую его для поиска соответствующих фильмов с языковой поддержкой и коррекцией опечатки. 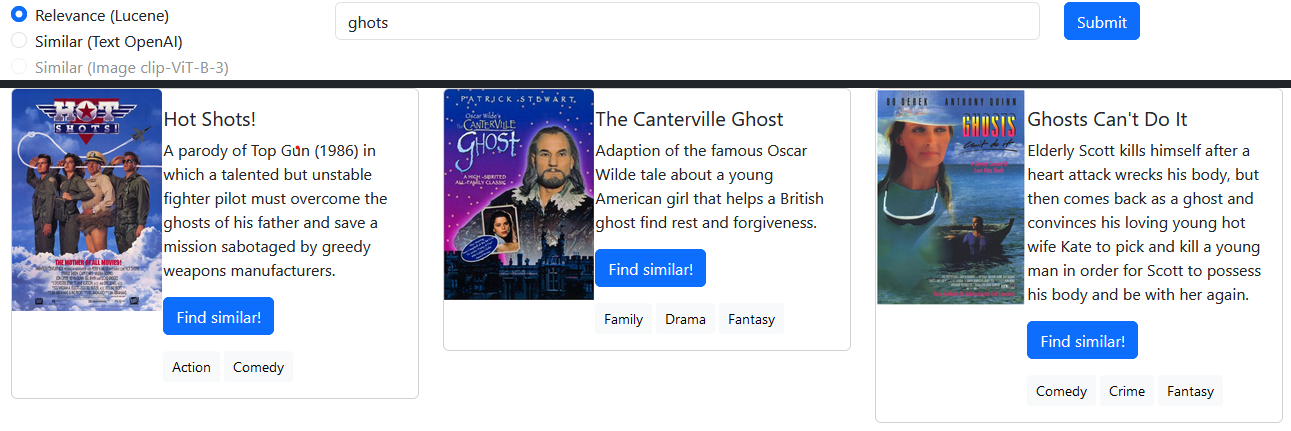
Текстовый сюжет каждого фильма проходит через API встраивания Openai, и эти text-embedding-ada-002 хранятся в MongoDB. Подсказка пользователя встроена и используется для запроса в векторной базе данных для аналогичного контента. Вы можете искать либо на своем вводе, либо выполнять поиск сходства на основе существующего сюжета фильма. 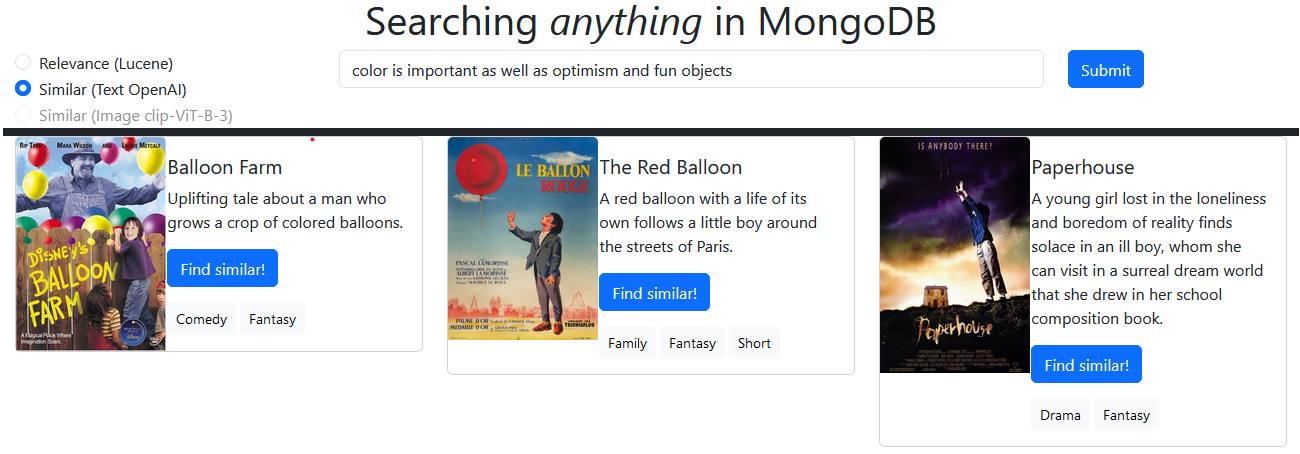
Изображение плаката каждого фильма интерпретируется clip-ViT-B-32 . Эти картинки хранятся в MongoDB. Пользователь может найти фильмы с изображениями постера, которые похожи на их запрос. 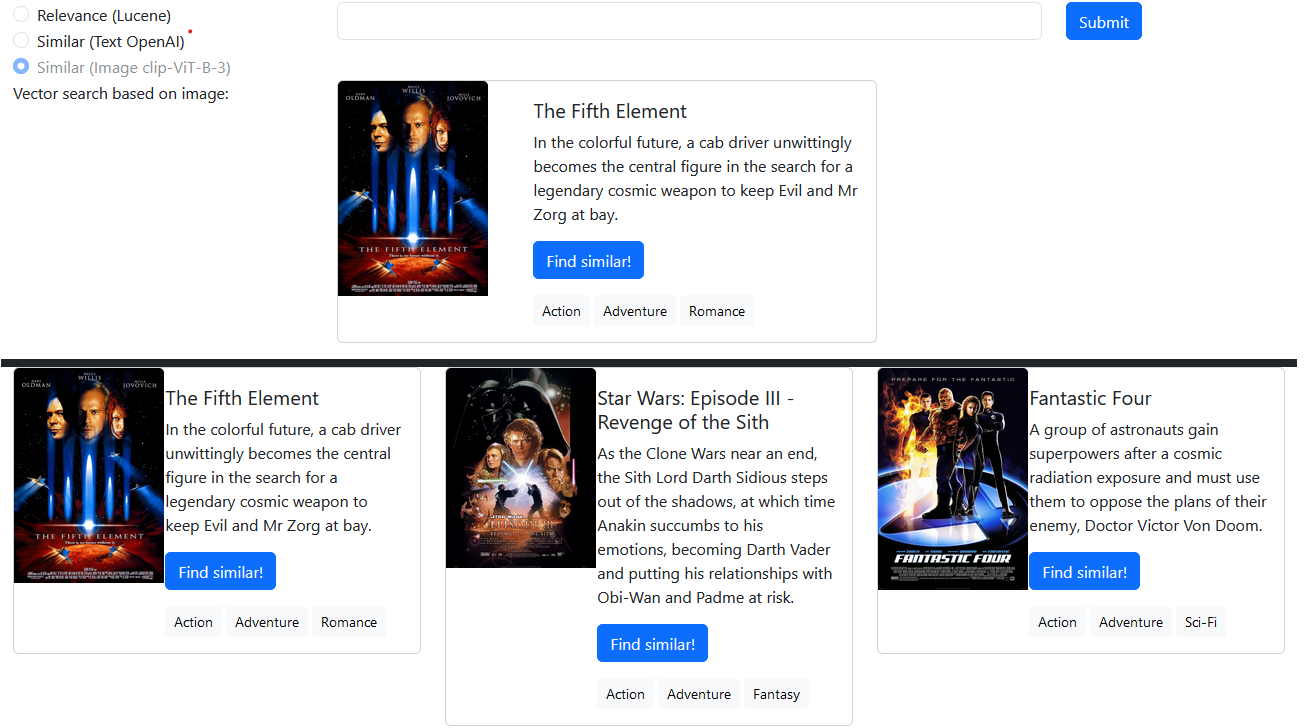
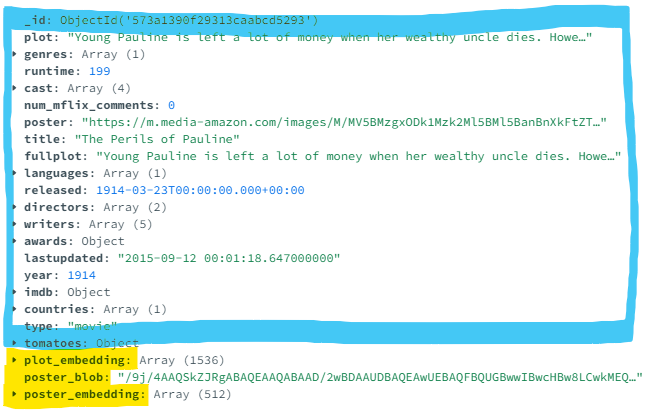
Структура документа выглядит следующим образом. В синем у вас есть поля, вложенные объекты и массивы с эксплуатационными данными. Синий запрашивается с помощью поиска в базе данных и поиска по поиску атласа. Этот проект добавляет поля в желтом цвете: представление Base64 плаката фильма, встроения текста ADA Openai и встроенные изображения, запрашиваемые поиском Vector Atlas.
Вам нужен python3 и pip .
python3 --version
python3 -m ensurepip --upgrade
pip3 install -r requirements.txt
Вам нужен кластер MongoDB Atlas . Это может быть бесплатный кластер, созданный на Cloud.mongodb.com. Убедитесь, что доступ к базе данных и доступ к сети позволяет вам подключить к базе данных. Примечание бесплатные кластеры имеют ограничение размера и производительности, не стесняйтесь запускать это на небольшом платном кластере с большим количеством данных.
Вам нужно установить некоторые локальные переменные среды. .env .env.example
MDB_CONN=<YOUR MongoDB Atlas connection string>
DB="sample_mflix"
COLL="embedded_movies"
OPENAI_API_KEY=<YOUR OpenAI API key>
Клонировать MDB-Search-Data Repo.
Там вам предлагаются 2 варианта: восстановление из резервного копирования или создание встроений сами на местном уровне. Восстановление из резервного копирования занимает менее 1 минуты.
В Search tab в Атласе введите следующую конфигурацию JSON. Используйте имя индекса default и убедитесь, что для создания его в коллекции embedded_movies . Это магия, которая позволит динамический полный текстовый поиск на полях, а также включить индексы поиска в вектор. Копия данных не требуется: o
{
"mappings": {
"dynamic": true,
"fields": {
"plot_embedding": {
"dimensions": 1536,
"similarity": "cosine",
"type": "knnVector"
},
"poster_embedding": {
"dimensions": 512,
"similarity": "cosine",
"type": "knnVector"
}
}
}
}
Это Flask Python3 Web-App.
Запустите приложение Flask, как это
flask --app app run
Или с помощником просто используйте Python, как это
python app.py
Вы можете получить доступ к веб -приложению по адресу http://localhost:8080 .
Теперь вы можете:
Доверьтесь ML и модели встраивания. Можете ли вы угадать, почему эти картинки похожи?


