mdb search
1.0.0
TL; DR: Aplikasi web yang diretas bersama dengan backend atlas MongoDB menggunakan pertanyaan pencarian yang berbeda.
Menawarkan pengalaman pencarian pengguna yang hebat dalam aplikasi bisa jadi sulit, tetapi tidak perlu.
Aplikasi ini menggabungkan beberapa teknik pencarian yang tersedia di MongoDB pada dataset film operasional. MongoDB adalah basis data dokumen yang sangat populer yang dikenal dengan kemampuan transaksional dan analitik yang kuat pada data terstruktur dan semi-terstruktur dalam struktur seperti JSON. Penambahan pencarian relevansi dan pencarian vektor semantik dalam platform yang sama dan bahasa kueri sangat mudah dan mudah digunakan, tanpa banyak kompleksitas. Sebagai database vektor, sekarang juga menyimpan data yang tidak terstruktur seperti teks, gambar, atau audio, dalam embeddings vektor (vektor dimensi tinggi) untuk memudahkan untuk menemukan dan mengambil objek serupa dengan cepat.
MongoDB ),Lucene ),text-embedding-ada-002 ),clip-ViT-B-32 ), Pencarian Atlas memungkinkan kemampuan pencarian dan penilaian relevansi berdasarkan indeks Lucene open-source. Di sini, saya menggunakannya untuk mencari film yang relevan dengan dukungan bahasa dan koreksi kesalahan ketik. 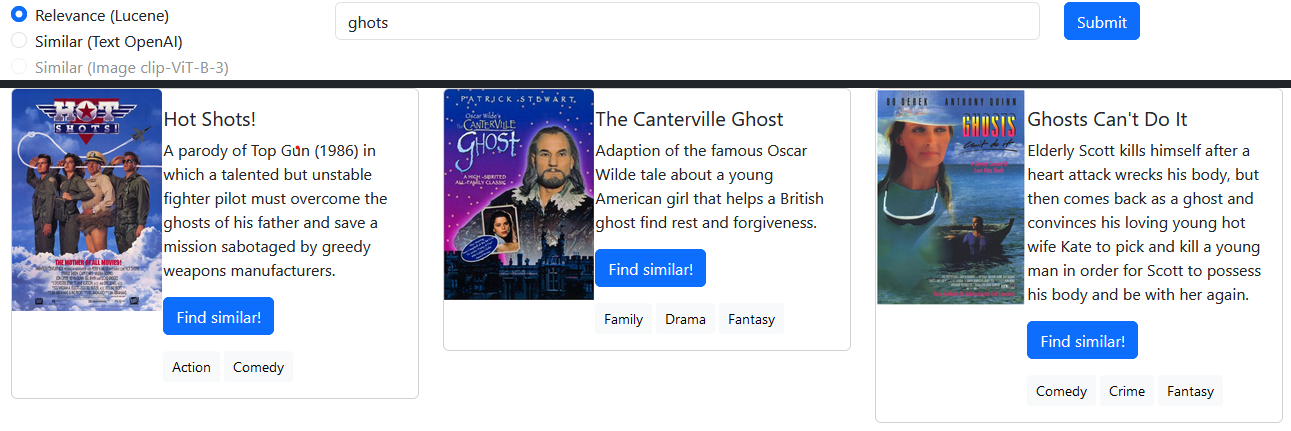
Plot teks masing-masing film dijalankan melalui embedding embedding Openai dan embeddings text-embedding-ada-002 itu disimpan di MongoDB. Prompt pengguna tertanam dan digunakan untuk meminta dalam database vektor untuk konten serupa. Anda dapat mencari di input Anda, atau melakukan pencarian kesamaan berdasarkan plot film yang ada. 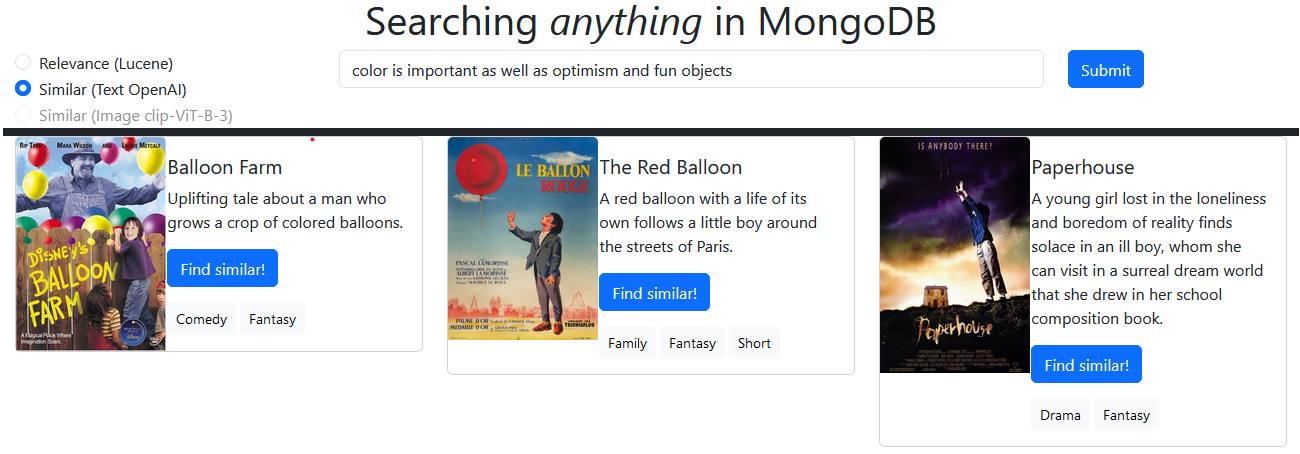
Gambar poster setiap film ditafsirkan oleh clip-ViT-B-32 . Embeddings gambar itu disimpan di MongoDB. Pengguna dapat menemukan film dengan gambar poster yang mirip dengan kueri mereka. 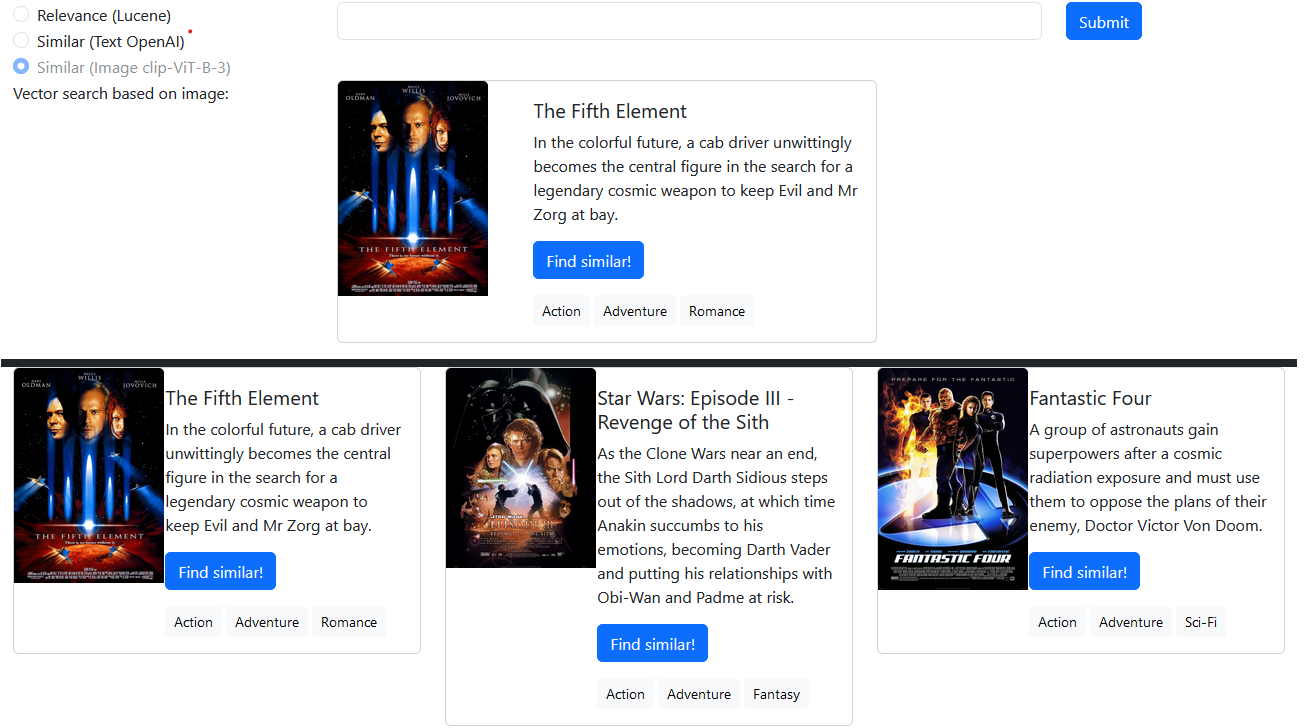
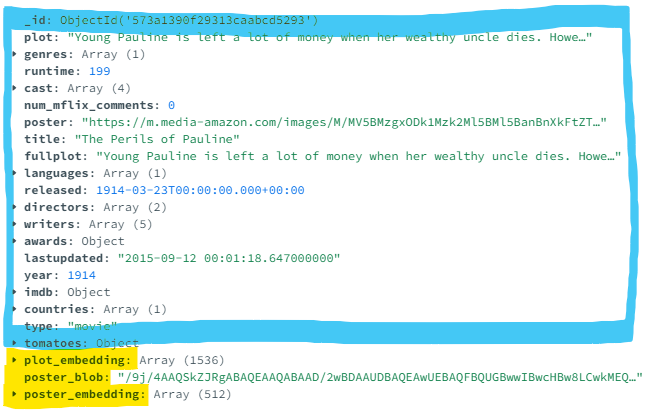
Struktur dokumen terlihat sebagai berikut. Dengan warna biru Anda memiliki bidang, benda dan array bersarang dengan data operasional. Biru ditanya dengan pencarian database dan pencarian relevansi pencarian atlas. Proyek ini menambahkan bidang dengan warna kuning: representasi base64 dari poster film, embeddings teks terbuka dan embeddings clip image, ditanya dengan pencarian vektor atlas.
Anda membutuhkan python3 dan pip .
python3 --version
python3 -m ensurepip --upgrade
pip3 install -r requirements.txt
Anda memerlukan cluster MongoDB Atlas . Ini bisa menjadi cluster gratis, dibuat di cloud.mongodb.com. Pastikan akses database dan akses jaringan memungkinkan Anda untuk membuat koneksi ke database. Catatan Cluster Gratis memiliki batasan ukuran dan kinerja, jangan ragu untuk menjalankan ini pada cluster berbayar kecil dengan lebih banyak data.
Anda perlu mengatur beberapa variabel lingkungan lokal. Template adalah .env.example yang dapat Anda salin ke file .env lokal Anda.
MDB_CONN=<YOUR MongoDB Atlas connection string>
DB="sample_mflix"
COLL="embedded_movies"
OPENAI_API_KEY=<YOUR OpenAI API key>
Klone repo MDB-Search-Data.
Di sana Anda ditawari 2 opsi: memulihkan dari cadangan atau menghasilkan embeddings sendiri secara lokal. Memulihkan dari cadangan membutuhkan waktu kurang dari 1 menit.
Di Atlas, di Search tab tampilan cluster, masukkan konfigurasi JSON berikut. Gunakan nama indeks default dan pastikan untuk membuatnya di koleksi embedded_movies . Ini adalah keajaiban yang akan memungkinkan pencarian teks lengkap dinamis di bidang, serta mengaktifkan indeks pencarian vektor. Tidak ada salinan data yang diperlukan: o
{
"mappings": {
"dynamic": true,
"fields": {
"plot_embedding": {
"dimensions": 1536,
"similarity": "cosine",
"type": "knnVector"
},
"poster_embedding": {
"dimensions": 512,
"similarity": "cosine",
"type": "knnVector"
}
}
}
}
Ini adalah aplikasi web Python3 Flask.
Mulai aplikasi Flask seperti ini
flask --app app run
Atau dengan penolong, hanya menggunakan ular python seperti ini
python app.py
Anda dapat mengakses aplikasi web di http://localhost:8080 .
Anda sekarang bisa:
Percayai ML dan model embedding. Bisakah Anda menebak mengapa gambar -gambar ini serupa?


