mdb search
1.0.0
Tl; dr: um aplicativo hackeado da web com um back -end de atlas do MongoDB usando diferentes consultas de pesquisa.
Oferecer uma ótima experiência de pesquisa de usuário em aplicativos pode ser difícil, mas não precisa ser.
Este aplicativo combina várias técnicas de pesquisa disponíveis no MongoDB em um conjunto de dados operacionais de filmes. O MongoDB é um banco de dados de documentos muito popular, conhecido por seus poderosos recursos transacionais e analíticos em dados estruturados e semiestruturados em uma estrutura do tipo JSON. A adição de pesquisa de relevância e pesquisa vetorial semântica na mesma plataforma e linguagem de consulta é muito fácil e simples de usar, sem muita complexidade. Como um banco de dados vetorial, agora também armazena dados não estruturados, como texto, imagens ou áudio, em incorporações vetoriais (vetores de alta dimensão) para facilitar a localização e recuperação de objetos semelhantes rapidamente.
MongoDB ),Lucene ),text-embedding-ada-002 ),clip-ViT-B-32 ), A busca no ATLAS permite a pesquisa de relevância e os recursos de pontuação com base nos índices Lucene de código aberto. Aqui, eu o uso para pesquisar filmes relevantes com suporte ao idioma e correção de digitação. 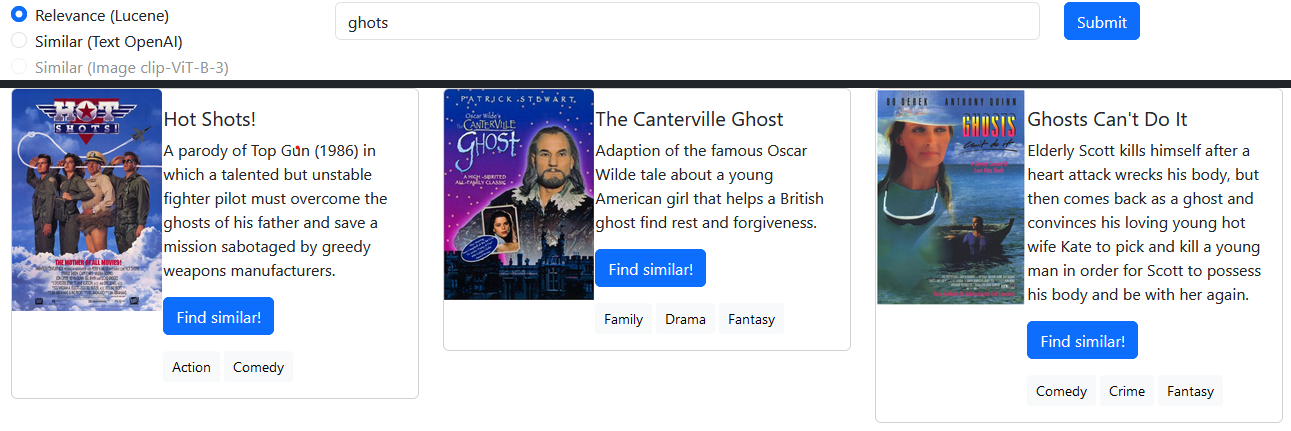
O enredo de texto de cada filme é executado pela API de incorporação do OpenAI e aquelas incorporações text-embedding-ada-002 são armazenadas em MongoDB. O prompt do usuário é incorporado e usado para consultar o banco de dados vetorial para conteúdo semelhante. Você pode pesquisar em sua entrada ou fazer uma pesquisa de similaridade com base no enredo de um filme existente. 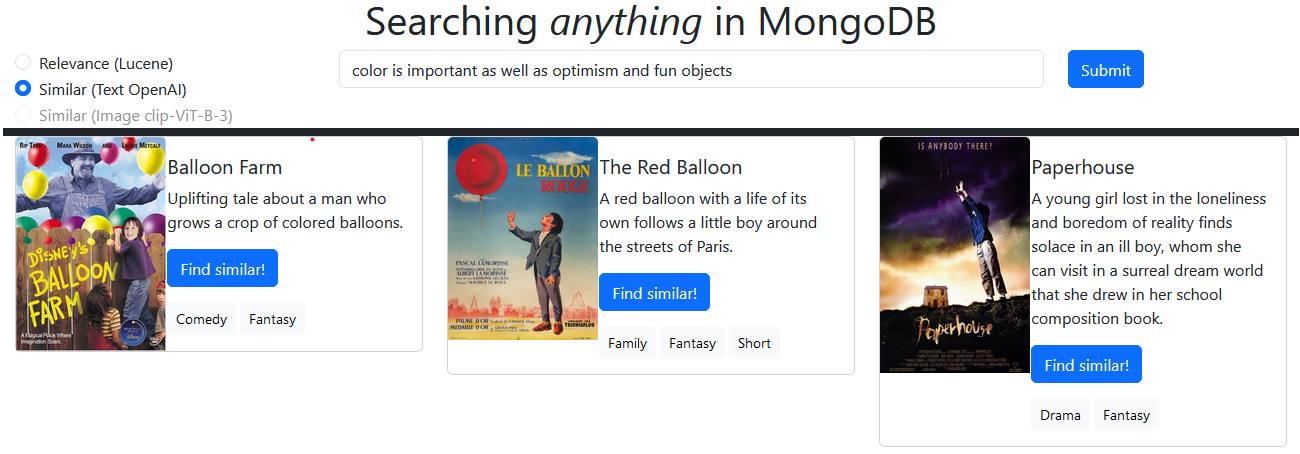
A imagem do pôster de cada filme é interpretada pelo clip-ViT-B-32 . Essas incorporações de imagem são armazenadas em MongoDB. O usuário pode encontrar filmes com imagens de pôsteres semelhantes à sua consulta. 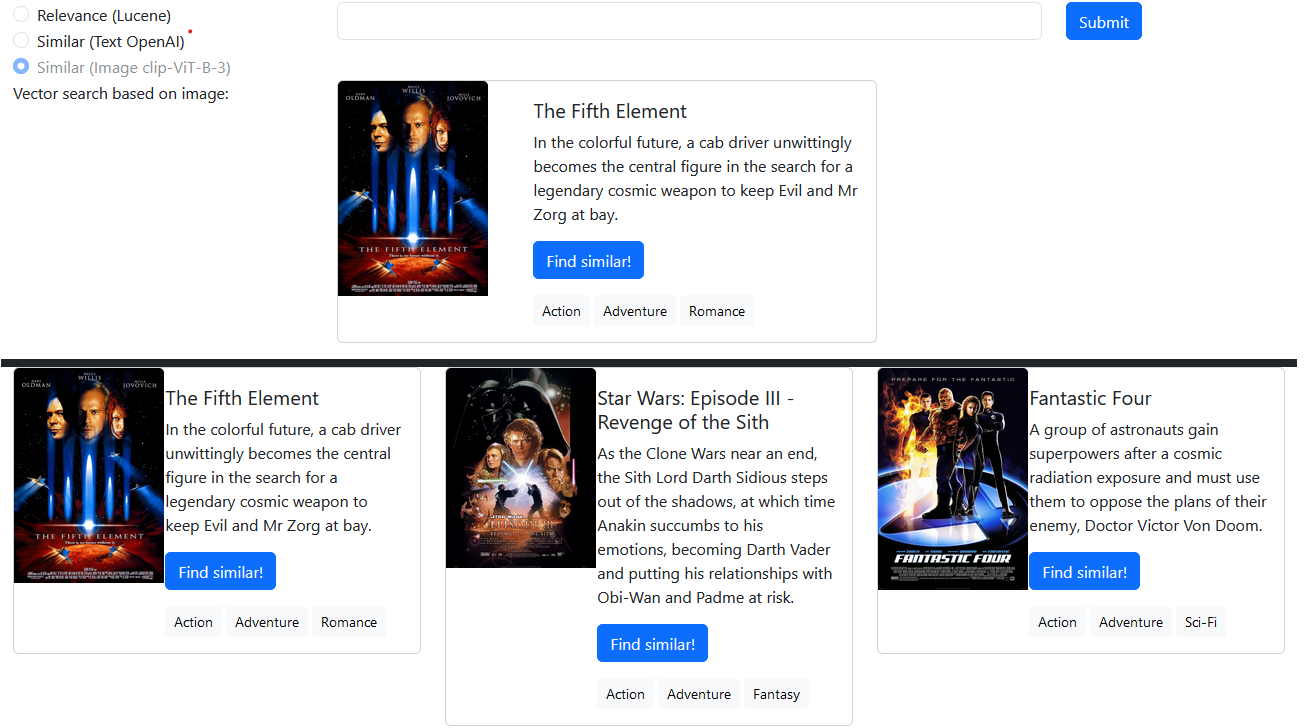
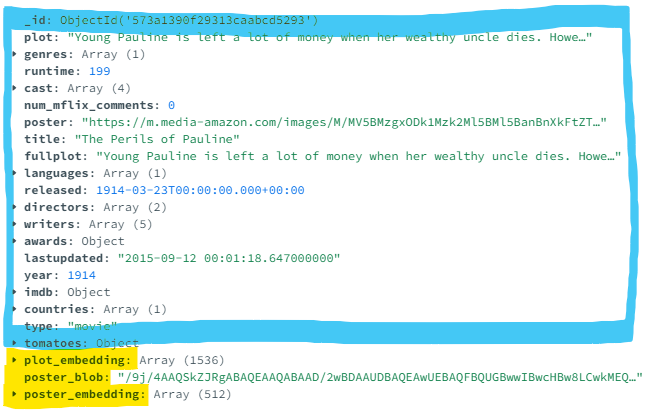
A estrutura do documento parece a seguir. Em azul, você tem os campos, objetos aninhados e matrizes com dados operacionais. O azul é consultado com a pesquisa de banco de dados e a pesquisa de relevância da Pesquisa de Atlas. Esses projetos adicionam os campos em amarelo: uma representação Base64 do pôster do filme, incorporações de textos ADA OpenAI e incorporação de imagem de clipes, consultada com a busca de vetores do Atlas.
Você precisa de python3 e pip .
python3 --version
python3 -m ensurepip --upgrade
pip3 install -r requirements.txt
Você precisa de um cluster MongoDB Atlas . Este pode ser um cluster gratuito, criado no cloud.mongodb.com. Verifique se o acesso ao banco de dados e o acesso à rede permite fazer uma conexão com o banco de dados. Nota Os clusters gratuitos têm uma limitação de tamanho e desempenho, fique à vontade para executá -lo em um pequeno cluster pago com muito mais dados.
Você precisa definir algumas variáveis de ambiente local. O modelo é .env.example que você pode copiar para o seu arquivo .env local.
MDB_CONN=<YOUR MongoDB Atlas connection string>
DB="sample_mflix"
COLL="embedded_movies"
OPENAI_API_KEY=<YOUR OpenAI API key>
Clone o repo MDB-Search-Data.
Lá, você recebe duas opções: restaurando de backup ou geração de incorporação localmente. A restauração do backup leva menos de 1 minuto.
No Atlas, na Search tab visualização do cluster, digite a seguinte configuração JSON. Use o nome do índice default e certifique -se de criá -lo na coleção embedded_movies . Esta é a mágica que permitirá a pesquisa dinâmica de texto completo nos campos, além de permitir os índices de pesquisa vetorial. Nenhuma cópia de dados necessária: O
{
"mappings": {
"dynamic": true,
"fields": {
"plot_embedding": {
"dimensions": 1536,
"similarity": "cosine",
"type": "knnVector"
},
"poster_embedding": {
"dimensions": 512,
"similarity": "cosine",
"type": "knnVector"
}
}
}
}
Este é um aplicativo web python3 de frasco.
Inicie o aplicativo Flask como este
flask --app app run
Ou com um ajudante, basta usar python como este
python app.py
Você pode acessar o aplicativo da web em http://localhost:8080 .
Você pode agora:
Confie no ML e no modelo de incorporação. Você consegue adivinhar por que essas fotos são semelhantes?


