mosec
0.9.0

![]()
A porção de modelo tornada eficiente na nuvem.
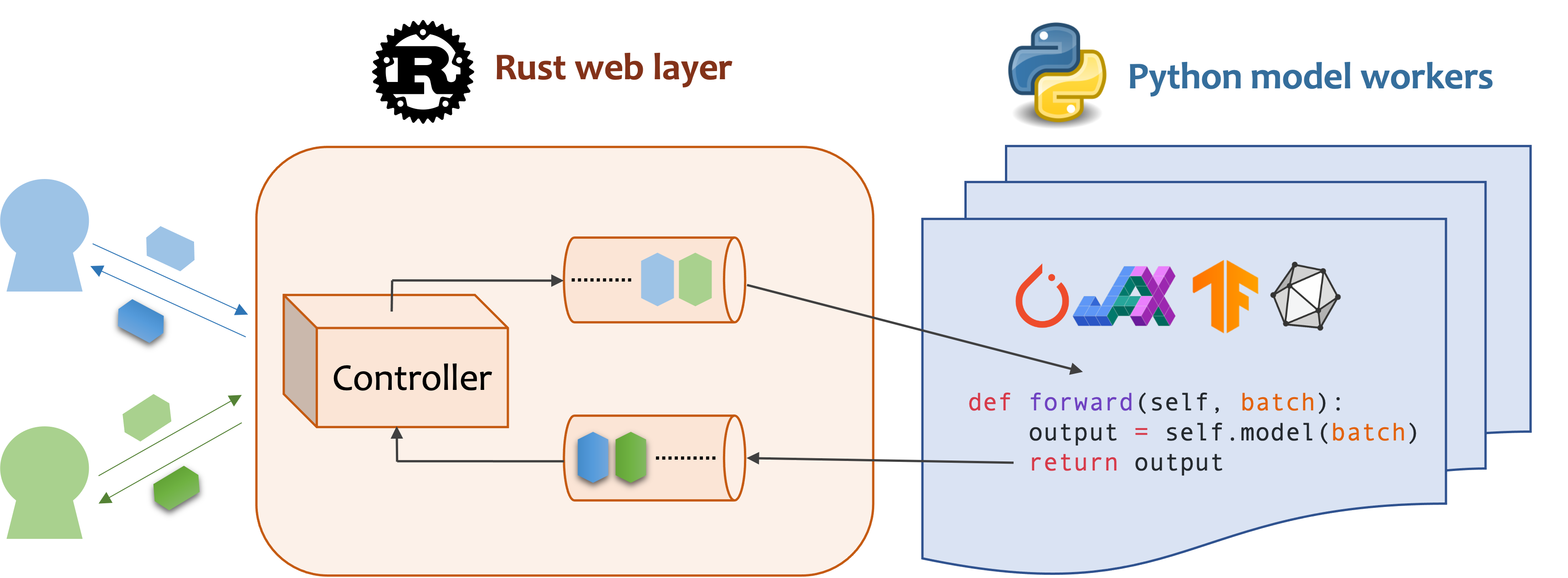
O MOSEC é uma estrutura de atendimento de modelo de alto desempenho e flexível para a criação de back-end e microsserviços habilitados para modelos ML. Ele preenche a lacuna entre os modelos de aprendizado de máquina que você acabou de treinar e a eficiente API de serviço on -line.
O MOSEC requer Python 3.7 ou superior. Instale o pacote Pypi mais recente para Linux X86_64 ou MacOS x86_64/ARM64 com:
pip install -U mosec
# or install with conda
conda install conda-forge::mosecPara construir a partir do código -fonte, instale a ferrugem e execute o seguinte comando:
make package Você receberá um arquivo de roda MOSEC na pasta dist .
Demonstramos como o MOSEC pode ajudá-lo a hospedar facilmente um modelo de difusão estável pré-treinado como um serviço. Você precisa instalar difusores e transformadores como pré -requisitos:
pip install --upgrade diffusers[torch] transformersEm primeiro lugar, importamos as bibliotecas e configuramos um madeireiro básico para observar melhor o que acontece.
from io import BytesIO
from typing import List
import torch # type: ignore
from diffusers import StableDiffusionPipeline # type: ignore
from mosec import Server , Worker , get_logger
from mosec . mixin import MsgpackMixin
logger = get_logger ()Em seguida, criamos uma API para os clientes consultar um prompt de texto e obter uma imagem com base no modelo estável difusão-v1-5 em apenas 3 etapas.
Defina seu serviço como uma classe que herda mosec.Worker . Aqui também herdamos MsgpackMixin para empregar o formato de serialização do MSGPACK (A) .
Dentro do método __init__ , inicialize seu modelo e coloque -o no dispositivo correspondente. Opcionalmente, você pode atribuir self.example com alguns dados para aquecer (b) o modelo. Observe que os dados devem ser compatíveis com o formato de entrada do seu manipulador, que detalhamos a seguir.
Substitua o método forward para escrever seu manipulador de serviço (c) , com a assinatura forward(self, data: Any | List[Any]) -> Any | List[Any] . Receber/retornar um único item ou uma tupla depende se está configurado em lote dinâmico (d) .
class StableDiffusion ( MsgpackMixin , Worker ):
def __init__ ( self ):
self . pipe = StableDiffusionPipeline . from_pretrained (
"sd-legacy/stable-diffusion-v1-5" , torch_dtype = torch . float16
)
self . pipe . enable_model_cpu_offload ()
self . example = [ "useless example prompt" ] * 4 # warmup (batch_size=4)
def forward ( self , data : List [ str ]) -> List [ memoryview ]:
logger . debug ( "generate images for %s" , data )
res = self . pipe ( data )
logger . debug ( "NSFW: %s" , res [ 1 ])
images = []
for img in res [ 0 ]:
dummy_file = BytesIO ()
img . save ( dummy_file , format = "JPEG" )
images . append ( dummy_file . getbuffer ())
return images[!OBSERVAÇÃO]
(a) Neste exemplo, retornamos uma imagem no formato binário, que o JSON não suporta (a menos que codificado com base64 que aumente a carga útil). Portanto, o msgpack combina com a nossa necessidade melhor. Se não herdarmos
MsgpackMixin, o JSON será usado por padrão. Em outras palavras, o protocolo da solicitação/resposta de serviço pode ser msgpack, json ou qualquer outro formato (verifique nossos mixins).(b) O aquecimento geralmente ajuda a alocar a memória da GPU com antecedência. Se o exemplo de aquecimento for especificado, o serviço só estará pronto depois que o exemplo for encaminhado através do manipulador. No entanto, se nenhum exemplo for dado, a latência da primeira solicitação deverá ser mais longa. O
exampledeve ser definido como um único item ou uma tupla, dependendo do queforwardespera receber. Além disso, no caso em que você deseja se aquecer com vários exemplos diferentes, você pode definirmulti_examples(demonstração aqui).(c) Este exemplo mostra um serviço de estágio único, onde o trabalhador
StableDiffusionrecebe diretamente a solicitação de prompt do cliente e responde à imagem. Assim, oforwardpode ser considerado como um manipulador de serviço completo. No entanto, também podemos projetar um serviço de vários estágios com trabalhadores fazendo trabalhos diferentes (por exemplo, baixando imagens, inferência de modelos, pós-processamento) em um pipeline. Nesse caso, todo o pipeline é considerado o manipulador de serviços, com o primeiro trabalhador recebendo a solicitação e o último trabalhador enviando a resposta. O fluxo de dados entre os trabalhadores é feito pela comunicação entre processos.(d) Como o lote dinâmico é ativado neste exemplo, o método
forwardreceberá uma lista de string, por exemplo,['a cute cat playing with a red ball', 'a man sitting in front of a computer', ...], agregado de diferentes clientes para inferência em lote , melhorando o título do sistema.
Finalmente, anexamos o trabalhador ao servidor para construir um fluxo de trabalho de estágio único (vários estágios podem ser pipelados para aumentar ainda mais a taxa de transferência, consulte este exemplo) e especificamos o número de processos que queremos que ele seja executado em paralelo ( num=1 ) e o tamanho máximo de lotes ( max_batch_size=4 , o max_wait_time=10 Em milissegundos, o que significa o mais tempo que Mosec espera até enviar o lote para o trabalhador).
if __name__ == "__main__" :
server = Server ()
# 1) `num` specifies the number of processes that will be spawned to run in parallel.
# 2) By configuring the `max_batch_size` with the value > 1, the input data in your
# `forward` function will be a list (batch); otherwise, it's a single item.
server . append_worker ( StableDiffusion , num = 1 , max_batch_size = 4 , max_wait_time = 10 )
server . run ()Os trechos acima são mesclados em nosso arquivo de exemplo. Você pode ser executado diretamente no nível da raiz do projeto. Primeiro, damos os argumentos da linha de comando (explicações aqui):
python examples/stable_diffusion/server.py --helpEntão vamos iniciar o servidor com logs de depuração:
python examples/stable_diffusion/server.py --log-level debug --timeout 30000 Abra http://127.0.0.1:8000/openapi/swagger/ no seu navegador para obter o documento Openapi.
E em outro terminal, teste -o:
python examples/stable_diffusion/client.py --prompt " a cute cat playing with a red ball " --output cat.jpg --port 8000Você receberá uma imagem chamada "Cat.jpg" no diretório atual.
Você pode verificar as métricas:
curl http://127.0.0.1:8000/metricsÉ isso! Você acabou de hospedar seu modelo de difusão estável como um serviço!
Exemplos mais prontos para uso podem ser encontrados na seção Exemplo. Inclui:
max_batch_size e max_wait_time (millisecond) são configurados quando você chama append_worker .max_batch_size não causará a falta de memória na GPU.max_wait_time deve ser menor que o tempo de inferência em lote.max_batch_size ou quando max_wait_time tiver decorrido. O serviço se beneficiará desse recurso quando o tráfego estiver alto.mosec instalado, pode verificar a imagem oficial mosecorg/mosec . Para o caso de uso complexo, consulte o ENVD.mosec_service_batch_size_bucket mostra a distribuição do tamanho do lote.mosec_service_batch_duration_second_bucket mostra a duração do lote dinâmico para cada conexão em cada estágio (começa com o recebimento da primeira tarefa).mosec_service_process_duration_second_bucket mostra a duração do processamento para cada conexão em cada estágio (incluindo o tempo do IPC, mas excluindo o mosec_service_batch_duration_second_bucket ).mosec_service_remaining_task mostra o número de tarefas atualmente de processamento.mosec_service_throughput mostra a taxa de transferência de serviço.SIGINT ( CTRL+C ) ou SIGTERM ( kill {PID} ), pois possui a lógica de desligamento graciosa. max_batch_size e max_wait_time para o seu serviço de inferência. As métricas mostrarão os histogramas do tamanho real do lote e da duração do lote. Essas são as informações principais para ajustar esses dois parâmetros.serialize_ipc/deserialize_ipc , para que dados extremamente grandes possam tornar todo o pipeline lento. Os dados serializados são passados para o próximo estágio através da ferrugem por padrão, você pode permitir que a memória compartilhada reduza a latência (ref RedissHMipcMixin).serialize/deserialize adequados, que são usados para decodificar a solicitação do usuário e codificar a resposta. Por padrão, ambos estão usando o JSON. No entanto, imagens e incorporações não são bem suportadas pelo JSON. Você pode escolher o MSGPACK, que é mais rápido e compatível binário (refusão estável de ref).mosec se adapta automaticamente ao protocolo do usuário (por exemplo, http/2) desde a v0.8.8. Aqui estão algumas das empresas e usuários individuais que estão usando o MOSEC:
Se você achar este software útil para sua pesquisa, considere citar
@software{yang2021mosec,
title = {{MOSEC: Model Serving made Efficient in the Cloud}},
author = {Yang, Keming and Liu, Zichen and Cheng, Philip},
url = {https://github.com/mosecorg/mosec},
year = {2021}
}
Congratulamo -nos com qualquer tipo de contribuição. Por favor, dê -nos feedback levantando questões ou discutindo sobre a discórdia. Você também pode contribuir diretamente com o seu código e puxar a solicitação!
Para começar a se desenvolver, você pode usar o ENVD para criar um ambiente de Python & Rust isolado e limpo. Verifique o Envd-Docs ou Build.envd para obter mais informações.


