mosec
0.9.0

![]()
クラウドで効率的になったモデルサービング。
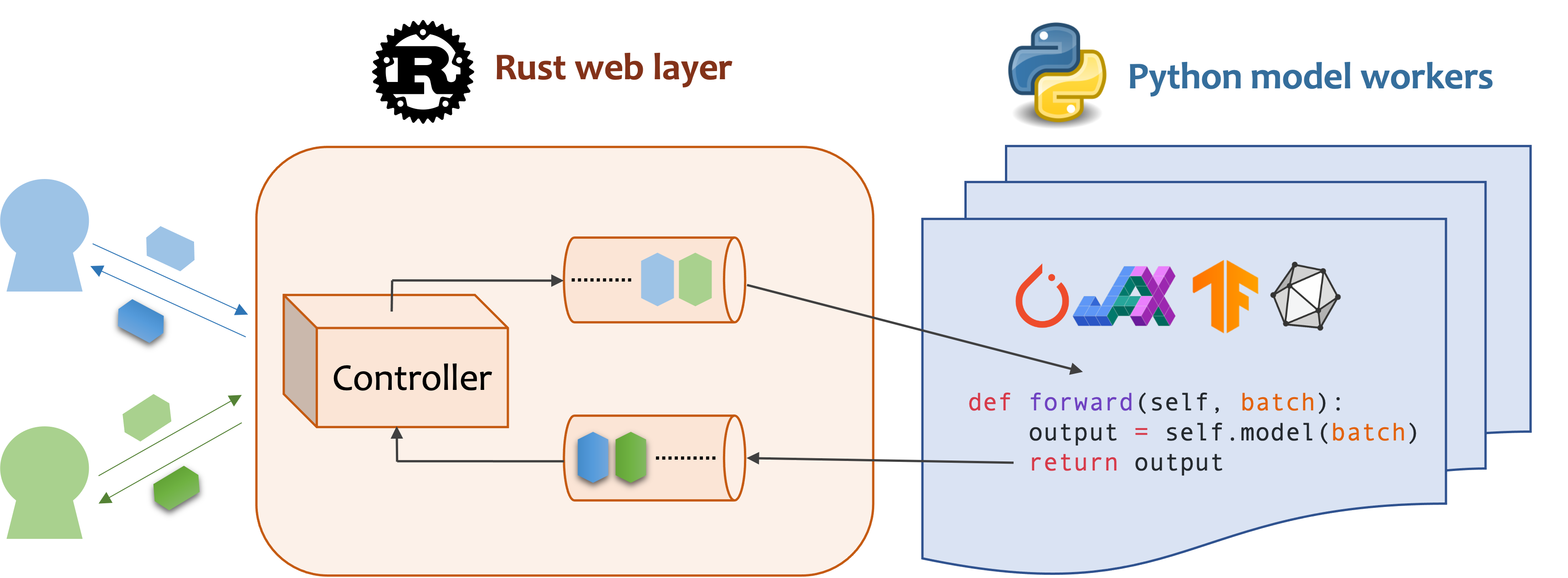
MOSECは、MLモデル対応のバックエンドとマイクロサービスを構築するための高性能で柔軟なモデルサービスフレームワークです。トレーニングしたばかりの機械学習モデルと、効率的なオンラインサービスAPIとの間のギャップを埋めます。
MOSECにはPython 3.7以上が必要です。 Linux x86_64またはmacos x86_64/arm64用の最新のPYPIパッケージを以下にインストールします。
pip install -U mosec
# or install with conda
conda install conda-forge::mosecソースコードからビルドするには、Rustをインストールして、次のコマンドを実行します。
make package distフォルダーにMOSECホイールファイルが取得されます。
MOSECがサービスとして事前に訓練された安定した拡散モデルを簡単にホストするのに役立つ方法を示します。ディフューザーと変圧器を前提条件としてインストールする必要があります。
pip install --upgrade diffusers[torch] transformersまず、ライブラリをインポートし、基本的なロガーを設定して、何が起こるかをよりよく観察します。
from io import BytesIO
from typing import List
import torch # type: ignore
from diffusers import StableDiffusionPipeline # type: ignore
from mosec import Server , Worker , get_logger
from mosec . mixin import MsgpackMixin
logger = get_logger ()次に、クライアントがテキストプロンプトを照会し、わずか3ステップで安定した拡散-V1-5モデルに基づいて画像を取得するためのAPIを構築します。
サービスをmosec.Workerを継承するクラスとして定義します。ここでは、 MsgpackMixinを継承して、MSGPACKシリアル化形式(a)を使用します。
__init__メソッド内で、モデルを初期化し、対応するデバイスに配置します。オプションで、いくつかのデータを使用してself.exampleを割り当てることができます(b)モデル。データは、ハンドラーの入力形式と互換性があることに注意してください。次に詳しく説明しています。
forwardメソッドをオーバーライドしてサービスハンドラー(c)を書き込み、署名forward(self, data: Any | List[Any]) -> Any | List[Any] 。単一のアイテムまたはタプルを受信/返すことは、動的バッチ(d)が構成されているかどうかによって異なります。
class StableDiffusion ( MsgpackMixin , Worker ):
def __init__ ( self ):
self . pipe = StableDiffusionPipeline . from_pretrained (
"sd-legacy/stable-diffusion-v1-5" , torch_dtype = torch . float16
)
self . pipe . enable_model_cpu_offload ()
self . example = [ "useless example prompt" ] * 4 # warmup (batch_size=4)
def forward ( self , data : List [ str ]) -> List [ memoryview ]:
logger . debug ( "generate images for %s" , data )
res = self . pipe ( data )
logger . debug ( "NSFW: %s" , res [ 1 ])
images = []
for img in res [ 0 ]:
dummy_file = BytesIO ()
img . save ( dummy_file , format = "JPEG" )
images . append ( dummy_file . getbuffer ())
return images[!注記]
(a)この例では、JSONはサポートしていないバイナリ形式で画像を返します(ペイロードを大きくするBase64でエンコードされていない限り)。したがって、msgpackは私たちのニーズに合っています。
MsgpackMixinを継承しない場合、JSONはデフォルトで使用されます。言い換えれば、サービス要求/応答のプロトコルは、MSGPACK、JSON、またはその他の形式のいずれかです(ミキシンを確認)。(b)ウォームアップは通常、GPUメモリを事前に割り当てるのに役立ちます。ウォームアップの例が指定されている場合、サービスは、例がハンドラーを介して転送された後にのみ準備が整います。ただし、例が指定されていない場合、最初のリクエストのレイテンシは長くなると予想されます。この
example、forwardが受信すると予想されるものに応じて、単一のアイテムまたはタプルとして設定する必要があります。さらに、複数の異なる例でウォームアップしたい場合は、multi_examplesを設定できます(ここにデモ)。(c)この例は、
StableDiffusionWorkerがクライアントの迅速な要求を直接撮影し、画像に応答する単一ステージサービスを示しています。したがって、forward完全なサービスハンドラーと見なすことができます。ただし、パイプラインで異なる仕事をしている労働者(例えば、画像のダウンロード、モデル推論、後処理)を行うマルチステージサービスを設計することもできます。この場合、パイプライン全体がサービスハンドラーと見なされ、最初の労働者がリクエストを取り入れ、最後の労働者が回答を送信します。労働者間のデータフローは、プロセス間通信によって行われます。(d)この例では動的バッチが有効になっているため、
forwardメソッドは、['a cute cat playing with a red ball', 'a man sitting in front of a computer', ...]、バッチ推論のためにさまざまなクライアントから集約され、システムのスループットを改善することを望んでいます。
最後に、ワーカーをサーバーに追加して、単一段階のワークフローを構築します(複数のステージをパイプ化してスループットをさらに高め、この例を参照してください)、並列で実行するプロセス数( num=1 max_wait_time=10 、および最大バッチサイズ( max_batch_size=4 、最大数のリクエスト数がマクチュアで蓄積されます。 Millisecondsは、Mosecがワーカーにバッチを送信するまで待機する最も長い時間を意味します)。
if __name__ == "__main__" :
server = Server ()
# 1) `num` specifies the number of processes that will be spawned to run in parallel.
# 2) By configuring the `max_batch_size` with the value > 1, the input data in your
# `forward` function will be a list (batch); otherwise, it's a single item.
server . append_worker ( StableDiffusion , num = 1 , max_batch_size = 4 , max_wait_time = 10 )
server . run ()上記のスニペットは、サンプルファイルにマージされています。プロジェクトルートレベルで直接実行できます。最初にコマンドラインの引数を見てみましょう(ここでの説明):
python examples/stable_diffusion/server.py --help次に、デバッグログでサーバーを開始しましょう。
python examples/stable_diffusion/server.py --log-level debug --timeout 30000 http://127.0.0.1:8000/openapi/swagger/ブラウザでOpenapi Docを取得することを開きます。
そして別の端末で、それをテストしてください:
python examples/stable_diffusion/client.py --prompt " a cute cat playing with a red ball " --output cat.jpg --port 8000現在のディレクトリに「cat.jpg」という名前の画像が表示されます。
メトリックを確認できます。
curl http://127.0.0.1:8000/metricsそれでおしまい!安定した拡散モデルをサービスとしてホストしました!
よりすぐに使用できる例は、セクションの例にあります。それは以下を含みます:
max_batch_sizeおよびmax_wait_time (millisecond)は、 append_workerを呼び出すときに構成されています。max_batch_size値を使用して、GPUのメモリ外の原因を引き起こさないようにしてください。max_wait_timeバッチ推論時間よりも短くする必要があります。max_batch_sizeに到達した場合、またはmax_wait_timeが経過したときのいずれかでバッチを収集します。トラフィックが高い場合、この機能はこの機能の恩恵を受けます。mosecがインストールされているGPUベース画像を探している場合は、公式画像mosecorg/mosecを確認できます。複雑なユースケースについては、Envdをご覧ください。mosec_service_batch_size_bucket 、バッチサイズの分布を表示します。mosec_service_batch_duration_second_bucket 、各段階の各接続の動的バッチの持続時間を表示します(最初のタスクの受信から始まります)。mosec_service_process_duration_second_bucket 、各段階の各接続の処理時間を表示します(IPC時間を含むが、 mosec_service_batch_duration_second_bucketを除く)。mosec_service_remaining_taskは、現在処理されているタスクの数が表示されます。mosec_service_throughput 、サービススループットを表示します。SIGINT ( CTRL+C )またはSIGTERM ( kill {PID} )でサービスを停止します。これは、優雅なシャットダウンロジックがあるためです。 max_batch_sizeとmax_wait_timeご覧ください。メトリックには、実際のバッチサイズとバッチ期間のヒストグラムが表示されます。これらは、これら2つのパラメーターを調整するための重要な情報です。serialize_ipc/deserialize_ipcメソッドによってシリアル化/降下されることに注意してください。そのため、非常に大きなデータがパイプライン全体を遅くする可能性があります。シリアル化されたデータは、デフォルトでRustを介して次の段階に渡されます。共有メモリが潜在的にレイテンシを減らすことができます(REF RedissHMIPCMIXIN)。serialize/deserializeメソッドを選択する必要があります。これは、ユーザー要求をデコードして応答をエンコードするために使用されます。デフォルトでは、両方ともJSONを使用しています。ただし、画像と埋め込みはJSONによって十分にサポートされていません。より高速でバイナリ互換性のあるMSGPackを選択できます(REF安定拡散)。mosec 、V0.8.8以降、ユーザーのプロトコル(例:HTTP/2)に自動的に適応します。 MOSECを使用している企業や個々のユーザーの一部は次のとおりです。
このソフトウェアがあなたの研究に役立つと思うなら、引用することを検討してください
@software{yang2021mosec,
title = {{MOSEC: Model Serving made Efficient in the Cloud}},
author = {Yang, Keming and Liu, Zichen and Cheng, Philip},
url = {https://github.com/mosecorg/mosec},
year = {2021}
}
あらゆる種類の貢献を歓迎します。問題を提起したり、不一致について話し合うことでフィードバックを与えてください。コードを直接紹介してリクエストをプルすることもできます!
開発を開始するには、Envdを使用して、孤立したクリーンなPython&Rust環境を作成できます。詳細については、envd-docsまたはbuild.envdを確認してください。


