mosec
0.9.0

![]()
Modèle de service rendu efficace dans le nuage.
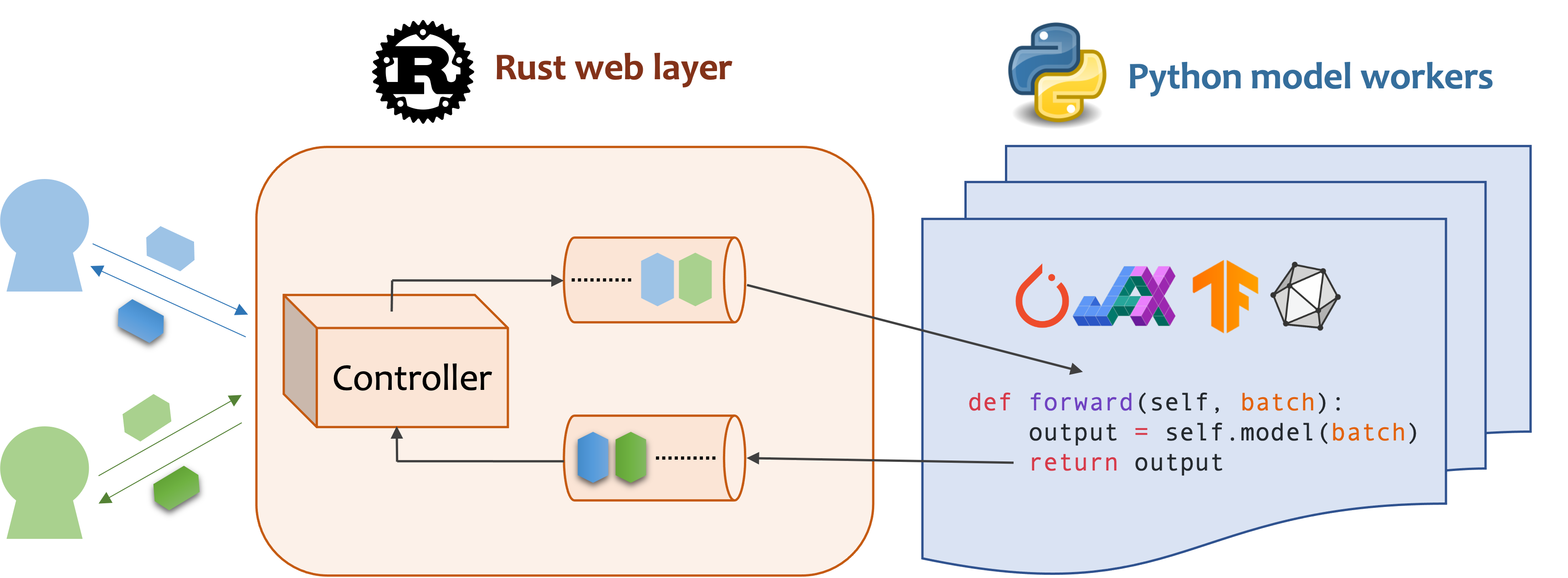
La MOSEC est un cadre de service de modèle haute performance et flexible pour la construction d'un backend et des microservices compatibles ML. Il comble l'écart entre tous les modèles d'apprentissage automatique que vous venez de former et l'API de service en ligne efficace.
MOSEC nécessite Python 3.7 ou plus. Installez le dernier package PYPI pour Linux x86_64 ou MacOS x86_64 / ARM64 avec:
pip install -U mosec
# or install with conda
conda install conda-forge::mosecPour construire à partir du code source, installez la rouille et exécutez la commande suivante:
make package Vous obtiendrez un fichier de roue MOSEC dans le dossier dist .
Nous démontrons comment la MOSEC peut vous aider à héberger facilement un modèle de diffusion stable pré-formé en tant que service. Vous devez installer des diffuseurs et des transformateurs comme condition préalable:
pip install --upgrade diffusers[torch] transformersPremièrement, nous importons les bibliothèques et créons un enregistreur de base pour mieux observer ce qui se passe.
from io import BytesIO
from typing import List
import torch # type: ignore
from diffusers import StableDiffusionPipeline # type: ignore
from mosec import Server , Worker , get_logger
from mosec . mixin import MsgpackMixin
logger = get_logger ()Ensuite, nous construisons une API pour que les clients interrogent une invite de texte et obtenons une image basée sur le modèle stable-diffusion-v1-5 en seulement 3 étapes.
Définissez votre service comme une classe qui hérite de mosec.Worker . Ici, nous héritons également de MsgpackMixin pour utiliser le format de sérialisation MSGPACK (A) .
À l'intérieur de la méthode __init__ , initialisez votre modèle et placez-le sur l'appareil correspondant. Éventuellement, vous pouvez affecter self.example avec certaines données pour échauffer (b) le modèle. Notez que les données doivent être compatibles avec le format d'entrée de votre gestionnaire, que nous détaillons ensuite.
Remplacez la méthode forward pour écrire votre gestionnaire de services (C) , avec la signature forward(self, data: Any | List[Any]) -> Any | List[Any] . La réception / renvoyer un seul élément ou un tuple dépend de la configuration du lot dynamique (d) .
class StableDiffusion ( MsgpackMixin , Worker ):
def __init__ ( self ):
self . pipe = StableDiffusionPipeline . from_pretrained (
"sd-legacy/stable-diffusion-v1-5" , torch_dtype = torch . float16
)
self . pipe . enable_model_cpu_offload ()
self . example = [ "useless example prompt" ] * 4 # warmup (batch_size=4)
def forward ( self , data : List [ str ]) -> List [ memoryview ]:
logger . debug ( "generate images for %s" , data )
res = self . pipe ( data )
logger . debug ( "NSFW: %s" , res [ 1 ])
images = []
for img in res [ 0 ]:
dummy_file = BytesIO ()
img . save ( dummy_file , format = "JPEG" )
images . append ( dummy_file . getbuffer ())
return images[!NOTER]
(a) Dans cet exemple, nous renvoyons une image dans le format binaire, que JSON ne prend pas en charge (sauf en codé avec Base64 qui rend la charge utile plus grande). Par conséquent, MSGPACK répond mieux à nos besoins. Si nous n'héritons pas
MsgpackMixin, JSON sera utilisé par défaut. En d'autres termes, le protocole de la demande / réponse de service peut être MSGPACK, JSON ou tout autre format (vérifiez nos mixins).(b) L'échauffement aide généralement à allouer la mémoire du GPU à l'avance. Si l'exemple d'échauffement est spécifié, le service ne sera prêt qu'après que l'exemple est transmis par le gestionnaire. Cependant, si aucun exemple n'est donné, la latence de la première demande devrait être plus longue. L'
exampledoit être défini en un seul élément ou un tuple en fonction de ceforwardprévoit de recevoir. De plus, dans le cas où vous souhaitez vous échauffer avec plusieurs exemples différents, vous pouvez définirmulti_examples(démo ici).(c) Cet exemple montre un service à un stade, où le travailleur
StableDiffusionprend directement la demande rapide du client et répond à l'image. Ainsi, l'forwardpeut être considéré comme un gestionnaire de services complet. Cependant, nous pouvons également concevoir un service à plusieurs étapes avec des travailleurs faisant différents travaux (par exemple, télécharger des images, inférence du modèle, post-traitement) dans un pipeline. Dans ce cas, l'ensemble du pipeline est considéré comme le gestionnaire de services, le premier travailleur prenant la demande et le dernier travailleur envoyant la réponse. Le flux de données entre les travailleurs est effectué par communication inter-processus.(d) Étant donné que le lot dynamique est activé dans cet exemple, la méthode
forwardrecevra avec une liste de chaîne, par exemple,['a cute cat playing with a red ball', 'a man sitting in front of a computer', ...], agrégé à partir de différents clients pour l'inférence par lots , améliorant le débit du système.
Enfin, nous ajoutons le travailleur au serveur pour construire un flux de travail à un étage (plusieurs étapes peuvent être pipelidées pour augmenter davantage le débit, voir cet exemple) et spécifier le nombre de processus que nous voulons qu'il exécute en parallèle ( num=1 max_wait_time=10 , et la taille maximale du lot ( max_batch_size=4 , le nombre maximum de demandes de lots de requins) Des millisecondes, ce qui signifie que le plus longtemps Mosec attend jusqu'à envoyer le lot au travailleur).
if __name__ == "__main__" :
server = Server ()
# 1) `num` specifies the number of processes that will be spawned to run in parallel.
# 2) By configuring the `max_batch_size` with the value > 1, the input data in your
# `forward` function will be a list (batch); otherwise, it's a single item.
server . append_worker ( StableDiffusion , num = 1 , max_batch_size = 4 , max_wait_time = 10 )
server . run ()Les extraits ci-dessus sont fusionnés dans notre exemple de fichier. Vous pouvez dire directement au niveau des racines du projet. Nous avons d'abord un œil aux arguments de la ligne de commande (explications ici):
python examples/stable_diffusion/server.py --helpCommençons ensuite le serveur avec des journaux de débogage:
python examples/stable_diffusion/server.py --log-level debug --timeout 30000 Ouvrez http://127.0.0.1:8000/openapi/swagger/ dans votre navigateur pour obtenir le doc openapi.
Et dans un autre terminal, testez-le:
python examples/stable_diffusion/client.py --prompt " a cute cat playing with a red ball " --output cat.jpg --port 8000Vous obtiendrez une image nommée "cat.jpg" dans le répertoire actuel.
Vous pouvez vérifier les mesures:
curl http://127.0.0.1:8000/metricsC'est ça! Vous venez d'héberger votre modèle de diffusion stable en tant que service!
D'autres exemples prêts à l'emploi peuvent être trouvés dans la section Exemple. Il comprend:
max_batch_size et max_wait_time (millisecond) sont configurés lorsque vous appelez append_worker .max_batch_size ne provoquera pas la mémoire hors de la mémoire dans GPU.max_wait_time devrait être inférieur au temps d'inférence par lots.max_batch_size ou lorsque max_wait_time s'est écoulé. Le service bénéficiera de cette fonctionnalité lorsque le trafic est élevé.mosec installée, vous pouvez vérifier l'image officielle mosecorg/mosec . Pour le cas d'utilisation complexe, consultez EnvD.mosec_service_batch_size_bucket Affiche la distribution de la taille du lot.mosec_service_batch_duration_second_bucket montre la durée du lot dynamique pour chaque connexion à chaque étape (commence par la réception de la première tâche).mosec_service_process_duration_second_bucket Affiche la durée du traitement pour chaque connexion à chaque étape (y compris le temps IPC mais à l'exclusion du mosec_service_batch_duration_second_bucket ).mosec_service_remaining_task Affiche le nombre de tâches de traitement actuellement.mosec_service_throughput montre le débit de service.SIGINT ( CTRL+C ) ou SIGTERM ( kill {PID} ) car il a la logique d'arrêt gracieuse. max_batch_size et max_wait_time pour votre service d'inférence. Les métriques montreront les histogrammes de la taille réelle du lot et de la durée du lot. Ce sont les informations clés pour ajuster ces deux paramètres.serialize_ipc/deserialize_ipc , donc des données extrêmement grandes peuvent rendre le pipeline entier lent. Les données sérialisées sont passées à l'étape suivante par Rust par défaut, vous pouvez permettre à la mémoire partagée de réduire potentiellement la latence (ref Redisshmipcmixin).serialize/deserialize , qui sont utilisées pour décoder la demande de l'utilisateur et coder la réponse. Par défaut, les deux utilisent JSON. Cependant, les images et les intérêts ne sont pas bien pris en charge par JSON. Vous pouvez choisir MSGPACK qui est plus rapide et compatible binaire (réfusion de référence stable).mosec s'adapte automatiquement au protocole de l'utilisateur (par exemple, HTTP / 2) depuis V0.8.8. Voici certaines des entreprises et des utilisateurs individuels qui utilisent la MOSEC:
Si vous trouvez ce logiciel utile pour vos recherches, veuillez envisager de citer
@software{yang2021mosec,
title = {{MOSEC: Model Serving made Efficient in the Cloud}},
author = {Yang, Keming and Liu, Zichen and Cheng, Philip},
url = {https://github.com/mosecorg/mosec},
year = {2021}
}
Nous accueillons toute sorte de contribution. Veuillez nous donner des commentaires en soulevant des problèmes ou en discutant de Discord. Vous pouvez également contribuer directement votre code et une demande de traction!
Pour commencer à développer, vous pouvez utiliser ENVD pour créer un environnement Python et Rust isolé et propre. Vérifiez les EnvD-Docs ou Build.envd pour plus d'informations.


