e2 tts mlx
v0.0.6
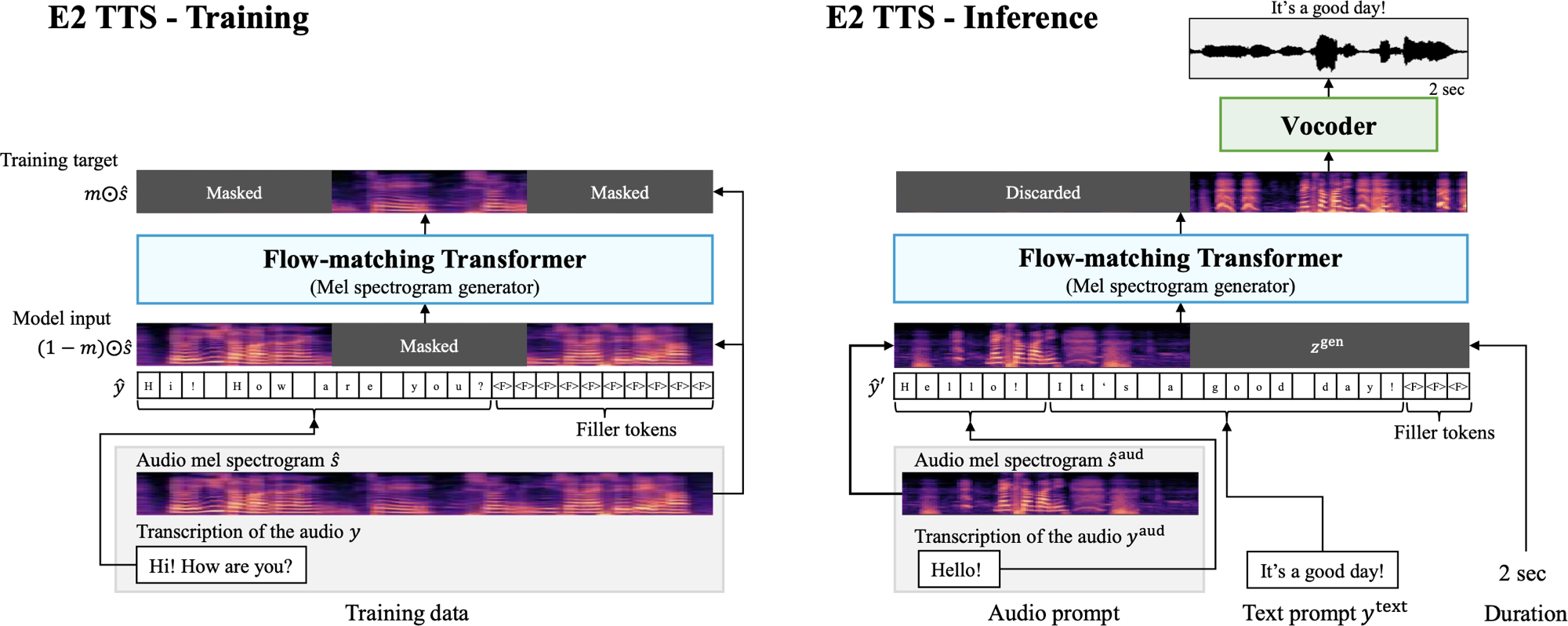
Implementação de E2-TTS, embaraçosamente fácil TTS com tiro zero totalmente não-autorregressivo, com a estrutura MLX.
O E2 TTS é um sistema de texto para fala zero e não autorregressivo que simplifica o pipeline TTS típico usando um gerador de espectrograma MEL de correspondência de fluxo treinado em uma tarefa de preenchimento de áudio mascarada, sem a necessidade de informações de alinhamento no nível do quadro.
Essa implementação é baseada na implementação do Lucidrains em Pytorch, que difere do artigo, pois usa um transformador multistristream para texto e áudio, com o condicionamento feito em todos os blocos de transformadores.
pip install mlx-e2-tts import mlx . core as mx
from e2_tts_mlx . model import E2TTS
from e2_tts_mlx . trainer import E2Trainer
from e2_tts_mlx . data import load_libritts_r
e2tts = E2TTS (
tokenizer = "char-utf8" , # or "phoneme_en" / callable
cond_drop_prob = 0.25 ,
frac_lengths_mask = ( 0.7 , 0.9 ),
transformer = dict (
dim = 1024 ,
depth = 24 ,
heads = 16 ,
text_depth = 12 ,
text_heads = 8 ,
max_seq_len = 4096 ,
dropout = 0.1
)
)
mx . eval ( e2tts . parameters ())
batch_size = 32
dataset = load_libritts_r ( split = "dev-clean" ) # or any audio/caption dataset
trainer = E2Trainer ( model = e2tts , num_warmup_steps = 20_000 )
trainer . train (
train_dataset = dataset ,
learning_rate = 7.5e-5 ,
batch_size = batch_size ,
total_steps = 1_000_000
)... depois de muito treinamento ...
generated_audio = e2tts . sample (
cond = cond , # reference mel spectrogram for voice matching
text = text , # caption for generation
duration = duration , # from a trained DurationPredictor or otherwise
steps = 32 ,
cfg_strength = 1.0 , # if trained for cfg
use_vocos = True # set to False to get mel spectrograms instead of audio
) Consulte train_example.py para um exemplo de treinamento em um único dispositivo.
Lucidrains para a implementação original em Pytorch.
@inproceedings { Eskimez2024E2TE ,
title = { E2 TTS: Embarrassingly Easy Fully Non-Autoregressive Zero-Shot TTS } ,
author = { Sefik Emre Eskimez and Xiaofei Wang and Manthan Thakker and Canrun Li and Chung-Hsien Tsai and Zhen Xiao and Hemin Yang and Zirun Zhu and Min Tang and Xu Tan and Yanqing Liu and Sheng Zhao and Naoyuki Kanda } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:270738197 }
} @article { Burtsev2021MultiStreamT ,
title = { Multi-Stream Transformers } ,
author = { Mikhail S. Burtsev and Anna Rumshisky } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2107.10342 } ,
url = { https://api.semanticscholar.org/CorpusID:236171087 }
}O código deste repositório é liberado sob a licença do MIT, conforme encontrado no arquivo de licença.


