e2 tts mlx
v0.0.6
Implementación de E2-TTS, vergonzosamente fácil TTS de disparo cero no autorgresivo, con el marco MLX.
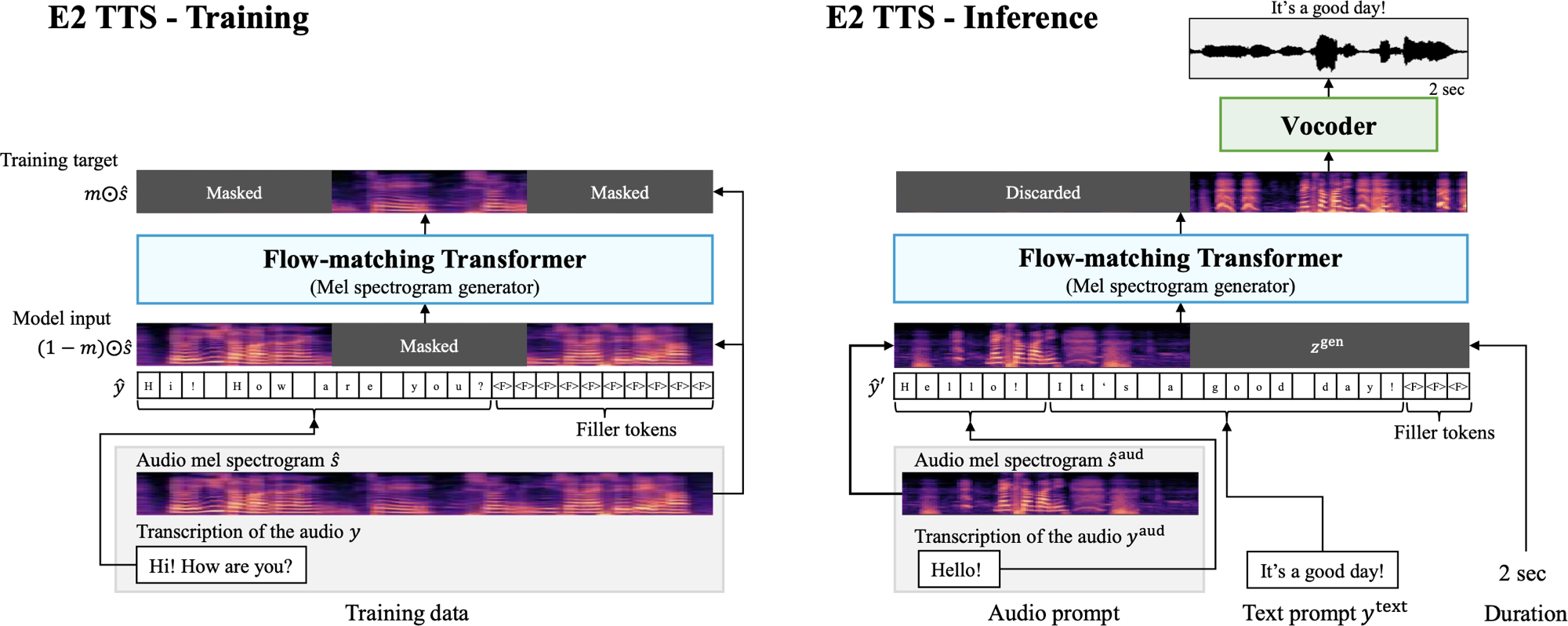
E2 TTS es un sistema de texto a voz no autorgresivo y de disparo cero que simplifica la tubería TTS típica utilizando un generador de espectrograma MEL de combinación de flujo entrenado en una tarea de relleno de audio enmascarada, sin la necesidad de información de alineación a nivel de cuadro.
Esta implementación se basa en la implementación de Lucidrains en Pytorch, que difiere del documento en que utiliza un transformador multistream para texto y audio, con acondicionamiento realizado en cada bloque de transformador.
pip install mlx-e2-tts import mlx . core as mx
from e2_tts_mlx . model import E2TTS
from e2_tts_mlx . trainer import E2Trainer
from e2_tts_mlx . data import load_libritts_r
e2tts = E2TTS (
tokenizer = "char-utf8" , # or "phoneme_en" / callable
cond_drop_prob = 0.25 ,
frac_lengths_mask = ( 0.7 , 0.9 ),
transformer = dict (
dim = 1024 ,
depth = 24 ,
heads = 16 ,
text_depth = 12 ,
text_heads = 8 ,
max_seq_len = 4096 ,
dropout = 0.1
)
)
mx . eval ( e2tts . parameters ())
batch_size = 32
dataset = load_libritts_r ( split = "dev-clean" ) # or any audio/caption dataset
trainer = E2Trainer ( model = e2tts , num_warmup_steps = 20_000 )
trainer . train (
train_dataset = dataset ,
learning_rate = 7.5e-5 ,
batch_size = batch_size ,
total_steps = 1_000_000
)... después de mucho entrenamiento ...
generated_audio = e2tts . sample (
cond = cond , # reference mel spectrogram for voice matching
text = text , # caption for generation
duration = duration , # from a trained DurationPredictor or otherwise
steps = 32 ,
cfg_strength = 1.0 , # if trained for cfg
use_vocos = True # set to False to get mel spectrograms instead of audio
) Consulte train_example.py para obtener un ejemplo de entrenamiento de un solo dispositivo.
Lucidrains para la implementación original en Pytorch.
@inproceedings { Eskimez2024E2TE ,
title = { E2 TTS: Embarrassingly Easy Fully Non-Autoregressive Zero-Shot TTS } ,
author = { Sefik Emre Eskimez and Xiaofei Wang and Manthan Thakker and Canrun Li and Chung-Hsien Tsai and Zhen Xiao and Hemin Yang and Zirun Zhu and Min Tang and Xu Tan and Yanqing Liu and Sheng Zhao and Naoyuki Kanda } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:270738197 }
} @article { Burtsev2021MultiStreamT ,
title = { Multi-Stream Transformers } ,
author = { Mikhail S. Burtsev and Anna Rumshisky } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2107.10342 } ,
url = { https://api.semanticscholar.org/CorpusID:236171087 }
}El código en este repositorio se publica bajo la licencia MIT como se encuentra en el archivo de licencia.


