e2 tts mlx
v0.0.6
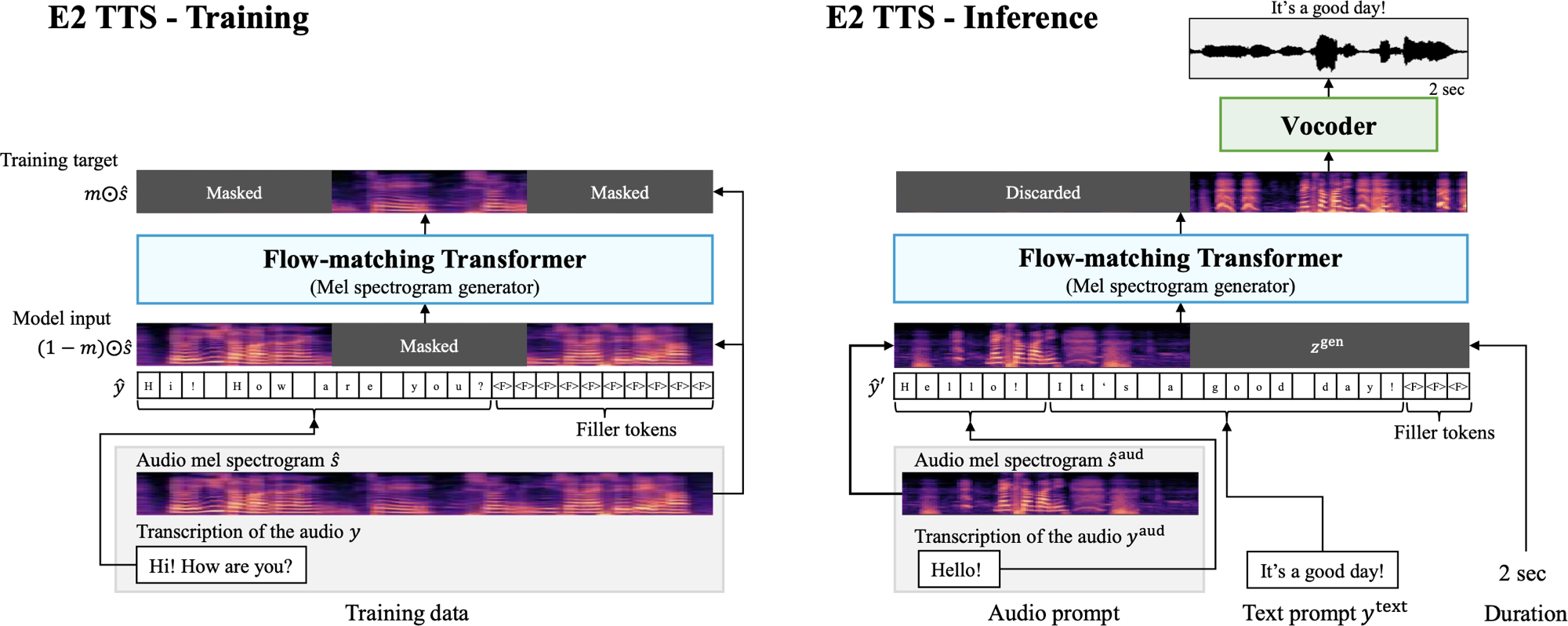
Mise en œuvre d'E2-TTS, embarrassant entièrement des TTS zéro-shot entièrement non autorégressifs, avec le cadre MLX.
E2 TTS est un système de texte à dispection non autorégressif et zéro qui simplifie le pipeline TTS typique en utilisant un générateur de spectrogramme MEL de correspondance de flux formé sur une tâche de remplissage audio masquée, sans avoir besoin d'informations d'alignement au niveau du cadre.
Cette implémentation est basée sur l'implémentation de LucidRains dans Pytorch, qui diffère du document en ce qu'il utilise un transformateur multi-éléments pour le texte et l'audio, avec un conditionnement effectué chaque bloc de transformateur.
pip install mlx-e2-tts import mlx . core as mx
from e2_tts_mlx . model import E2TTS
from e2_tts_mlx . trainer import E2Trainer
from e2_tts_mlx . data import load_libritts_r
e2tts = E2TTS (
tokenizer = "char-utf8" , # or "phoneme_en" / callable
cond_drop_prob = 0.25 ,
frac_lengths_mask = ( 0.7 , 0.9 ),
transformer = dict (
dim = 1024 ,
depth = 24 ,
heads = 16 ,
text_depth = 12 ,
text_heads = 8 ,
max_seq_len = 4096 ,
dropout = 0.1
)
)
mx . eval ( e2tts . parameters ())
batch_size = 32
dataset = load_libritts_r ( split = "dev-clean" ) # or any audio/caption dataset
trainer = E2Trainer ( model = e2tts , num_warmup_steps = 20_000 )
trainer . train (
train_dataset = dataset ,
learning_rate = 7.5e-5 ,
batch_size = batch_size ,
total_steps = 1_000_000
)... après beaucoup de formation ...
generated_audio = e2tts . sample (
cond = cond , # reference mel spectrogram for voice matching
text = text , # caption for generation
duration = duration , # from a trained DurationPredictor or otherwise
steps = 32 ,
cfg_strength = 1.0 , # if trained for cfg
use_vocos = True # set to False to get mel spectrograms instead of audio
) Voir train_example.py pour un exemple de formation à un seul appareil.
Lucidrains pour l'implémentation originale dans Pytorch.
@inproceedings { Eskimez2024E2TE ,
title = { E2 TTS: Embarrassingly Easy Fully Non-Autoregressive Zero-Shot TTS } ,
author = { Sefik Emre Eskimez and Xiaofei Wang and Manthan Thakker and Canrun Li and Chung-Hsien Tsai and Zhen Xiao and Hemin Yang and Zirun Zhu and Min Tang and Xu Tan and Yanqing Liu and Sheng Zhao and Naoyuki Kanda } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:270738197 }
} @article { Burtsev2021MultiStreamT ,
title = { Multi-Stream Transformers } ,
author = { Mikhail S. Burtsev and Anna Rumshisky } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2107.10342 } ,
url = { https://api.semanticscholar.org/CorpusID:236171087 }
}Le code de ce référentiel est publié dans le cadre de la licence MIT telle que trouvée dans le fichier de licence.


