NN dependência-kit
O KIT de dependência de NN é uma ferramenta de pesquisa de código aberto para ajudar as redes neurais de engenharia para domínios críticos de segurança.
C.-H. Cheng, C.-H. Huang e G. Nührenberg. NN dependência-kit: engenharia redes neurais para sistemas de direção autônomos críticos à segurança . https://arxiv.org/abs/1811.06746
Licença
GNU Affero Geral Public License (AGPL) Versão 3
Manual
Consulte nn_dependability_kit_manual.pdf
Experimente a ferramenta
Os exemplos são apresentados como cadernos Jupyter para permitir uma compreensão passo a passo sobre os conceitos.
- [Metrics & test case generation] GTSRB_Neuron2ProjectionCoverage_TestGen.ipynb, or GTSRB_AdditionalMetrics.ipynb, or Scenario_Coverage_A9.ipynb, or KITTI_Scenario_Coverage.ipynb, or MNIST_Neuron2ProjectionCoverage_TestGen.ipynb, or Ssd_interpretationprecision.ipynb
- [Verificação formal] TargetvehicleProcessingNetwork_FormalVerification.ipynb
- [Verificação de tempo de execução] gtsrb_runtimemonitoring.ipynb, ou mnist_runtimemonitoring.ipynb
Estrutura
Existem quatro pacotes sob a dependência, ou seja,
- Básico: leitor para modelos, bem como representação intermediária de NN (para fins de verificação)
- Métricas: Calcule as métricas de confiabilidade para redes neurais
- ATG: geração automática de casos de teste para melhorar as métricas
- Formal: Verificação formal (análise estática, solução de restrições) de redes neurais
- RV: Monitoramento de tempo de execução de redes neurais
Pacotes importantes do Python como requisitos
Pytorch + numpy + matplotlib + jupyter
[Geração de casos de teste] Ferramentas de pesquisa de otimização do Google
[Verificação / análise estática] Pulpa (conector MILP baseado em Python para CBC e outros solucionadores)
- O solucionador da CBC pré-enviado com polpa pode travar na solução de alguns problemas. O mecanismo de análise estática pressupõe que o solucionador GLPK possa ser chamado (configure a variável do caminho), de modo que sempre que o CBC falhe, o GLPK é automaticamente acionado como substituição. Infelizmente, isso não pode garantir que os dois solucionadores não travem ao mesmo tempo. Portanto, para o uso industrial, aconselhamos fortemente usar o IBM CPLEX como o solucionador MILP subjacente.
- [GNU glpk] http://www.gnu.org/software/glpk/
- [GPLK no Windows] http://winglpk.sourceforge.net/
[Verificação em tempo de execução] DD (diagrama de decisão binária implementado usando Python)
Use requisitos.txt para instalar dependências para executar a maioria dos notebooks (excluindo o tensorflow).
Publicações relacionadas
- [Métricas e geração de casos de teste] https://arxiv.org/abs/1806.02338
- [Verificação formal] https://arxiv.org/abs/1705.01040, https://arxiv.org/abs/1904.04706
- [Verificação de tempo de execução] https://arxiv.org/abs/1809.06573
- [SSD-Exemplo] O exemplo usa algumas imagens do conjunto de dados VOC2012: o desafio Pascal Visual Objects Classes (VOC) Everingham, M., Van Gool, L., Williams, CKI, Winn, J. e Zisserman, A. International Journal of Computer Vision, 88 (2), 303-338, 2010, 2010, 2010, 2010, A.
Outros tópicos
A. Métricas relacionadas à precisão da intrepretação e sensibilidade à oclusão
1. Pacote adicional a ser instalado
- [Métricas] Saliência (https://github.com/pair-code/salience) usa-a da seguinte maneira:
# init submodule for saliency
cd nndependability/metrics/saliency-source/
git submodule init
git submodule update
cd ..
ln -s saliency-source/saliency saliency
cd ../../
2. Preparação para o exemplo de SSD
cd models/SSD-Tensorflow/
git submodule init
git submodule update
# prepare weights
cd checkpoints/
unzip ssd_300_vgg.ckpt.zip
cd ../
# install custom changes to module SSD-Tensorflow that allows using saliency
git apply ../ssd_tensorflow_diff.diff
cd ../../
B. Desafios na verificação formal devido à falta de especificação de entrada e escalabilidade
Para fazer verificação formal sobre as redes neurais, há dois problemas comumente vistos.
- A escalabilidade da verificação formal pode não ser capaz de lidar com redes muito complexas e muito profundas
- A "forma da entrada" é desconhecida. De fato, geralmente normaliza os dados, de modo que todas as entradas geralmente têm um intervalo de [-1,1], mas podemos querer ter uma "abordagem excessiva" mais rígida sobre os dados de treinamento.
No kit de dependência de NN, aconselhamos os usuários a prosseguir com as etapas seguintes.
- Execute a análise, tomando uma sub-rede de camadas de perto de saída, como a rede amarela da figura abaixo. Se para cada entrada para a rede amarela, garantir -se que a saída ruim não será produzida, para todas as entradas para a rede original muito profunda e complexa, nenhuma saída ruim será produzida.
- Os 2º e 3º parâmetros na função loadMlpfrompytorch () em Nndependability/Basics/pytorchreader.py Suporte
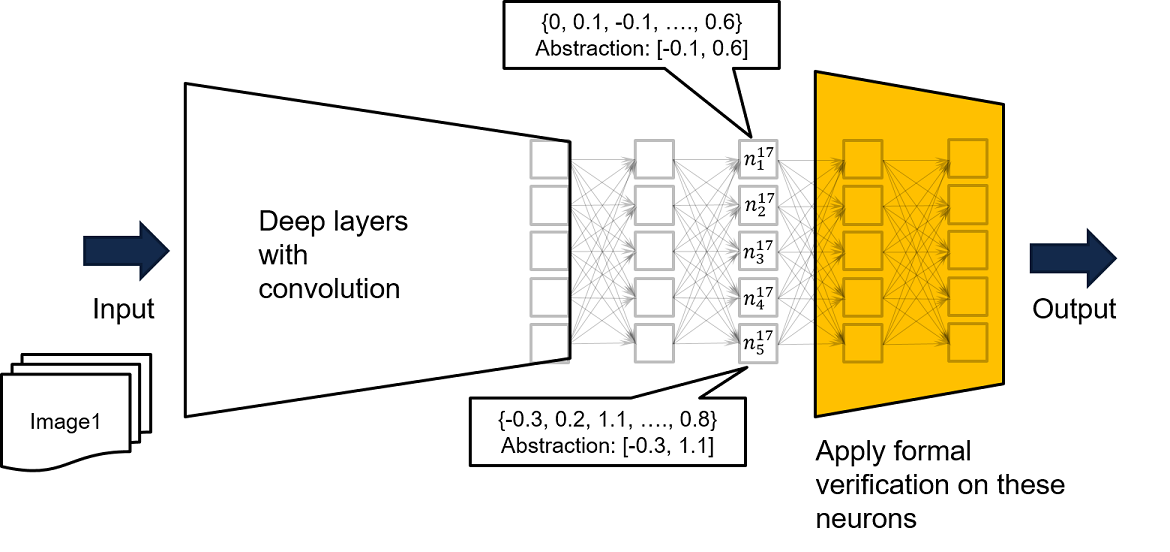
Como as entradas para a rede completa só podem levar a certos valores para a entrada da rede amarela, se a propriedade de segurança não puder ser comprovada na rede amarela, nossa recomendação adicional é alimentar a rede completa com dados de treinamento, a fim de derivar uma abrangência mais rigorosa com base em entradas visitadas para a rede amarela. Um exemplo pode ser encontrado no neurônio n^17_ {1}, onde, executando a rede com todos os dados de treinamento disponíveis, sabemos que os dados de treinamento produzem a saída de n^17_ {1} limitada por [-0.1, 0.6]. Assim, podemos usar o limite registrado como restrições de entrada para a rede amarela para executar a verificação formal.
- Além de usar intervalos, também se pode registrar restrições de octógono ou mesmo padrões de ativação de neurônios para criar uma excesso de excesso de excesso dos dados visitados.
A correção da verificação é baseada na suposição de que é impossível ter valores de neurônios sentados fora do intervalo criado, o que é uma prova de garantia . A suposição pode ser facilmente monitorada no tempo de execução.


