Pipeline
- Eu criei um pipeline RAG para mostrar como podemos aumentar o conhecimento com dados adicionais.
Descrição visual do pipeline RAG
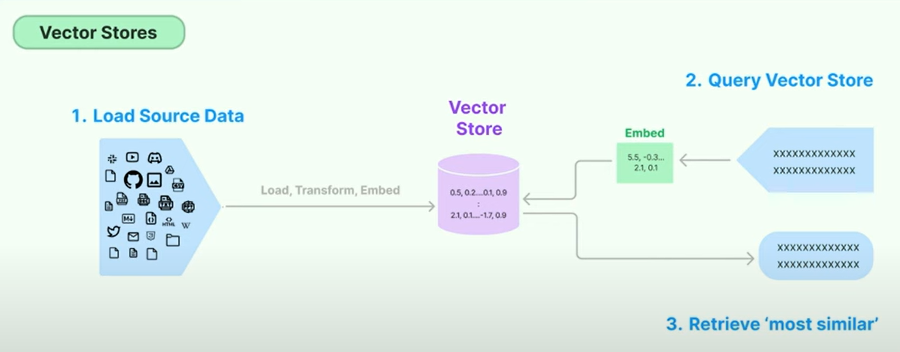
Descrição
- O RAG é uma técnica para aumentar o conhecimento do LLM com dados adicionais.
- Os LLMs podem raciocinar sobre tópicos abrangentes, mas seus conhecimentos são limitados aos dados públicos até um momento específico em que foram treinados.
- Se você deseja criar aplicativos de IA que possam raciocinar sobre dados ou dados privados introduzidos após a data de corte de um modelo, precisará aumentar o conhecimento do modelo com as informações específicas necessárias.
- O processo de trazer as informações apropriadas e inseri -las no prompt do modelo é conhecido como geração aumentada de recuperação (RAG).
Bibliotecas usadas
- Langchain == 0.1.20
- Langchain-Community == 0.0.38
- BS4 == 0.0.2
- Pypdf == 4.2.0
- Chromadb == 0.5.0
Instalação
- Pré -requisitos
- Git
- Família da linha de comando
- Clone o repositório:
git clone https://github.com/NebeyouMusie/RAG-Pipeline.git - Criar e ativar o ambiente virtual (recomendado)
-
python -m venv venv -
source venv/bin/activate
- Navegue até o
cd ./RAG-Pipeline usando seu terminal - Instalar bibliotecas:
pip install -r requirements.txt - Abra e execute todas as células no notebook
rag_pipeline.ipynb - Ou você pode baixar os documentos no diretório
files e o notebook rag_pipeline.ipynb do diretório notebook no repositório, carregar esses arquivos e notebook para o Google Collab e executar todas as células no rag_pipeline.ipynb notebook
Colaboração
- As colaborações são bem -vindas ❤️
Agradecimentos
- Eu gostaria de agradecer a Krish Naik
Contato


