Pipeline de chiffon (récupération augmentée augmentée)
- J'ai construit un pipeline de chiffons pour montrer comment augmenter les connaissances avec des données supplémentaires.
Description visuelle du pipeline de chiffon
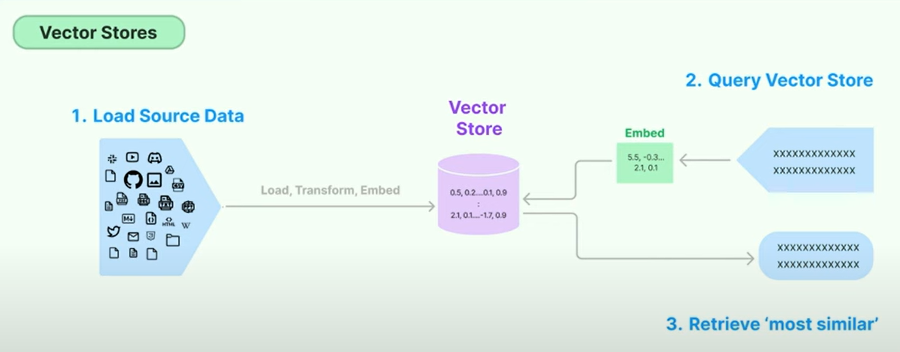
Description
- Le chiffon est une technique pour augmenter les connaissances LLM avec des données supplémentaires.
- Les LLM peuvent raisonner sur des sujets de grande envergure, mais leurs connaissances sont limitées aux données publiques jusqu'à un moment spécifique sur lequel ils ont été formés.
- Si vous souhaitez créer des applications d'IA qui peuvent raisonner sur les données privées ou les données introduites après la date de coupure d'un modèle, vous devez augmenter les connaissances du modèle avec les informations spécifiques dont elle a besoin.
- Le processus de mise en place des informations appropriés et de l'insertion dans l'invite du modèle est connu sous le nom de génération augmentée de récupération (RAG).
Bibliothèques utilisées
- Langchain == 0.1.20
- Langchain-Community == 0,0,38
- bs4 == 0.0.2
- PYPDF == 4.2.0
- chromadb == 0.5.0
Installation
- Condition préalable
- Git
- Familiarité de la ligne de commande
- Clone The Repository:
git clone https://github.com/NebeyouMusie/RAG-Pipeline.git - Créer et activer l'environnement virtuel (recommandé)
-
python -m venv venv -
source venv/bin/activate
- Accédez au CD du répertoire des projets
cd ./RAG-Pipeline à l'aide de votre terminal - Installation de bibliothèques:
pip install -r requirements.txt - Ouvrez et exécutez toutes les cellules dans le cahier
rag_pipeline.ipynb - Ou vous pouvez télécharger les documents dans le répertoire
files et le cahier rag_pipeline.ipynb à partir du répertoire rag_pipeline.ipynb notebook
Collaboration
- Les collaborations sont les bienvenues ❤️
Remerciements
- Je voudrais remercier Krish Naik
Contact


