Pipeline von Rag (Abruf Augmented Generation)
- Ich habe eine Lag -Pipeline gebaut, um zu zeigen, wie wir das Wissen mit zusätzlichen Daten erweitern können.
Visuelle Beschreibung der Lappenpipeline
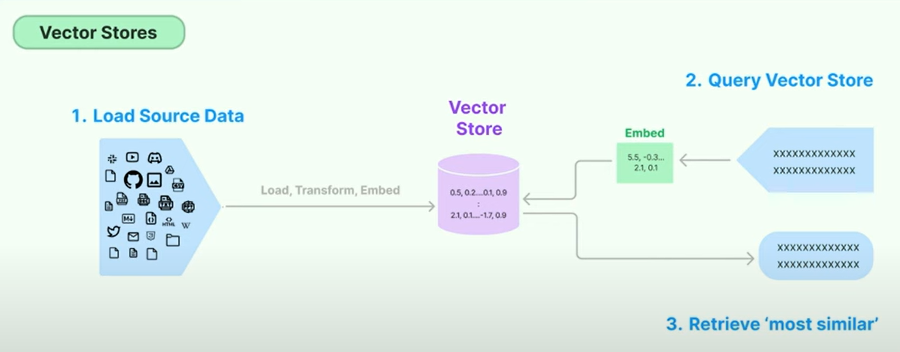
Beschreibung
- Rag ist eine Technik, um LLM -Wissen mit zusätzlichen Daten zu erweitern.
- LLMs können über weitreichende Themen argumentieren, aber ihr Wissen beschränkt sich auf die öffentlichen Daten bis zu einem bestimmten Zeitpunkt, an dem sie geschult wurden.
- Wenn Sie KI -Anwendungen erstellen möchten, die über private Daten oder Daten, die nach dem Cutoff -Datum eines Modells eingeführt wurden, begründen können, müssen Sie das Wissen des Modells mit den spezifischen Informationen erweitern, die es benötigt.
- Der Prozess des Einbringens der entsprechenden Informationen und des Einfügens in die Modellaufforderung wird als Abruf Augmented Generation (RAG) bezeichnet.
Bibliotheken verwendet
- Langchain == 0,1,20
- Langchain-Community == 0,0,38
- BS4 == 0,0,2
- pypdf == 4.2.0
- Chromadb == 0.5.0
Installation
- Voraussetzungen
- Git
- Befehlszeile Vertrautheit
- Klon das Repository:
git clone https://github.com/NebeyouMusie/RAG-Pipeline.git - Virtuelle Umgebung erstellen und aktivieren (empfohlen)
-
python -m venv venv -
source venv/bin/activate
- Navigieren Sie mit Ihrem Terminal zur Projektverzeichnis-Verzeichnis
cd ./RAG-Pipeline - Installieren Sie Bibliotheken:
pip install -r requirements.txt - Öffnen und führen Sie alle Zellen in das Notebook
rag_pipeline.ipynb aus -
rag_pipeline.ipynb Sie können die Dokumente in das files und das Notebook rag_pipeline.ipynb im notebook -Verzeichnis im Repository herunterladen, laden Sie diese Dateien und das Notebook in Google Collab
Zusammenarbeit
- Die Kooperationen sind begrüßt ❤️
Anerkennung
- Ich möchte Krish Naik danken
Kontakt


