thesis rag chatbot gemini
1.0.0
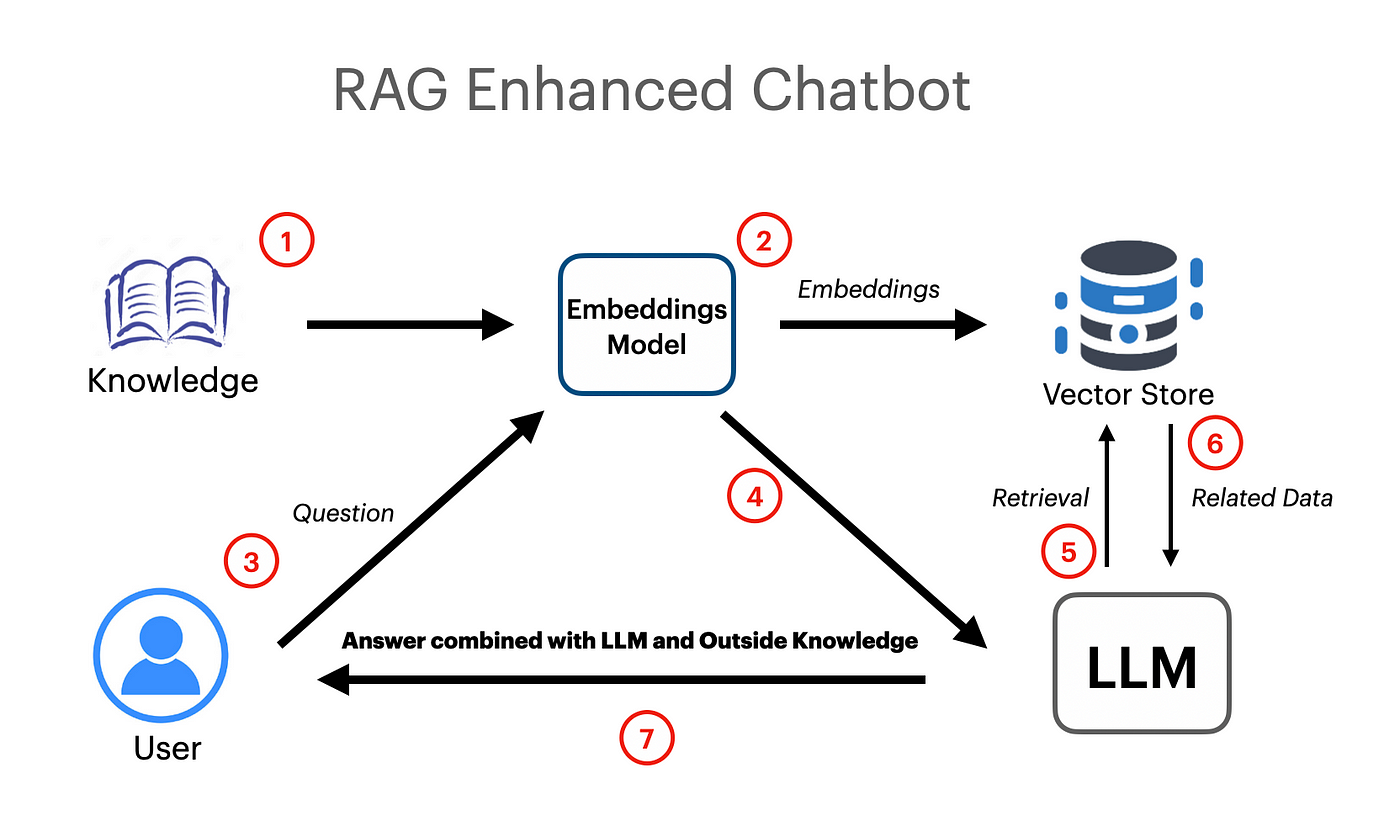
Foi feito um aplicativo RAG baseado em Langchain, que funciona usando o modelo de incorporação de vetor e o modelo do Google Gemini Pro LLM.
export GOOGLE_API_KEY= " your api key "UnstructureExcelloader foi usado em Langchain.Document-carregadores, que é usado para carregar dados da planilha Excel em documentos.
O modelo do Google Gemini Pro foi usado para obter a conclusão contextual do bate -papo.
llm = ChatGoogleGenerativeAI ( model = "gemini-pro" , google_api_key = os . environ [ "GOOGLE_API_KEY" ])
embeddings = GoogleGenerativeAIEmbeddings ( model = "models/embedding-001" )A loja de vetores FAISS (Facebook AI similaridade) foi usada para criar e armazenar incorporações semânticas para os documentos carregados. O Vector Store pode ser consultado posteriormente com uma pesquisa de similaridade para obter informações mais relevantes.
vectordb = FAISS . from_documents ( documents = docs , embedding = embeddings )
# save db as pickle file
with open ( "vectorstore.pkl" , "wb" ) as f :
pickle . dump ( vectordb , f )
#load db from pickle file
with open ( "vectorstore.pkl" , "rb" ) as f :
my_vector_database = pickle . load ( f )
# get 5 most relevant similar results
retriever = my_vector_database . as_retriever ( search_kwargs = { "k" : 5 })O PromptTemplate foi usado da Langchain para criar instruções eficientes que mais tarde seriam transmitidas ao modelo. O prompt também contém variáveis de entrada que indicam ao modelo que algumas informações serão transmitidas pelo usuário.
template = """
You are a very helpful AI assistant.
You answer every question and apologize polietly if you dont know the answer.
The context contains information about a person,
title of their thesis,
the abstract of their thesis
and a link to their thesis.
Your task is to answer based on that information.
context: {context}
input: {input}
answer:
"""
prompt = PromptTemplate . from_template ( template )A cadeia de retraca tem sido usada para passar documentos/incorporações ao modelo como contexto para a geração aumentada em volta.
combine_docs_chain = create_stuff_documents_chain ( llm , prompt )
retrieval_chain = create_retrieval_chain ( retriever , combine_docs_chain )


