thesis rag chatbot gemini
1.0.0
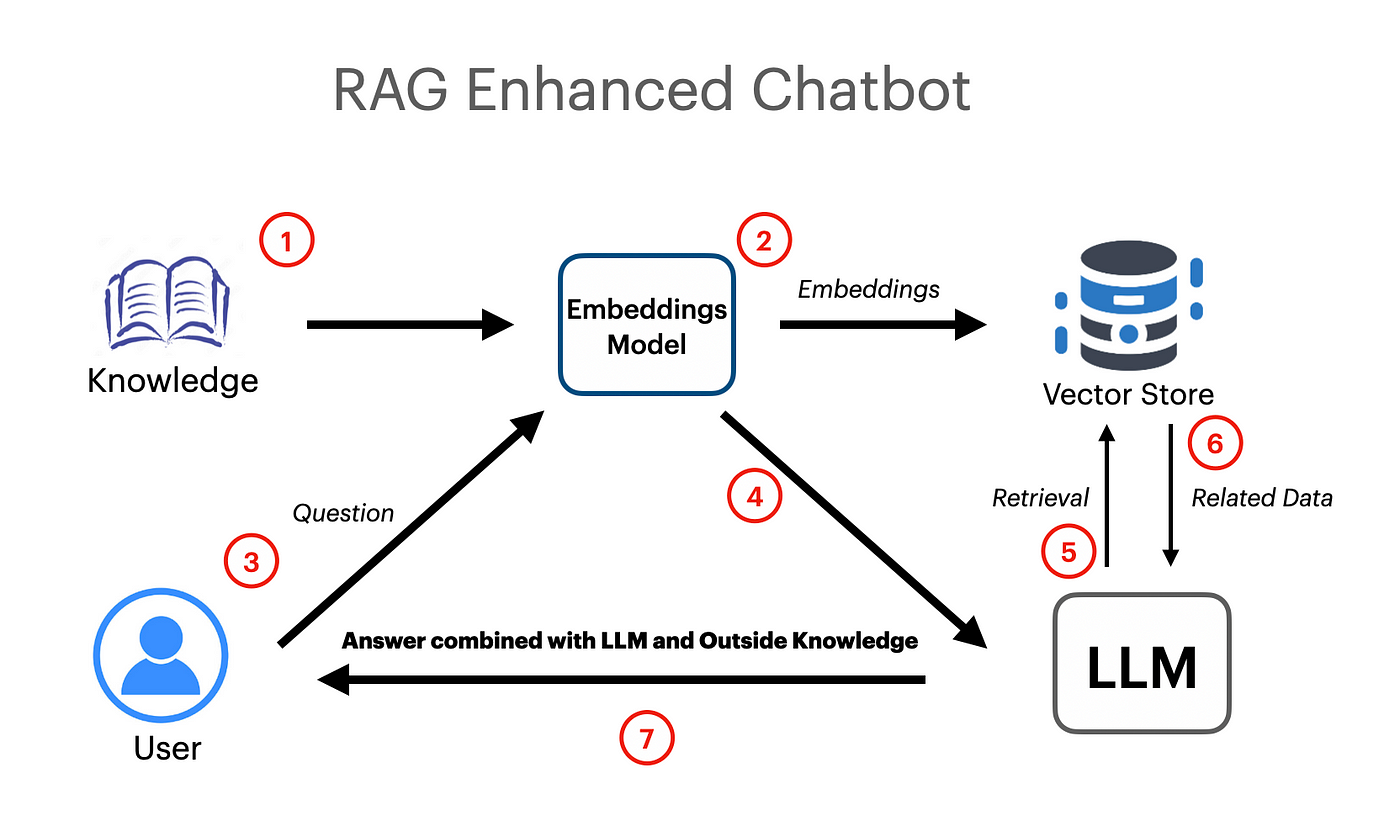
Aplikasi Rag Berbasis Langchain telah dibuat yang berfungsi menggunakan vektor embeddings dan model Google Gemini Pro LLM.
export GOOGLE_API_KEY= " your api key "UnstrukturExcelloader telah digunakan dari Langchain. Dokumen-Loaders yang digunakan untuk memuat data spreadsheet Excel ke dalam dokumen.
Model Google Gemini Pro telah digunakan untuk mendapatkan penyelesaian obrolan kontekstual.
llm = ChatGoogleGenerativeAI ( model = "gemini-pro" , google_api_key = os . environ [ "GOOGLE_API_KEY" ])
embeddings = GoogleGenerativeAIEmbeddings ( model = "models/embedding-001" )Toko Vektor FAISS (Facebook AI Kesamaan Pencarian) telah digunakan untuk membuat dan menyimpan embeddings semantik untuk dokumen yang dimuat. Toko vektor kemudian dapat ditanya dengan pencarian kesamaan untuk mendapatkan informasi yang paling relevan.
vectordb = FAISS . from_documents ( documents = docs , embedding = embeddings )
# save db as pickle file
with open ( "vectorstore.pkl" , "wb" ) as f :
pickle . dump ( vectordb , f )
#load db from pickle file
with open ( "vectorstore.pkl" , "rb" ) as f :
my_vector_database = pickle . load ( f )
# get 5 most relevant similar results
retriever = my_vector_database . as_retriever ( search_kwargs = { "k" : 5 })PromptTemplate telah digunakan dari Langchain untuk membuat petunjuk yang efisien yang nantinya akan diteruskan ke model. Prompt ini juga berisi variabel input yang menunjukkan kepada model bahwa beberapa informasi akan diteruskan oleh pengguna.
template = """
You are a very helpful AI assistant.
You answer every question and apologize polietly if you dont know the answer.
The context contains information about a person,
title of their thesis,
the abstract of their thesis
and a link to their thesis.
Your task is to answer based on that information.
context: {context}
input: {input}
answer:
"""
prompt = PromptTemplate . from_template ( template )Rantai retreival telah digunakan untuk meneruskan dokumen/embeddings ke model sebagai konteks untuk generasi augmented retreival.
combine_docs_chain = create_stuff_documents_chain ( llm , prompt )
retrieval_chain = create_retrieval_chain ( retriever , combine_docs_chain )


