HebTTS
1.0.0
논문의 추론 코드 및 모델 가중치 "Diacritic-Free 히브리어 TT에 대한 언어 모델링 접근법"(Interspeech 2024).
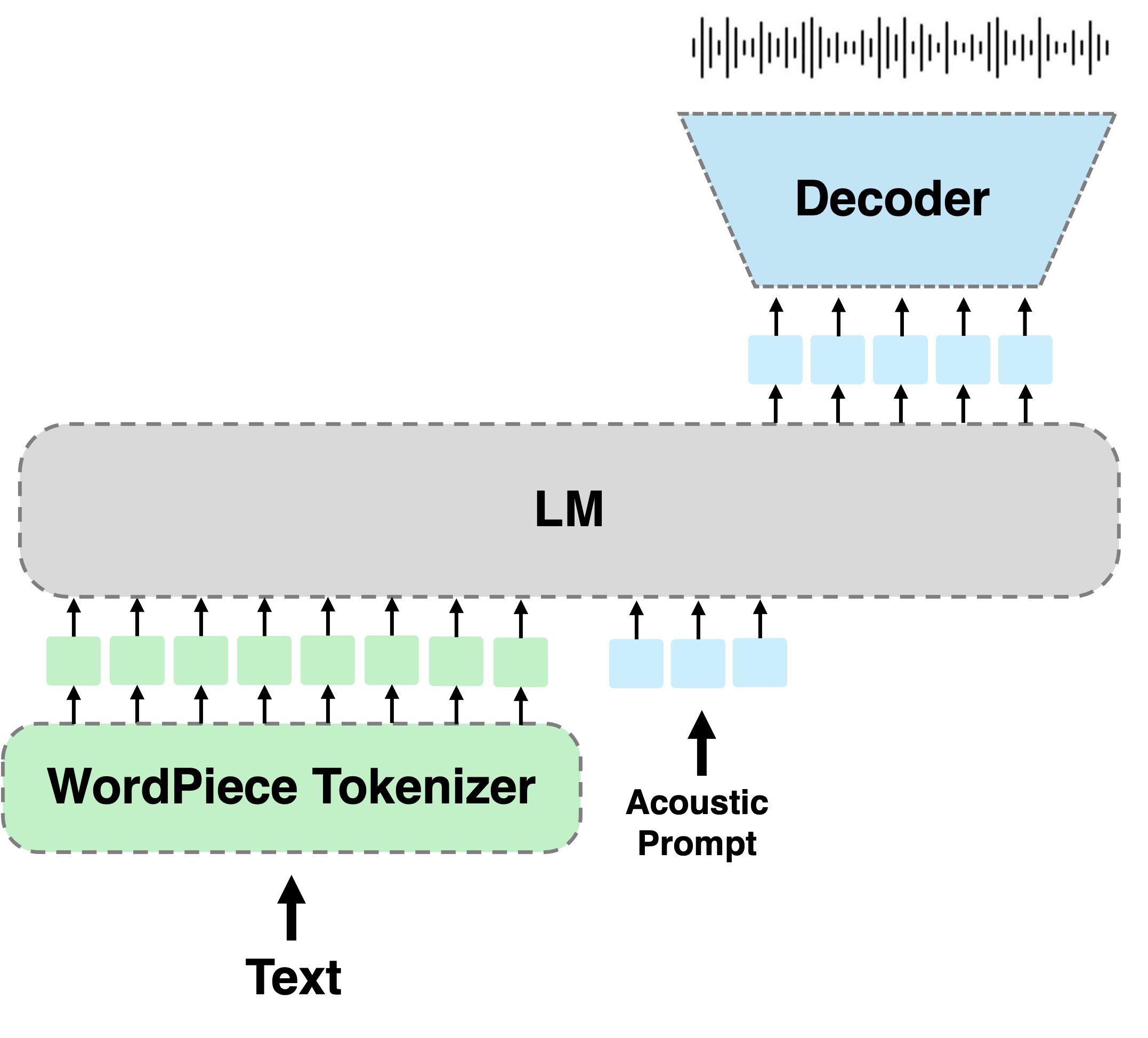
초록 : 우리는 히브리어로 텍스트 음성 (TTS)의 과제를 다룹니다. 전통적인 히브리에는 디아크리닉 (`niqqud ')이 포함되어 있으며, 이는 개인이 말을 주어야하는 방식을 지시하지만 현대 히브리어는 거의 사용하지 않습니다. 현대 히브리어의 디아크리닉 부족으로 인해 독자들은 올바른 발음을 마치고 상황에 따라 어떤 음소를 사용할 것인지 이해할 것으로 예상됩니다. 이것은 TTS 시스템에 근본적인 과제를 부과하여 텍스트 음성 연설을 정확하게 매핑합니다. 이 연구에서 우리는 히브리어 TTS의 과제를 위해 언어 모델링 Diacritics-Free TTS 접근법을 채택 할 것을 제안합니다. 언어 모델 (LM)은 불연속 음성 표현에서 작동하며 워드 피스 토큰 화기에 조절됩니다. 우리는 오래된 감독 기록을 사용하여 제안 된 방법을 최적화하고 여러 Diacritic 기반 히브리어 TTS 시스템과 비교합니다. 결과는 제안 된 방법이 생성 된 음성의 내용 보존 및 자연성을 고려하여 평가 된 기준선보다 우수하다는 것을 시사합니다.
Google Colab 데모에서 모델을 사용해 볼 수 있습니다.
git clone https://github.com/slp-rl/HebTTS.gitGoogle 드라이브에 체크 포인트를 게시합니다. AR 모델은 HEBDB에서 1.2m 단계 및 NAR 모델에 대한 훈련을 받았습니다.
gdown 11NoOJzMLRX9q1C_Q4sX0w2b9miiDjGrvpip install torch torchaudio
pip install torchmetrics
pip install omegaconf
pip install git+https://github.com/lhotse-speech/lhotse
pip install librosa
pip install encodec
pip install phonemizer
pip install audiocraft # optional 다른 스피커와 텍스트 프롬프트로 모델을 사용하여 재생할 수 있습니다.
infer.py 실행 :
python infer.py --checkpoint checkpoint.pt --output-dir ./out --text "היי מה קורה"
추가 인수 --speaker 및 --top-k 지정할 수 있습니다.
팁
우리는 새로운 멀티 밴드 확산 (MBD) 보코더를 사용하여 더 나은 quallity 오디오를 생성 할 수 있습니다. 오디오 크래프트를 설치하고 --mbd True 플래그를 설정하십시오.
| 사용하여 텍스트 프롬프트를 연결할 수 있습니다 또는 터미널에 히브리어를 쓰는 것이 불편한 경우 n 에 의해 스파이팅 된 텍스트 파일의 경로를 지정하십시오.
תגידו גנבו לכם פעם את האוטו ופשוט ידעתם שאין טעם להגיש תלונה במשטרה
היי מה קורה
בראשית היתה חללית מסוג נחתת
그리고 달리기
python infer.py --checkpoint checkpoint.pt --output-dir ./out --text example.txt
speakers.yaml 에 정의 된 스피커를 사용하거나 추가 스피커를 추가 할 수 있습니다. 동일한 형식으로 WAV 파일과 전사를 지정하십시오.
--speaker shaul
@article { roth2024language ,
title = { A Language Modeling Approach to Diacritic-Free Hebrew TTS } ,
author = { Roth, Amit and Turetzky, Arnon and Adi, Yossi } ,
journal = { arXiv preprint arXiv:2407.12206 } ,
year = { 2024 }
}valle 내부의 모델 코드는 Feiteng Li의 구현을 기반으로합니다.

