HebTTS
1.0.0
論文の推論コードとモデルの重み「ディアクリティックフリーヘブライTTSへの言語モデリングアプローチ」(speech 2024)。
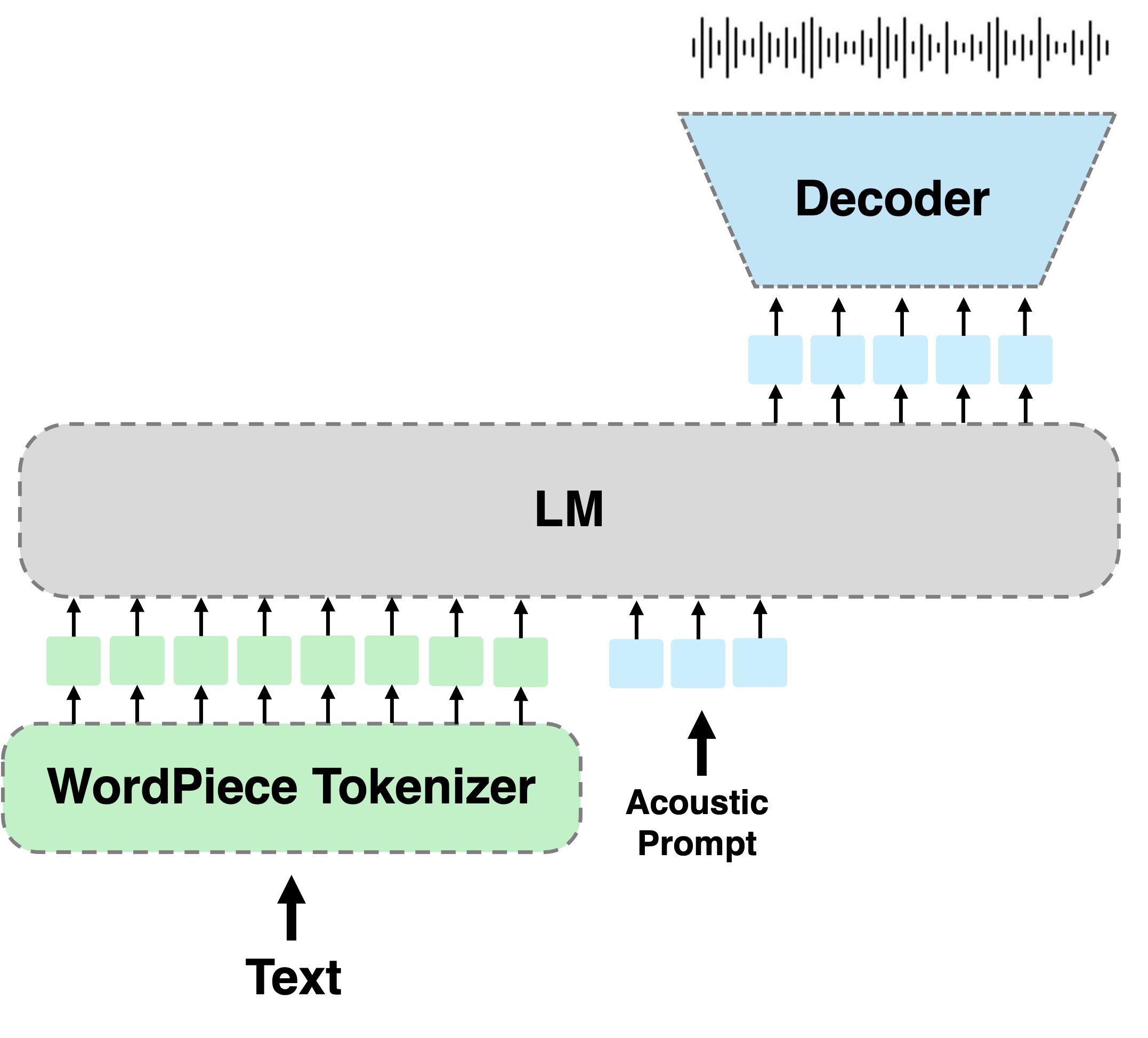
要約:ヘブライ語のテキストからスピーチ(TTS)のタスクに取り組んでいます。伝統的なヘブライ語にはディクリチック(「niqqud」)が含まれています。現代のヘブライ語におけるディクリティックの欠如は、正しい発音を終了し、コンテキストに基づいてどの音素を使用するかを理解すると予想される読者をもたらします。これは、TTSシステムにテキスト間の間を正確にマッピングするための基本的な課題を課します。この研究では、ヘブライ語TTSのタスクのために、ディアチックのないTTSアプローチをモデル化する言語を採用することを提案します。言語モデル(LM)は、個別の音声表現で動作し、ワードピーストークネザーを条件付けます。内部の弱い監視された録音を使用して提案された方法を最適化し、それをいくつかの異なるヘブライ語TTSシステムと比較します。結果は、提案された方法が、生成された音声のコンテンツの保存と自然性の両方を考慮して、評価されたベースラインよりも優れていることを示唆しています。
Google Colabデモでモデルを試すことができます。
git clone https://github.com/slp-rl/HebTTS.gitGoogleドライブでチェックポイントを公開しています。 ARモデルは、HEBDBで200Kステップで1.2mのステップとNARモデルをトレーニングしました。
gdown 11NoOJzMLRX9q1C_Q4sX0w2b9miiDjGrvpip install torch torchaudio
pip install torchmetrics
pip install omegaconf
pip install git+https://github.com/lhotse-speech/lhotse
pip install librosa
pip install encodec
pip install phonemizer
pip install audiocraft # optional さまざまなスピーカーとテキストプロンプトを使用してモデルで再生できます。
durin infer.py :
python infer.py --checkpoint checkpoint.pt --output-dir ./out --text "היי מה קורה"
追加の引数を指定できます--speakerと--top-k 。
ヒント
より良いQuallityオーディオを生成するために、新しいマルチバンド拡散(MBD)ボコーダーを使用することを許可します。 Audiocraftをインストールし、 --mbd True Flagをセットします。
|を使用してテキストプロンプトを連結することができますまたは、ターミナルにヘブライ語を書くことが不便な場合はnによって促進されたテキストファイルのパスを指定します。
תגידו גנבו לכם פעם את האוטו ופשוט ידעתם שאין טעם להגיש תלונה במשטרה
היי מה קורה
בראשית היתה חללית מסוג נחתת
そして実行します
python infer.py --checkpoint checkpoint.pt --output-dir ./out --text example.txt
speakers.yamlで定義されたスピーカーを使用するか、スピーカーを追加することもできます。 WAVファイルと転写を同じ形式で指定します。
--speaker shaul
@article { roth2024language ,
title = { A Language Modeling Approach to Diacritic-Free Hebrew TTS } ,
author = { Roth, Amit and Turetzky, Arnon and Adi, Yossi } ,
journal = { arXiv preprint arXiv:2407.12206 } ,
year = { 2024 }
}valle内のモデルコードは、Feiteng Liの実装に基づいています。

