HebTTS
1.0.0
رمز الاستدلال والأوزان النموذجية للورقة "نهج نمذجة اللغة إلى TTS العبرية الخالية من الرسوم" (Interspeech 2024).
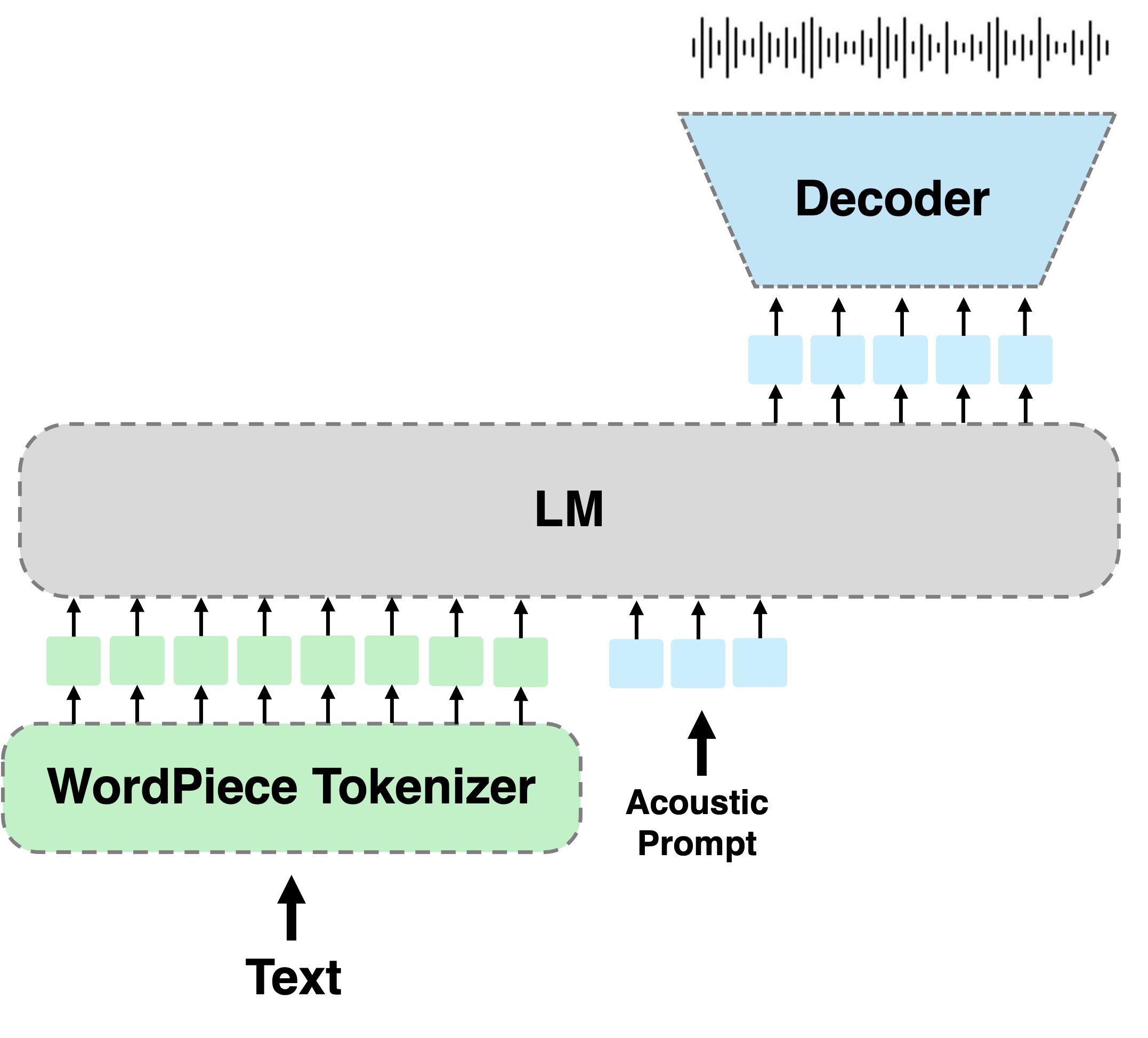
الخلاصة: نتعامل مع مهمة النص إلى كلام (TTS) باللغة العبرية. يحتوي العبرية التقليدية على علم الوزراء ("niqqud") ، والتي تملي الطريقة التي يجب أن ينطق بها الأفراد الكلمات المعطاة ، ومع ذلك ، نادراً ما يستخدمها العبرية الحديثة. يؤدي الافتقار إلى العلماء في العبرية الحديثة إلى أن يستنتج القراء النطق الصحيح وفهم الصوتيات التي يجب استخدامها بناءً على السياق. هذا يفرض تحديًا أساسيًا على أنظمة TTS لخريطة خريطة بدقة بين نص إلى كلام. في هذه الدراسة ، نقترح تبني نهج TTS النمذجة النمذجة الخالية من المواد الدراسية ، لمهمة TTS العبرية. يعمل نموذج اللغة (LM) على تمثيلات الكلام المنفصلة وهو مشروط على رمز الكلمات. نقوم بتحسين الطريقة المقترحة باستخدام التسجيلات الخاضعة للإشراف بشكل ضعيف ومقارنتها بالعديد من أنظمة TTS العبرية القائمة على التشكيل. تشير النتائج إلى أن الطريقة المقترحة متفوقة على خطوط الأساس التي تم تقييمها بالنظر إلى كل من الحفاظ على المحتوى والطبيعة في الكلام المولد.
يمكنك تجربة نموذجنا في Google Colab Demo.
git clone https://github.com/slp-rl/HebTTS.gitننشر نقطة التفتيش الخاصة بنا في Google Drive. تم تدريب نموذج AR على خطوات 1.2 مليون ونموذج NAR لما 200 ألف خطوة على HEBDB.
gdown 11NoOJzMLRX9q1C_Q4sX0w2b9miiDjGrvpip install torch torchaudio
pip install torchmetrics
pip install omegaconf
pip install git+https://github.com/lhotse-speech/lhotse
pip install librosa
pip install encodec
pip install phonemizer
pip install audiocraft # optional يمكنك اللعب مع النموذج مع مكبرات صوت مختلفة ومطالبات نصية.
تشغيل infer.py :
python infer.py --checkpoint checkpoint.pt --output-dir ./out --text "היי מה קורה"
يمكنك تحديد وسيطات إضافية- --speaker و-- --top-k .
نصيحة
نسمح باستخدام Vocoder الجديد لنشر النطاق (MBD) لتوليد صوت أفضل. قم بتثبيت Audiocraft وقم بتعيين العلم --mbd True .
يمكنك تسلسل مطالبات النص باستخدام | أو حدد مسارًا لملف نصي تم تجميعه بواسطة n إذا كانت كتابة العبرية في المحطة غير مريحة.
תגידו גנבו לכם פעם את האוטו ופשוט ידעתם שאין טעם להגיש תלונה במשטרה
היי מה קורה
בראשית היתה חללית מסוג נחתת
وركض
python infer.py --checkpoint checkpoint.pt --output-dir ./out --text example.txt
يمكنك استخدام السماعة المحددة في speakers.yaml ، أو إضافة مكبرات صوت إضافية. حدد ملفات WAV والنسخ بنفس التنسيق.
--speaker shaul
@article { roth2024language ,
title = { A Language Modeling Approach to Diacritic-Free Hebrew TTS } ,
author = { Roth, Amit and Turetzky, Arnon and Adi, Yossi } ,
journal = { arXiv preprint arXiv:2407.12206 } ,
year = { 2024 }
}valle على تنفيذ Feiteng Li.

