RAG QA Generator
v1.1.0
검색 증강 생성 (RAG) 시스템은 인공 지능 분야에서 중요한 개발 방향이되어 대규모 언어 모델의 세대 기능을 외부 지식 기반의 정확한 정보와 결합하여보다 정확하고 신뢰할 수있는 답변을 제공합니다. 그러나 RAG 시스템을위한 지식 기반을 구축하고 유지하는 것은 특히 많은 양의 구조화되지 않은 문서를 다룰 때 항상 시간이 많이 걸리고 복잡한 프로세스였습니다. 최근에, 우리는 검색 증강 생성 (RAG) 시스템을위한 자동화 된 Q & A (QA) 생성 도구를 개발하고 있습니다. 이 프로젝트는 프로세스를 다양한 형식의 구조화 된 질문 및 답변 쌍으로 변환하여 RAG 시스템의 지식 기반에 원활하게 통합하여 위의 과제를 완화하는 것을 목표로합니다.
이 프로젝트는 실제 RAG 시스템 개발에서 발생하는 과제에서 비롯된 것인데, 그 중 일반 동기는 다음과 같습니다.
특히, 우리의 전반적인 기술 솔루션은 다음 부분으로 요약 될 수 있습니다.
git clone https://github.com/wangxb96/RAG-QA-Generator.git
cd RAG-QA-Generator
pip install -r requirements.txt
base_url = 'http://your-api-url/v1/'
api_key = 'your-api-key'
headers = {"Authorization": f"Bearer {api_key}"}
client = OpenAI(
api_key="your-openai-api-key",
base_url="http://your-openai-api-url/v1",
)
streamlit run AutoQAG.py
응용 프로그램 인터페이스는 두 가지 주요 부분으로 나뉩니다.
 헝겊 관리 홈페이지
헝겊 관리 홈페이지
 파일 업로드 및 QA 쌍 생성
파일 업로드 및 QA 쌍 생성
 업데이트 된 버전은 여러 파일 업로드를 지원합니다
업데이트 된 버전은 여러 파일 업로드를 지원합니다
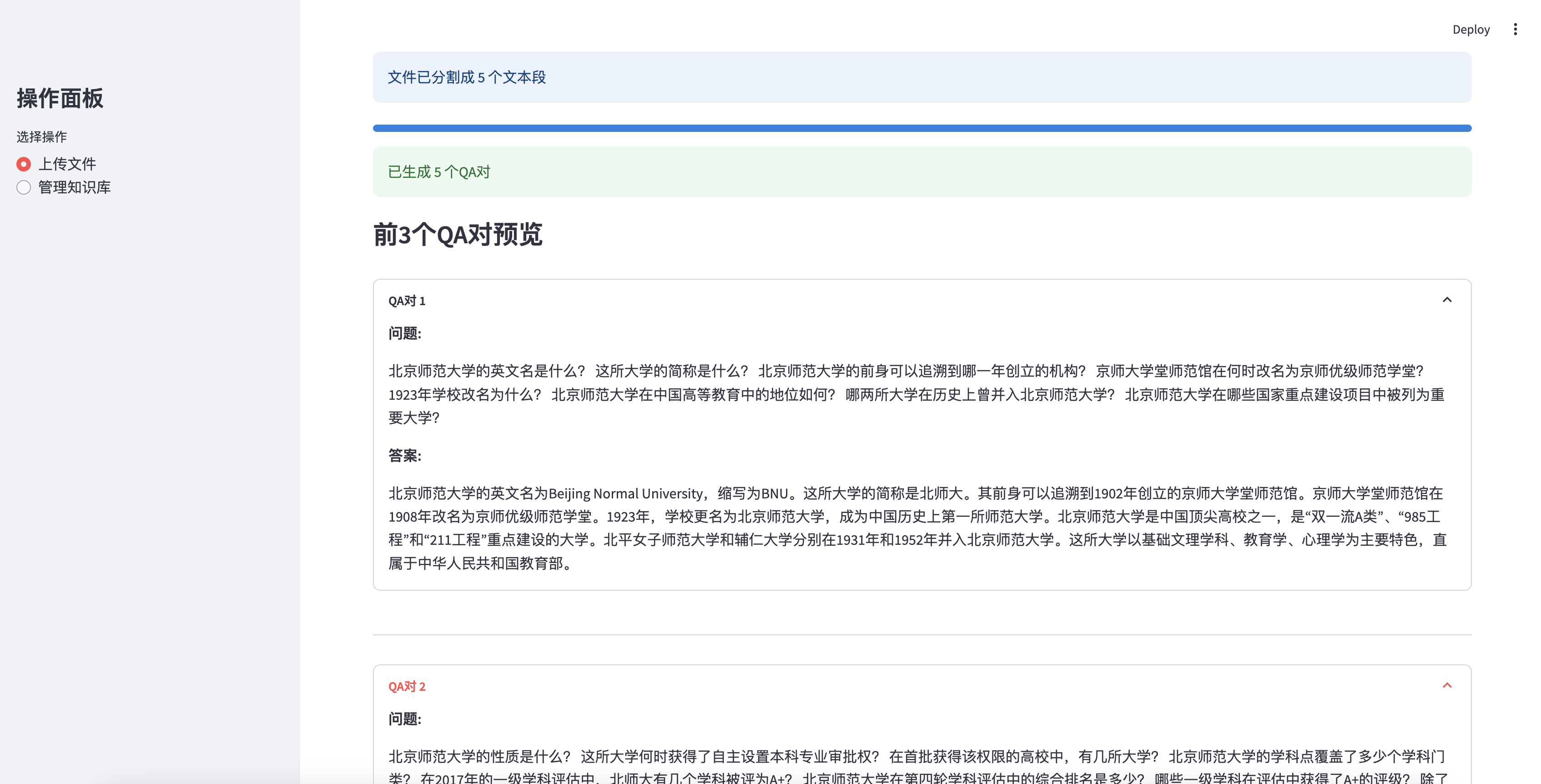 생성 된 처음 3 개의 QA 쌍을 미리 봅니다
생성 된 처음 3 개의 QA 쌍을 미리 봅니다
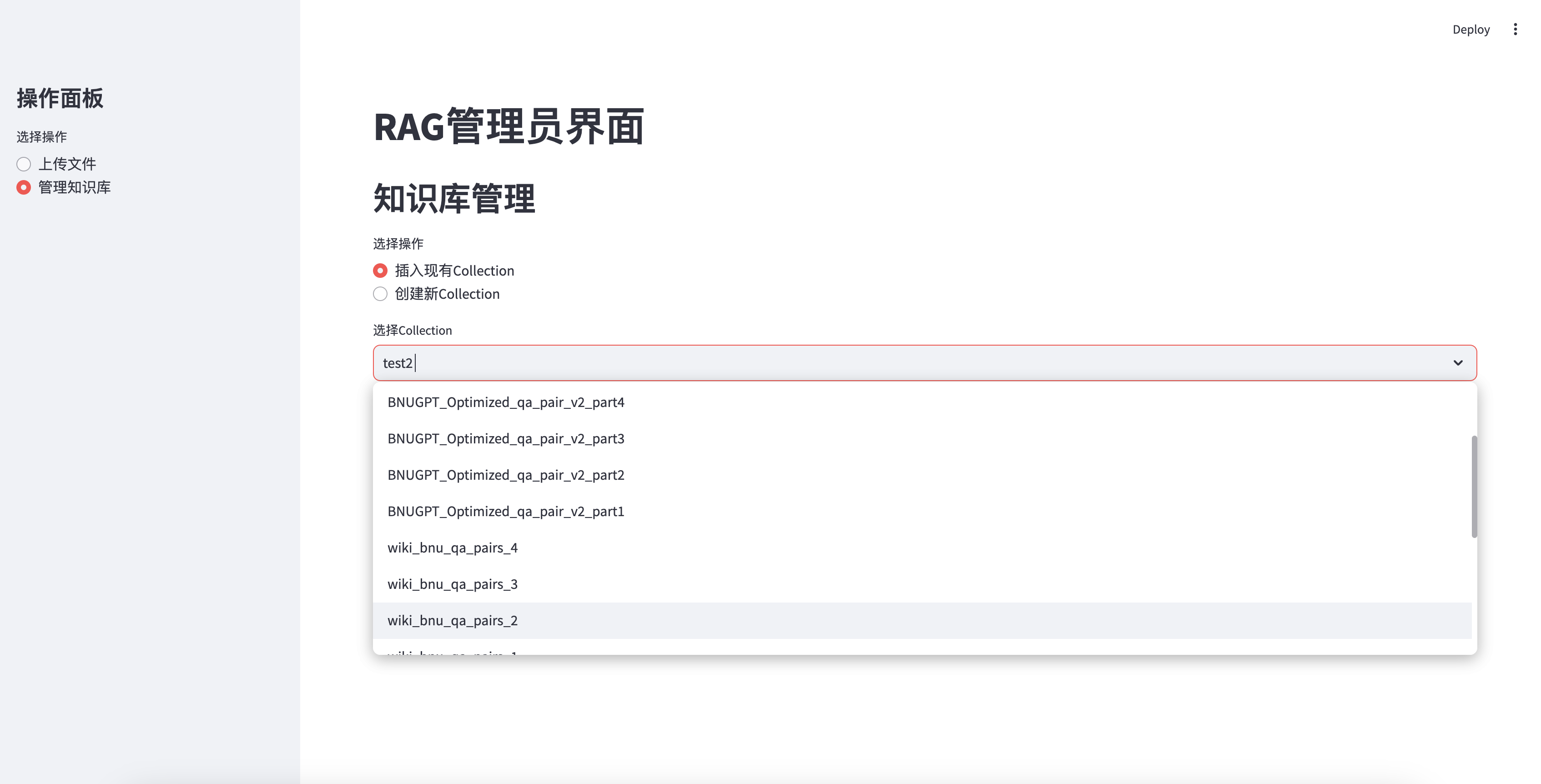 기존 지식 기반을 삽입하십시오
기존 지식 기반을 삽입하십시오
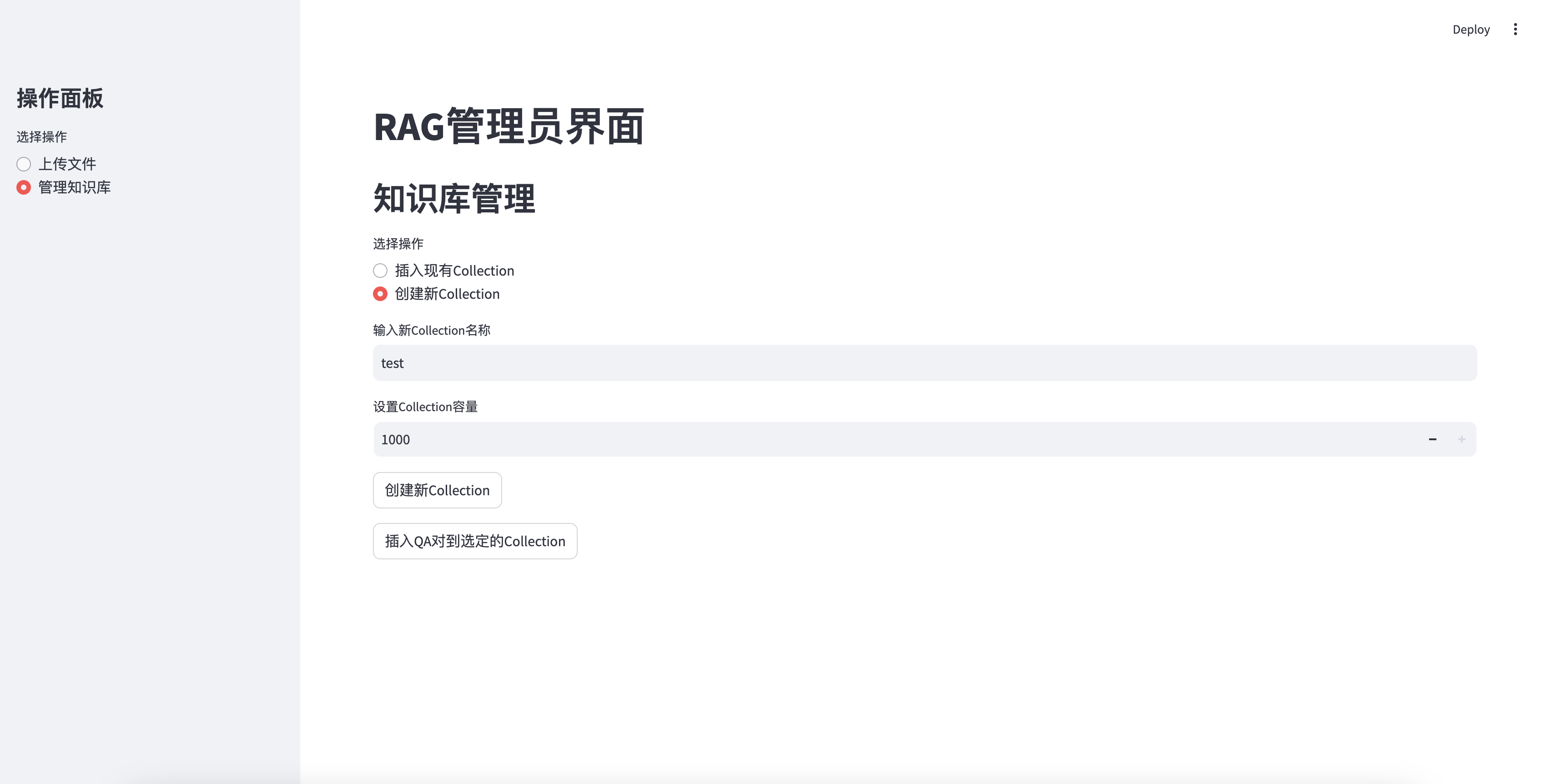 새로 생성 된 지식 기반을 삽입하십시오
새로 생성 된 지식 기반을 삽입하십시오
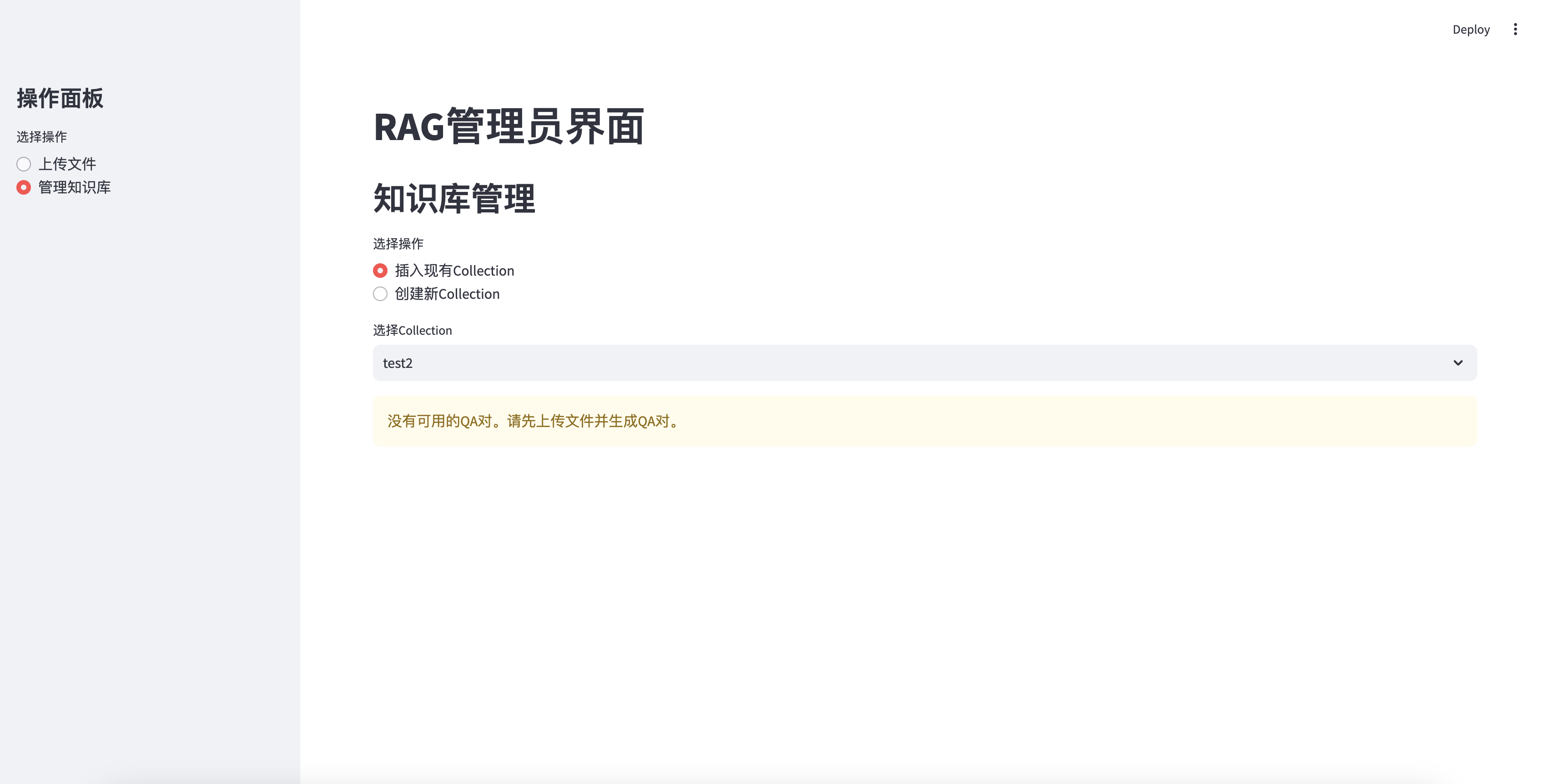 QA 없이는 삽입 할 수 없습니다
QA 없이는 삽입 할 수 없습니다
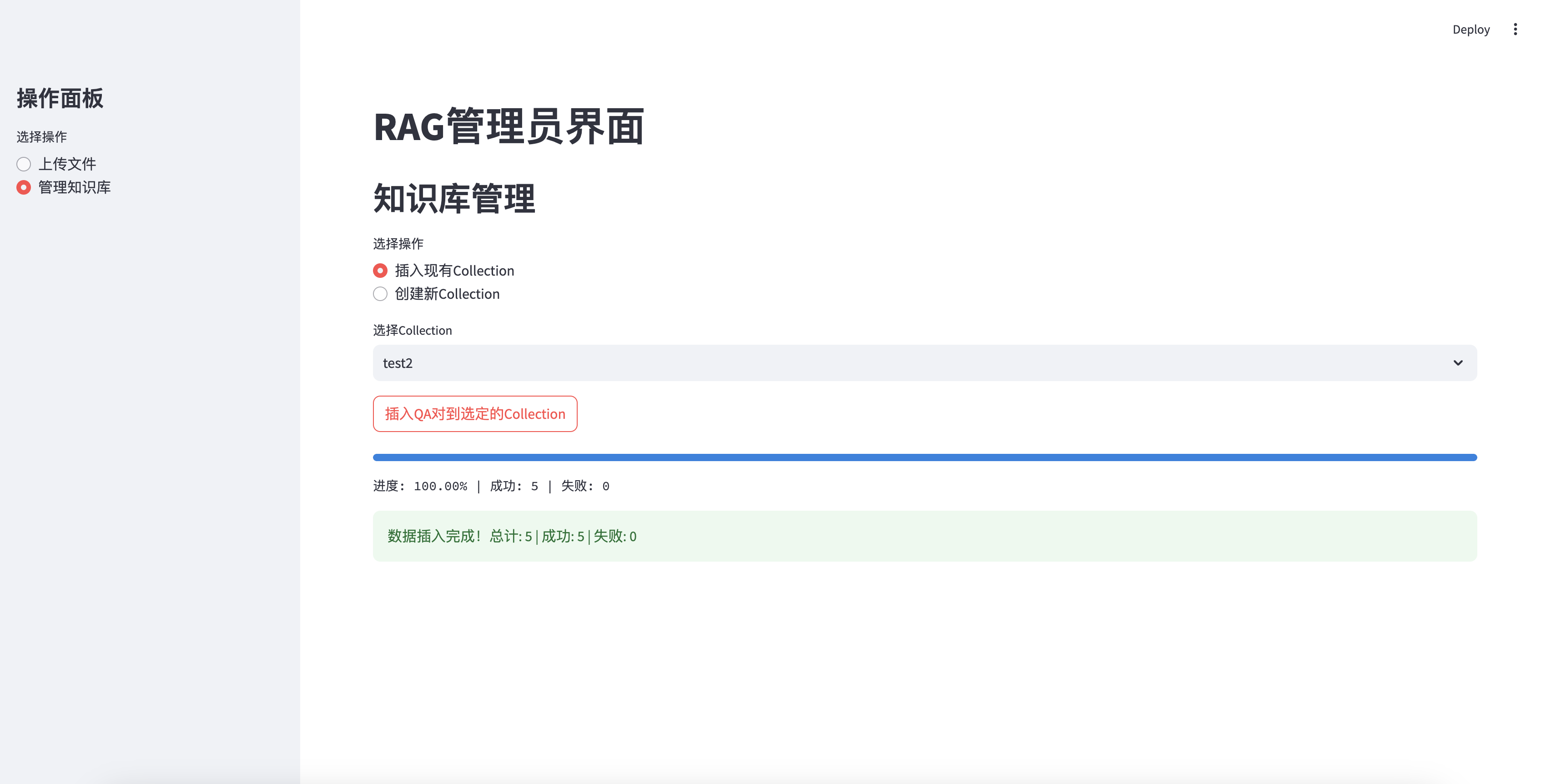 지식 기반에 성공적으로 삽입되었습니다
지식 기반에 성공적으로 삽입되었습니다
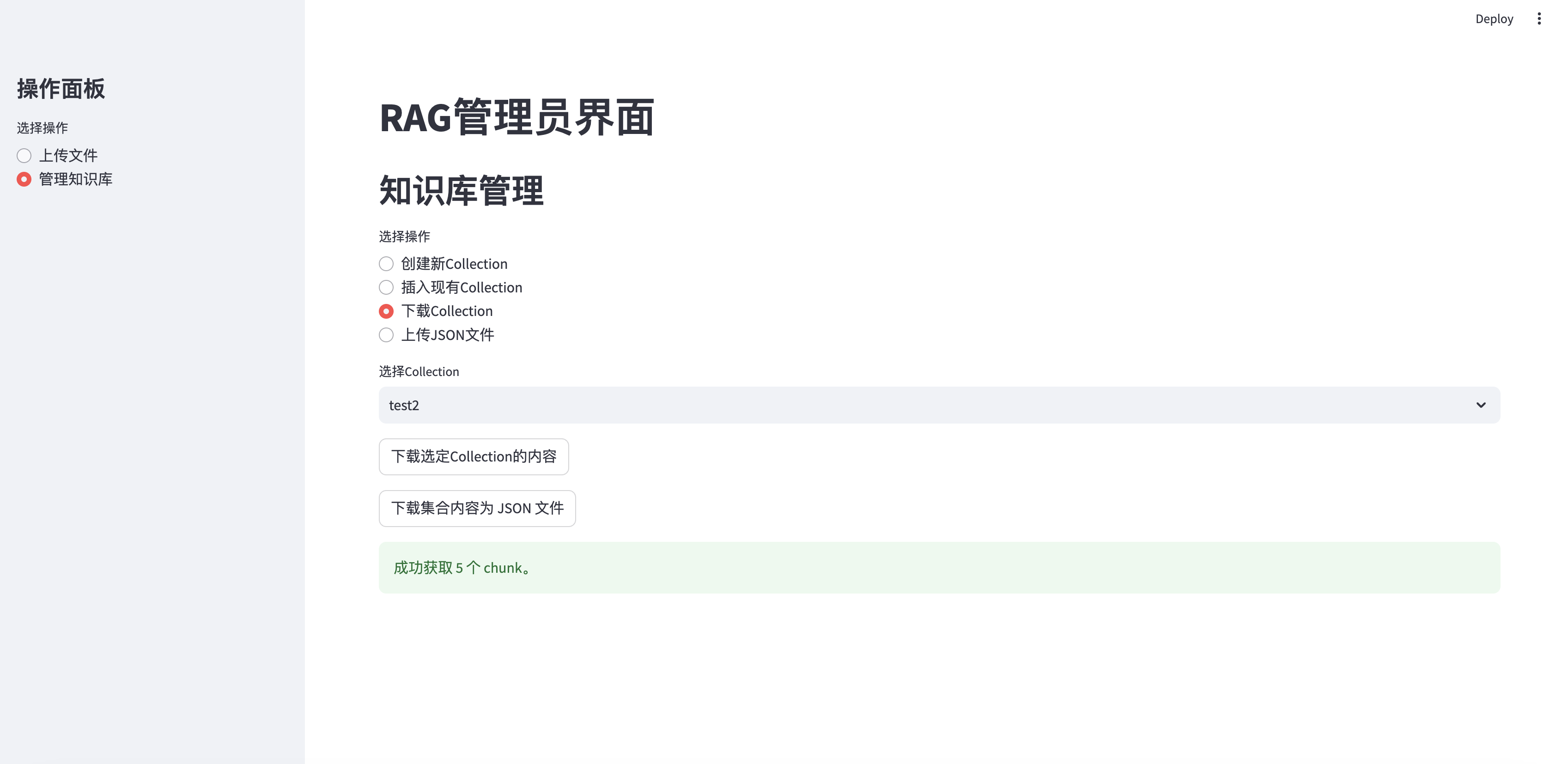 다운로드 컬렉션
다운로드 컬렉션
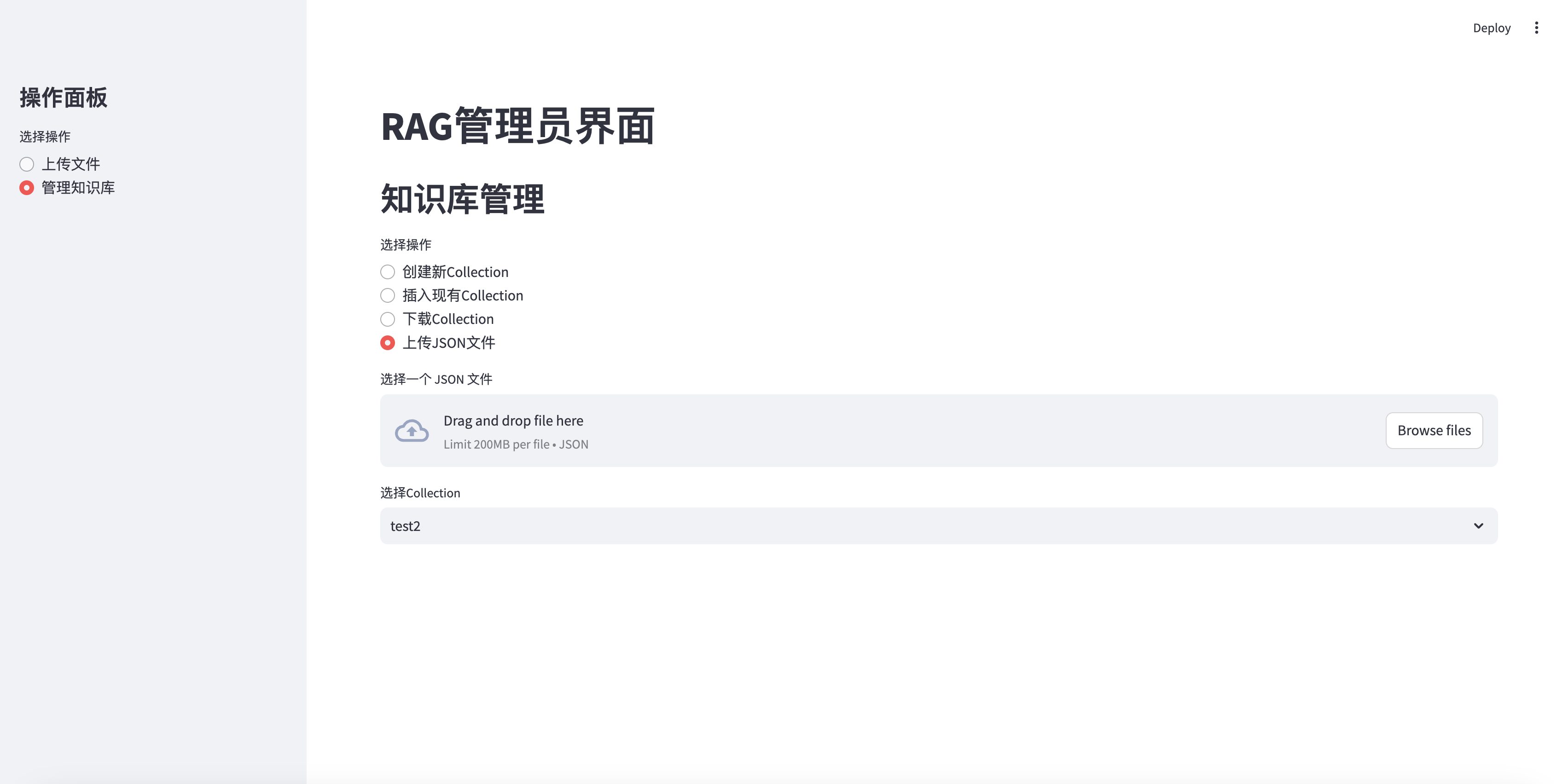 json 파일을 수집에 업로드하십시오
json 파일을 수집에 업로드하십시오
먼저 필요한 구성 및 초기화를 설정합니다.
base_url = 'your_knowledgebase_base_url'
api_key = 'your_knowledgebase_api_key'
headers = { "Authorization" : f"Bearer { api_key } " }
client = OpenAI (
api_key = "your_llm_api_key" ,
base_url = "your_llm_base_url" ,
)이 섹션에서는 API의 기본 URL 및 인증 정보와 OpenAI 클라이언트의 구성을 설정합니다.
기능 : 모델의 응답을 얻으십시오.
매개 변수 :
prompt : 모델로 보내는 텍스트 프롬프트.model : 사용 된 모델 이름, 기본값은 "QWEN25-72B"입니다.반환 : 모델에서 생성 된 응답 내용을 반환합니다. API를 호출하는 동안 오류가 발생하면 반환되지 않습니다.
def get_completion ( prompt , model = "qwen25-72b" ):
"""获取模型的响应"""
try :
response = client . chat . completions . create (
model = model ,
messages = [{ "role" : "user" , "content" : prompt }],
temperature = 0 ,
)
return response . choices [ 0 ]. message . content
except Exception as e :
st . error ( f"调用API时发生错误: { e } " )
return None 기능 :이 기능은 텍스트 블록을 기반으로 QA 쌍을 생성합니다 (여기서는 더 나은 QA 생성 전략을 설계하고 Propt를 조정하여 더 나은 생성을 달성 할 수 있습니다).
매개 변수 :
text_chunks : 질문과 답변 쌍을 생성하기위한 텍스트 블록 목록. 반품 : 생성 된 질문과 답변 목록을 반환합니다. def generate_qa_pairs_with_progress ( text_chunks ):
"""生成问答对并显示进度"""
qa_pairs = []
progress_bar = st . progress ( 0 )
for i , chunk in enumerate ( text_chunks ):
prompt = f"""基于以下给定的文本,生成一组高质量的问答对。请遵循以下指南:
1. 问题部分:
- 为同一个主题创建尽可能多的(如K个)不同表述的问题,确保问题的多样性。
- 每个问题应考虑用户可能的多种问法,例如:
- 直接询问(如“什么是...?”)
- 请求确认(如“是否可以说...?”)
- 寻求解释(如“请解释一下...的含义。”)
- 假设性问题(如“如果...会怎样?”)
- 例子请求(如“能否举个例子说明...?”)
- 问题应涵盖文本中的关键信息、主要概念和细节,确保不遗漏重要内容。
2. 答案部分:
- 提供一个全面、信息丰富的答案,涵盖问题的所有可能角度,确保逻辑连贯。
- 答案应直接基于给定文本,确保准确性和一致性。
- 包含相关的细节,如日期、名称、职位等具体信息,必要时提供背景信息以增强理解。
3. 格式:
- 使用 "Q:" 标记问题集合的开始,所有问题应在一个段落内,问题之间用空格分隔。
- 使用 "A:" 标记答案的开始,答案应清晰分段,便于阅读。
- 问答对之间用两个空行分隔,以提高可读性。
4. 内容要求:
- 确保问答对紧密围绕文本主题,避免偏离主题。
- 避免添加文本中未提及的信息,确保信息的真实性。
- 如果文本信息不足以回答某个方面,可以在答案中说明 "根据给定信息无法确定",并尽量提供相关的上下文。
5. 示例结构(仅供参考,实际内容应基于给定文本):
给定文本:
{ chunk }
请基于这个文本生成问答对。
"""
response = get_completion ( prompt )
if response :
try :
parts = response . split ( "A:" , 1 )
if len ( parts ) == 2 :
question = parts [ 0 ]. replace ( "Q:" , "" ). strip ()
answer = parts [ 1 ]. strip ()
qa_pairs . append ({ "question" : question , "answer" : answer })
else :
st . warning ( f"无法解析响应: { response } " )
except Exception as e :
st . warning ( f"处理响应时出错: { str ( e ) } " )
progress = ( i + 1 ) / len ( text_chunks )
progress_bar . progress ( progress )
return qa_pairs기능 : 일반적인 API 요청을 처리합니다.
매개 변수 :
method : HTTP 요청 방법 (예 : Get, Post 등).url : 요청 된 URL.kwargs : 기타 요청 매개 변수 (예 : 헤더, JSON 등). 반품 : API 응답의 "데이터"부분을 반환합니다. 요청이 실패하면 오류 메시지가 표시되고 리턴되지 않습니다. def api_request ( method , url , ** kwargs ):
try :
response = requests . request ( method , url , headers = headers , ** kwargs )
response . raise_for_status ()
return response . json (). get ( 'data' )
except requests . RequestException as e :
st . error ( f"API请求失败: { e } " )
return None 기능 : 새 컬렉션을 만듭니다.
매개 변수 :
name : 컬렉션의 이름.embedding_model_id : 임베디드 모델의 ID.capacity : 컬렉션의 용량. 반품 : 생성 된 컬렉션의 응답 데이터를 반환합니다. def create_collection ( name , embedding_model_id , capacity ):
data = {
"name" : name ,
"embedding_model_id" : embedding_model_id ,
"capacity" : capacity
}
return api_request ( "POST" , f" { base_url } collections" , json = data )기능 : 데이터 블록을 만듭니다.
매개 변수 :
collection_id : 컬렉션의 ID.content : 데이터 블록의 내용. 반환 : 생성 된 데이터 블록의 응답 데이터를 반환합니다. 요청이 실패하면 오류 메시지가 표시되고 리턴되지 않습니다. def create_chunk ( collection_id , content ):
data = {
"collection_id" : collection_id ,
"content" : content
}
endpoint = f" { base_url } collections/ { collection_id } /chunks"
try :
response = requests . post ( endpoint , headers = headers , json = data )
response . raise_for_status ()
return response . json ()[ 'data' ]
except requests . RequestException as e :
st . error ( f"创建chunk失败: { e } " )
return None 기능 : 지정된 컬렉션에 데이터 블록을 나열합니다.
매개 변수 :
collection_id : 컬렉션의 ID.limit : 반환 된 데이터 블록 수는 제한되어 있고 기본값은 20입니다.after : 페이징에 사용되는 매개 변수, 시작할 데이터 블록을 지정합니다. 반환 : 데이터 블록 목록을 반환합니다. 요청이 실패하면 오류 메시지가 표시되고 빈 목록이 반환됩니다. def list_chunks ( collection_id , limit = 20 , after = None ):
url = f" { base_url } collections/ { collection_id } /chunks"
params = {
"limit" : limit ,
"order" : "desc"
}
if after :
params [ "after" ] = after
response = api_request ( "GET" , url , params = params )
if response is not None :
return response
else :
st . error ( "列出 chunks 失败。" )
return []기능 : 특정 데이터 블록에 대한 자세한 정보를 얻으십시오.
매개 변수 :
chunk_id : 데이터 블록의 ID.collection_id : 컬렉션의 ID. 반품 : 데이터 블록의 세부 사항을 반환합니다. 요청이 실패하면 오류 메시지가 표시되고 리턴되지 않습니다. def get_chunk_details ( chunk_id , collection_id ):
url = f" { base_url } collections/ { collection_id } /chunks/ { chunk_id } "
response = api_request ( "GET" , url )
if response is not None :
return response
else :
st . error ( "获取 chunk 详细信息失败。" )
return None 기능 : 지정된 컬렉션에서 모든 데이터 블록을 가져옵니다.
매개 변수 :
collection_id : 컬렉션의 ID. 반품 : 모든 데이터 블록에 대한 자세한 정보 목록을 반환합니다. def fetch_all_chunks_from_collection ( collection_id ):
all_chunks = []
after = None
while True :
chunk_list = list_chunks ( collection_id , after = after )
if not chunk_list :
break
for chunk in chunk_list :
chunk_id = chunk [ 'chunk_id' ]
chunk_details = get_chunk_details ( chunk_id , collection_id )
if chunk_details :
all_chunks . append ( chunk_details )
if len ( chunk_list ) < 20 :
break
after = chunk_list [ - 1 ][ 'chunk_id' ]
return all_chunks기능 : 단일 문서를로드하십시오. 매개 변수 :
file_path : 문서의 파일 경로. 반품 :로드 된 문서 목록을 반환합니다. 파일 확장자가 지원되지 않으면 ValueError가 발생합니다. def load_single_document ( file_path : str ) -> List [ Document ]:
ext = "." + file_path . rsplit ( "." , 1 )[ - 1 ]
if ext in LOADER_MAPPING :
loader_class , loader_args = LOADER_MAPPING [ ext ]
loader = loader_class ( file_path , ** loader_args )
return loader . load ()
raise ValueError ( f"Unsupported file extension ' { ext } '" )기능 : 업로드 된 파일을 프로세스하고 텍스트 블록을 생성합니다. 매개 변수 :
uploaded_file : 업로드 된 파일 개체. 반환 : 생성 된 텍스트 블록 목록을 반환합니다. 파일 처리가 실패하면 빈 목록이 반환됩니다. def process_file ( uploaded_file ):
with tempfile . NamedTemporaryFile ( delete = False , suffix = os . path . splitext ( uploaded_file . name )[ 1 ]) as tmp_file :
tmp_file . write ( uploaded_file . getvalue ())
tmp_file_path = tmp_file . name
try :
documents = load_single_document ( tmp_file_path )
if not documents :
st . error ( "文件处理失败,请检查文件格式是否正确。" )
return []
text_splitter = RecursiveCharacterTextSplitter ( chunk_size = 2000 , chunk_overlap = 500 )
text_chunks = text_splitter . split_documents ( documents )
return text_chunks
except Exception as e :
st . error ( f"处理文件时发生错误: { e } " )
return []
finally :
os . unlink ( tmp_file_path )기능 : 다중 업로드 된 파일을 처리하고 텍스트 블록을 생성합니다. 매개 변수 :
uploaded_files : 업로드 된 파일 개체 목록. 반환 : 생성 된 모든 텍스트 블록의 목록을 반환합니다. def process_files ( uploaded_files ):
all_text_chunks = []
for uploaded_file in uploaded_files :
with tempfile . NamedTemporaryFile ( delete = False , suffix = os . path . splitext ( uploaded_file . name )[ 1 ]) as tmp_file :
tmp_file . write ( uploaded_file . getvalue ())
tmp_file_path = tmp_file . name
try :
documents = load_single_document ( tmp_file_path )
if not documents :
st . error ( f"文件 { uploaded_file . name } 处理失败,请检查文件格式是否正确。" )
continue
text_splitter = RecursiveCharacterTextSplitter ( chunk_size = 2000 , chunk_overlap = 500 )
text_chunks = text_splitter . split_documents ( documents )
all_text_chunks . extend ( text_chunks )
except Exception as e :
st . error ( f"处理文件 { uploaded_file . name } 时发生错误: { e } " )
finally :
os . unlink ( tmp_file_path )
return all_text_chunks기능 : Q & A 쌍을 데이터베이스에 삽입하십시오.
매개 변수 :
collection_id : Q & A 쌍을 삽입하는 Collection ID. 반품 : 성공적으로 삽입 된 Q & A 쌍의 수와 실패한 수를 반환합니다. def insert_qa_pairs_to_database ( collection_id ):
progress_bar = st . progress ( 0 )
status_text = st . empty ()
success_count = 0
fail_count = 0
for i , qa_pair in enumerate ( st . session_state . qa_pairs ):
try :
if "question" in qa_pair and "answer" in qa_pair and "chunk" in qa_pair :
content = f"问题: { qa_pair [ 'question' ] } n答案: { qa_pair [ 'answer' ] } n原文: { qa_pair [ 'chunk' ] } "
if len ( content ) > 4000 :
content = content [: 4000 ]
if create_chunk ( collection_id = collection_id , content = content ):
success_count += 1
else :
fail_count += 1
st . warning ( f"插入QA对 { i + 1 } 失败" )
else :
fail_count += 1
st . warning ( f"QA对 { i + 1 } 格式无效" )
except Exception as e :
st . error ( f"插入QA对 { i + 1 } 时发生错误: { str ( e ) } " )
fail_count += 1
progress = ( i + 1 ) / len ( st . session_state . qa_pairs )
progress_bar . progress ( progress )
status_text . text ( f"进度: { progress :.2% } | 成功: { success_count } | 失败: { fail_count } " )
return success_count , fail_count기능 : 데이터 블록을 JSON 파일로 다운로드하여 명확하게 포맷하십시오.
매개 변수 :
chunks : 데이터 블록 목록.collection_name : 다운로드 된 파일의 이름을 생성하는 데 사용되는 컬렉션의 이름입니다. 반환 : 반환 값이없고 다운로드 버튼을 직접 제공하십시오. def download_chunks_as_json ( chunks , collection_name ):
if chunks :
json_data = { "chunks" : []}
for chunk in chunks :
json_data [ "chunks" ]. append ({
"chunk_id" : chunk . get ( "chunk_id" ),
"record_id" : chunk . get ( "record_id" ),
"collection_id" : chunk . get ( "collection_id" ),
"content" : chunk . get ( "content" ),
"num_tokens" : chunk . get ( "num_tokens" ),
"metadata" : chunk . get ( "metadata" , {}),
"updated_timestamp" : chunk . get ( "updated_timestamp" ),
"created_timestamp" : chunk . get ( "created_timestamp" ),
})
json_str = json . dumps ( json_data , ensure_ascii = False , indent = 4 )
st . download_button (
label = "下载集合内容为 JSON 文件" ,
data = json_str ,
file_name = f" { collection_name } .json" ,
mime = "application/json"
)기능 : JSON 파일에서 지정된 컬렉션으로 데이터 블록을 업로드합니다.
매개 변수 :
uploaded_json_file : 업로드 된 JSON 파일 개체.collection_id : 업로드 할 데이터 블록의 수집 ID. 반환 : 반환 값이없고 인터페이스에 업로드 진행 상황과 결과를 직접 표시하십시오. def upload_json_chunks ( uploaded_json_file , collection_id ):
try :
data = json . load ( uploaded_json_file )
if 'chunks' not in data :
st . error ( "JSON 文件中缺少 'chunks' 键。" )
return
chunks = data [ 'chunks' ]
total_records = len ( chunks )
records_per_collection = 1000
num_collections = math . ceil ( total_records / records_per_collection )
st . write ( f"总记录数: { total_records } " )
st . write ( f"每个集合的记录数: { records_per_collection } " )
st . write ( f"需要创建的集合数: { num_collections } " )
for i in range ( num_collections ):
st . write ( f" n导入集合 { i + 1 } / { num_collections } ..." )
start_index = i * records_per_collection
end_index = min (( i + 1 ) * records_per_collection , total_records )
progress_bar = st . progress ( 0 )
for j , chunk in enumerate ( chunks [ start_index : end_index ]):
if 'content' in chunk :
content = chunk [ 'content' ]
try :
create_chunk (
collection_id = collection_id ,
content = content
)
except Exception as e :
st . error ( f"创建 chunk 时出错: { str ( e ) } " )
break
else :
st . warning ( f"第 { start_index + j + 1 } 条记录缺少 'content' 键。" )
continue
progress = ( j + 1 ) / ( end_index - start_index )
progress_bar . progress ( progress )
st . success ( "所有数据导入完成。" )
except Exception as e :
st . error ( f"上传 JSON 文件时发生错误: { str ( e ) } " )기본 인터페이스 구조는 main () 함수로 정의됩니다.
def main ():
st . set_page_config ( page_title = "RAG管理员界面" , layout = "wide" )
st . title ( "RAG管理员界面" )
# 侧边栏
st . sidebar . title ( "操作面板" )
operation = st . sidebar . radio ( "选择操作" , [ "上传文件" , "管理知识库" ])
if operation == "上传文件" :
# 文件上传和处理逻辑
...
elif operation == "管理知识库" :
# 知识库管理逻辑
...
if __name__ == "__main__" :
main () if operation == "上传文件" :
st . header ( "文件上传与QA对生成" )
uploaded_files = st . file_uploader ( "上传非结构化文件" , type = [ "txt" , "pdf" , "docx" ], accept_multiple_files = True )
if uploaded_files :
st . success ( "文件上传成功!" )
if st . button ( "处理文件并生成QA对" ):
with st . spinner ( "正在处理文件..." ):
text_chunks = process_files ( uploaded_files )
if not text_chunks :
st . error ( "文件处理失败,请检查文件格式是否正确。" )
return
st . info ( f"文件已分割成 { len ( text_chunks ) } 个文本段" )
with st . spinner ( "正在生成QA对..." ):
st . session_state . qa_pairs = generate_qa_pairs_with_progress ( text_chunks )
st . success ( f"已生成 { len ( st . session_state . qa_pairs ) } 个QA对" )
if st . session_state . qa_pairs :
st . subheader ( "前3个QA对预览" )
cols = st . columns ( 3 )
for i , qa in enumerate ( st . session_state . qa_pairs [: 3 ]):
with st . expander ( f"**QA对 { i + 1 } **" , expanded = True ):
st . markdown ( "**问题:**" )
st . markdown ( qa [ 'question' ])
st . markdown ( "**答案:**" )
st . markdown ( qa [ 'answer' ])
st . markdown ( "**原文:**" )
st . markdown ( qa [ 'chunk' ])
st . markdown ( "---" )
else :
st . warning ( "请上传文件。" ) elif operation == "管理知识库" :
st . header ( "知识库管理" )
option = st . radio ( "选择操作" , ( "创建新Collection" , "插入现有Collection" , "下载Collection" , "上传JSON文件" ))
if option == "插入现有Collection" :
if st . session_state . collections :
collection_names = [ c [ 'name' ] for c in st . session_state . collections ]
selected_collection = st . selectbox ( "选择Collection" , collection_names )
selected_id = next ( c [ 'collection_id' ] for c in st . session_state . collections if c [ 'name' ] == selected_collection )
if st . button ( "插入QA对到选定的Collection" ):
if hasattr ( st . session_state , 'qa_pairs' ) and st . session_state . qa_pairs :
with st . spinner ( "正在插入QA对..." ):
success_count , fail_count = insert_qa_pairs_to_database ( selected_id )
st . success ( f"数据插入完成!总计: { len ( st . session_state . qa_pairs ) } | 成功: { success_count } | 失败: { fail_count } " )
else :
st . warning ( "没有可用的QA对。请先上传文件并生成QA对。" )
else :
st . warning ( "没有可用的 Collections,请创建新的 Collection。" )
elif option == "创建新Collection" :
new_collection_name = st . text_input ( "输入新Collection名称" )
capacity = st . number_input ( "设置Collection容量" , min_value = 1 , max_value = 1000 , value = 1000 )
if st . button ( "创建新Collection" ):
with st . spinner ( "正在创建新Collection..." ):
new_collection = create_collection (
name = new_collection_name ,
embedding_model_id = embedding , # 这里可以替换为实际的模型ID
capacity = capacity
)
if new_collection :
st . success ( f"新Collection创建成功,ID: { new_collection [ 'collection_id' ] } " )
# 立即更新 collections 列表
st . session_state . collections = api_request ( "GET" , f" { base_url } collections" )
st . rerun ()
else :
st . error ( "创建新Collection失败" )
elif option == "下载Collection" :
if st . session_state . collections :
collection_names = [ c [ 'name' ] for c in st . session_state . collections ]
selected_collection = st . selectbox ( "选择Collection" , collection_names )
selected_id = next ( c [ 'collection_id' ] for c in st . session_state . collections if c [ 'name' ] == selected_collection )
if st . button ( "下载选定Collection的内容" ):
with st . spinner ( "正在获取集合内容..." ):
chunks = fetch_all_chunks_from_collection ( selected_id ) # Pass the API key
if chunks :
download_chunks_as_json ( chunks , selected_collection ) # Pass the collection name
st . success ( f"成功获取 { len ( chunks ) } 个 chunk。" )
else :
st . error ( "未能获取集合内容。" )
else :
st . warning ( "没有可用的 Collections,请创建新的 Collection。" )
elif option == "上传JSON文件" :
uploaded_json_file = st . file_uploader ( "选择一个 JSON 文件" , type = [ "json" ])
if st . session_state . collections :
collection_names = [ c [ 'name' ] for c in st . session_state . collections ]
selected_collection = st . selectbox ( "选择Collection" , collection_names )
selected_id = next ( c [ 'collection_id' ] for c in st . session_state . collections if c [ 'name' ] == selected_collection )
if uploaded_json_file is not None :
if st . button ( "上传并插入到选定的Collection" ):
with st . spinner ( "正在上传 JSON 文件并插入数据..." ):
upload_json_chunks ( uploaded_json_file , selected_id )
else :
st . warning ( "没有可用的 Collections,请创建新的 Collection。" )이 프로젝트는 베이징 일반 대학의 Zhuhai 캠퍼스의 인공 지능 및 미래 네트워크 센터, 베이징 노동 대학의 Zhuhai 캠퍼스의 지능형 크로스 컴퓨팅 센터 및 교육부의 엔지니어링 연구 센터, Beijing Normal University, Beijing Normal University의 교육부 공동 작업 센터에 의해 강력하게 지원되었습니다.


