RAG QA Generator
v1.1.0
Retrieval augmented generation (RAG) systems have become an important development direction in the field of artificial intelligence, combining the generation capabilities of large-scale language models with precise information from external knowledge bases to provide more accurate and reliable answers. However, building and maintaining a knowledge base for RAG systems has always been a time-consuming and complex process, especially when dealing with large amounts of unstructured documents. Recently, we are developing an automated Q&A (QA) generation tool for a Retrieval Augmentation Generation (RAG) system. This project aims to alleviate the above challenges by automating the process to convert documents in various formats into structured question and answer pairs and seamlessly integrate them into the knowledge base of the RAG system.
This project originates from challenges encountered in actual RAG system development, among which the general motivations are as follows:
In particular, our overall technical solution can be summarized into the following parts:
git clone https://github.com/wangxb96/RAG-QA-Generator.git
cd RAG-QA-Generator
pip install -r requirements.txt
base_url = 'http://your-api-url/v1/'
api_key = 'your-api-key'
headers = {"Authorization": f"Bearer {api_key}"}
client = OpenAI(
api_key="your-openai-api-key",
base_url="http://your-openai-api-url/v1",
)
streamlit run AutoQAG.py
The application interface is divided into two main parts:
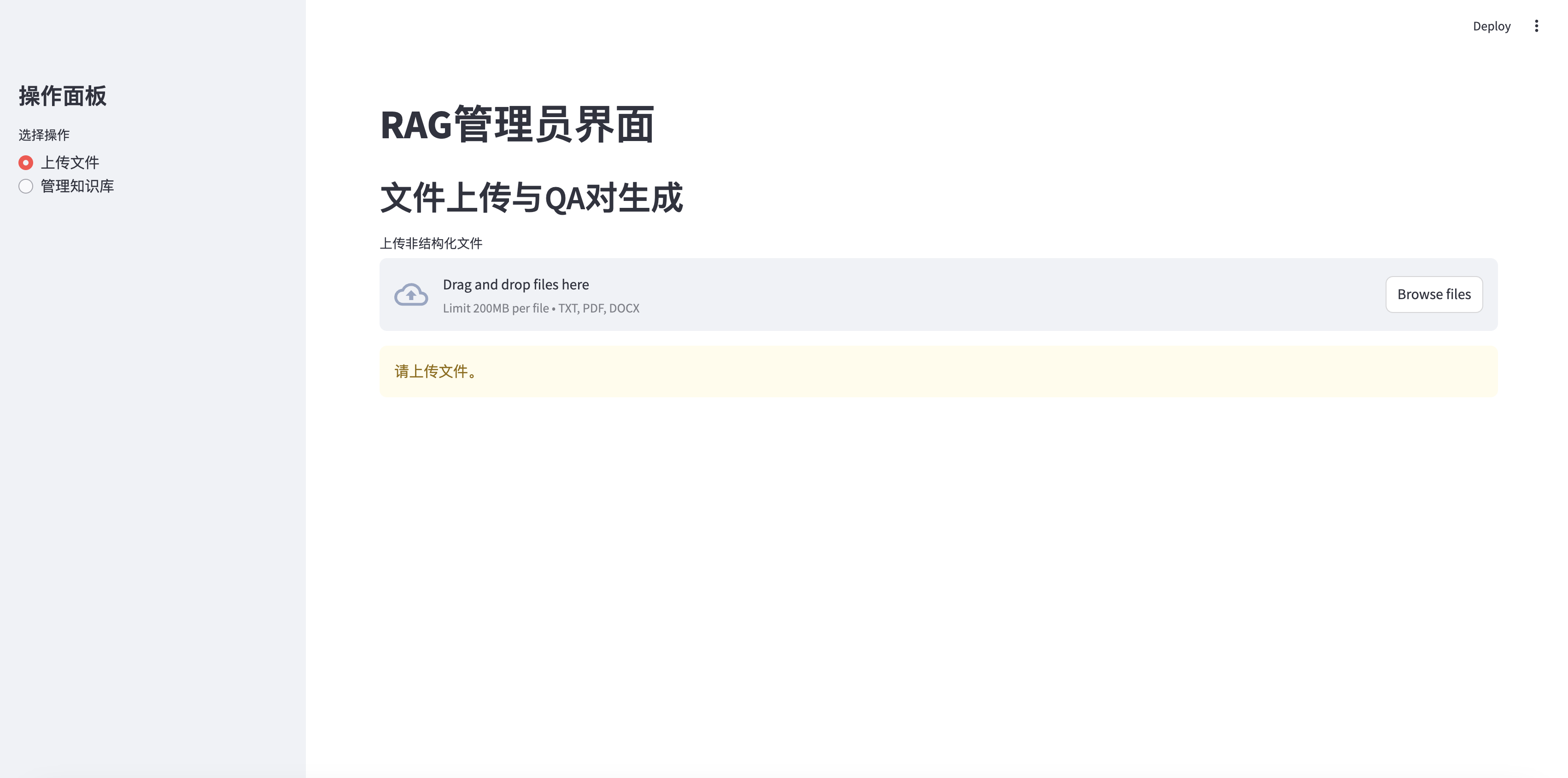 RAG Management Home Page
RAG Management Home Page
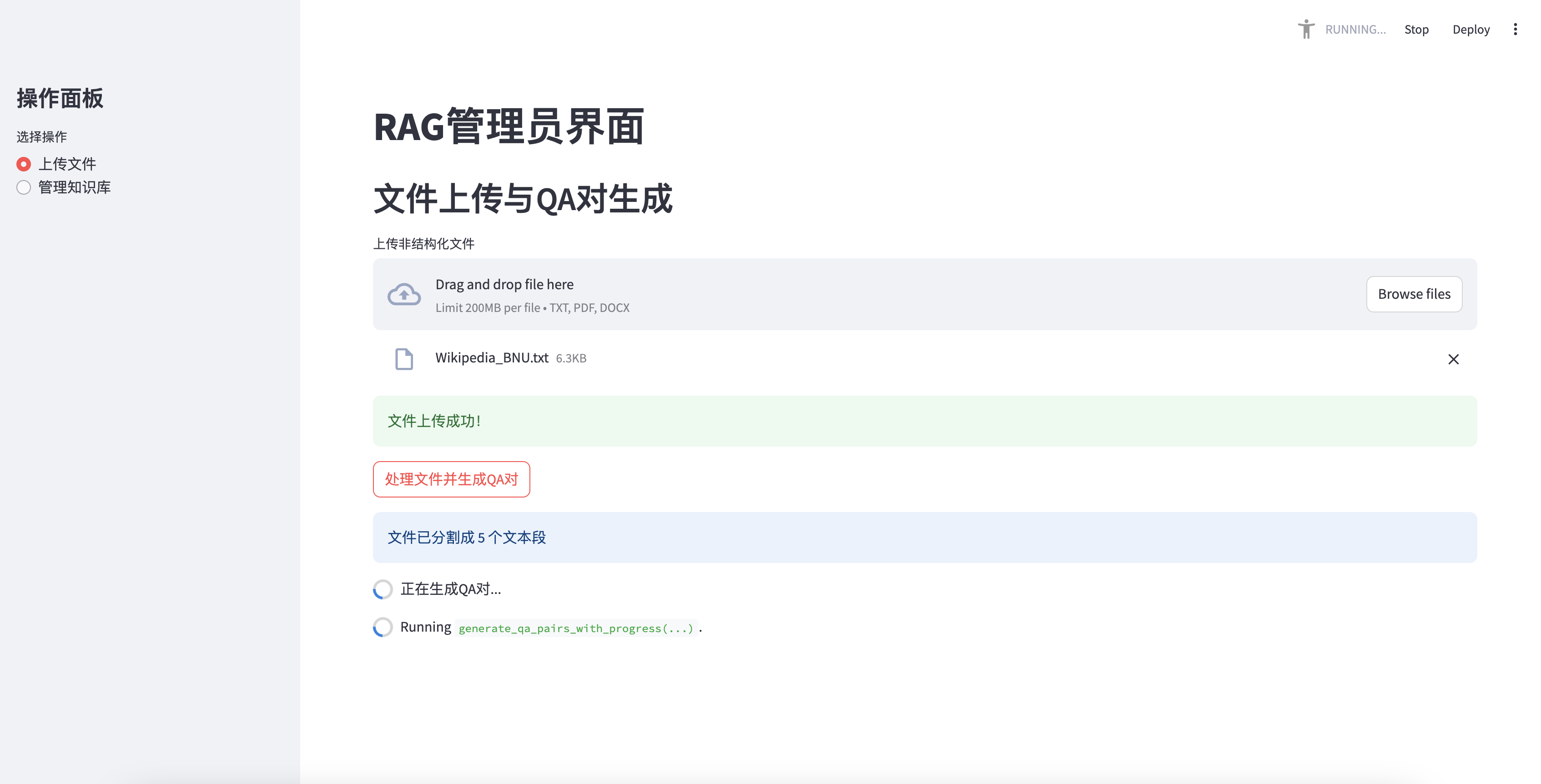 File upload and QA pair generation
File upload and QA pair generation
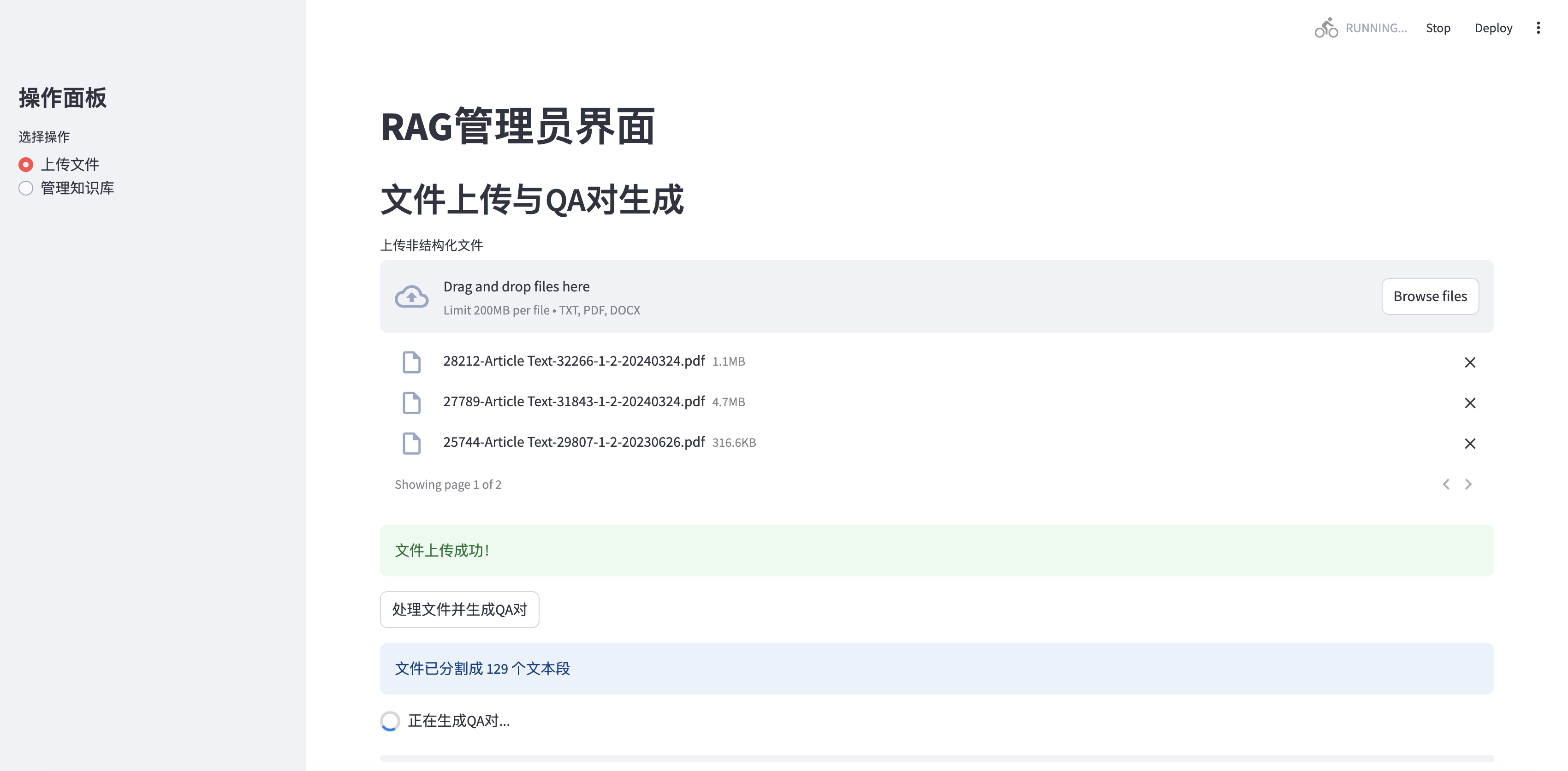 The updated version supports multiple file uploads
The updated version supports multiple file uploads
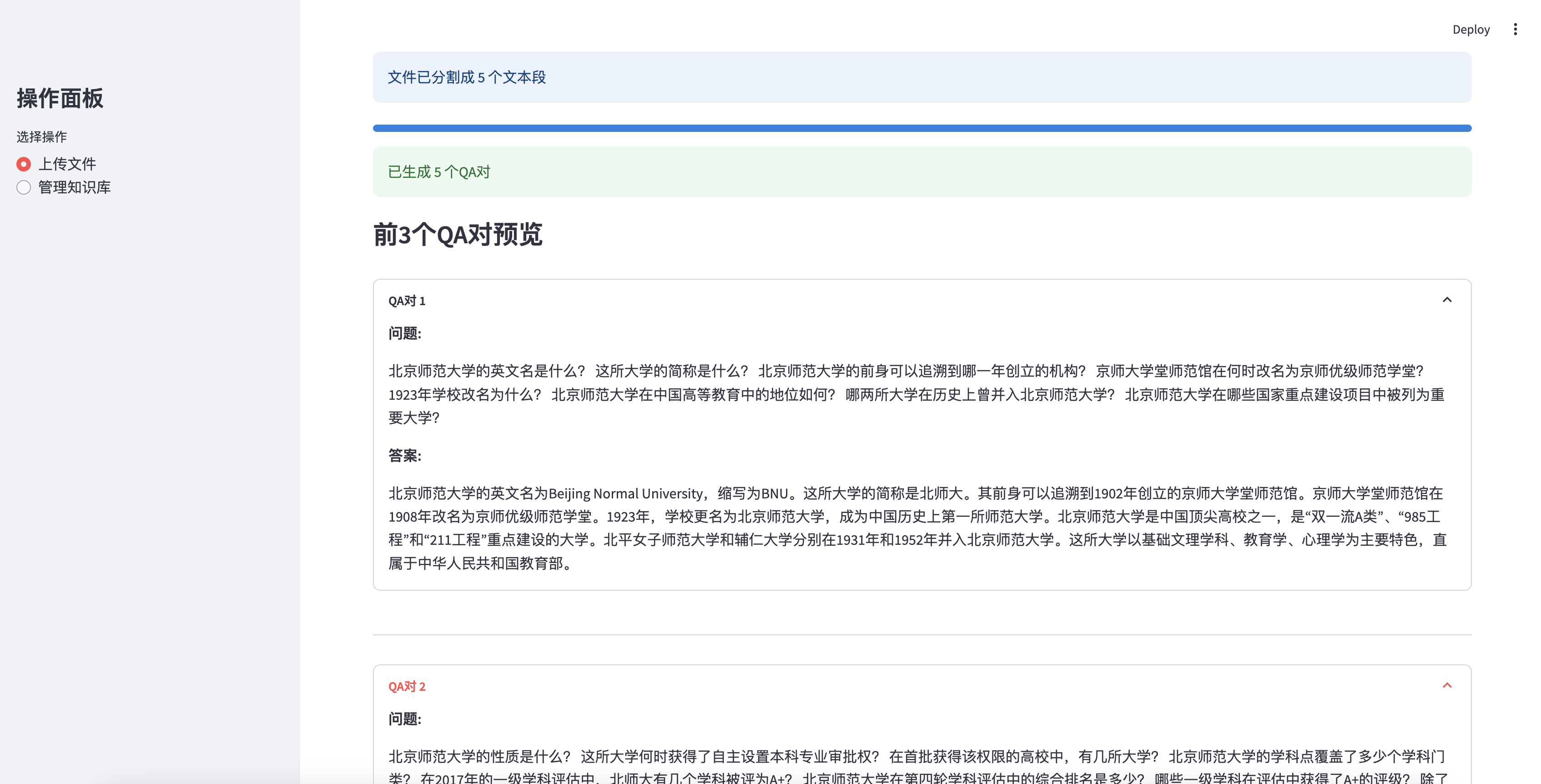 Preview the first 3 QA pairs generated
Preview the first 3 QA pairs generated
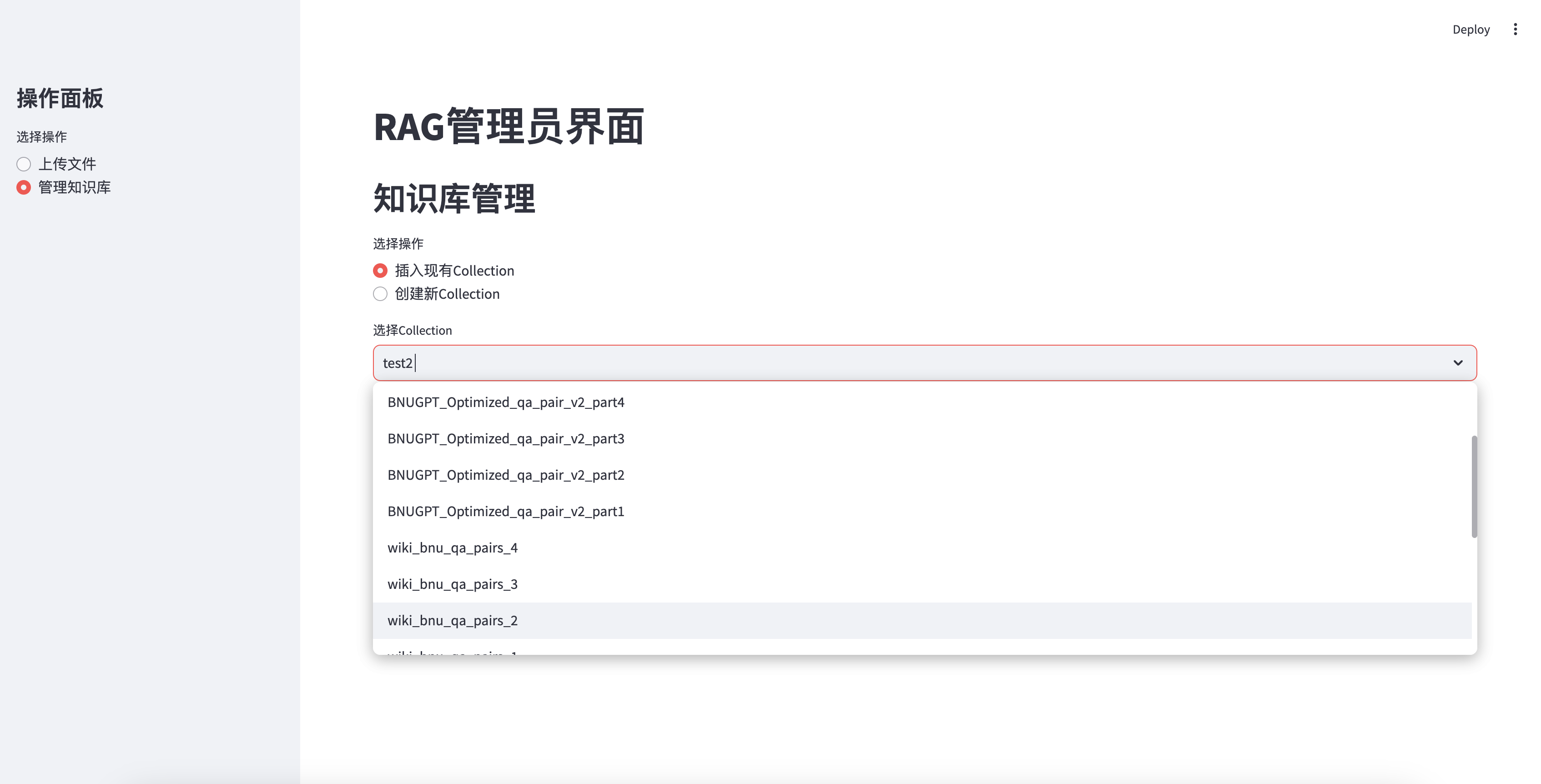 Insert existing knowledge base
Insert existing knowledge base
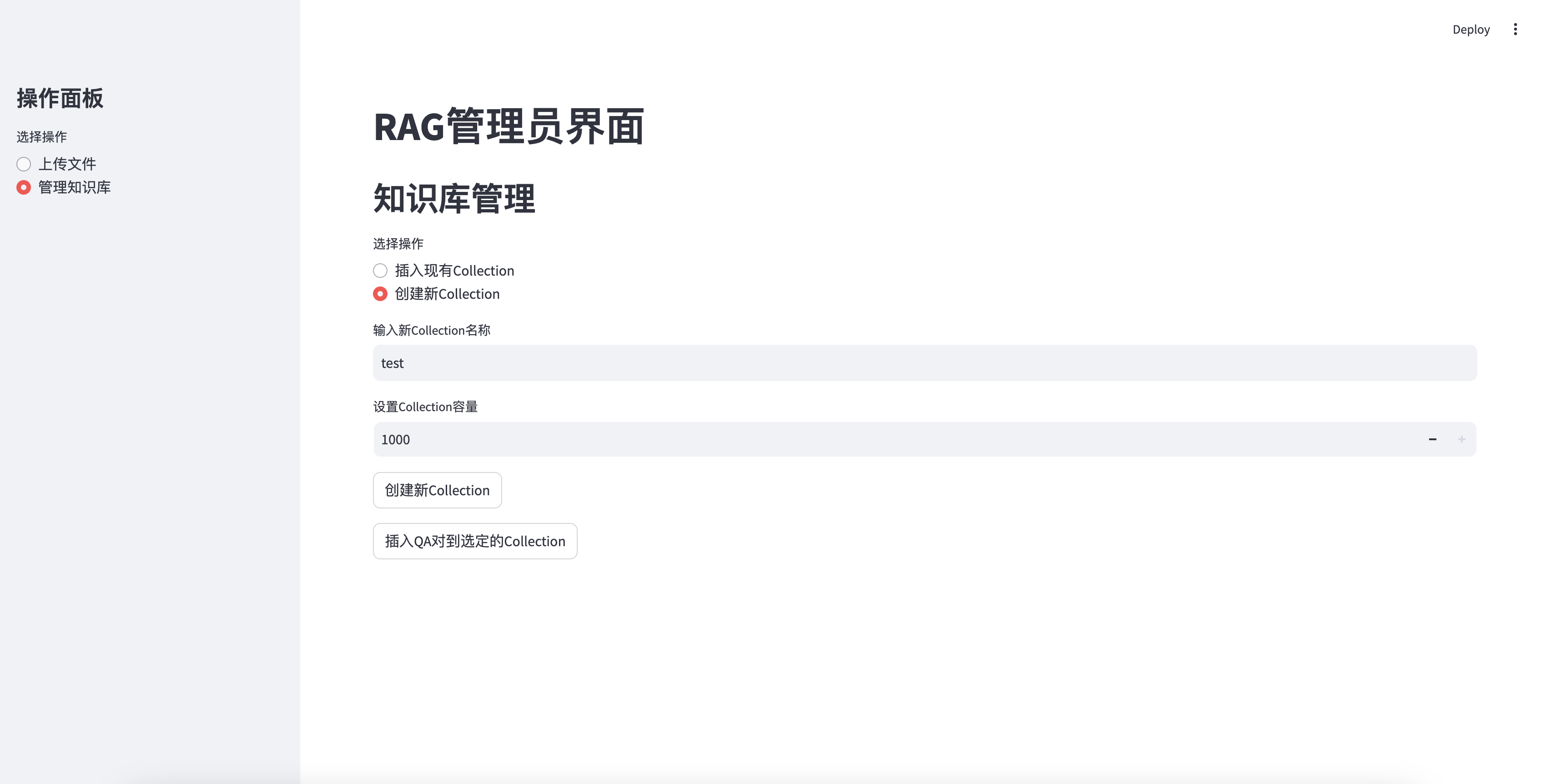 Insert a newly created knowledge base
Insert a newly created knowledge base
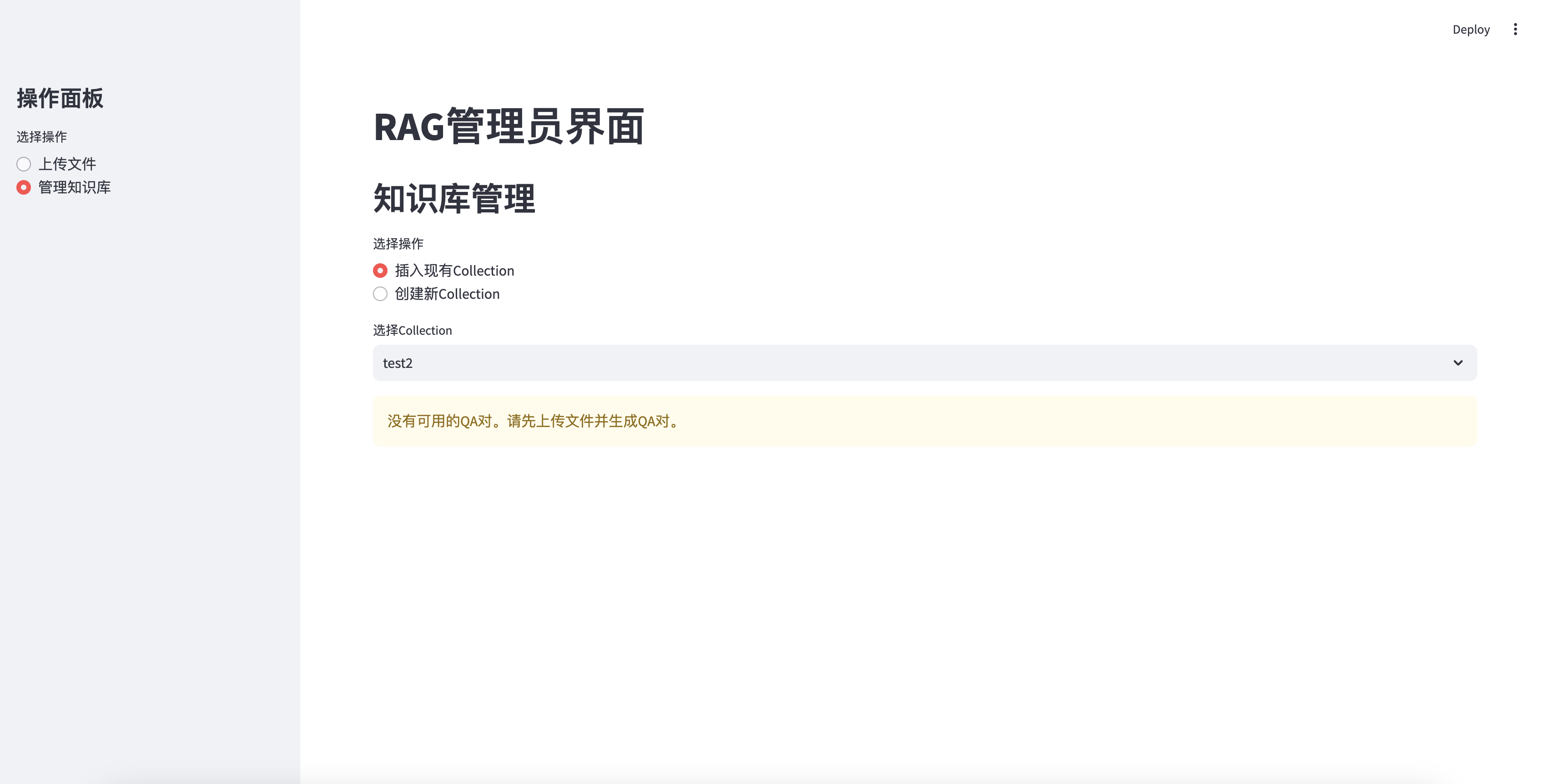 Cannot insert without QA
Cannot insert without QA
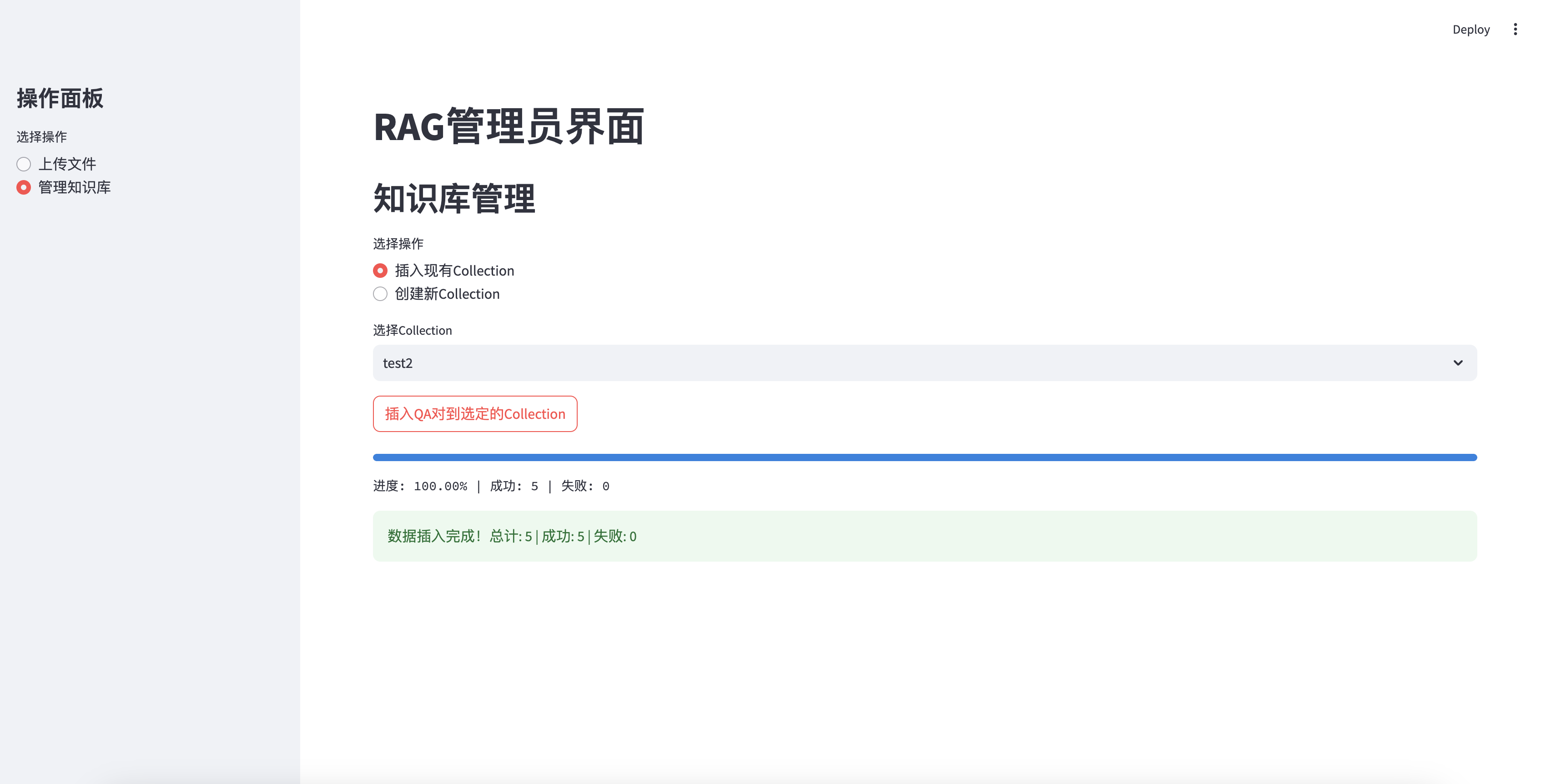 Successfully inserted into the knowledge base
Successfully inserted into the knowledge base
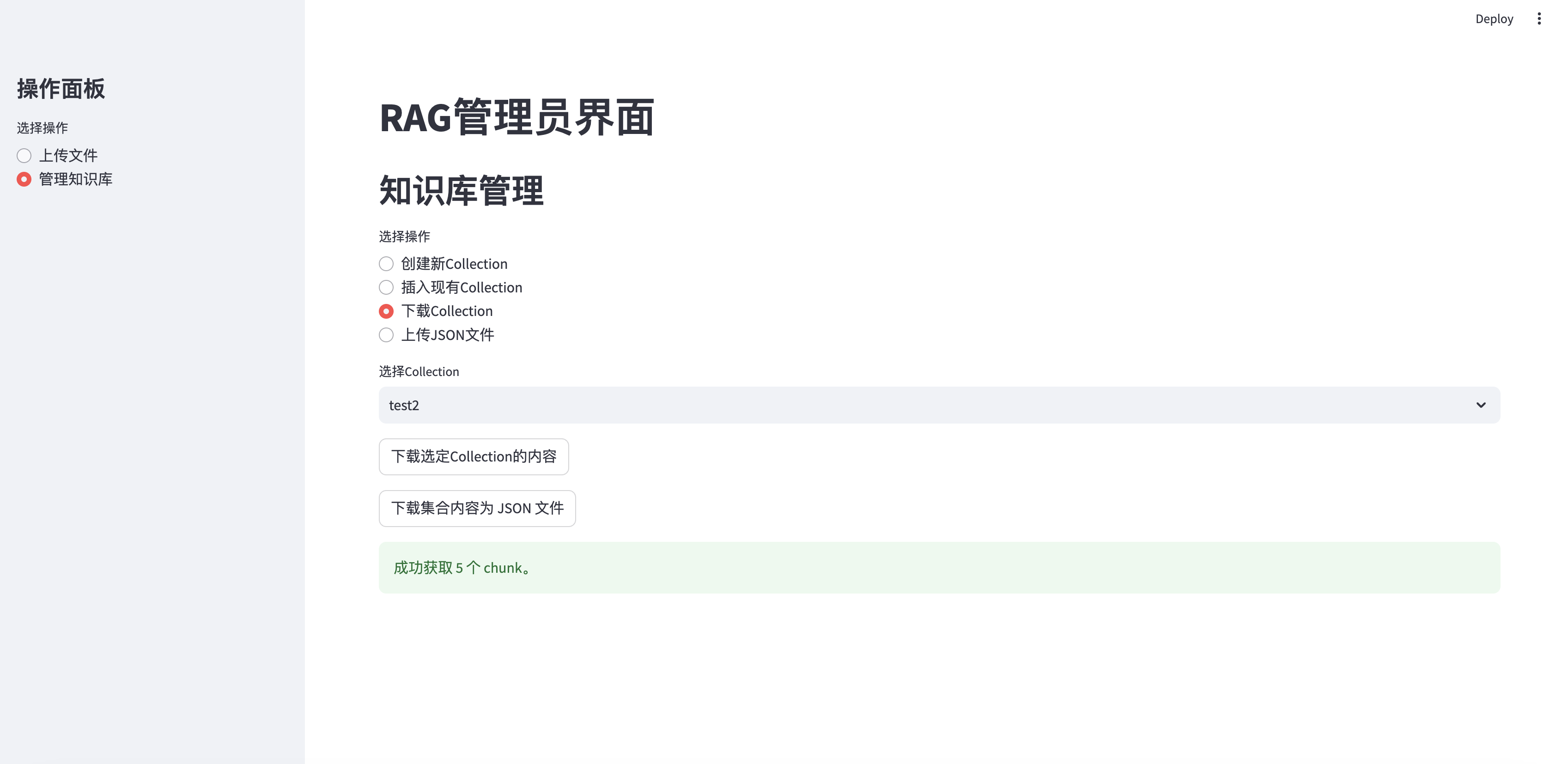 Download Collection
Download Collection
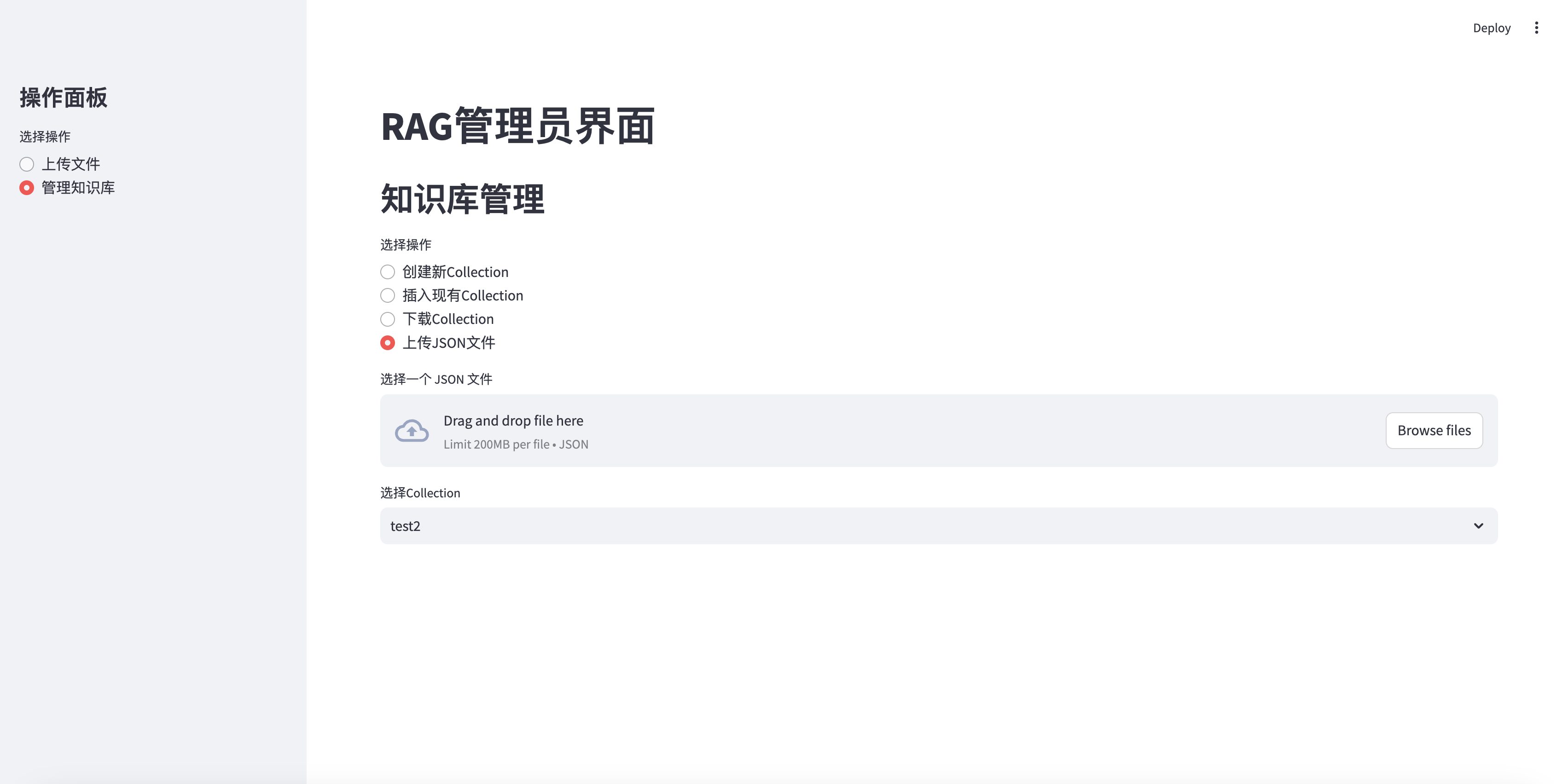 Upload JSON file to Collection
Upload JSON file to Collection
First, we set up the necessary configuration and initialization:
base_url = 'your_knowledgebase_base_url'
api_key = 'your_knowledgebase_api_key'
headers = { "Authorization" : f"Bearer { api_key } " }
client = OpenAI (
api_key = "your_llm_api_key" ,
base_url = "your_llm_base_url" ,
)This section sets the basic URL and authentication information of the API, as well as the configuration of the OpenAI client.
Function : Get the model's response.
parameter :
prompt : Text prompt to send to the model.model : The model name used, default is "qwen25-72b".Return : Returns the response content generated by the model. If an error occurs while calling the API, None is returned.
def get_completion ( prompt , model = "qwen25-72b" ):
"""获取模型的响应"""
try :
response = client . chat . completions . create (
model = model ,
messages = [{ "role" : "user" , "content" : prompt }],
temperature = 0 ,
)
return response . choices [ 0 ]. message . content
except Exception as e :
st . error ( f"调用API时发生错误: { e } " )
return None Function : This function generates QA pairs based on text blocks (here can design a better QA generation strategy and achieve better generation by adjusting propt).
parameter :
text_chunks : A list of text blocks to generate question and answer pairs. Return : Returns the generated list of questions and answers. def generate_qa_pairs_with_progress ( text_chunks ):
"""生成问答对并显示进度"""
qa_pairs = []
progress_bar = st . progress ( 0 )
for i , chunk in enumerate ( text_chunks ):
prompt = f"""基于以下给定的文本,生成一组高质量的问答对。请遵循以下指南:
1. 问题部分:
- 为同一个主题创建尽可能多的(如K个)不同表述的问题,确保问题的多样性。
- 每个问题应考虑用户可能的多种问法,例如:
- 直接询问(如“什么是...?”)
- 请求确认(如“是否可以说...?”)
- 寻求解释(如“请解释一下...的含义。”)
- 假设性问题(如“如果...会怎样?”)
- 例子请求(如“能否举个例子说明...?”)
- 问题应涵盖文本中的关键信息、主要概念和细节,确保不遗漏重要内容。
2. 答案部分:
- 提供一个全面、信息丰富的答案,涵盖问题的所有可能角度,确保逻辑连贯。
- 答案应直接基于给定文本,确保准确性和一致性。
- 包含相关的细节,如日期、名称、职位等具体信息,必要时提供背景信息以增强理解。
3. 格式:
- 使用 "Q:" 标记问题集合的开始,所有问题应在一个段落内,问题之间用空格分隔。
- 使用 "A:" 标记答案的开始,答案应清晰分段,便于阅读。
- 问答对之间用两个空行分隔,以提高可读性。
4. 内容要求:
- 确保问答对紧密围绕文本主题,避免偏离主题。
- 避免添加文本中未提及的信息,确保信息的真实性。
- 如果文本信息不足以回答某个方面,可以在答案中说明 "根据给定信息无法确定",并尽量提供相关的上下文。
5. 示例结构(仅供参考,实际内容应基于给定文本):
给定文本:
{ chunk }
请基于这个文本生成问答对。
"""
response = get_completion ( prompt )
if response :
try :
parts = response . split ( "A:" , 1 )
if len ( parts ) == 2 :
question = parts [ 0 ]. replace ( "Q:" , "" ). strip ()
answer = parts [ 1 ]. strip ()
qa_pairs . append ({ "question" : question , "answer" : answer })
else :
st . warning ( f"无法解析响应: { response } " )
except Exception as e :
st . warning ( f"处理响应时出错: { str ( e ) } " )
progress = ( i + 1 ) / len ( text_chunks )
progress_bar . progress ( progress )
return qa_pairsFunction : Handle common API requests.
parameter :
method : HTTP request method (such as GET, POST, etc.).url : The requested URL.kwargs : Other request parameters (such as headers, json, etc.). Return : Returns the "data" part of the API response. If the request fails, an error message is displayed and None is returned. def api_request ( method , url , ** kwargs ):
try :
response = requests . request ( method , url , headers = headers , ** kwargs )
response . raise_for_status ()
return response . json (). get ( 'data' )
except requests . RequestException as e :
st . error ( f"API请求失败: { e } " )
return None Function : Create a new collection.
parameter :
name : The name of the collection.embedding_model_id : The ID of the embedded model.capacity : capacity of the collection. Return : Returns the response data of the created collection. def create_collection ( name , embedding_model_id , capacity ):
data = {
"name" : name ,
"embedding_model_id" : embedding_model_id ,
"capacity" : capacity
}
return api_request ( "POST" , f" { base_url } collections" , json = data )Function : Create data blocks.
parameter :
collection_id : ID of the collection.content : The content of the data block. Return : Returns the response data of the created data block. If the request fails, an error message is displayed and None is returned. def create_chunk ( collection_id , content ):
data = {
"collection_id" : collection_id ,
"content" : content
}
endpoint = f" { base_url } collections/ { collection_id } /chunks"
try :
response = requests . post ( endpoint , headers = headers , json = data )
response . raise_for_status ()
return response . json ()[ 'data' ]
except requests . RequestException as e :
st . error ( f"创建chunk失败: { e } " )
return None Function : Lists the data blocks in the specified collection.
parameter :
collection_id : ID of the collection.limit : The number of data blocks returned is limited, the default is 20.after : Parameters used for paging, specifying which data block to start from. Return : Returns the list of data blocks. If the request fails, an error message is displayed and an empty list is returned. def list_chunks ( collection_id , limit = 20 , after = None ):
url = f" { base_url } collections/ { collection_id } /chunks"
params = {
"limit" : limit ,
"order" : "desc"
}
if after :
params [ "after" ] = after
response = api_request ( "GET" , url , params = params )
if response is not None :
return response
else :
st . error ( "列出 chunks 失败。" )
return []Function : Get detailed information about a specific data block.
parameter :
chunk_id : The ID of the data block.collection_id : ID of the collection. Return : Returns the details of the data block. If the request fails, an error message is displayed and None is returned. def get_chunk_details ( chunk_id , collection_id ):
url = f" { base_url } collections/ { collection_id } /chunks/ { chunk_id } "
response = api_request ( "GET" , url )
if response is not None :
return response
else :
st . error ( "获取 chunk 详细信息失败。" )
return None Function : Get all data blocks from the specified collection.
parameter :
collection_id : ID of the collection. Return : Returns a list of detailed information for all data blocks. def fetch_all_chunks_from_collection ( collection_id ):
all_chunks = []
after = None
while True :
chunk_list = list_chunks ( collection_id , after = after )
if not chunk_list :
break
for chunk in chunk_list :
chunk_id = chunk [ 'chunk_id' ]
chunk_details = get_chunk_details ( chunk_id , collection_id )
if chunk_details :
all_chunks . append ( chunk_details )
if len ( chunk_list ) < 20 :
break
after = chunk_list [ - 1 ][ 'chunk_id' ]
return all_chunksFunction : Load a single document. parameter :
file_path : The file path to the document. Return : Returns the loaded document list. If the file extension is not supported, a ValueError is thrown. def load_single_document ( file_path : str ) -> List [ Document ]:
ext = "." + file_path . rsplit ( "." , 1 )[ - 1 ]
if ext in LOADER_MAPPING :
loader_class , loader_args = LOADER_MAPPING [ ext ]
loader = loader_class ( file_path , ** loader_args )
return loader . load ()
raise ValueError ( f"Unsupported file extension ' { ext } '" )Function : Process uploaded files and generate text blocks. parameter :
uploaded_file : The uploaded file object. Return : Returns the generated text block list. If file processing fails, an empty list is returned. def process_file ( uploaded_file ):
with tempfile . NamedTemporaryFile ( delete = False , suffix = os . path . splitext ( uploaded_file . name )[ 1 ]) as tmp_file :
tmp_file . write ( uploaded_file . getvalue ())
tmp_file_path = tmp_file . name
try :
documents = load_single_document ( tmp_file_path )
if not documents :
st . error ( "文件处理失败,请检查文件格式是否正确。" )
return []
text_splitter = RecursiveCharacterTextSplitter ( chunk_size = 2000 , chunk_overlap = 500 )
text_chunks = text_splitter . split_documents ( documents )
return text_chunks
except Exception as e :
st . error ( f"处理文件时发生错误: { e } " )
return []
finally :
os . unlink ( tmp_file_path )Function : Process multiple uploaded files and generate text blocks. parameter :
uploaded_files : A list of uploaded file objects. Return : Returns a list of all generated text blocks. def process_files ( uploaded_files ):
all_text_chunks = []
for uploaded_file in uploaded_files :
with tempfile . NamedTemporaryFile ( delete = False , suffix = os . path . splitext ( uploaded_file . name )[ 1 ]) as tmp_file :
tmp_file . write ( uploaded_file . getvalue ())
tmp_file_path = tmp_file . name
try :
documents = load_single_document ( tmp_file_path )
if not documents :
st . error ( f"文件 { uploaded_file . name } 处理失败,请检查文件格式是否正确。" )
continue
text_splitter = RecursiveCharacterTextSplitter ( chunk_size = 2000 , chunk_overlap = 500 )
text_chunks = text_splitter . split_documents ( documents )
all_text_chunks . extend ( text_chunks )
except Exception as e :
st . error ( f"处理文件 { uploaded_file . name } 时发生错误: { e } " )
finally :
os . unlink ( tmp_file_path )
return all_text_chunksFunction : Insert a Q&A pair into the database.
parameter :
collection_id : The collection ID to insert the Q&A pair. Return : Returns the number of successfully inserted Q&A pairs and the number of failed ones. def insert_qa_pairs_to_database ( collection_id ):
progress_bar = st . progress ( 0 )
status_text = st . empty ()
success_count = 0
fail_count = 0
for i , qa_pair in enumerate ( st . session_state . qa_pairs ):
try :
if "question" in qa_pair and "answer" in qa_pair and "chunk" in qa_pair :
content = f"问题: { qa_pair [ 'question' ] } n答案: { qa_pair [ 'answer' ] } n原文: { qa_pair [ 'chunk' ] } "
if len ( content ) > 4000 :
content = content [: 4000 ]
if create_chunk ( collection_id = collection_id , content = content ):
success_count += 1
else :
fail_count += 1
st . warning ( f"插入QA对 { i + 1 } 失败" )
else :
fail_count += 1
st . warning ( f"QA对 { i + 1 } 格式无效" )
except Exception as e :
st . error ( f"插入QA对 { i + 1 } 时发生错误: { str ( e ) } " )
fail_count += 1
progress = ( i + 1 ) / len ( st . session_state . qa_pairs )
progress_bar . progress ( progress )
status_text . text ( f"进度: { progress :.2% } | 成功: { success_count } | 失败: { fail_count } " )
return success_count , fail_countFunction : Download the data blocks into JSON files and format them clearly.
parameter :
chunks : A list of data blocks.collection_name : The name of the collection, used to generate the name of the downloaded file. Return : No return value, directly provide the download button. def download_chunks_as_json ( chunks , collection_name ):
if chunks :
json_data = { "chunks" : []}
for chunk in chunks :
json_data [ "chunks" ]. append ({
"chunk_id" : chunk . get ( "chunk_id" ),
"record_id" : chunk . get ( "record_id" ),
"collection_id" : chunk . get ( "collection_id" ),
"content" : chunk . get ( "content" ),
"num_tokens" : chunk . get ( "num_tokens" ),
"metadata" : chunk . get ( "metadata" , {}),
"updated_timestamp" : chunk . get ( "updated_timestamp" ),
"created_timestamp" : chunk . get ( "created_timestamp" ),
})
json_str = json . dumps ( json_data , ensure_ascii = False , indent = 4 )
st . download_button (
label = "下载集合内容为 JSON 文件" ,
data = json_str ,
file_name = f" { collection_name } .json" ,
mime = "application/json"
)Function : Upload data blocks from JSON files to the specified collection.
parameter :
uploaded_json_file : uploaded JSON file object.collection_id : The collection ID of the data block to be uploaded. Return : No return value, directly display the upload progress and results on the interface. def upload_json_chunks ( uploaded_json_file , collection_id ):
try :
data = json . load ( uploaded_json_file )
if 'chunks' not in data :
st . error ( "JSON 文件中缺少 'chunks' 键。" )
return
chunks = data [ 'chunks' ]
total_records = len ( chunks )
records_per_collection = 1000
num_collections = math . ceil ( total_records / records_per_collection )
st . write ( f"总记录数: { total_records } " )
st . write ( f"每个集合的记录数: { records_per_collection } " )
st . write ( f"需要创建的集合数: { num_collections } " )
for i in range ( num_collections ):
st . write ( f" n导入集合 { i + 1 } / { num_collections } ..." )
start_index = i * records_per_collection
end_index = min (( i + 1 ) * records_per_collection , total_records )
progress_bar = st . progress ( 0 )
for j , chunk in enumerate ( chunks [ start_index : end_index ]):
if 'content' in chunk :
content = chunk [ 'content' ]
try :
create_chunk (
collection_id = collection_id ,
content = content
)
except Exception as e :
st . error ( f"创建 chunk 时出错: { str ( e ) } " )
break
else :
st . warning ( f"第 { start_index + j + 1 } 条记录缺少 'content' 键。" )
continue
progress = ( j + 1 ) / ( end_index - start_index )
progress_bar . progress ( progress )
st . success ( "所有数据导入完成。" )
except Exception as e :
st . error ( f"上传 JSON 文件时发生错误: { str ( e ) } " )The main interface structure is defined in the main() function:
def main ():
st . set_page_config ( page_title = "RAG管理员界面" , layout = "wide" )
st . title ( "RAG管理员界面" )
# 侧边栏
st . sidebar . title ( "操作面板" )
operation = st . sidebar . radio ( "选择操作" , [ "上传文件" , "管理知识库" ])
if operation == "上传文件" :
# 文件上传和处理逻辑
...
elif operation == "管理知识库" :
# 知识库管理逻辑
...
if __name__ == "__main__" :
main () if operation == "上传文件" :
st . header ( "文件上传与QA对生成" )
uploaded_files = st . file_uploader ( "上传非结构化文件" , type = [ "txt" , "pdf" , "docx" ], accept_multiple_files = True )
if uploaded_files :
st . success ( "文件上传成功!" )
if st . button ( "处理文件并生成QA对" ):
with st . spinner ( "正在处理文件..." ):
text_chunks = process_files ( uploaded_files )
if not text_chunks :
st . error ( "文件处理失败,请检查文件格式是否正确。" )
return
st . info ( f"文件已分割成 { len ( text_chunks ) } 个文本段" )
with st . spinner ( "正在生成QA对..." ):
st . session_state . qa_pairs = generate_qa_pairs_with_progress ( text_chunks )
st . success ( f"已生成 { len ( st . session_state . qa_pairs ) } 个QA对" )
if st . session_state . qa_pairs :
st . subheader ( "前3个QA对预览" )
cols = st . columns ( 3 )
for i , qa in enumerate ( st . session_state . qa_pairs [: 3 ]):
with st . expander ( f"**QA对 { i + 1 } **" , expanded = True ):
st . markdown ( "**问题:**" )
st . markdown ( qa [ 'question' ])
st . markdown ( "**答案:**" )
st . markdown ( qa [ 'answer' ])
st . markdown ( "**原文:**" )
st . markdown ( qa [ 'chunk' ])
st . markdown ( "---" )
else :
st . warning ( "请上传文件。" ) elif operation == "管理知识库" :
st . header ( "知识库管理" )
option = st . radio ( "选择操作" , ( "创建新Collection" , "插入现有Collection" , "下载Collection" , "上传JSON文件" ))
if option == "插入现有Collection" :
if st . session_state . collections :
collection_names = [ c [ 'name' ] for c in st . session_state . collections ]
selected_collection = st . selectbox ( "选择Collection" , collection_names )
selected_id = next ( c [ 'collection_id' ] for c in st . session_state . collections if c [ 'name' ] == selected_collection )
if st . button ( "插入QA对到选定的Collection" ):
if hasattr ( st . session_state , 'qa_pairs' ) and st . session_state . qa_pairs :
with st . spinner ( "正在插入QA对..." ):
success_count , fail_count = insert_qa_pairs_to_database ( selected_id )
st . success ( f"数据插入完成!总计: { len ( st . session_state . qa_pairs ) } | 成功: { success_count } | 失败: { fail_count } " )
else :
st . warning ( "没有可用的QA对。请先上传文件并生成QA对。" )
else :
st . warning ( "没有可用的 Collections,请创建新的 Collection。" )
elif option == "创建新Collection" :
new_collection_name = st . text_input ( "输入新Collection名称" )
capacity = st . number_input ( "设置Collection容量" , min_value = 1 , max_value = 1000 , value = 1000 )
if st . button ( "创建新Collection" ):
with st . spinner ( "正在创建新Collection..." ):
new_collection = create_collection (
name = new_collection_name ,
embedding_model_id = embedding , # 这里可以替换为实际的模型ID
capacity = capacity
)
if new_collection :
st . success ( f"新Collection创建成功,ID: { new_collection [ 'collection_id' ] } " )
# 立即更新 collections 列表
st . session_state . collections = api_request ( "GET" , f" { base_url } collections" )
st . rerun ()
else :
st . error ( "创建新Collection失败" )
elif option == "下载Collection" :
if st . session_state . collections :
collection_names = [ c [ 'name' ] for c in st . session_state . collections ]
selected_collection = st . selectbox ( "选择Collection" , collection_names )
selected_id = next ( c [ 'collection_id' ] for c in st . session_state . collections if c [ 'name' ] == selected_collection )
if st . button ( "下载选定Collection的内容" ):
with st . spinner ( "正在获取集合内容..." ):
chunks = fetch_all_chunks_from_collection ( selected_id ) # Pass the API key
if chunks :
download_chunks_as_json ( chunks , selected_collection ) # Pass the collection name
st . success ( f"成功获取 { len ( chunks ) } 个 chunk。" )
else :
st . error ( "未能获取集合内容。" )
else :
st . warning ( "没有可用的 Collections,请创建新的 Collection。" )
elif option == "上传JSON文件" :
uploaded_json_file = st . file_uploader ( "选择一个 JSON 文件" , type = [ "json" ])
if st . session_state . collections :
collection_names = [ c [ 'name' ] for c in st . session_state . collections ]
selected_collection = st . selectbox ( "选择Collection" , collection_names )
selected_id = next ( c [ 'collection_id' ] for c in st . session_state . collections if c [ 'name' ] == selected_collection )
if uploaded_json_file is not None :
if st . button ( "上传并插入到选定的Collection" ):
with st . spinner ( "正在上传 JSON 文件并插入数据..." ):
upload_json_chunks ( uploaded_json_file , selected_id )
else :
st . warning ( "没有可用的 Collections,请创建新的 Collection。" )This project has been strongly supported by the Artificial Intelligence and Future Network Center of Zhuhai Campus of Beijing Normal University, the Intelligent Cross-Computing Center of Zhuhai Campus of Beijing Normal University, and the Engineering Research Center of the Ministry of Education, Big Data Cloud-Border Intelligence Collaboration of the Ministry of Education, Beijing Normal University


