RAG QA Generator
v1.1.0
Les systèmes de génération augmentée (RAG) de récupération sont devenus une direction de développement importante dans le domaine de l'intelligence artificielle, combinant les capacités de génération des modèles de langage à grande échelle avec des informations précises à partir de bases de connaissances externes pour fournir des réponses plus précises et fiables. Cependant, la construction et le maintien d'une base de connaissances pour les systèmes de chiffon ont toujours été un processus long et complexe, en particulier lorsqu'ils traitent de grandes quantités de documents non structurés. Récemment, nous développons un outil de génération de questions / réponses automatisé (QA) pour un système de génération d'augmentation (RAG) de récupération. Ce projet vise à atténuer les défis ci-dessus en automatisant le processus pour convertir des documents dans divers formats en paires de questions et réponses structurées et les intégrer de manière transparente dans la base de connaissances du système de chiffon.
Ce projet provient des défis rencontrés dans le développement réel du système de chiffon, parmi lesquels les motivations générales sont les suivantes:
En particulier, notre solution technique globale peut être résumé dans les parties suivantes:
git clone https://github.com/wangxb96/RAG-QA-Generator.git
cd RAG-QA-Generator
pip install -r requirements.txt
base_url = 'http://your-api-url/v1/'
api_key = 'your-api-key'
headers = {"Authorization": f"Bearer {api_key}"}
client = OpenAI(
api_key="your-openai-api-key",
base_url="http://your-openai-api-url/v1",
)
streamlit run AutoQAG.py
L'interface d'application est divisée en deux parties principales:
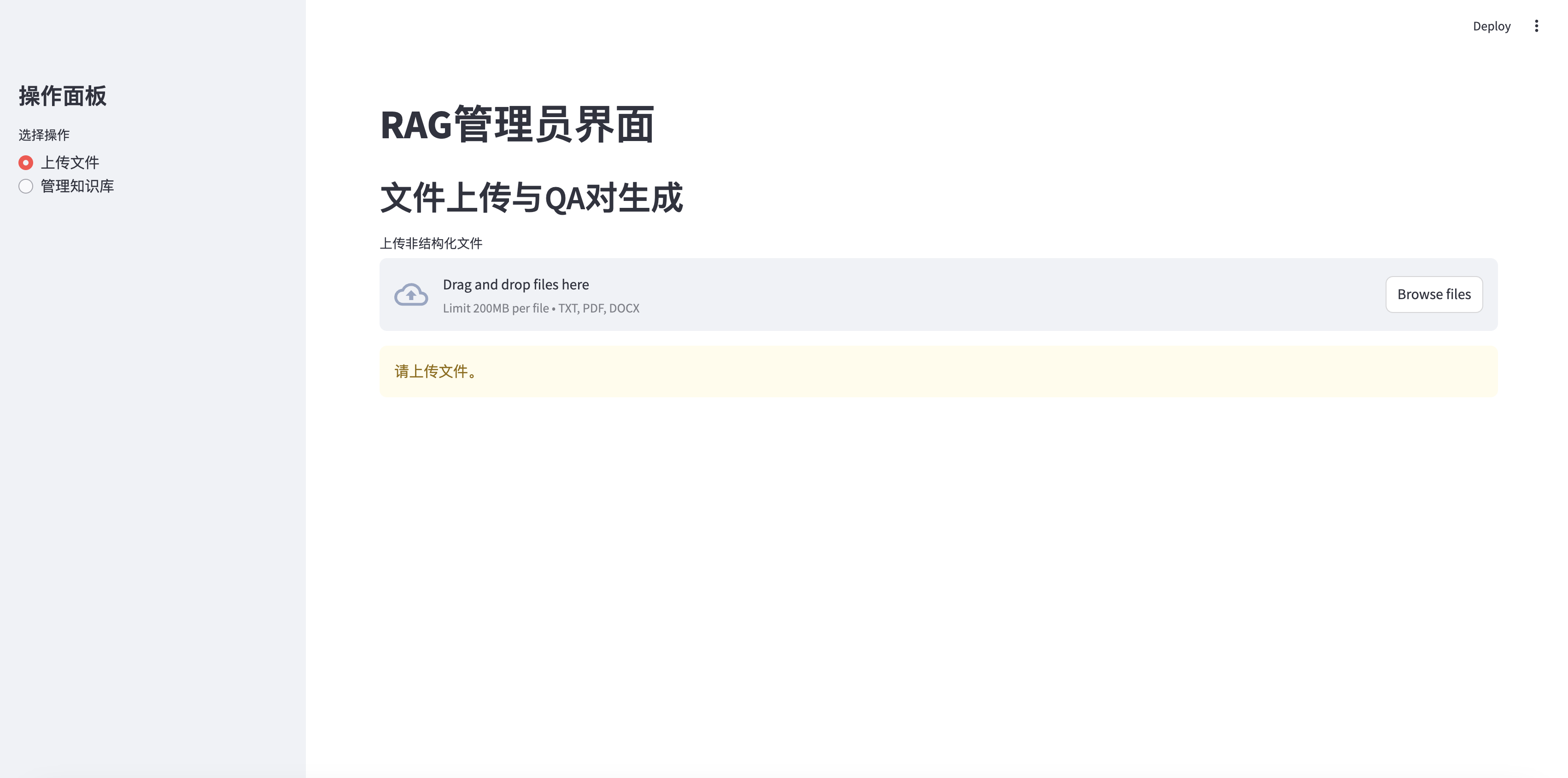 Page d'accueil de gestion des chiffons
Page d'accueil de gestion des chiffons
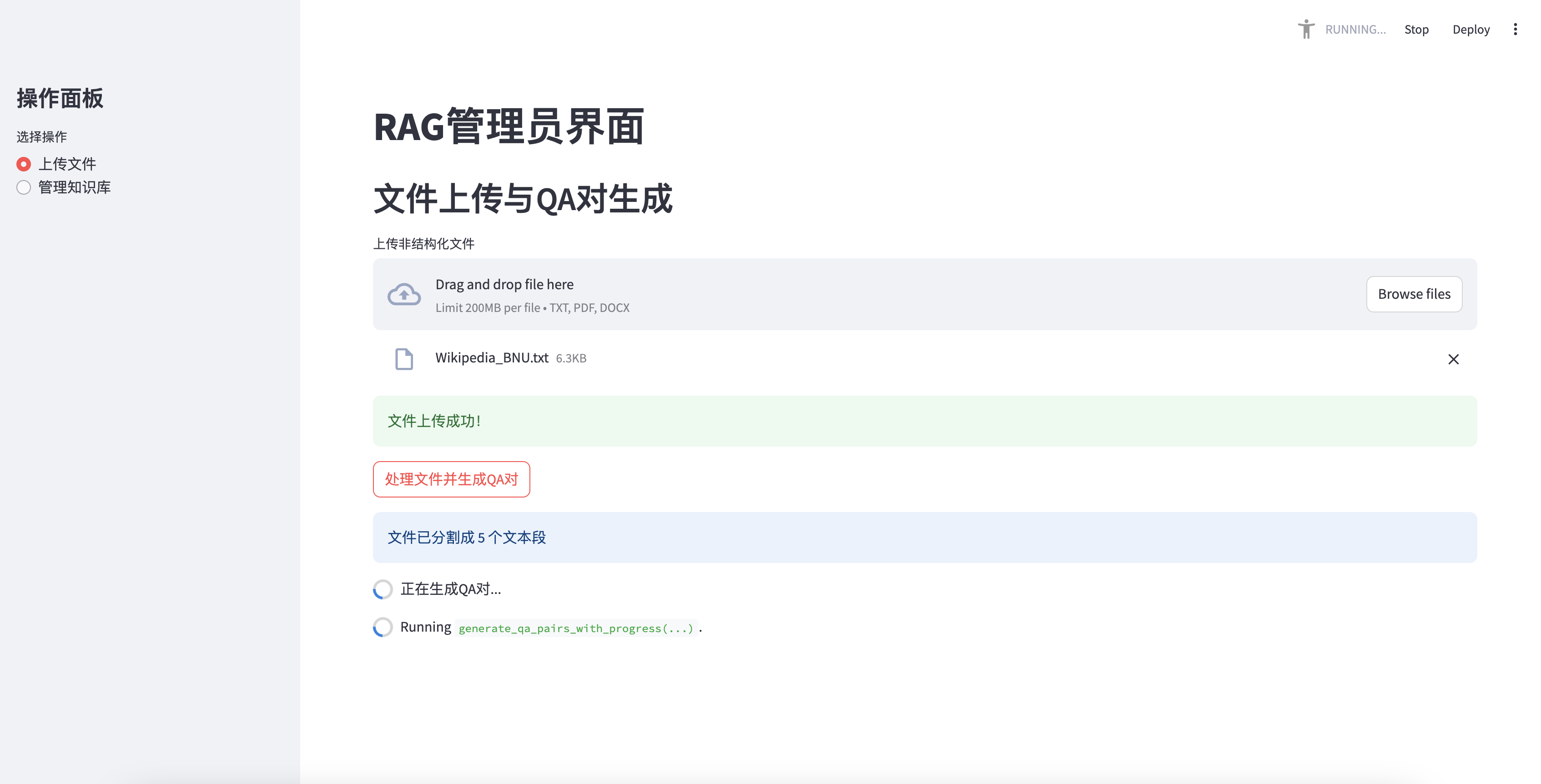 Téléchargement de fichiers et génération de paires d'AQ
Téléchargement de fichiers et génération de paires d'AQ
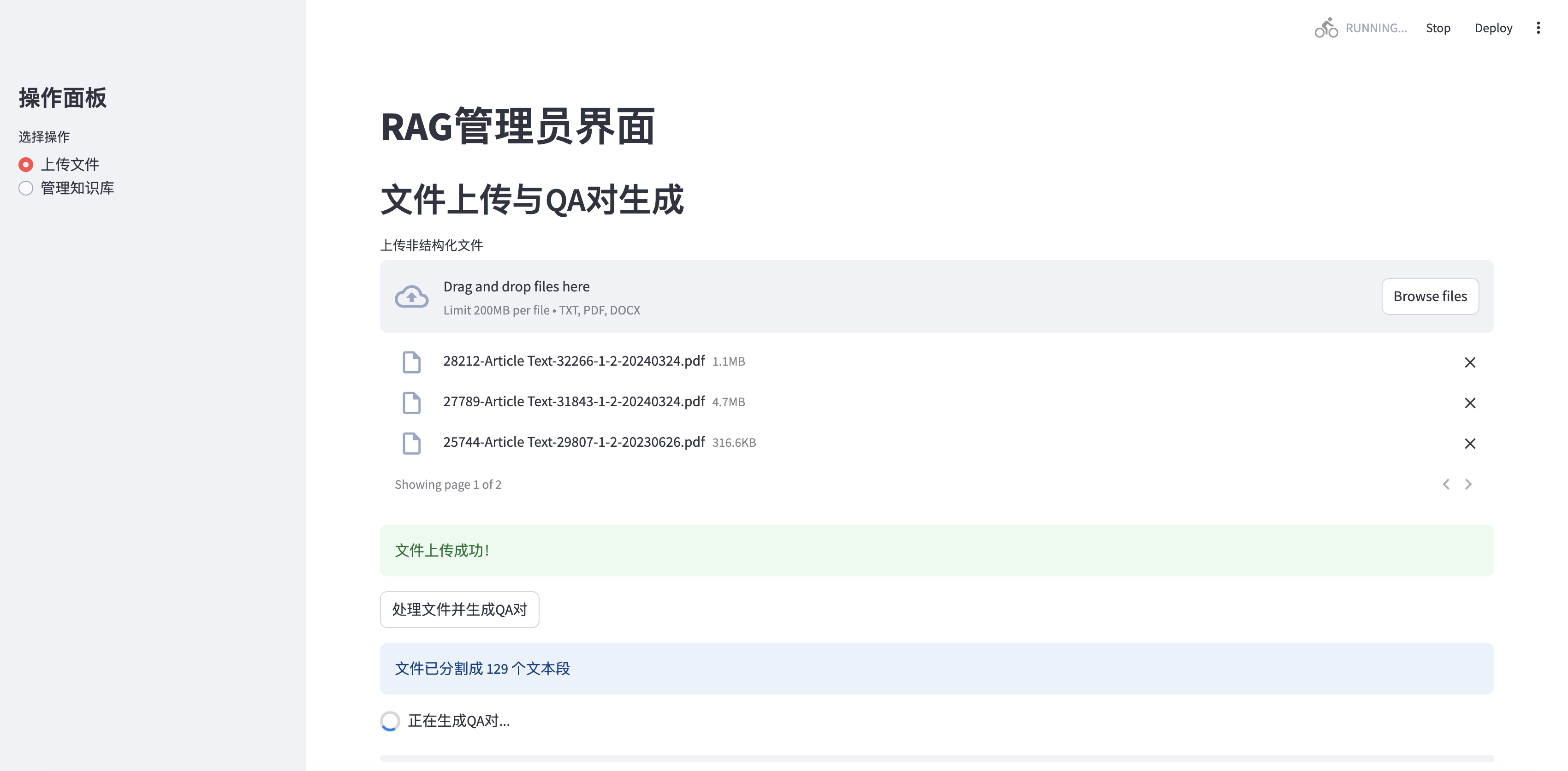 La version mise à jour prend en charge plusieurs téléchargements de fichiers
La version mise à jour prend en charge plusieurs téléchargements de fichiers
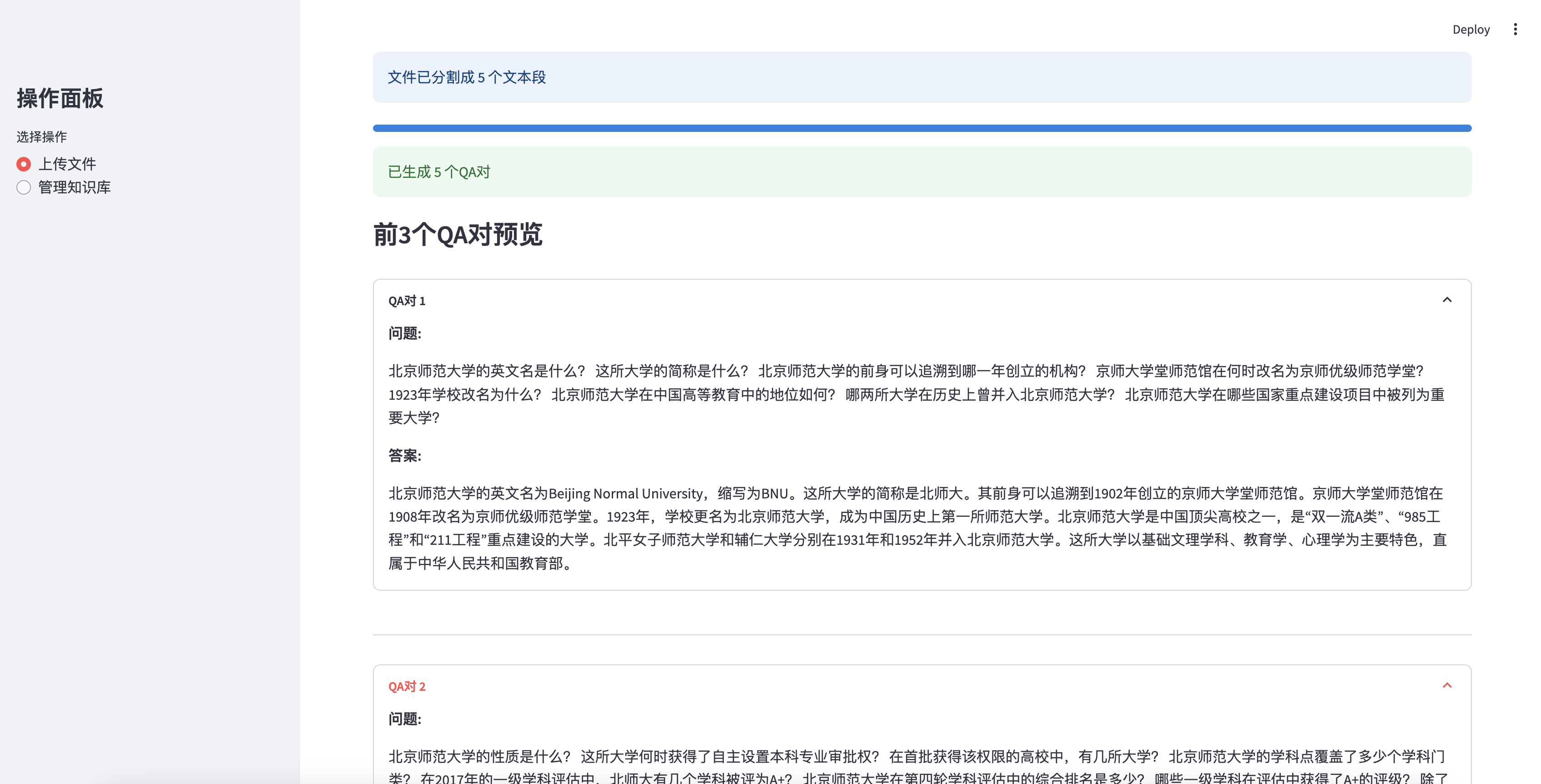 Aperçu les 3 premières paires d'AQ générées
Aperçu les 3 premières paires d'AQ générées
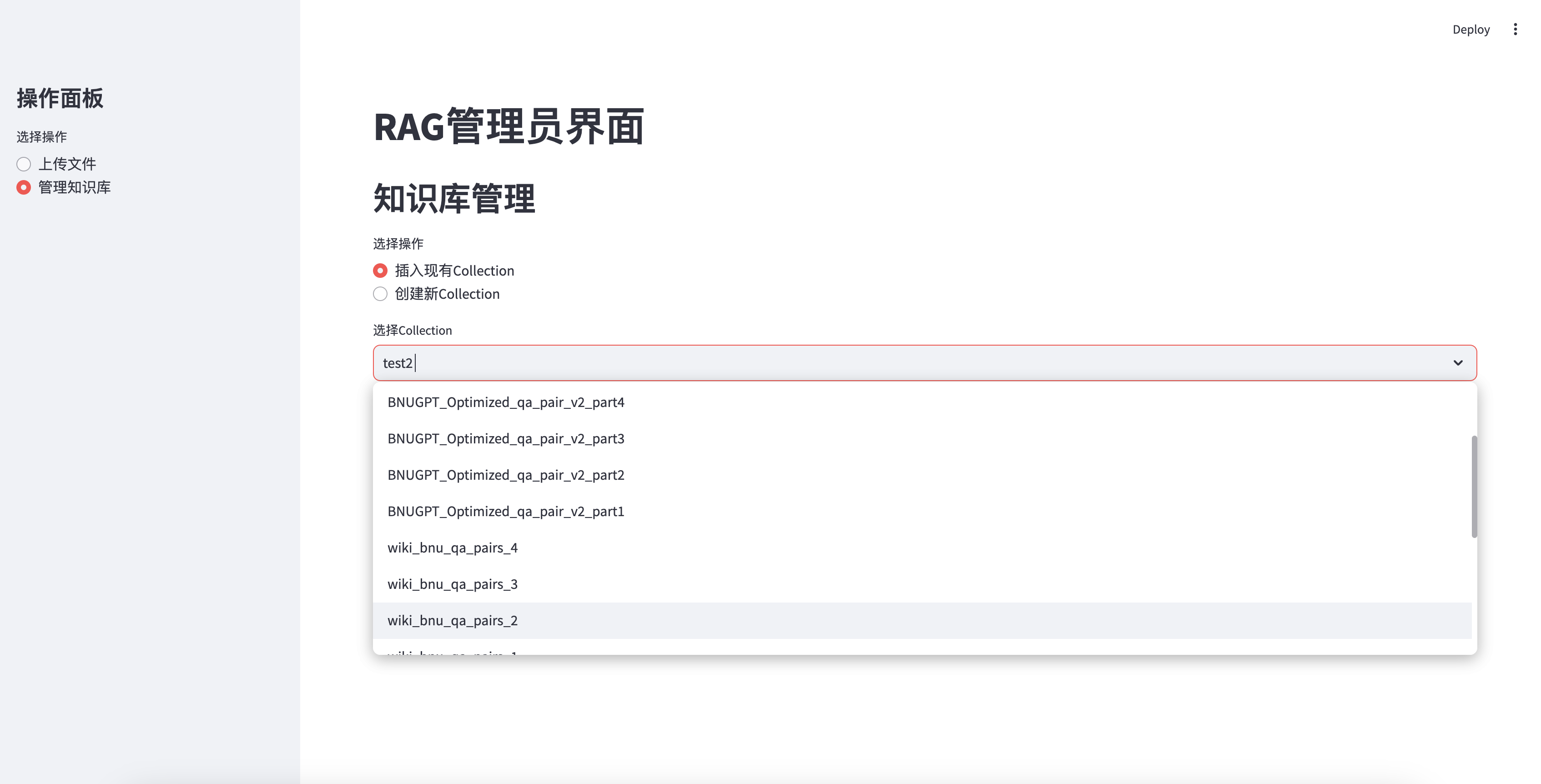 Insérer la base de connaissances existante
Insérer la base de connaissances existante
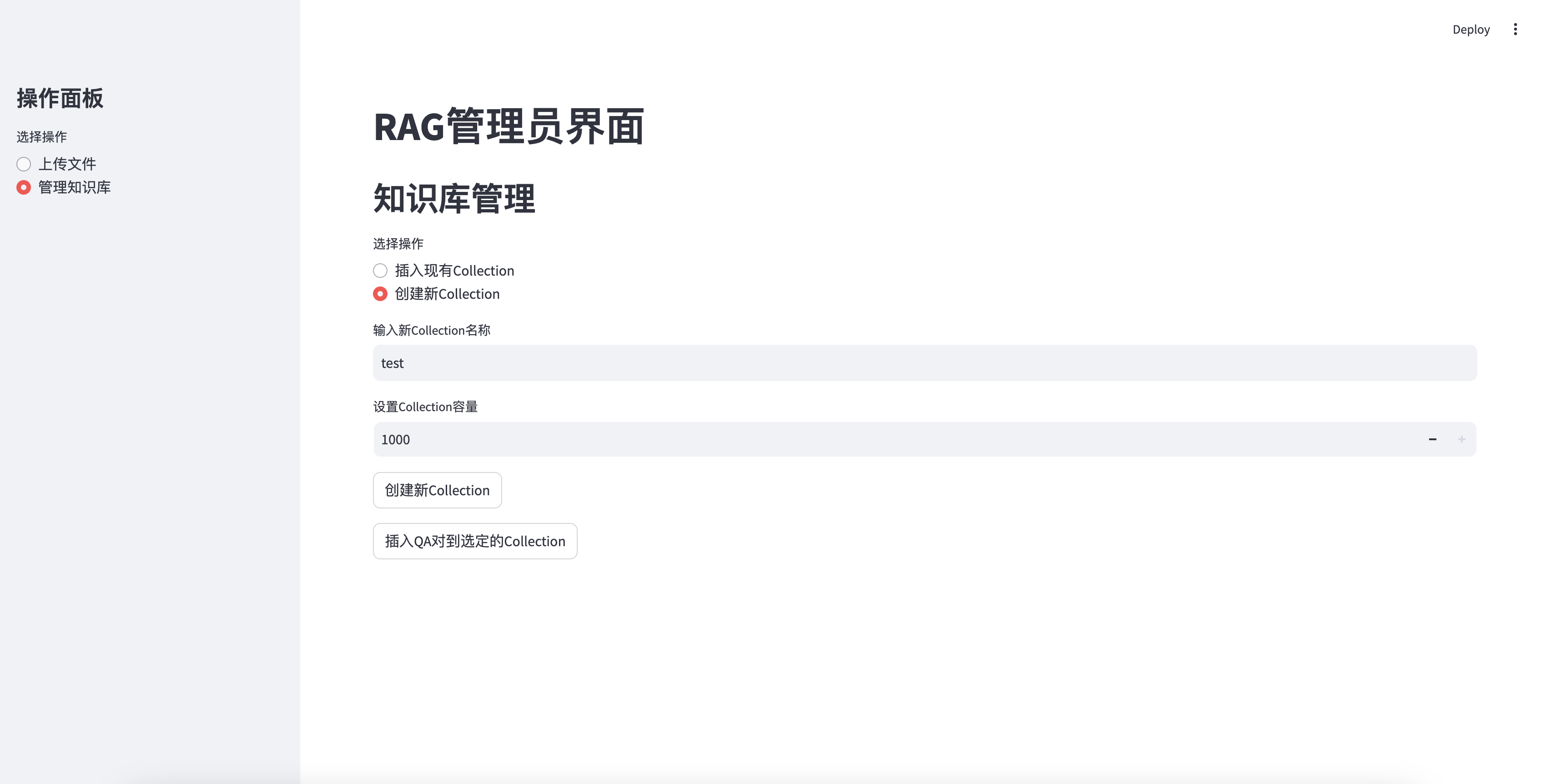 Insérer une base de connaissances nouvellement créée
Insérer une base de connaissances nouvellement créée
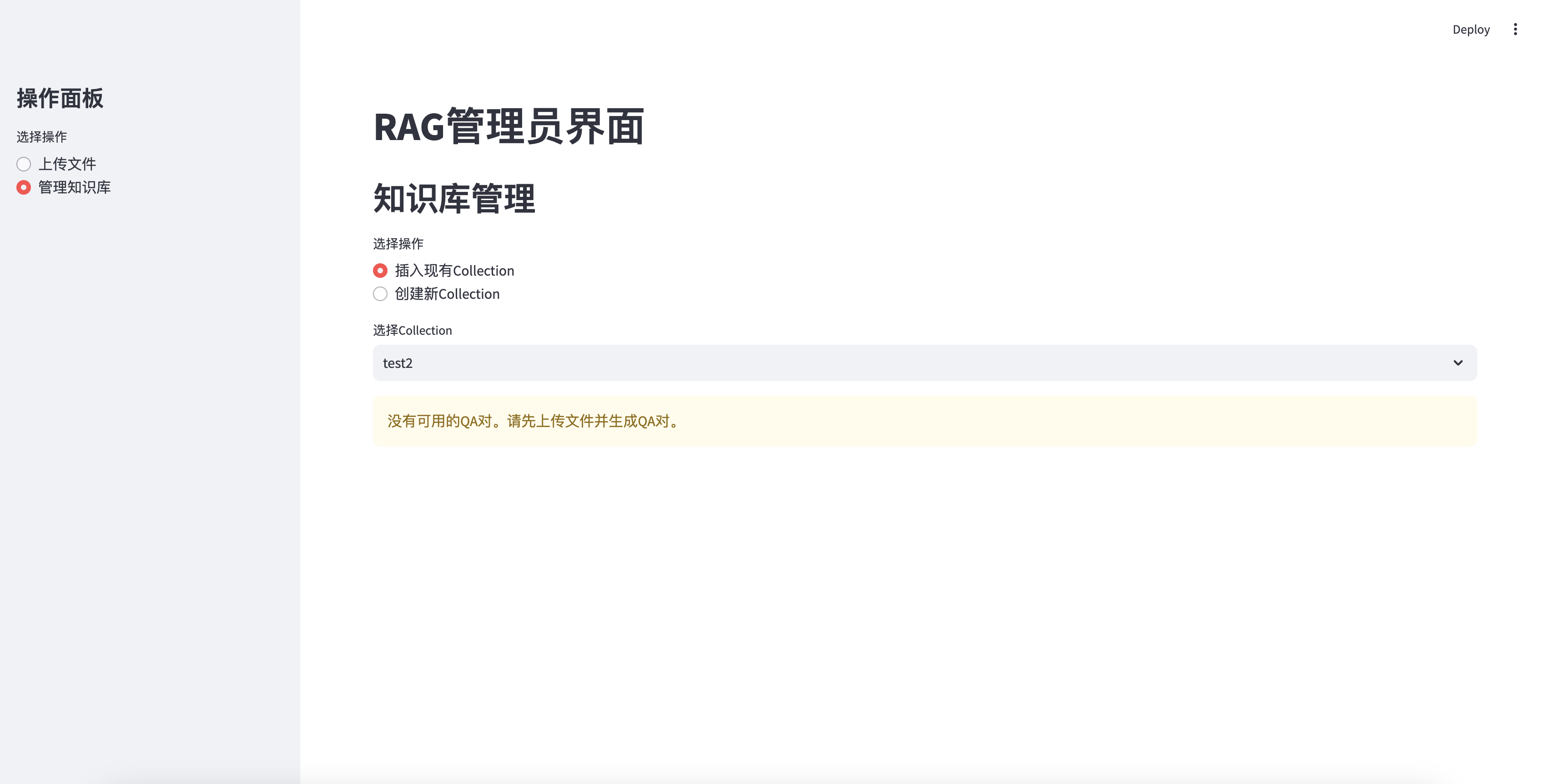 Ne peut pas insérer sans QA
Ne peut pas insérer sans QA
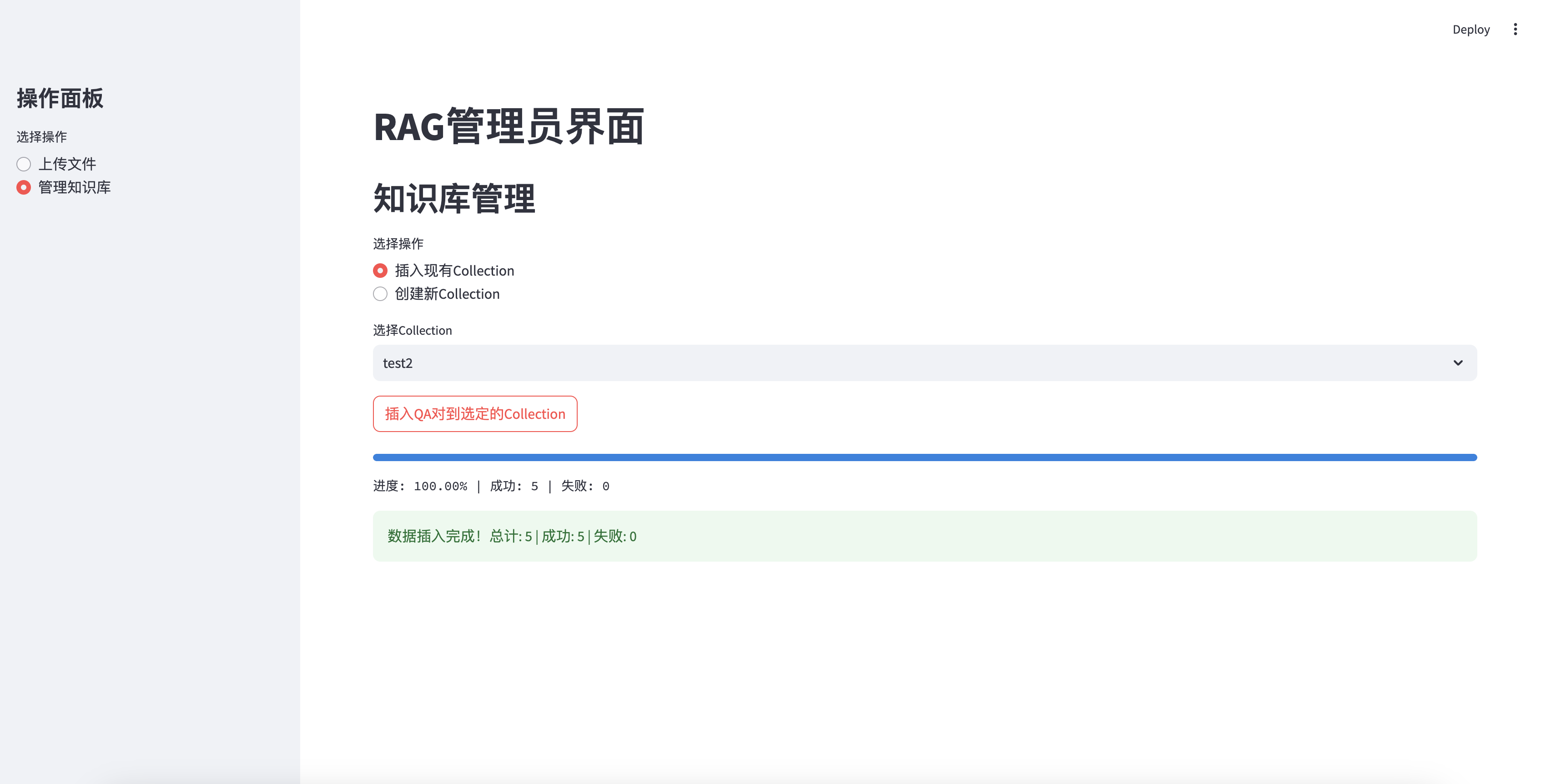 Inséré avec succès dans la base de connaissances
Inséré avec succès dans la base de connaissances
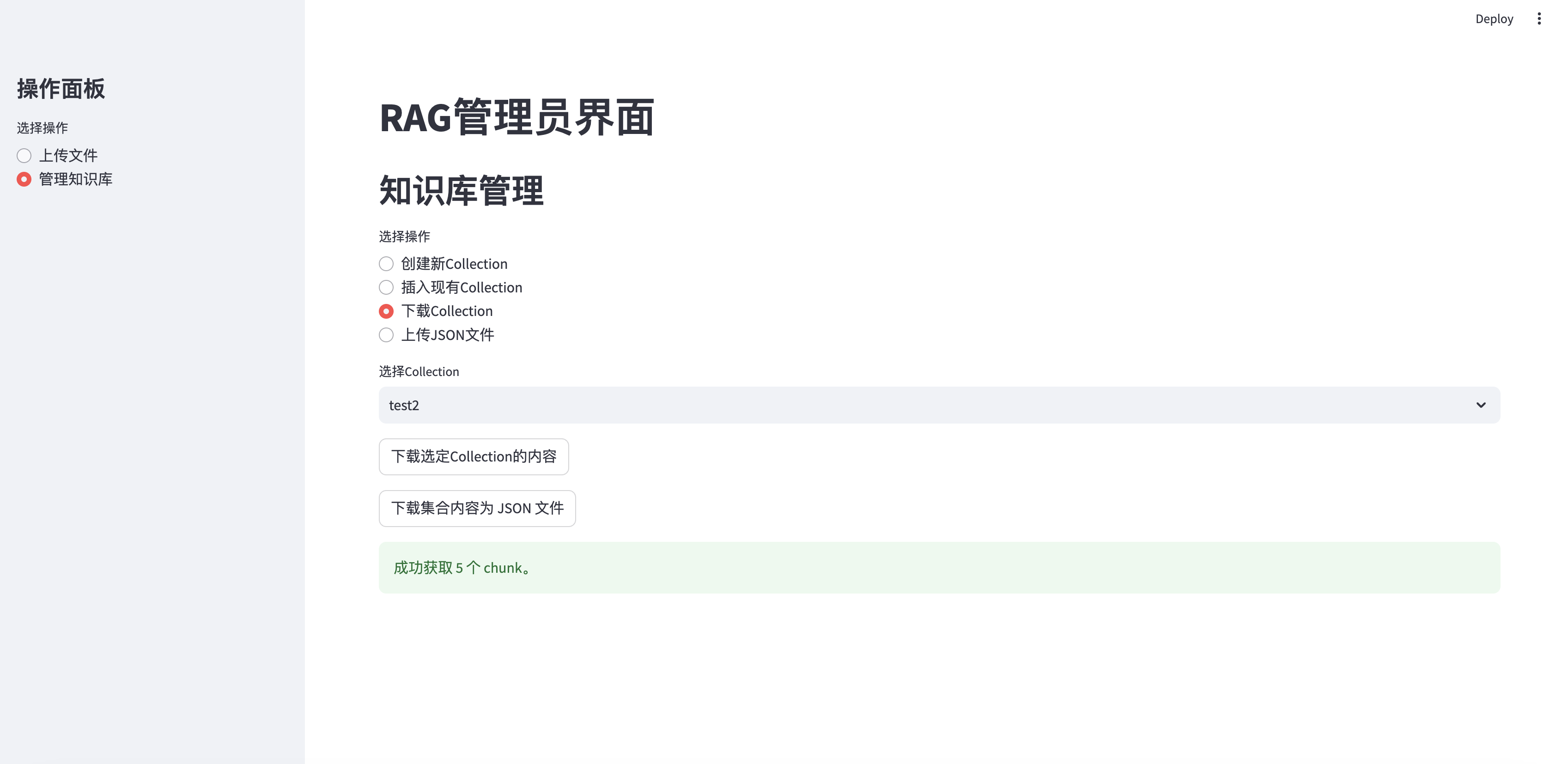 Collection de téléchargement
Collection de téléchargement
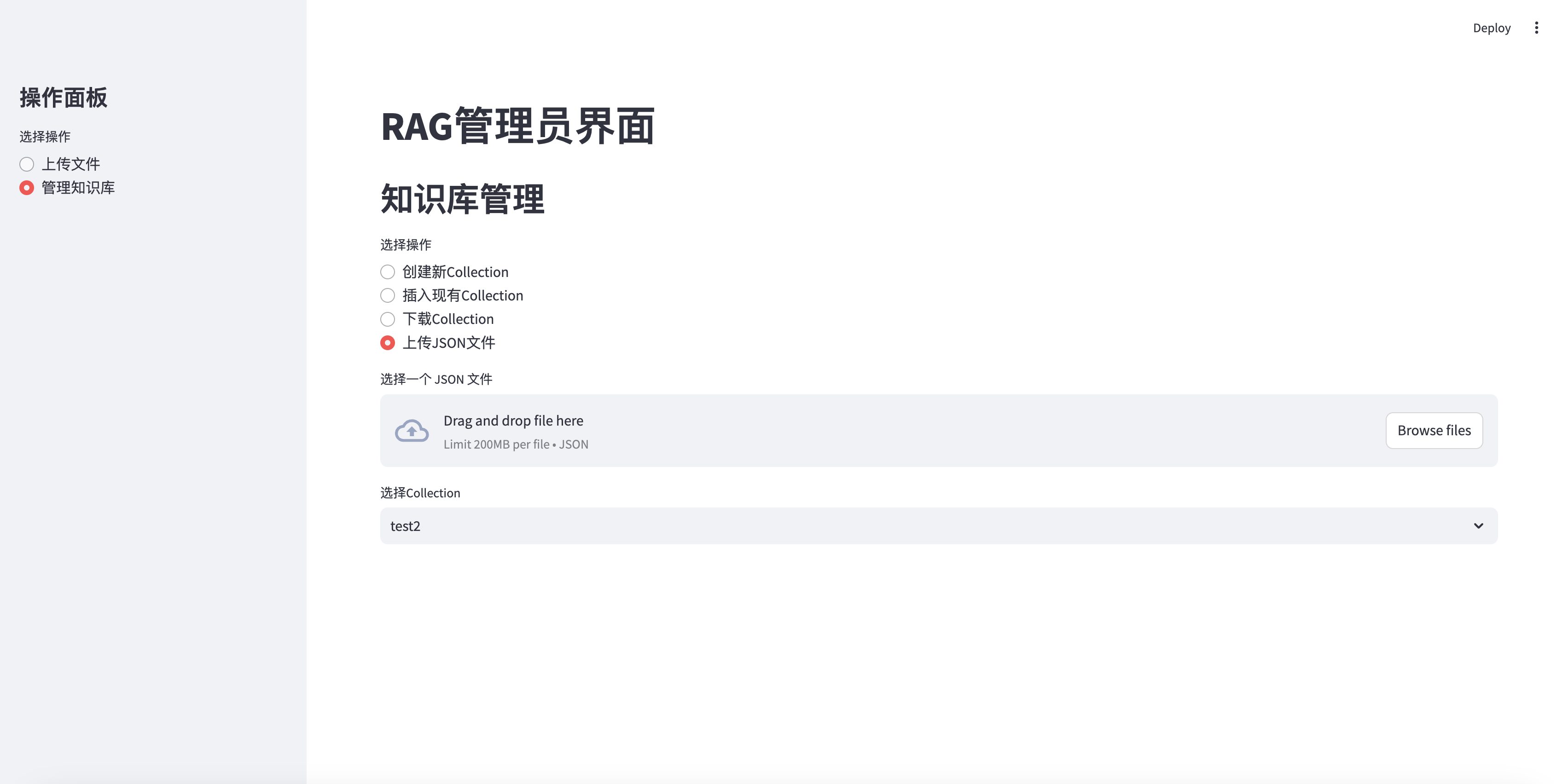 Télécharger le fichier JSON à la collection
Télécharger le fichier JSON à la collection
Tout d'abord, nous avons configuré la configuration et l'initialisation nécessaires:
base_url = 'your_knowledgebase_base_url'
api_key = 'your_knowledgebase_api_key'
headers = { "Authorization" : f"Bearer { api_key } " }
client = OpenAI (
api_key = "your_llm_api_key" ,
base_url = "your_llm_base_url" ,
)Cette section définit l'URL de base et les informations d'authentification de l'API, ainsi que la configuration du client OpenAI.
Fonction : Obtenez la réponse du modèle.
Paramètre :
prompt : invite de texte à envoyer au modèle.model : le nom du modèle utilisé, par défaut est "qwen25-72b".Retour : renvoie le contenu de réponse généré par le modèle. Si une erreur se produit lors de l'appel de l'API, aucune n'est renvoyée.
def get_completion ( prompt , model = "qwen25-72b" ):
"""获取模型的响应"""
try :
response = client . chat . completions . create (
model = model ,
messages = [{ "role" : "user" , "content" : prompt }],
temperature = 0 ,
)
return response . choices [ 0 ]. message . content
except Exception as e :
st . error ( f"调用API时发生错误: { e } " )
return None Fonction : Cette fonction génère des paires d'AQ basées sur des blocs de texte (ici peut concevoir une meilleure stratégie de génération QA et obtenir une meilleure génération en ajustant Propt).
Paramètre :
text_chunks : une liste de blocs de texte pour générer des paires de questions et réponses. Retour : renvoie la liste générée des questions et réponses. def generate_qa_pairs_with_progress ( text_chunks ):
"""生成问答对并显示进度"""
qa_pairs = []
progress_bar = st . progress ( 0 )
for i , chunk in enumerate ( text_chunks ):
prompt = f"""基于以下给定的文本,生成一组高质量的问答对。请遵循以下指南:
1. 问题部分:
- 为同一个主题创建尽可能多的(如K个)不同表述的问题,确保问题的多样性。
- 每个问题应考虑用户可能的多种问法,例如:
- 直接询问(如“什么是...?”)
- 请求确认(如“是否可以说...?”)
- 寻求解释(如“请解释一下...的含义。”)
- 假设性问题(如“如果...会怎样?”)
- 例子请求(如“能否举个例子说明...?”)
- 问题应涵盖文本中的关键信息、主要概念和细节,确保不遗漏重要内容。
2. 答案部分:
- 提供一个全面、信息丰富的答案,涵盖问题的所有可能角度,确保逻辑连贯。
- 答案应直接基于给定文本,确保准确性和一致性。
- 包含相关的细节,如日期、名称、职位等具体信息,必要时提供背景信息以增强理解。
3. 格式:
- 使用 "Q:" 标记问题集合的开始,所有问题应在一个段落内,问题之间用空格分隔。
- 使用 "A:" 标记答案的开始,答案应清晰分段,便于阅读。
- 问答对之间用两个空行分隔,以提高可读性。
4. 内容要求:
- 确保问答对紧密围绕文本主题,避免偏离主题。
- 避免添加文本中未提及的信息,确保信息的真实性。
- 如果文本信息不足以回答某个方面,可以在答案中说明 "根据给定信息无法确定",并尽量提供相关的上下文。
5. 示例结构(仅供参考,实际内容应基于给定文本):
给定文本:
{ chunk }
请基于这个文本生成问答对。
"""
response = get_completion ( prompt )
if response :
try :
parts = response . split ( "A:" , 1 )
if len ( parts ) == 2 :
question = parts [ 0 ]. replace ( "Q:" , "" ). strip ()
answer = parts [ 1 ]. strip ()
qa_pairs . append ({ "question" : question , "answer" : answer })
else :
st . warning ( f"无法解析响应: { response } " )
except Exception as e :
st . warning ( f"处理响应时出错: { str ( e ) } " )
progress = ( i + 1 ) / len ( text_chunks )
progress_bar . progress ( progress )
return qa_pairsFonction : gérer les demandes d'API communes.
Paramètre :
method : méthode de demande HTTP (telle que GET, POST, etc.).url : l'URL demandée.kwargs : Autres paramètres de demande (tels que les en-têtes, JSON, etc.). Retour : renvoie la partie "données" de la réponse de l'API. Si la demande échoue, un message d'erreur s'affiche et aucun n'est renvoyé. def api_request ( method , url , ** kwargs ):
try :
response = requests . request ( method , url , headers = headers , ** kwargs )
response . raise_for_status ()
return response . json (). get ( 'data' )
except requests . RequestException as e :
st . error ( f"API请求失败: { e } " )
return None Fonction : Créez une nouvelle collection.
Paramètre :
name : le nom de la collection.embedding_model_id : l'ID du modèle intégré.capacity : capacité de la collection. Retour : renvoie les données de réponse de la collection créée. def create_collection ( name , embedding_model_id , capacity ):
data = {
"name" : name ,
"embedding_model_id" : embedding_model_id ,
"capacity" : capacity
}
return api_request ( "POST" , f" { base_url } collections" , json = data )Fonction : Créez des blocs de données.
Paramètre :
collection_id : ID de la collection.content : le contenu du bloc de données. Retour : renvoie les données de réponse du bloc de données créé. Si la demande échoue, un message d'erreur s'affiche et aucun n'est renvoyé. def create_chunk ( collection_id , content ):
data = {
"collection_id" : collection_id ,
"content" : content
}
endpoint = f" { base_url } collections/ { collection_id } /chunks"
try :
response = requests . post ( endpoint , headers = headers , json = data )
response . raise_for_status ()
return response . json ()[ 'data' ]
except requests . RequestException as e :
st . error ( f"创建chunk失败: { e } " )
return None Fonction : répertorie les blocs de données dans la collection spécifiée.
Paramètre :
collection_id : ID de la collection.limit : Le nombre de blocs de données renvoyés est limité, la valeur par défaut est de 20.after : Paramètres utilisés pour la pagination, spécifiant de quel bloc de données à partir du départ. Retour : renvoie la liste des blocs de données. Si la demande échoue, un message d'erreur s'affiche et une liste vide est renvoyée. def list_chunks ( collection_id , limit = 20 , after = None ):
url = f" { base_url } collections/ { collection_id } /chunks"
params = {
"limit" : limit ,
"order" : "desc"
}
if after :
params [ "after" ] = after
response = api_request ( "GET" , url , params = params )
if response is not None :
return response
else :
st . error ( "列出 chunks 失败。" )
return []Fonction : Obtenez des informations détaillées sur un bloc de données spécifique.
Paramètre :
chunk_id : l'ID du bloc de données.collection_id : ID de la collection. Retour : renvoie les détails du bloc de données. Si la demande échoue, un message d'erreur s'affiche et aucun n'est renvoyé. def get_chunk_details ( chunk_id , collection_id ):
url = f" { base_url } collections/ { collection_id } /chunks/ { chunk_id } "
response = api_request ( "GET" , url )
if response is not None :
return response
else :
st . error ( "获取 chunk 详细信息失败。" )
return None Fonction : Obtenez tous les blocs de données de la collection spécifiée.
Paramètre :
collection_id : ID de la collection. Retour : renvoie une liste d'informations détaillées pour tous les blocs de données. def fetch_all_chunks_from_collection ( collection_id ):
all_chunks = []
after = None
while True :
chunk_list = list_chunks ( collection_id , after = after )
if not chunk_list :
break
for chunk in chunk_list :
chunk_id = chunk [ 'chunk_id' ]
chunk_details = get_chunk_details ( chunk_id , collection_id )
if chunk_details :
all_chunks . append ( chunk_details )
if len ( chunk_list ) < 20 :
break
after = chunk_list [ - 1 ][ 'chunk_id' ]
return all_chunksFonction : Chargez un seul document. Paramètre :
file_path : le chemin du fichier vers le document. Retour : renvoie la liste des documents chargés. Si l'extension de fichier n'est pas prise en charge, une valeur de valeur est lancée. def load_single_document ( file_path : str ) -> List [ Document ]:
ext = "." + file_path . rsplit ( "." , 1 )[ - 1 ]
if ext in LOADER_MAPPING :
loader_class , loader_args = LOADER_MAPPING [ ext ]
loader = loader_class ( file_path , ** loader_args )
return loader . load ()
raise ValueError ( f"Unsupported file extension ' { ext } '" )Fonction : Processus Fichiers téléchargés et générer des blocs de texte. Paramètre :
uploaded_file : l'objet de fichier téléchargé. Retour : renvoie la liste des blocs de texte générés. Si le traitement de fichiers échoue, une liste vide est renvoyée. def process_file ( uploaded_file ):
with tempfile . NamedTemporaryFile ( delete = False , suffix = os . path . splitext ( uploaded_file . name )[ 1 ]) as tmp_file :
tmp_file . write ( uploaded_file . getvalue ())
tmp_file_path = tmp_file . name
try :
documents = load_single_document ( tmp_file_path )
if not documents :
st . error ( "文件处理失败,请检查文件格式是否正确。" )
return []
text_splitter = RecursiveCharacterTextSplitter ( chunk_size = 2000 , chunk_overlap = 500 )
text_chunks = text_splitter . split_documents ( documents )
return text_chunks
except Exception as e :
st . error ( f"处理文件时发生错误: { e } " )
return []
finally :
os . unlink ( tmp_file_path )Fonction : traitez plusieurs fichiers téléchargés et générez des blocs de texte. Paramètre :
uploaded_files : une liste des objets de fichiers téléchargés. Retour : renvoie une liste de tous les blocs de texte générés. def process_files ( uploaded_files ):
all_text_chunks = []
for uploaded_file in uploaded_files :
with tempfile . NamedTemporaryFile ( delete = False , suffix = os . path . splitext ( uploaded_file . name )[ 1 ]) as tmp_file :
tmp_file . write ( uploaded_file . getvalue ())
tmp_file_path = tmp_file . name
try :
documents = load_single_document ( tmp_file_path )
if not documents :
st . error ( f"文件 { uploaded_file . name } 处理失败,请检查文件格式是否正确。" )
continue
text_splitter = RecursiveCharacterTextSplitter ( chunk_size = 2000 , chunk_overlap = 500 )
text_chunks = text_splitter . split_documents ( documents )
all_text_chunks . extend ( text_chunks )
except Exception as e :
st . error ( f"处理文件 { uploaded_file . name } 时发生错误: { e } " )
finally :
os . unlink ( tmp_file_path )
return all_text_chunksFonction : insérez une paire de questions / réponses dans la base de données.
Paramètre :
collection_id : l'ID de collection pour insérer la paire de questions et réponses. Retour : renvoie le nombre de paires de questions / réponses insérées avec succès et le nombre d'échecs. def insert_qa_pairs_to_database ( collection_id ):
progress_bar = st . progress ( 0 )
status_text = st . empty ()
success_count = 0
fail_count = 0
for i , qa_pair in enumerate ( st . session_state . qa_pairs ):
try :
if "question" in qa_pair and "answer" in qa_pair and "chunk" in qa_pair :
content = f"问题: { qa_pair [ 'question' ] } n答案: { qa_pair [ 'answer' ] } n原文: { qa_pair [ 'chunk' ] } "
if len ( content ) > 4000 :
content = content [: 4000 ]
if create_chunk ( collection_id = collection_id , content = content ):
success_count += 1
else :
fail_count += 1
st . warning ( f"插入QA对 { i + 1 } 失败" )
else :
fail_count += 1
st . warning ( f"QA对 { i + 1 } 格式无效" )
except Exception as e :
st . error ( f"插入QA对 { i + 1 } 时发生错误: { str ( e ) } " )
fail_count += 1
progress = ( i + 1 ) / len ( st . session_state . qa_pairs )
progress_bar . progress ( progress )
status_text . text ( f"进度: { progress :.2% } | 成功: { success_count } | 失败: { fail_count } " )
return success_count , fail_countFonction : Téléchargez les blocs de données dans des fichiers JSON et formatez-les clairement.
Paramètre :
chunks : une liste de blocs de données.collection_name : le nom de la collection, utilisé pour générer le nom du fichier téléchargé. Retour : pas de valeur de retour, fournissez directement le bouton de téléchargement. def download_chunks_as_json ( chunks , collection_name ):
if chunks :
json_data = { "chunks" : []}
for chunk in chunks :
json_data [ "chunks" ]. append ({
"chunk_id" : chunk . get ( "chunk_id" ),
"record_id" : chunk . get ( "record_id" ),
"collection_id" : chunk . get ( "collection_id" ),
"content" : chunk . get ( "content" ),
"num_tokens" : chunk . get ( "num_tokens" ),
"metadata" : chunk . get ( "metadata" , {}),
"updated_timestamp" : chunk . get ( "updated_timestamp" ),
"created_timestamp" : chunk . get ( "created_timestamp" ),
})
json_str = json . dumps ( json_data , ensure_ascii = False , indent = 4 )
st . download_button (
label = "下载集合内容为 JSON 文件" ,
data = json_str ,
file_name = f" { collection_name } .json" ,
mime = "application/json"
)Fonction : Téléchargez les blocs de données des fichiers JSON vers la collection spécifiée.
Paramètre :
uploaded_json_file : objet de fichier JSON téléchargé.collection_id : L'ID de collecte du bloc de données à télécharger. Retour : pas de valeur de retour, affichez directement les progrès et les résultats de téléchargement sur l'interface. def upload_json_chunks ( uploaded_json_file , collection_id ):
try :
data = json . load ( uploaded_json_file )
if 'chunks' not in data :
st . error ( "JSON 文件中缺少 'chunks' 键。" )
return
chunks = data [ 'chunks' ]
total_records = len ( chunks )
records_per_collection = 1000
num_collections = math . ceil ( total_records / records_per_collection )
st . write ( f"总记录数: { total_records } " )
st . write ( f"每个集合的记录数: { records_per_collection } " )
st . write ( f"需要创建的集合数: { num_collections } " )
for i in range ( num_collections ):
st . write ( f" n导入集合 { i + 1 } / { num_collections } ..." )
start_index = i * records_per_collection
end_index = min (( i + 1 ) * records_per_collection , total_records )
progress_bar = st . progress ( 0 )
for j , chunk in enumerate ( chunks [ start_index : end_index ]):
if 'content' in chunk :
content = chunk [ 'content' ]
try :
create_chunk (
collection_id = collection_id ,
content = content
)
except Exception as e :
st . error ( f"创建 chunk 时出错: { str ( e ) } " )
break
else :
st . warning ( f"第 { start_index + j + 1 } 条记录缺少 'content' 键。" )
continue
progress = ( j + 1 ) / ( end_index - start_index )
progress_bar . progress ( progress )
st . success ( "所有数据导入完成。" )
except Exception as e :
st . error ( f"上传 JSON 文件时发生错误: { str ( e ) } " )La structure d'interface principale est définie dans la fonction principale ():
def main ():
st . set_page_config ( page_title = "RAG管理员界面" , layout = "wide" )
st . title ( "RAG管理员界面" )
# 侧边栏
st . sidebar . title ( "操作面板" )
operation = st . sidebar . radio ( "选择操作" , [ "上传文件" , "管理知识库" ])
if operation == "上传文件" :
# 文件上传和处理逻辑
...
elif operation == "管理知识库" :
# 知识库管理逻辑
...
if __name__ == "__main__" :
main () if operation == "上传文件" :
st . header ( "文件上传与QA对生成" )
uploaded_files = st . file_uploader ( "上传非结构化文件" , type = [ "txt" , "pdf" , "docx" ], accept_multiple_files = True )
if uploaded_files :
st . success ( "文件上传成功!" )
if st . button ( "处理文件并生成QA对" ):
with st . spinner ( "正在处理文件..." ):
text_chunks = process_files ( uploaded_files )
if not text_chunks :
st . error ( "文件处理失败,请检查文件格式是否正确。" )
return
st . info ( f"文件已分割成 { len ( text_chunks ) } 个文本段" )
with st . spinner ( "正在生成QA对..." ):
st . session_state . qa_pairs = generate_qa_pairs_with_progress ( text_chunks )
st . success ( f"已生成 { len ( st . session_state . qa_pairs ) } 个QA对" )
if st . session_state . qa_pairs :
st . subheader ( "前3个QA对预览" )
cols = st . columns ( 3 )
for i , qa in enumerate ( st . session_state . qa_pairs [: 3 ]):
with st . expander ( f"**QA对 { i + 1 } **" , expanded = True ):
st . markdown ( "**问题:**" )
st . markdown ( qa [ 'question' ])
st . markdown ( "**答案:**" )
st . markdown ( qa [ 'answer' ])
st . markdown ( "**原文:**" )
st . markdown ( qa [ 'chunk' ])
st . markdown ( "---" )
else :
st . warning ( "请上传文件。" ) elif operation == "管理知识库" :
st . header ( "知识库管理" )
option = st . radio ( "选择操作" , ( "创建新Collection" , "插入现有Collection" , "下载Collection" , "上传JSON文件" ))
if option == "插入现有Collection" :
if st . session_state . collections :
collection_names = [ c [ 'name' ] for c in st . session_state . collections ]
selected_collection = st . selectbox ( "选择Collection" , collection_names )
selected_id = next ( c [ 'collection_id' ] for c in st . session_state . collections if c [ 'name' ] == selected_collection )
if st . button ( "插入QA对到选定的Collection" ):
if hasattr ( st . session_state , 'qa_pairs' ) and st . session_state . qa_pairs :
with st . spinner ( "正在插入QA对..." ):
success_count , fail_count = insert_qa_pairs_to_database ( selected_id )
st . success ( f"数据插入完成!总计: { len ( st . session_state . qa_pairs ) } | 成功: { success_count } | 失败: { fail_count } " )
else :
st . warning ( "没有可用的QA对。请先上传文件并生成QA对。" )
else :
st . warning ( "没有可用的 Collections,请创建新的 Collection。" )
elif option == "创建新Collection" :
new_collection_name = st . text_input ( "输入新Collection名称" )
capacity = st . number_input ( "设置Collection容量" , min_value = 1 , max_value = 1000 , value = 1000 )
if st . button ( "创建新Collection" ):
with st . spinner ( "正在创建新Collection..." ):
new_collection = create_collection (
name = new_collection_name ,
embedding_model_id = embedding , # 这里可以替换为实际的模型ID
capacity = capacity
)
if new_collection :
st . success ( f"新Collection创建成功,ID: { new_collection [ 'collection_id' ] } " )
# 立即更新 collections 列表
st . session_state . collections = api_request ( "GET" , f" { base_url } collections" )
st . rerun ()
else :
st . error ( "创建新Collection失败" )
elif option == "下载Collection" :
if st . session_state . collections :
collection_names = [ c [ 'name' ] for c in st . session_state . collections ]
selected_collection = st . selectbox ( "选择Collection" , collection_names )
selected_id = next ( c [ 'collection_id' ] for c in st . session_state . collections if c [ 'name' ] == selected_collection )
if st . button ( "下载选定Collection的内容" ):
with st . spinner ( "正在获取集合内容..." ):
chunks = fetch_all_chunks_from_collection ( selected_id ) # Pass the API key
if chunks :
download_chunks_as_json ( chunks , selected_collection ) # Pass the collection name
st . success ( f"成功获取 { len ( chunks ) } 个 chunk。" )
else :
st . error ( "未能获取集合内容。" )
else :
st . warning ( "没有可用的 Collections,请创建新的 Collection。" )
elif option == "上传JSON文件" :
uploaded_json_file = st . file_uploader ( "选择一个 JSON 文件" , type = [ "json" ])
if st . session_state . collections :
collection_names = [ c [ 'name' ] for c in st . session_state . collections ]
selected_collection = st . selectbox ( "选择Collection" , collection_names )
selected_id = next ( c [ 'collection_id' ] for c in st . session_state . collections if c [ 'name' ] == selected_collection )
if uploaded_json_file is not None :
if st . button ( "上传并插入到选定的Collection" ):
with st . spinner ( "正在上传 JSON 文件并插入数据..." ):
upload_json_chunks ( uploaded_json_file , selected_id )
else :
st . warning ( "没有可用的 Collections,请创建新的 Collection。" )Ce projet a été fortement soutenu par le centre d'intelligence artificielle et le futur Centre de réseau de Zhuhai Campus de l'Université normale de Pékin, le Centre de réduction croisée intelligent du campus de Zhuhai de l'Université normale de Pékin et le centre de recherche en ingénierie du ministère de l'Éducation, la collaboration de l'intelligence du nuage du nuage du Big Data du ministère de l'Éducation, de l'université normale de Beijing Normal University


