transfer nlp
Make PyTorch an optional dependency

NLP에서 재현 가능한 실험 및 전송 학습을 촉진하기 위해 Pytorch 위에 구축 된 프레임 워크 인 Transfer NLP Library에 오신 것을 환영합니다.
이 Colab 노트북에서 고급 API에 대한 개요를 가질 수 있으며, 여기에는 여러 예제에서 프레임 워크를 사용하는 방법을 보여줍니다. 이 노트북의 모든 DL 기반 예제는 세포 내 텐서 보드 교육 모니터링을 포함합니다!
미리 훈련 된 모델 Finetuning의 예는이 Colab 노트북에서 BertClassifier Finetuning에 대한 짧은 실행 자습서를 제공합니다.
mkvirtualenv transfernlp
workon transfernlp
git clone https://github.com/feedly/transfer-nlp.git
cd transfer-nlp
pip install -r requirements.txt
전송 NLP를 라이브러리로 사용하려면 :
# to install the experiment builder only
pip install transfernlp
# to install Transfer NLP with PyTorch and Transfer Learning in NLP support
pip install transfernlp[torch]
또는
pip install git+https://github.com/feedly/transfer-nlp.git
새로운 릴리스 전에 최신 상태를 얻습니다.
관련 예제와 함께 전송 NLP를 사용하려면 :
git clone https://github.com/feedly/transfer-nlp.git
pip install -r requirements.txt
API 문서 및 라이브러리 개요는 여기에서 찾을 수 있습니다.
라이브러리의 핵심은 실험 빌더로 만들어집니다. 실험이 필요로하는 다른 객체를 정의하고 구성 로더가 좋은 방법으로 빌드합니다. 재현 가능한 연구와 쉬운 절제 연구를 위해, 라이브러리는 실험에 구성 파일을 사용하도록 시행합니다. 사람들이 좋은 실험 파일을 구성하는 것에 대한 맛이 다르므로 라이브러리는 여러 형식으로 정의 된 실험을 허용합니다.
Transfer-NLP에서 실험 구성 파일에는 실험을 완전히 정의하는 데 필요한 모든 정보가 포함되어 있습니다. 이곳에서 실험에서 사용하려는 다양한 구성 요소의 이름을 삽입 할 수 있으며 사용하려는 초 매개 변수와 함께 사용됩니다. Transfer-NLP는 제어 패턴의 역전을 사용하여 필요한 클래스 / 메소드 / 함수를 정의 할 수있게되면 ExperimentConfig 클래스는 DictionNary를 생성하고 그에 따라 객체를 인수합니다.
Transfer-NLP 내에서 자신의 클래스를 사용하려면 @register_plugin 데코레이터를 사용하여 등록해야합니다. 각 종류의 구성 요소 (모델, 데이터 로더, 벡터 라이저, 최적화기 등)에 대해 다른 레지스트리를 사용하는 대신 총 사용자 정의를 시행하기 위해 여기에서 단일 레지스트리 만 사용됩니다.
전송 NLP를 DEV 종속성으로만 사용하는 경우 선언적으로 만 사용하고 실험 실행 시간에 사용하려는 객체에서 register_plugin() 호출 할 수 있습니다.
다음은 Yaml 파일에서 실험을 정의하는 방법의 예입니다.
data_loader:
_name: MyDataLoader
data_parameter: foo
data_vectorizer:
_name: MyVectorizer
vectorizer_parameter: bar
model:
_name: MyModel
model_hyper_param: 100
data: $data_loader
trainer:
_name: MyTrainer
model: $model
data: $data_loader
loss:
_name: PyTorchLoss
tensorboard_logs: $HOME/path/to/tensorboard/logs
metrics:
accuracy:
_name: Accuracy
_name 매개 변수와 자체 매개 변수가 주어지면 클래스, 메소드 또는 함수를 통해 모든 객체를 정의 할 수 있습니다. 실험은 ExperimentConfig(experiment=experiment_path_or_dict) 사용하여로드하고 인스턴스화됩니다.
몇 가지 고려 사항 :
기본값 매개 변수는 실험 파일에서 건너 뛸 수 있습니다.
객체가 다른 장소에서 사용되는 경우 $ 기호를 사용하여이를 참조 할 수 있습니다. 예를 들어 trainer 객체는 다른 곳에서 인스턴스화 된 data_loader 사용합니다. 객체 주문이 필요하지 않습니다.
경로의 경우 다른 기계가 실험을 실행할 수 있도록 환경 변수를 사용하려고 할 수 있습니다. 이전 예에서는 실험을 인스턴스화하고 기계 홈 경로로 $HOME 교체하기 위해 ExperimentConfig(experiment=yaml_path, HOME=Path.home()) 를 실행합니다.
Config Instantiation을 사용하면 중첩 DICT / LIST가있는 복잡한 설정이 가능합니다.
구성 로더가 빌드 할 수있는 실험 설정의 예를위한 테스트를 살펴볼 수 있습니다. 또한 experiments/ 에서 실험 할 수있는 실험을 제공합니다.
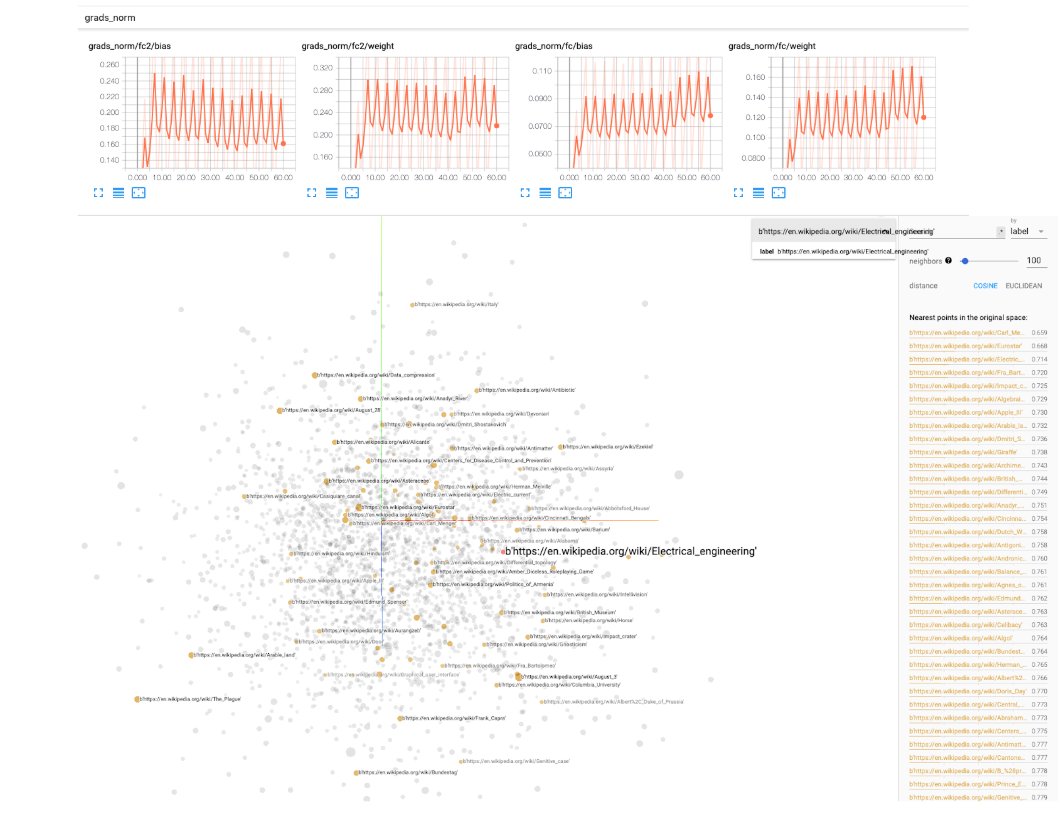
딥 러닝 실험의 경우 transfer_nlp.plugins.trainers.py 에서 BaseIgniteTrainer 제공합니다. 이 기본 트레이너는 모델과 일부 데이터를 입력으로 가져 와서 전체 교육 파이프 라인을 실행합니다. 우리는 Pytorch-Indite Library를 사용하여 교육 중 이벤트를 모니터링합니다 (일부 메트릭을 기록하고 학습 속도 조작, 체크 포인팅 모델 등). Tensorboard 로그도 옵션으로 포함되어 있으므로 구성 파일에 tensorboard_logs 간단한 매개 변수 경로를 지정해야합니다. 그런 다음 tensorboard --logdir=path/to/logs in Terminal을 실행하면 훈련 중에 실험을 모니터링 할 수 있습니다! Tensorboard에는 모델 가중치, 히스토그램, 분포, 임베딩 시각화 등의 규범을 추적하기 위해 매우 훌륭한 유틸리티가 제공되므로 사용하는 것이 좋습니다.
우리는 하나의 작업을 다루는 감독 된 설정에 사용할 수있는 SingleTaskTrainer 클래스를 제공합니다. 우리는 멀티 태스크 설정을 처리하기 위해 MultiTaskTrainer 클래스와 대규모 모델을위한 SingleTaskFineTuner 태스크 파이너 튜너를 처리하고 있습니다.
전송 NLP의 몇 가지 사용 사례는 다음과 같습니다.
ExperimentRunner 클래스는 실험 세트를 순차적으로 실행할 수 있고 개인화 된보고를 생성합니다 (사용자 정의 ReporterABC 클래스에서 report 메소드 만 구현하면됩니다).Module 구현에 집중하고 트레이너가 교육 부분을 처리하도록합니다 (실험 파일을 통해 대부분의 교육 매개 변수를 제어하는 동안).자신의 모델 / 데이터를 실험하는 동안 교육에 시간이 걸릴 수 있습니다. 훈련이 끝나거나 충돌 할 때 알림을 받으려면 Huggingface의 사람들이 간단한 라이브러리 노크 노크를 사용할 수 있습니다.
이 도서관은 Delip Rao와 Brian McMahan의 "Pytorch를 사용한 자연 언어 처리"의 독서에서 영감을 얻었습니다. experiments 실험, 어휘 빌딩 블록 및 가장 가까운 이웃은 책에 제공된 코드에서 가져 오거나 조정됩니다.


