transfer nlp
Make PyTorch an optional dependency

Pytorchの上に構築されたフレームワークであるTransfer NLP Libraryへようこそ。
このColabノートブックにある高レベルのAPIの概要を説明できます。これは、いくつかの例でフレームワークを使用する方法を示しています。これらのノートブックのすべてのDLベースの例は、セル内のテンソルボードトレーニングモニタリングを埋め込みました!
事前に訓練されたモデルFinetuningの例については、このコラブノートブックでBertClassifier Finetuningに関する短い実行可能なチュートリアルを提供します
mkvirtualenv transfernlp
workon transfernlp
git clone https://github.com/feedly/transfer-nlp.git
cd transfer-nlp
pip install -r requirements.txt
NLPをライブラリとして転送するには:
# to install the experiment builder only
pip install transfernlp
# to install Transfer NLP with PyTorch and Transfer Learning in NLP support
pip install transfernlp[torch]
または
pip install git+https://github.com/feedly/transfer-nlp.git
新しいリリースの前に最新の状態を取得します。
関連する例でNLPを転送するには:
git clone https://github.com/feedly/transfer-nlp.git
pip install -r requirements.txt
APIドキュメントとライブラリの概要はこちらをご覧ください
ライブラリのコアは実験ビルダーで作られています。実験が必要とするさまざまなオブジェクトを定義し、構成ローダーがそれらを優れた方法で構築します。再現可能な研究と簡単なアブレーション研究のために、ライブラリは実験のために構成ファイルの使用を実施します。人々は優れた実験ファイルを構成するものに対して異なる好みを持っているため、ライブラリはいくつかの形式で定義された実験を許可します。
Transfer-NLPでは、実験構成ファイルには、実験を完全に定義するために必要なすべての情報が含まれています。これは、使用するハイパーパラメーターとともに、実験が使用するさまざまなコンポーネントの名前を挿入する場所です。 Transfer-NLPは、コントロールパターンの反転を使用します。これにより、必要なクラス /メソッド /関数を定義できます。 ExperimentConfigクラスは、辞書を作成し、それに応じてオブジェクトを設置します。
Transfer-NLP内で独自のクラスを使用するには、 @register_pluginデコレーターを使用してそれらを登録する必要があります。各種類のコンポーネント(モデル、データローダー、ベクトルザー、オプティマイザーなど)に異なるレジストリを使用する代わりに、完全なカスタマイズを実施するために、ここでは単一のレジストリのみが使用されます。
NLPをDEV依存関係としてのみ使用する場合は、宣言的にのみ使用し、実験実行時間で使用するオブジェクトにregister_plugin()を呼び出すことをお勧めします。
YAMLファイルで実験を定義する方法の例は次のとおりです。
data_loader:
_name: MyDataLoader
data_parameter: foo
data_vectorizer:
_name: MyVectorizer
vectorizer_parameter: bar
model:
_name: MyModel
model_hyper_param: 100
data: $data_loader
trainer:
_name: MyTrainer
model: $model
data: $data_loader
loss:
_name: PyTorchLoss
tensorboard_logs: $HOME/path/to/tensorboard/logs
metrics:
accuracy:
_name: Accuracy
任意のオブジェクトは、 _nameパラメーターに続いて独自のパラメーターを使用して、クラス、方法、または関数を通じて定義できます。その後、実験はExperimentConfig(experiment=experiment_path_or_dict)を使用してロードされ、インスタンス化されます
いくつかの考慮事項:
デフォルトのパラメーターは、実験ファイルでスキップできます。
オブジェクトが異なる場所で使用されている場合、 $シンボルを使用してそれを参照できます。たとえば、 trainerオブジェクトは他の場所にインスタンス化されたdata_loaderを使用します。オブジェクトの順序は必要ありません。
パスの場合、他のマシンも実験を実行できるように、環境変数を使用することをお勧めします。前の例では、 ExperimentConfig(experiment=yaml_path, HOME=Path.home())を実行して、実験をインスタンス化し、 $HOMEマシンホームパスに置き換えます。
構成インスタンス化により、ネストされたdict / listを使用した複雑な設定が可能になります
構成ローダーが構築できる実験設定の例については、テストを見ることができます。さらに、 experiments/で実行可能な実験を提供します。
ディープラーニング実験のために、 transfer_nlp.plugins.trainers.pyでBaseIgniteTrainerを提供します。この基本的なトレーナーは、モデルといくつかのデータを入力として取得し、トレーニングパイプライン全体を実行します。 Pytorch-Ingiteライブラリを利用して、トレーニング中のイベントを監視します(いくつかのメトリックのログ、学習率の操作、チェックポイントモデルなど)。テンソルボードログもオプションとして含まれています。構成ファイルにtensorboard_logs簡単なパラメーターパスを指定する必要があります。次に、 tensorboard --logdir=path/to/logs in terminalでは、トレーニング中に実験を監視できます。 Tensorboardには、モデルの重み、ヒストグラム、分布、埋め込みなどの規範を追跡するための非常に優れたユーティリティが付属しているため、使用することをお勧めします。
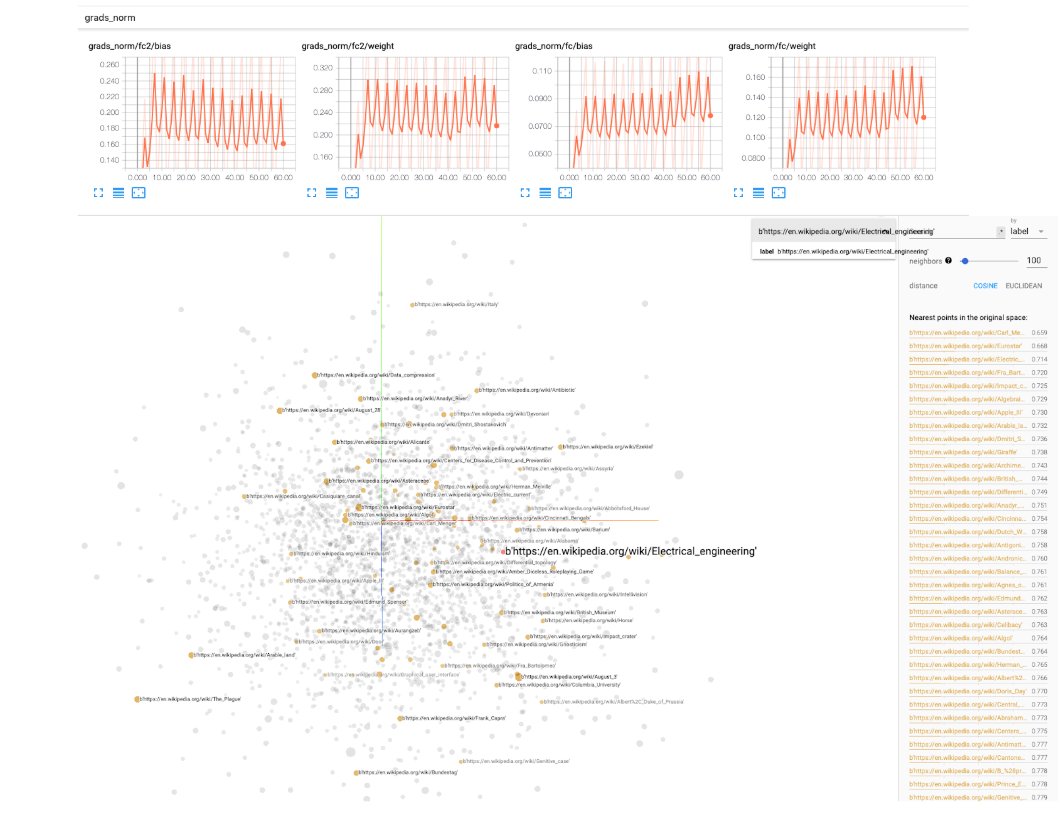
1つのタスクを扱う任意の任意の設定に使用できるSingleTaskTrainerクラスを提供します。マルチタスク設定を扱うために、マルチMultiTaskTrainerクラスと、大規模なモデルの微調整設定用のSingleTaskFineTunerに取り組んでいます。
NLPを転送するためのいくつかのユースケースを次に示します。
ExperimentRunnerクラスでは、実験のセットを順次実行し、パーソナライズされたレポートを生成することができます(カスタムReporterABCクラスでreportメソッドのみを実装する必要があります)Module実装に焦点を当て、トレーナーがトレーニングパラメーターのほとんどを制御しながら、トレーニング部品に対処できるようにします)独自のモデル /データを試している間、トレーニングには時間がかかる場合があります。トレーニングが終了またはクラッシュしたときに通知を受けるには、Huggingfaceの人々がシンプルなライブラリノックノックを使用して、Slack、電子メールなどで通知するためにシンプルなデコレーターを実行していることを使用できます。
図書館は、デリップ・ラオとブライアン・マクマハンによる「Pytorchとの自然言語加工」の読書に触発されました。 experiments実験、語彙の構成ブロック、および埋め込み最近の隣人は、本に記載されているコードから採取または採用されています。


