transfer nlp
Make PyTorch an optional dependency

Bienvenue à la bibliothèque NLP Transfer, un cadre construit au-dessus de Pytorch pour promouvoir l'expérimentation reproductible et l'apprentissage du transfert dans PNLP
Vous pouvez avoir un aperçu de l'API de haut niveau sur ce cahier Colab, qui montre comment utiliser le cadre sur plusieurs exemples. Tous les exemples basés sur DL sur ces ordinateurs portables incorporent la surveillance de la formation en tensorboard à cellules!
Pour un exemple de Finetuning de modèle pré-formé, nous fournissons un court didacticiel exécutable sur BertClassifier Finetuning sur ce cahier Colab
mkvirtualenv transfernlp
workon transfernlp
git clone https://github.com/feedly/transfer-nlp.git
cd transfer-nlp
pip install -r requirements.txt
Pour utiliser le transfert NLP comme bibliothèque:
# to install the experiment builder only
pip install transfernlp
# to install Transfer NLP with PyTorch and Transfer Learning in NLP support
pip install transfernlp[torch]
ou
pip install git+https://github.com/feedly/transfer-nlp.git
Pour obtenir le dernier état avant de nouvelles versions.
Pour utiliser le transfert de PNL avec des exemples associés:
git clone https://github.com/feedly/transfer-nlp.git
pip install -r requirements.txt
La documentation de l'API et un aperçu de la bibliothèque peuvent être trouvés ici
Le cœur de la bibliothèque est fait d'un constructeur d'expérience: vous définissez les différents objets dont votre expérience a besoin, et le chargeur de configuration les construit d'une manière agréable. Pour la recherche reproductible et les études d'ablation faciles, la bibliothèque applique ensuite l'utilisation de fichiers de configuration pour les expériences. Comme les gens ont des goûts différents pour ce qui constitue un bon fichier d'expérience, la bibliothèque permet des expériences définies dans plusieurs formats:
Dans Transfer-NLP, un fichier de configuration d'expérience contient toutes les informations nécessaires pour définir entièrement l'expérience. C'est là que vous insérez les noms des différents composants que votre expérience utilisera, ainsi que les hyperparamètres que vous souhaitez utiliser. Le transfert-NLP utilise l'inversion du modèle de contrôle, qui vous permet de définir n'importe quelle classe / méthode / fonction dont vous pourriez avoir besoin, la classe ExperimentConfig créera un dictionNary et Instatiera vos objets en conséquence.
Pour utiliser vos propres classes à l'intérieur de transfert-nlp, vous devez les enregistrer à l'aide du décorateur @register_plugin . Au lieu d'utiliser un registre différent pour chaque type de composant (modèles, chargeurs de données, vectoriels, optimisateurs, ...), un seul registre est utilisé ici, afin d'appliquer la personnalisation totale.
Si vous utilisez le transfert NLP comme dépendance de développement uniquement, vous voudrez peut-être l'utiliser de manière déclarative uniquement et appeler register_plugin() sur les objets que vous souhaitez utiliser au temps d'exécution de l'expérience.
Voici un exemple de la façon dont vous pouvez définir une expérience dans un fichier YAML:
data_loader:
_name: MyDataLoader
data_parameter: foo
data_vectorizer:
_name: MyVectorizer
vectorizer_parameter: bar
model:
_name: MyModel
model_hyper_param: 100
data: $data_loader
trainer:
_name: MyTrainer
model: $model
data: $data_loader
loss:
_name: PyTorchLoss
tensorboard_logs: $HOME/path/to/tensorboard/logs
metrics:
accuracy:
_name: Accuracy
Tout objet peut être défini via une classe, une méthode ou une fonction, compte tenu d'un _name paramètres suivis de ses propres paramètres. Les expériences sont ensuite chargées et instanciées à l'aide ExperimentConfig(experiment=experiment_path_or_dict)
Quelques considérations:
Les paramètres par défaut peuvent être ignorés dans le fichier d'expérience.
Si un objet est utilisé à différents endroits, vous pouvez vous y référer à l'aide du symbole $ , par exemple ici, l'objet trainer utilise le data_loader instancié ailleurs. Aucune commande d'objets n'est requise.
Pour les chemins, vous voudrez peut-être utiliser des variables d'environnement afin que d'autres machines puissent également exécuter vos expériences. Dans l'exemple précédent, vous exécuteriez, par exemple ExperimentConfig(experiment=yaml_path, HOME=Path.home()) pour instancier l'expérience et remplacer $HOME par votre chemin d'accueil de votre machine.
L'instanciation de configuration permet tous les paramètres complexes avec un dict / liste imbriqué
Vous pouvez consulter les tests pour des exemples de paramètres d'expérience que le chargeur de configuration peut créer. De plus, nous fournissons des expériences de course dans experiments/ .
Pour les expériences d'apprentissage en profondeur, nous fournissons une BaseIgniteTrainer dans transfer_nlp.plugins.trainers.py . Ce formateur de base prendra un modèle et certaines données en entrée et exécutera un pipeline de formation entier. Nous utilisons la bibliothèque Pytorch-Innimite pour surveiller les événements pendant la formation (enregistrer certaines mesures, manipuler les taux d'apprentissage, les modèles de pointage de contrôle, etc ...). Les journaux de tensorboard sont également inclus comme option, vous devrez spécifier un chemin de paramètres simples tensorboard_logs dans le fichier de configuration. Ensuite, exécutez simplement tensorboard --logdir=path/to/logs dans un terminal et vous pouvez surveiller votre expérience pendant sa formation! Tensorboard est livré avec de très beaux utilitaires pour garder une trace des normes des poids de votre modèle, des histogrammes, des distributions, de la visualisation des intérêts, etc. Nous recommandons donc vraiment de l'utiliser.
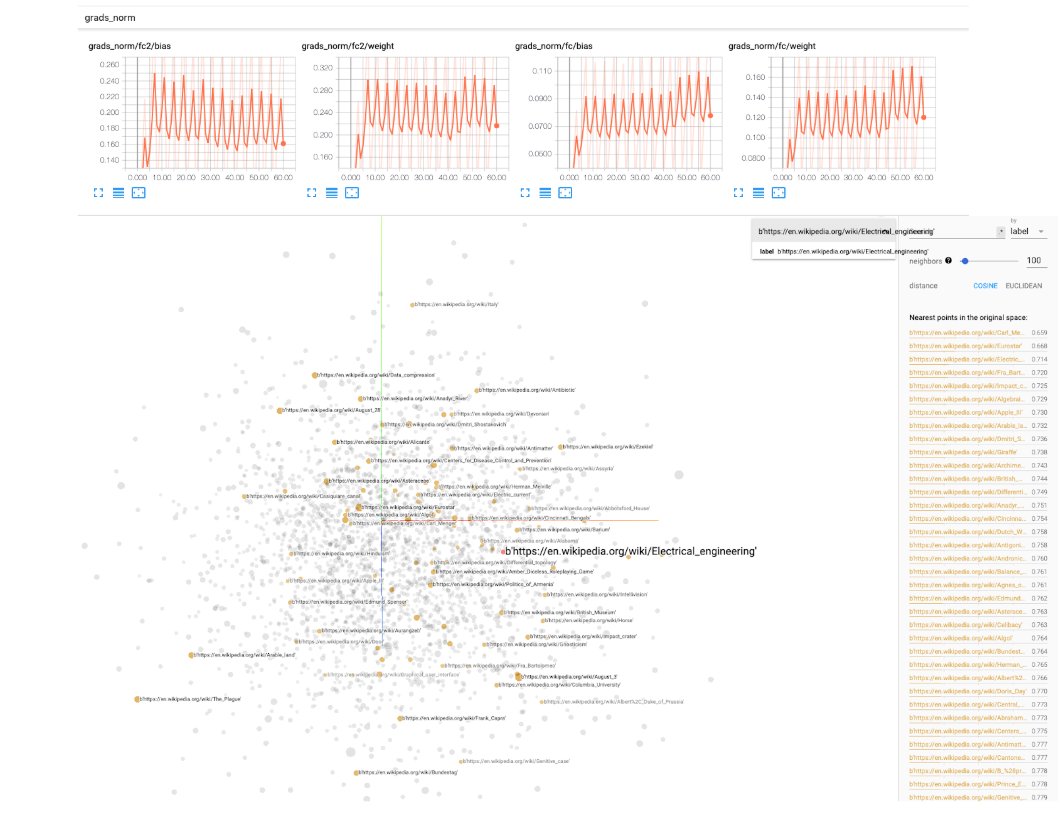
Nous fournissons une classe SingleTaskTrainer que vous pouvez utiliser pour tout réglage supervisé traitant d'une tâche. Nous travaillons sur une classe MultiTaskTrainer pour gérer les paramètres multi-tâches, et un SingleTaskFineTuner pour les grands modèles de paramètres de finetuning.
Voici quelques cas d'utilisation pour le transfert NLP:
ExperimentRunner permet d'exécuter séquentiellement vos ensembles d'expériences et génère des rapports personnalisés (vous n'avez qu'à implémenter votre méthode report dans une classe ReporterABC personnalisée)Module Pytorch et laisser les formateurs s'occuper de la partie de formation (tout en contrôlant la plupart des paramètres de formation via le fichier d'expérience)Tout en expérimentant vos propres modèles / données, la formation pourrait prendre un certain temps. Pour être informé lorsque votre formation se termine ou se bloque, vous pouvez utiliser la simple bibliothèque Knockknock par des gens de HuggingFace, qui ajoutent un décorateur simple à votre fonction de course pour vous informer via Slack, E-mail, etc.
La bibliothèque a été inspirée par la lecture de "Traitement du langage naturel avec Pytorch" de Delip Rao et Brian McMahan. Expériences dans experiments , le bloc de construction du vocabulaire et les voisins les plus proches sont pris ou adaptés du code fourni dans le livre.


