semantic search
v1.0.0
MDX 파일에서 시맨틱 검색 인덱스를 구축하기위한 OpenAi 구동 CLI. 컨텐츠에서 복잡한 검색을 수행하고 플랫폼과 통합 할 수 있습니다.
이 프로젝트는 OpenAI를 사용하여 벡터 임베딩 및 피네 콘을 생성하여 임베딩을 호스팅합니다. 즉, OpenAI 및 Pinecone에 사용하려면 계정을 사용해야합니다.
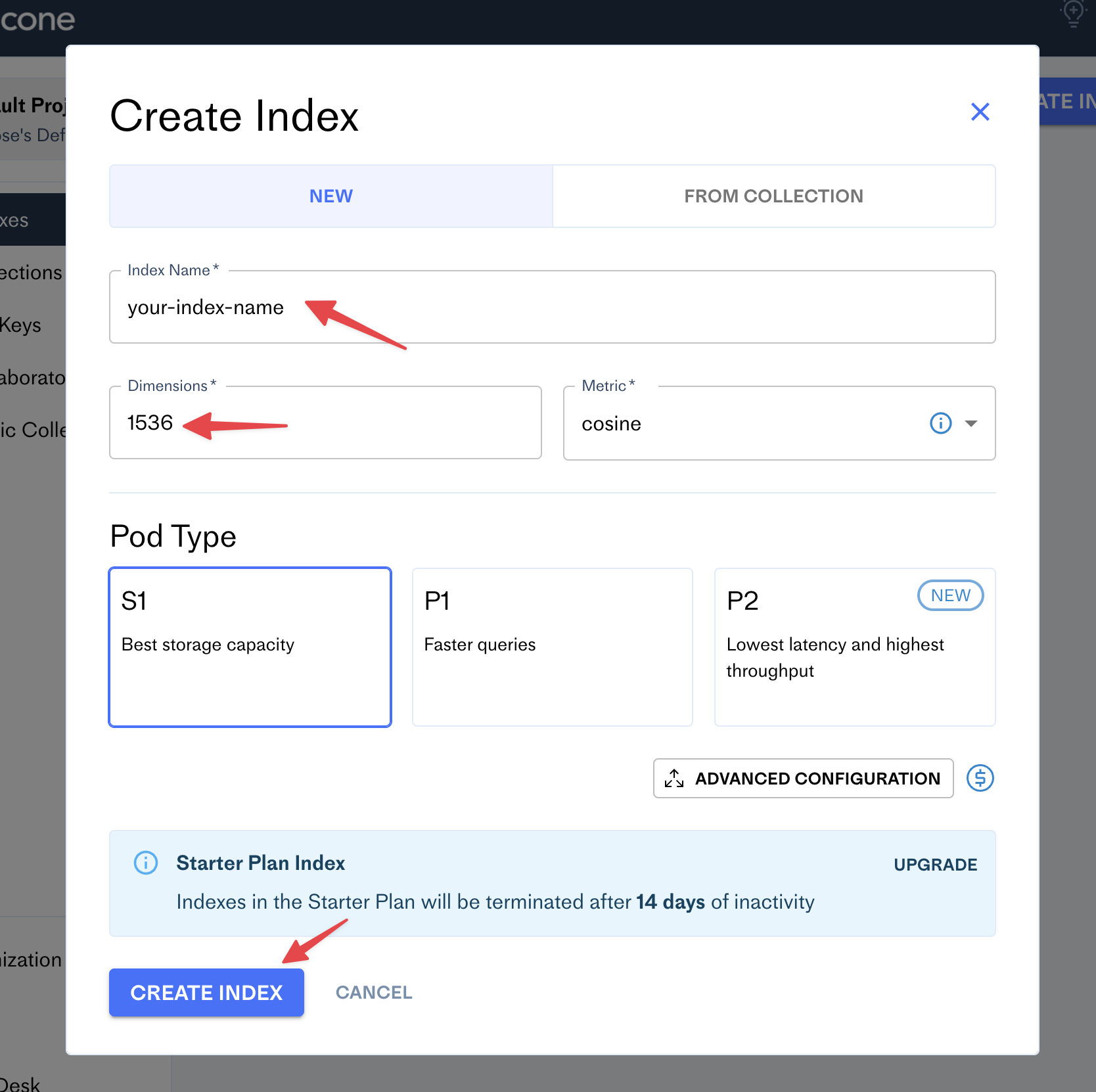
Pinecone에서 계정을 작성한 후 대시 보드로 이동하여 Create Index 버튼을 클릭하십시오.

새 인덱스 이름 (예 : 블로그 이름)으로 양식을 채우고 차원 수를 1536으로 설정하십시오.
피네콘
Openai
CLI에는 4 개의 env 키가 필요합니다.
OPENAI_API_KEY=
PINECONE_API_KEY=
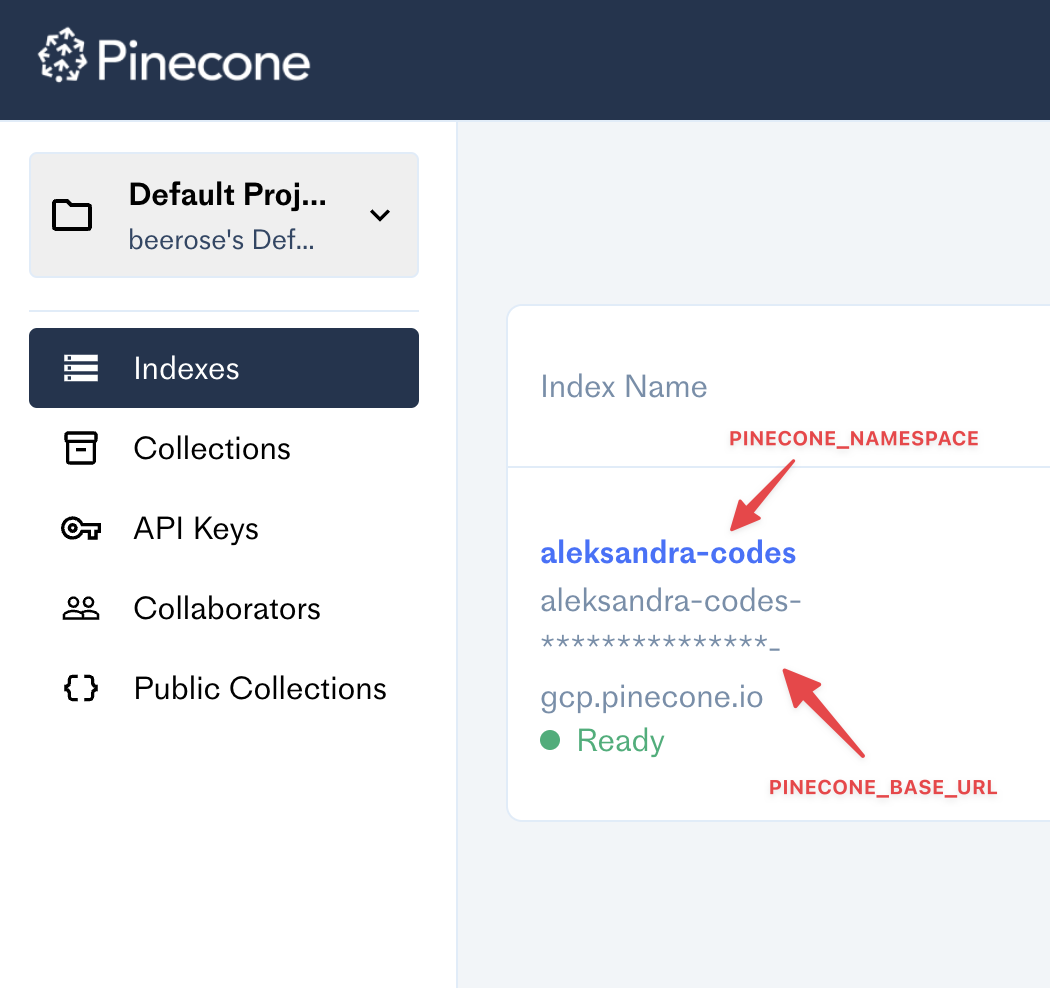
PINECONE_BASE_URL=
PINECONE_NAMESPACE=사용하기 전에 추가하십시오!
index <dir> - 컨텐츠로 파일을 처리하고 Pinecone에 업로드합니다.
예:
$ @beerose/semantic-search index ./posts search <query> - 주어진 쿼리로 의미 검색을 수행합니다.
예:
$ @beerose/semantic-search search " hello world " 자세한 내용은 --help 플래그로 명령을 실행하십시오.
$ @beerose/semantic-search index --help
$ @beerose/semantic-search search --help
$ @beerose/semantic-search --help 이 라이브러리에서 내보낸 semanticQuery 함수를 사용하여 웹 사이트 또는 응용 프로그램과 통합 할 수 있습니다.
DEP 설치 :
$ pnpm add pinecone-client openai @beerose/semantic-search
# or `yarn add` or `npm i`예제 사용 :
import { PineconeMetadata , semanticQuery } from "@beerose/semantic-search" ;
import { Configuration , OpenAIApi } from "openai" ;
import { PineconeClient } from "pinecone-client" ;
const openai = new OpenAIApi (
new Configuration ( {
apiKey : process . env . OPENAI_API_KEY ,
} )
) ;
const pinecone = new PineconeClient < PineconeMetadata > ( {
apiKey : process . env . PINECONE_API_KEY ,
baseUrl : process . env . PINECONE_BASE_URL ,
namespace : process . env . PINECONE_NAMESPACE ,
} ) ;
const result = await semanticQuery ( "hello world" , openai , pinecone ) ;다음은 Aleksandra.codes의 API 경로 예입니다 : https://github.com/beerose/aleksandra.codes/blob/main/api/search.ts
시맨틱 검색은 문서에서 단어의 의미를 이해하고 사용자의 의도와 더 관련이있는 결과를 반환 할 수 있습니다.
이 도구는 OpenAI를 사용하여 text-embedding-ada-002 모델로 벡터 임베딩을 생성합니다.
임베딩은 숫자 시퀀스로 변환 된 개념의 수치 표현으로 컴퓨터가 해당 개념 간의 관계를 쉽게 이해할 수있게합니다. https://openai.com/blog/new-and-improved-embedding-model/
또한 벡터 검색을 위해 호스팅 된 데이터베이스 인 Pinecone을 사용합니다. 생성 된 임베딩에서 K-NN 검색을 수행 할 수 있습니다.
@beerose/sematic-search index CLI 명령은 주어진 디렉토리에서 각 파일에 대해 다음 단계를 수행합니다.
콘텐츠에 따라 전체 프로세스에는 OpenAi 및 Pinecone에 대한 많은 전화가 필요하므로 시간이 걸릴 수 있습니다. 예를 들어, ~ 25 개의 블로그 게시물이있는 디렉토리와 평균 6 분의 읽기 시간이있는 디렉토리의 경우 약 30 분이 걸립니다.
시맨틱 검색을 테스트하려면 @beerose/sematic-search search CLI 명령을 사용할 수 있습니다.
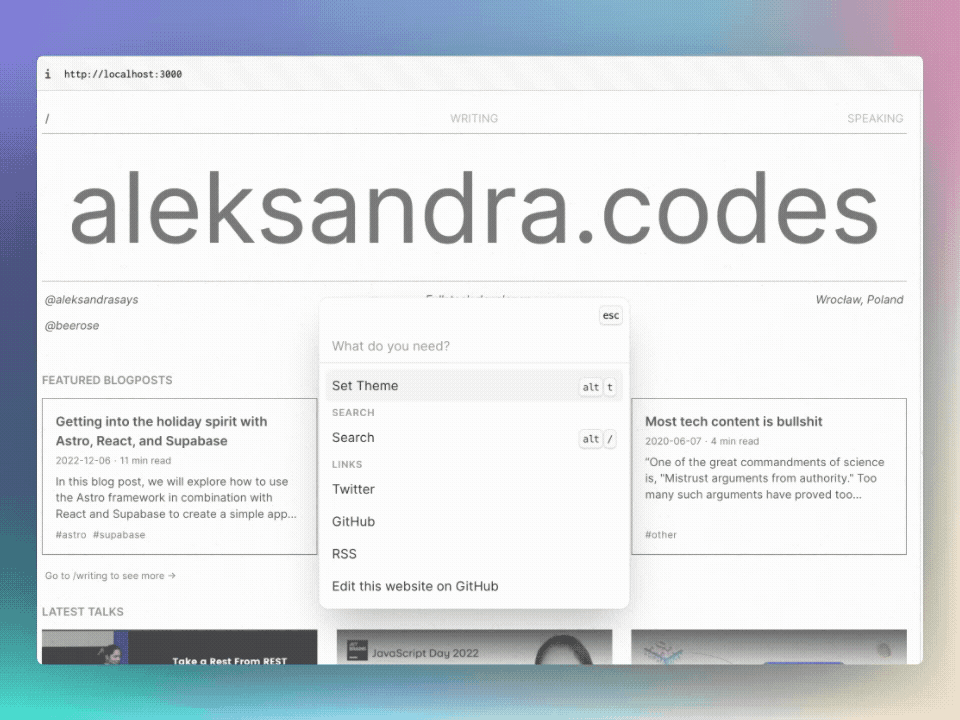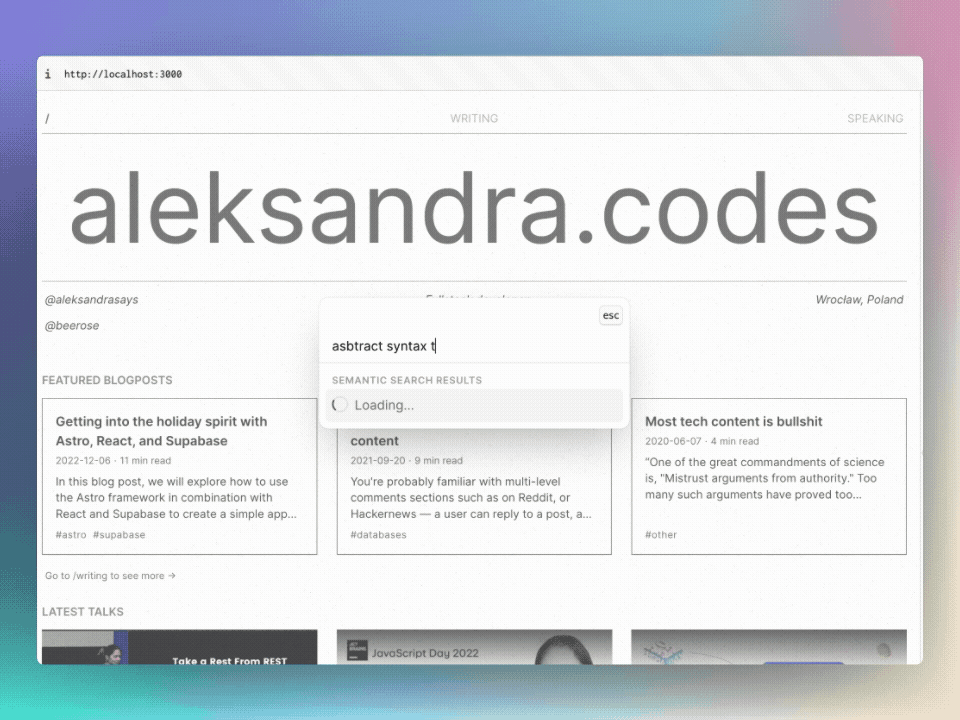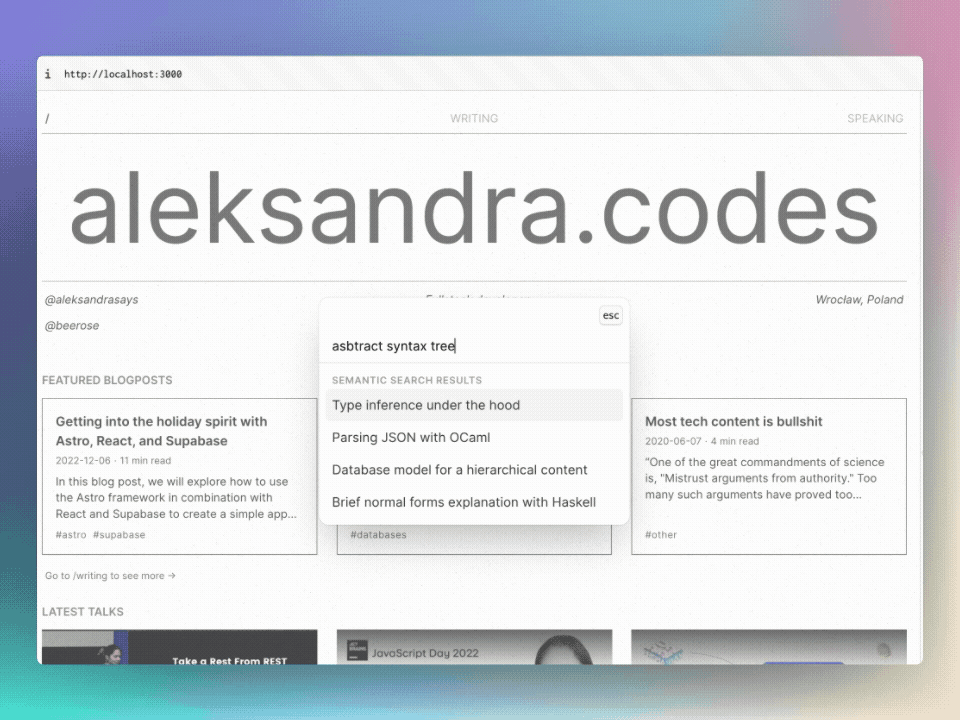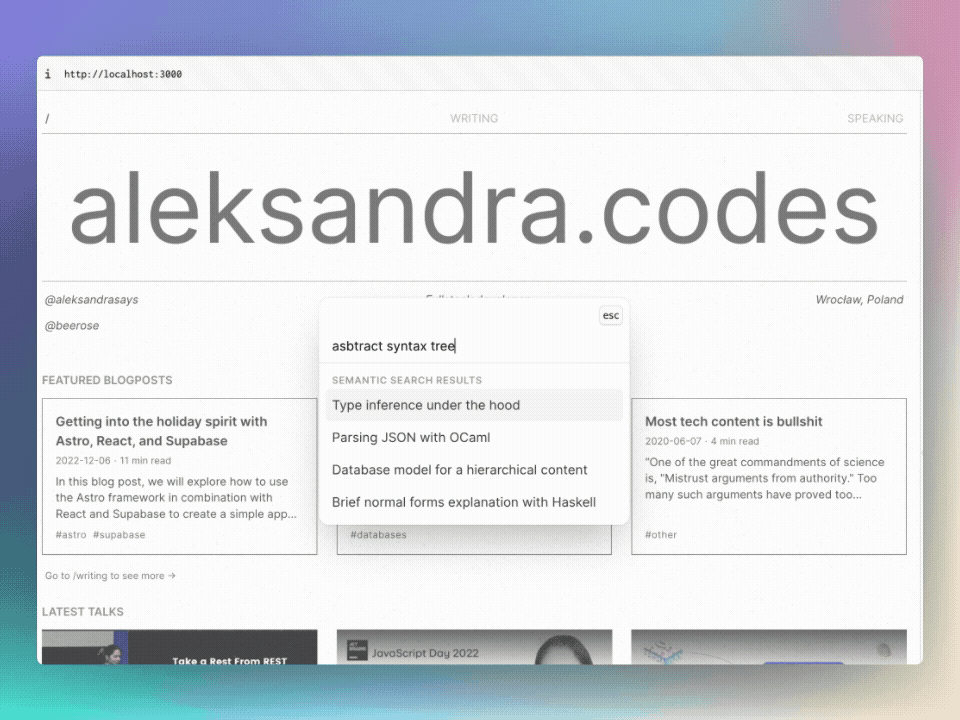
.
├── bin
│ └── cli.js
├── src
│ ├── bin
│ │ └── cli.ts
│ ├── commands
│ │ ├── indexFiles.ts
│ │ └── search.ts
│ ├── getEmbeddings.ts
│ ├── isRateLimitExceeded.ts
│ ├── mdxToPlainText.test.ts
│ ├── mdxToPlainText.ts
│ ├── semanticQuery.ts
│ ├── splitIntoChunks.test.ts
│ ├── splitIntoChunks.ts
│ ├── titleCase.ts
│ └── types.ts
├── tsconfig.build.json
├── tsconfig.json
├── package.json
└── pnpm-lock.yamlbin/cli.js - CLI EntryPoint.src :bin/cli.ts - CLI 명령 및 설정을 찾을 수있는 파일. 이 프로젝트는 CLI를 구축하는 데 CAC를 사용합니다.commands/indexFiles.ts - MD/MDX 컨텐츠 처리, 임베딩 생성 및 벡터를 PENECONE에 처리하는 CLI 명령.command/search.ts - 의미 검색 명령. 주어진 검색 쿼리에 대한 임베딩을 생성 한 다음 결과를 위해 Pinecone을 호출합니다.getEmbeddings.ts - 임베딩 로직 생성. AI를 열기위한 전화를 처리합니다.isRateLimitExceeded.ts - 오류 처리 도우미.mdxToPlainText.ts - MDX 파일을 원시 텍스트로 변환합니다. 비고 및 사용자 정의 remarkMdxToPlainText 플러그인을 사용합니다 (해당 파일에도 정의 됨).semanticQuery.ts - 시맨틱 검색을 수행하기위한 핵심 논리. search 명령에 사용되고 있으며이 라이브러리에서 내보내려 프로젝트와 통합 할 수 있습니다.splitIntoChunks.ts - 텍스트를 최대 100 개의 토큰으로 청크로 나눕니다.titleCase.ts - 파일 경로에서 제목을 추출합니다.types.ts -이 프로젝트에 사용되는 유형 및 유틸리티.tsconfig.json TypeScript 컴파일러 구성.tsconfig.build.json pnpm build 에 사용되는 TypeScript 컴파일러 구성.테스트 :
src/mdxToPlainText.test.tssrc/splitIntoChunks.test.tsDEP를 설치하고 프로젝트 구축 :
pnpm i
pnpm buildCLI를 로컬로 실행하십시오.
node bin/cli.jspnpm test 기부금, 문제 및 기능 요청을 환영합니다.
기여하려면 문제 페이지를 확인하십시오.
Copyright © 2023 Aleksandra Sikora.
이 프로젝트는 MIT 라이센스가 부여되었습니다.


