semantic search
v1.0.0
MDXファイルからセマンティック検索インデックスを構築するためのOpenAIを搭載したCLI。コンテンツ全体で複雑な検索を実行し、プラットフォームと統合することができます。
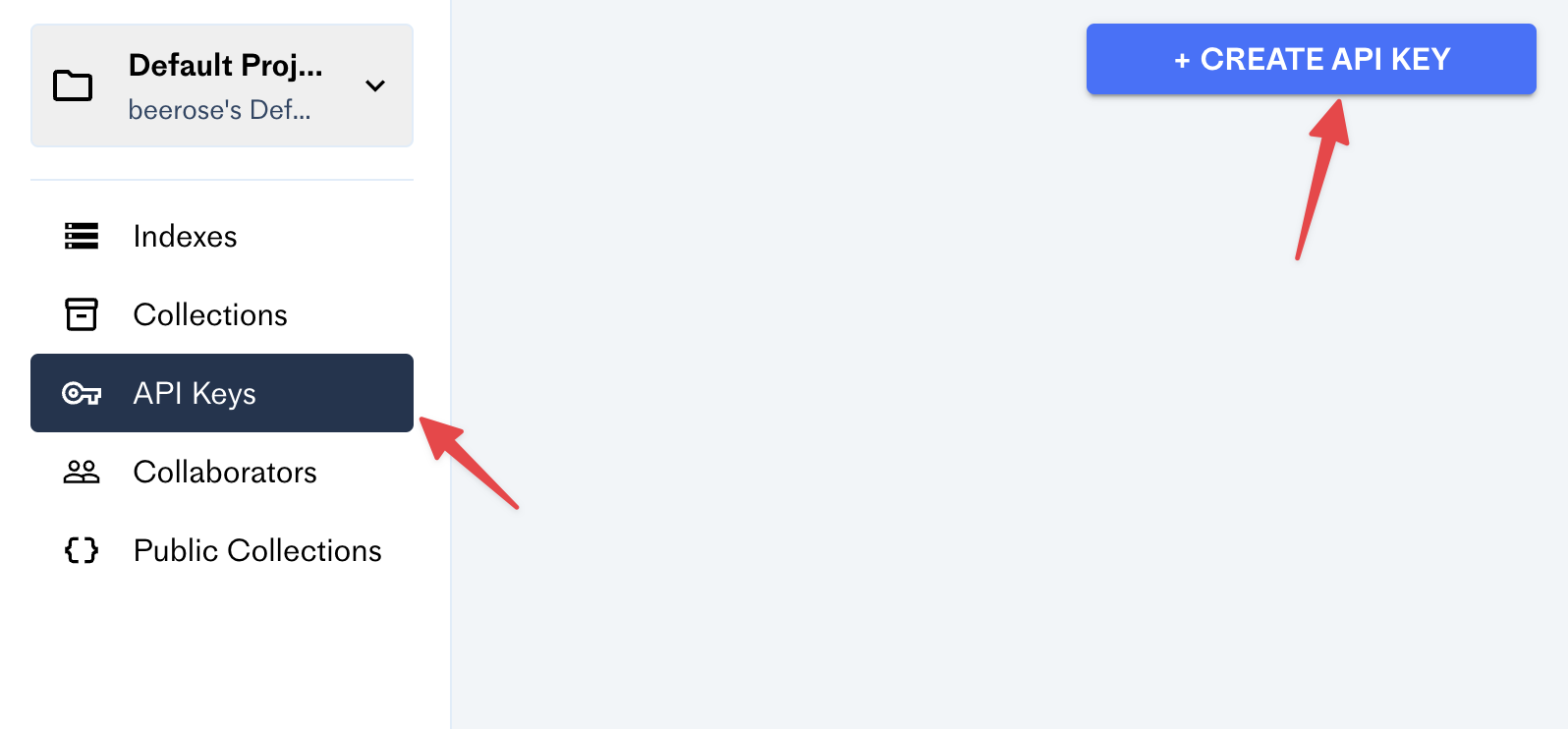
このプロジェクトでは、OpenAIを使用してベクトル埋め込みと松ぼっくりを生成して埋め込みをホストします。つまり、OpenaiとPineconeに使用するにはアカウントが必要です。
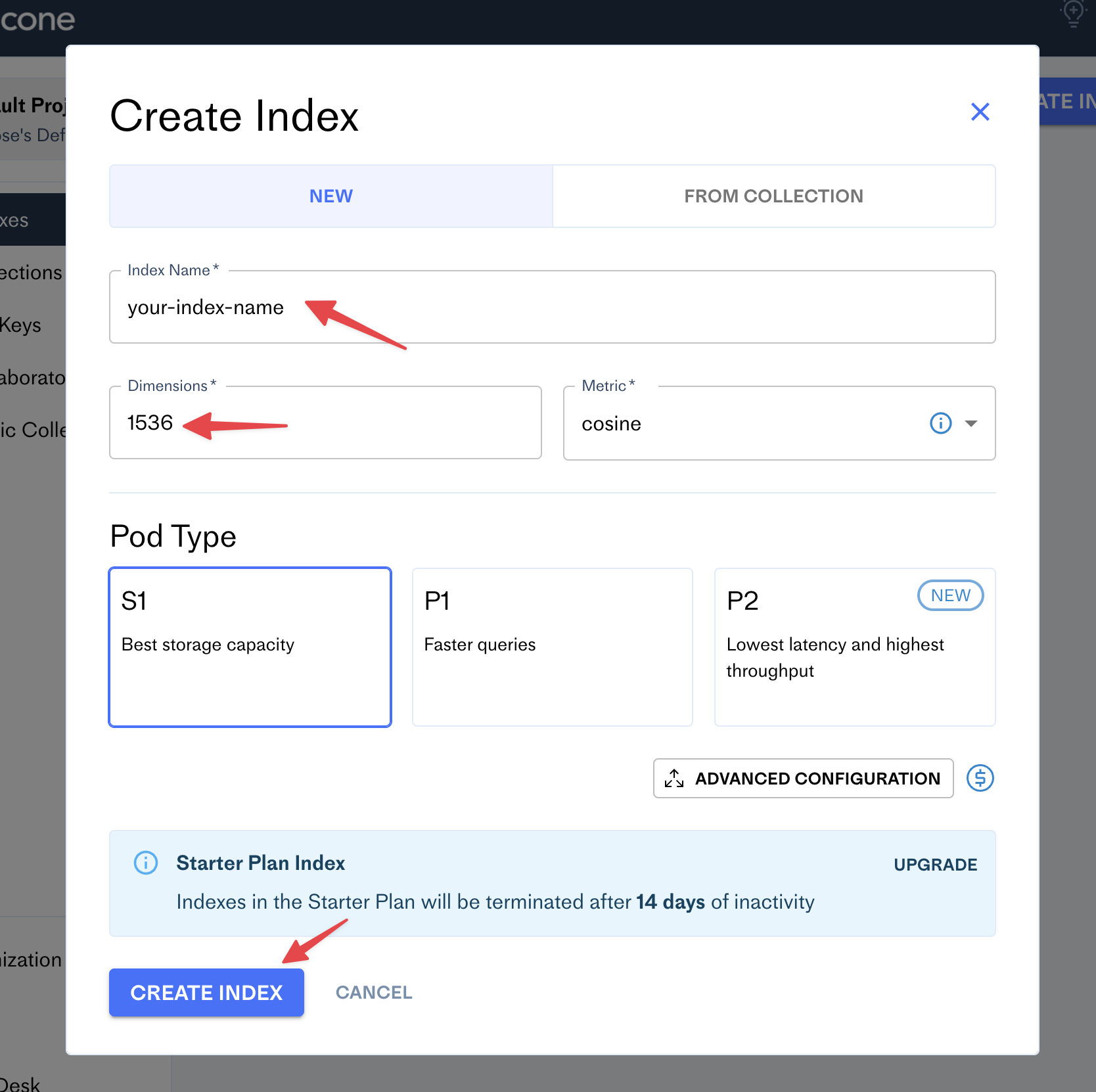
Pineconeでアカウントを作成した後、ダッシュボードに移動し、 Create Indexボタンをクリックします。

新しいインデックス名(ブログ名など)でフォームに記入し、寸法の数を1536に設定します。
松ぼっくり
Openai
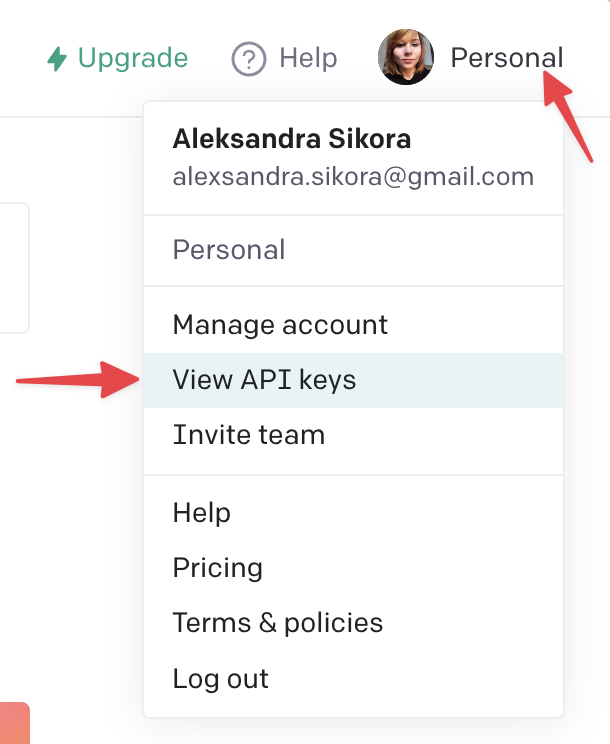
CLIには4つのenvキーが必要です。
OPENAI_API_KEY=
PINECONE_API_KEY=
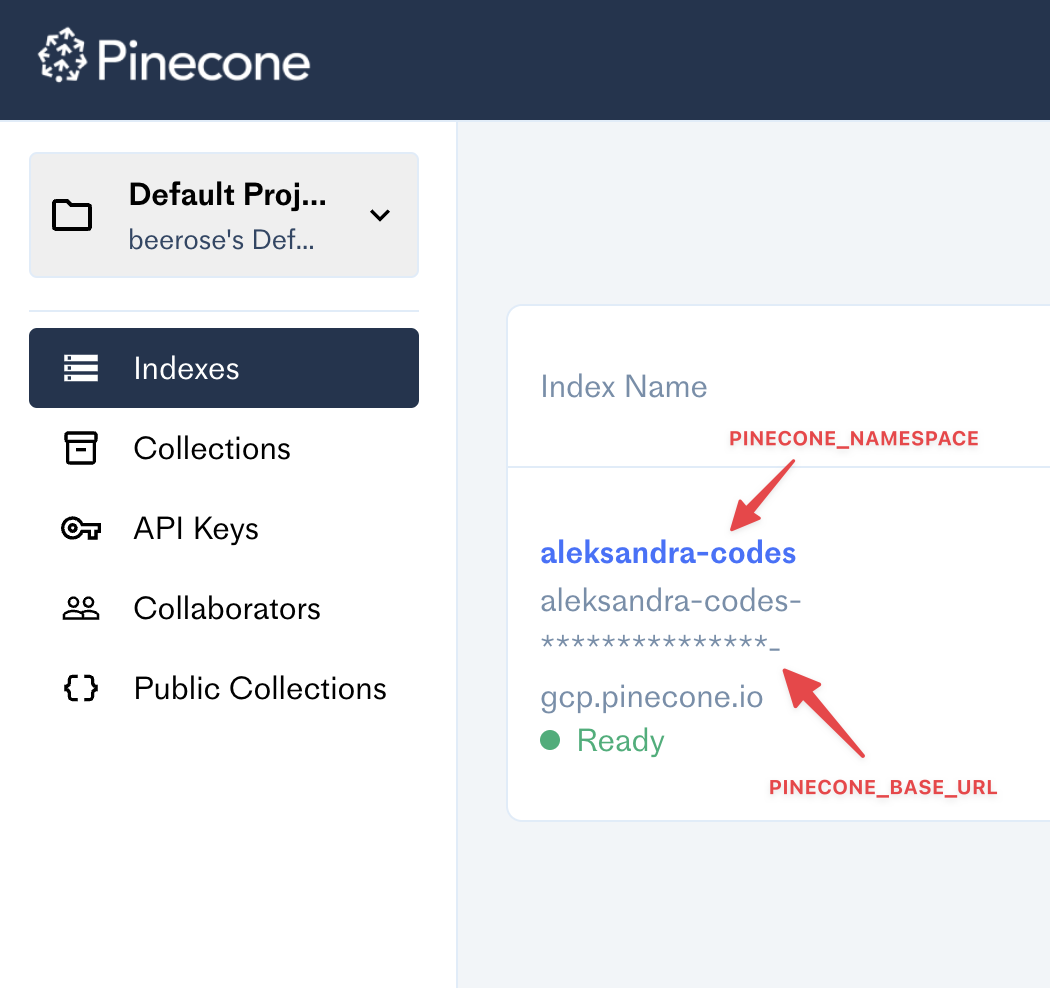
PINECONE_BASE_URL=
PINECONE_NAMESPACE=使用する前に必ず追加してください!
index <dir> - コンテンツでファイルを処理し、それらをPineconeにアップロードします。
例:
$ @beerose/semantic-search index ./posts search <query> - 特定のクエリでセマンティック検索を実行します。
例:
$ @beerose/semantic-search search " hello world "詳細については、 --helpフラグを使用してコマンドを実行します。
$ @beerose/semantic-search index --help
$ @beerose/semantic-search search --help
$ @beerose/semantic-search --helpこのライブラリからエクスポートされたsemanticQuery関数を使用して、Webサイトまたはアプリケーションに統合できます。
DEPSのインストール:
$ pnpm add pinecone-client openai @beerose/semantic-search
# or `yarn add` or `npm i`使用例:
import { PineconeMetadata , semanticQuery } from "@beerose/semantic-search" ;
import { Configuration , OpenAIApi } from "openai" ;
import { PineconeClient } from "pinecone-client" ;
const openai = new OpenAIApi (
new Configuration ( {
apiKey : process . env . OPENAI_API_KEY ,
} )
) ;
const pinecone = new PineconeClient < PineconeMetadata > ( {
apiKey : process . env . PINECONE_API_KEY ,
baseUrl : process . env . PINECONE_BASE_URL ,
namespace : process . env . PINECONE_NAMESPACE ,
} ) ;
const result = await semanticQuery ( "hello world" , openai , pinecone ) ;Aleksandra.CodesのAPIルートの例:https://github.com/beerose/aleksandra.codes/blob/main/api/search.ts
セマンティック検索では、ドキュメント内の単語の意味を理解し、ユーザーの意図により関連する結果を返すことができます。
このツールは、OpenAIを使用して、 text-embedding-ada-002モデルでベクトル埋め込みを生成します。
埋め込みは、数字シーケンスに変換された概念の数値表現であり、コンピューターがそれらの概念間の関係を簡単に理解できるようにします。 https://openai.com/blog/new-and-ifroved-embedding-model/
また、Vector検索のためにホストされたデータベースであるPineconeも使用します。生成された埋め込みを介してk-nn検索を実行できます。
@beerose/sematic-search index CLIコマンドは、特定のディレクトリ内の各ファイルに対して次の手順を実行します。
コンテンツに応じて、プロセス全体には、OpenaiとPineconeへの多くの呼び出しが必要であり、時間がかかる場合があります。たとえば、約25のブログ投稿と平均6分間の読み取り時間を備えたディレクトリには約30分かかります。
セマンティック検索をテストするには、 @beerose/sematic-search search CLIコマンドを使用できます。
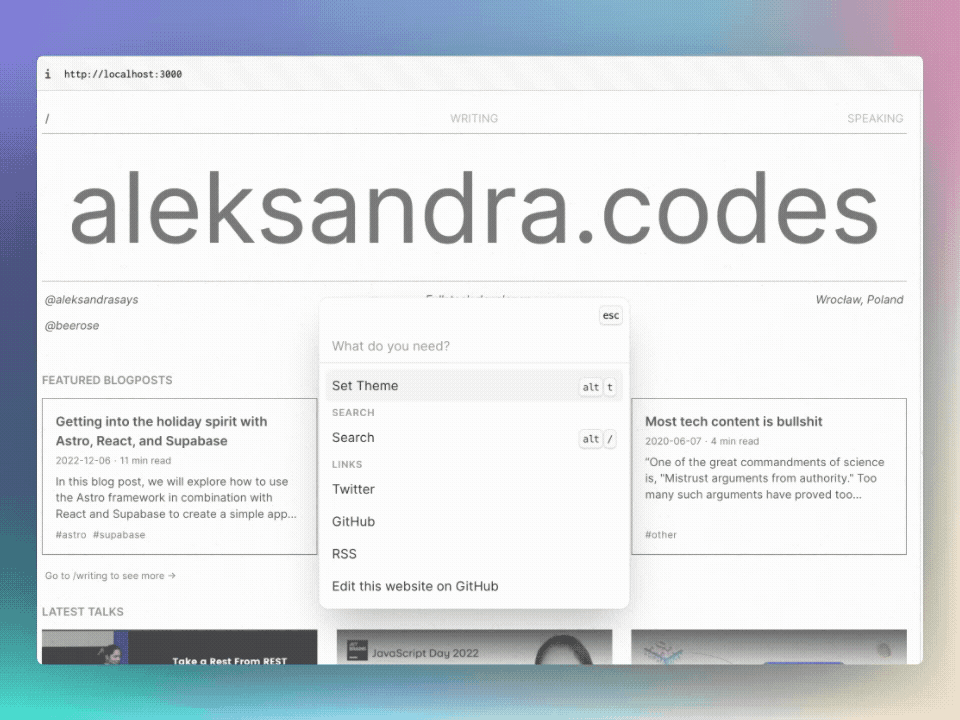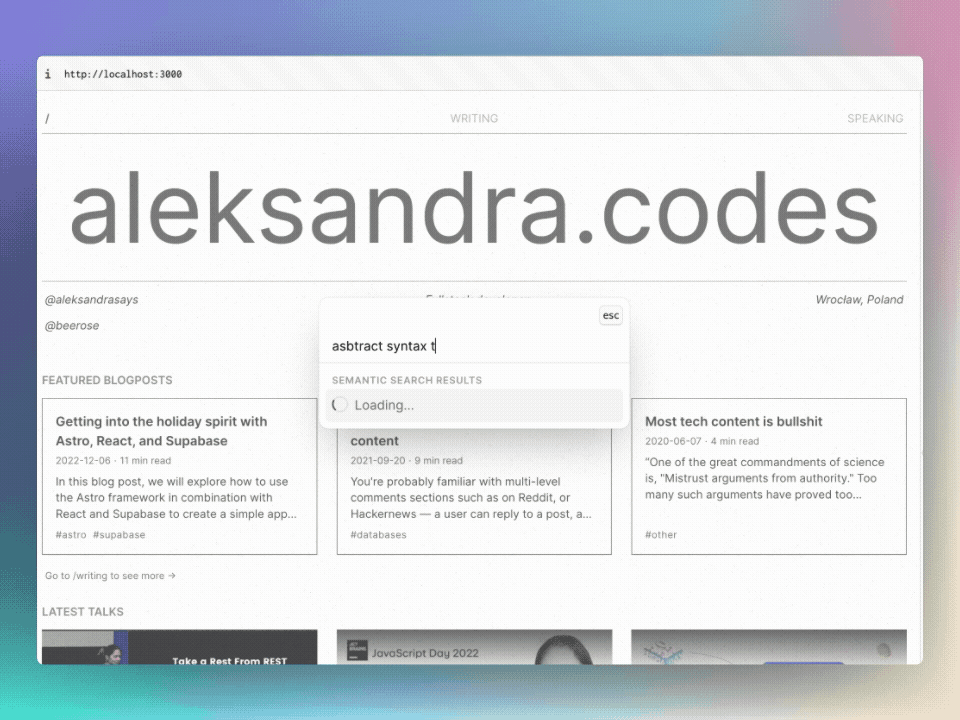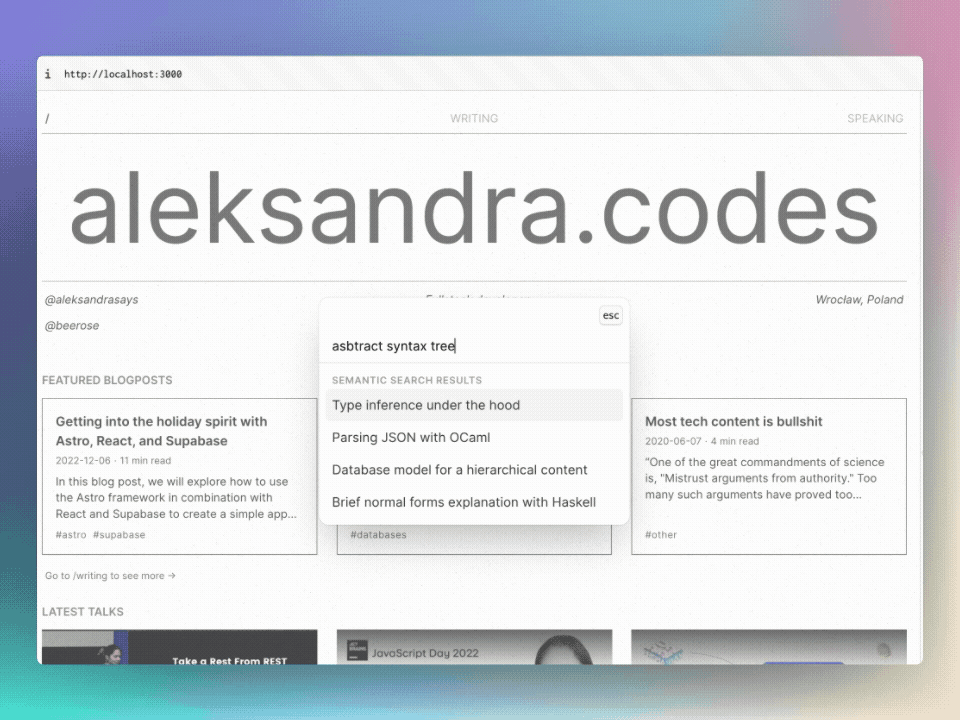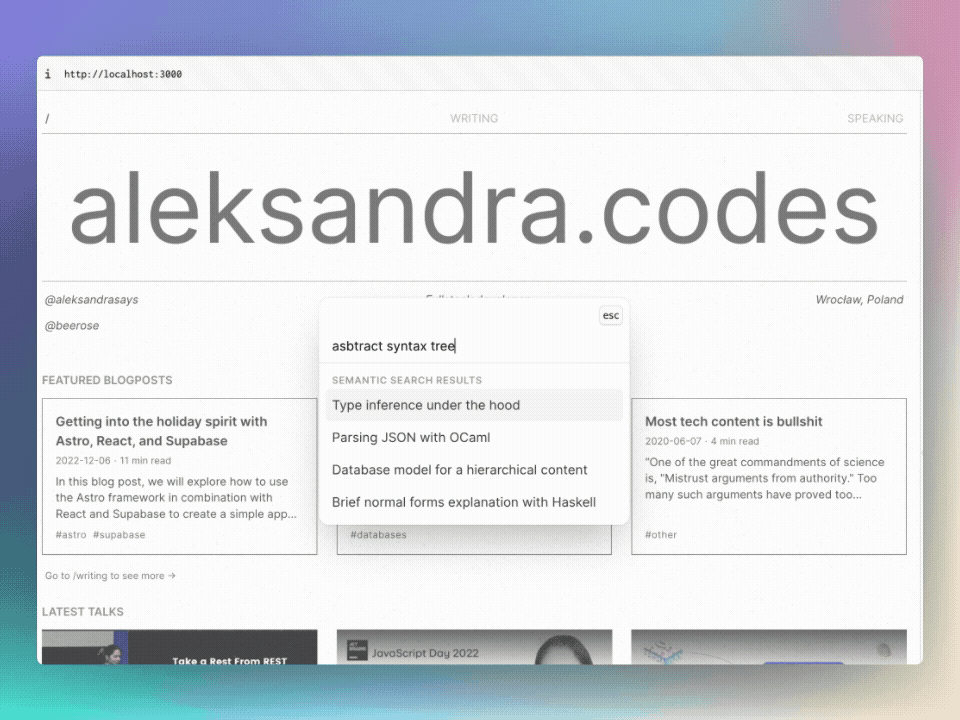
.
├── bin
│ └── cli.js
├── src
│ ├── bin
│ │ └── cli.ts
│ ├── commands
│ │ ├── indexFiles.ts
│ │ └── search.ts
│ ├── getEmbeddings.ts
│ ├── isRateLimitExceeded.ts
│ ├── mdxToPlainText.test.ts
│ ├── mdxToPlainText.ts
│ ├── semanticQuery.ts
│ ├── splitIntoChunks.test.ts
│ ├── splitIntoChunks.ts
│ ├── titleCase.ts
│ └── types.ts
├── tsconfig.build.json
├── tsconfig.json
├── package.json
└── pnpm-lock.yamlbin/cli.js - CLIエントリポイント。src :bin/cli.ts - CLIコマンドと設定を見つけることができるファイル。このプロジェクトでは、CACを使用してCLIを構築します。commands/indexFiles.ts - MD/MDXコンテンツの処理を処理し、埋め込みを生成し、ベクターを松ぼっくりにアップロードするCLIコマンド。command/search.ts - セマンティック検索コマンド。特定の検索クエリの埋め込みを生成し、結果のPineconeを呼び出します。getEmbeddings.ts - 埋め込みロジックの生成。 AIを開くための呼び出しを処理します。isRateLimitExceeded.ts - エラー処理ヘルパー。mdxToPlainText.ts - MDXファイルをRAWテキストに変換します。備考とカスタムremarkMdxToPlainTextプラグインを使用します(そのファイルでも定義されています)。semanticQuery.ts - セマンティック検索を実行するためのコアロジック。 searchコマンドで使用されており、このライブラリからエクスポートされているため、プロジェクトと統合できます。splitIntoChunks.ts - 最大100トークンでテキストをチャンクに分割します。titleCase.ts - ファイルパスからタイトルを抽出します。types.ts - このプロジェクトで使用されるタイプとユーティリティ。tsconfig.jsonタイプスクリプトコンパイラ構成。tsconfig.build.json pnpm buildに使用されるタイプスクリプトコンパイラ構成。テスト:
src/mdxToPlainText.test.tssrc/splitIntoChunks.test.tsDEPSをインストールしてプロジェクトを構築します。
pnpm i
pnpm buildCLIをローカルに実行します:
node bin/cli.jspnpm test 貢献、問題、機能のリクエストは大歓迎です。
貢献したい場合は、問題のページを自由に確認してください。
Copyright©2023 Aleksandra Sikora。
このプロジェクトはMITライセンスです。


