Baichuan2
1.0.0
껴안는 얼굴 •?

Baixiaoying 앱이 공식적으로 출시되었습니다! AI 조수 검색 및 질문, 주요 신청서에서 Baixiao 검색, 다운로드 및 경험을 환영합니다.
중국어 |. 영어
[ 2023.12.29 ] ?? 안에:
릴리스 버전 및 다운로드 링크는 다음 표에 나와 있습니다.
| 기본 모델 | 모델을 정렬하십시오 | 정렬 모델 4Bits Quantization | |
|---|---|---|---|
| 7b | Baichuan2-7B 기반 | Baichuan2-7B-Chat | Baichuan2-7B-Chat-4bits |
| 13b | Baichuan2-13B-베이스 | Baichuan2-13B-Chat | Baichuan2-13B-Chat-4bits |
우리는 일반, 법률, 의료, 수학, 코드 및 다국어 번역의 6 가지 분야에서 중국어 및 영어 및 다국어 권위있는 데이터 세트에 대한 모델을 광범위하게 테스트했습니다.
일반 도메인에서 우리는 다음 데이터 세트에서 5 샷 테스트를 수행했습니다.
| C-Eval | MMLU | cmmlu | 가오카오 | Agieval | BBH | |
|---|---|---|---|---|---|---|
| 5 샷 | 5 샷 | 5 샷 | 5 샷 | 5 샷 | 3 샷 | |
| GPT-4 | 68.40 | 83.93 | 70.33 | 66.15 | 63.27 | 75.12 |
| GPT-3.5 터보 | 51.10 | 68.54 | 54.06 | 47.07 | 46.13 | 61.59 |
| llama-7b | 27.10 | 35.10 | 26.75 | 27.81 | 28.17 | 32.38 |
| llama2-7b | 28.90 | 45.73 | 31.38 | 25.97 | 26.53 | 39.16 |
| MPT-7B | 27.15 | 27.93 | 26.00 | 26.54 | 24.83 | 35.20 |
| 팔콘 -7b | 24.23 | 26.03 | 25.66 | 24.24 | 24.10 | 28.77 |
| chatglm2-6b | 50.20 | 45.90 | 49.00 | 49.44 | 45.28 | 31.65 |
| Baichuan-7b | 42.80 | 42.30 | 44.02 | 36.34 | 34.44 | 32.48 |
| Baichuan2-7B-베이스 | 54.00 | 54.16 | 57.07 | 47.47 | 42.73 | 41.56 |
| C-Eval | MMLU | cmmlu | 가오카오 | Agieval | BBH | |
|---|---|---|---|---|---|---|
| 5 샷 | 5 샷 | 5 샷 | 5 샷 | 5 샷 | 3 샷 | |
| GPT-4 | 68.40 | 83.93 | 70.33 | 66.15 | 63.27 | 75.12 |
| GPT-3.5 터보 | 51.10 | 68.54 | 54.06 | 47.07 | 46.13 | 61.59 |
| llama-13b | 28.50 | 46.30 | 31.15 | 28.23 | 28.22 | 37.89 |
| llama2-13b | 35.80 | 55.09 | 37.99 | 30.83 | 32.29 | 46.98 |
| Vicuna-13b | 32.80 | 52.00 | 36.28 | 30.11 | 31.55 | 43.04 |
| 중국-알파카 -Plus-13B | 38.80 | 43.90 | 33.43 | 34.78 | 35.46 | 28.94 |
| xverse-13b | 53.70 | 55.21 | 58.44 | 44.69 | 42.54 | 38.06 |
| BAICHUAN-13B-베이스 | 52.40 | 51.60 | 55.30 | 49.69 | 43.20 | 43.01 |
| Baichuan2-13B-베이스 | 58.10 | 59.17 | 61.97 | 54.33 | 48.17 | 48.78 |
법률 분야에서 우리는 JEC-QA 데이터 세트를 사용했습니다. JEC-QA 데이터 세트는 중국 국가 사법 시험에서 파생됩니다. 우리는 단일 선택 질문 만 유지했습니다. 우리는 C-Eval과 유사한 평가 체계를 채택했습니다.
의료 분야는 일반 도메인 데이터 세트 (C-Eval, MMLU, CMMLU)에서 의료 관련 분야, MEDQA 및 MEDMCQA를 사용합니다. 우리는 C-Eval과 유사한 평가 체계를 채택했습니다.
위의 데이터 세트에서 5 샷 테스트를 수행했습니다.
| JEC-QA | ceval-mmlu-cmmlu | Medqa-usmle | medqa-mcmle | medmcqa | |
|---|---|---|---|---|---|
| 5 샷 | 5 샷 | 5 샷 | 5 샷 | 5 샷 | |
| GPT-4 | 59.32 | 77.16 | 80.28 | 74.58 | 72.51 |
| GPT-3.5 터보 | 42.31 | 61.17 | 53.81 | 52.92 | 56.25 |
| llama-7b | 27.45 | 33.34 | 24.12 | 21.72 | 27.45 |
| llama2-7b | 29.20 | 36.75 | 27.49 | 24.78 | 37.93 |
| MPT-7B | 27.45 | 26.67 | 16.97 | 19.79 | 31.96 |
| 팔콘 -7b | 23.66 | 25.33 | 21.29 | 18.07 | 33.88 |
| chatglm2-6b | 40.76 | 44.54 | 26.24 | 45.53 | 30.22 |
| Baichuan-7b | 34.64 | 42.37 | 27.42 | 39.46 | 31.39 |
| Baichuan2-7B-베이스 | 44.46 | 56.39 | 32.68 | 54.93 | 41.73 |
| JEC-QA | ceval-mmlu-cmmlu | Medqa-usmle | medqa-mcmle | medmcqa | |
|---|---|---|---|---|---|
| 5 샷 | 5 샷 | 5 샷 | 5 샷 | 5 샷 | |
| GPT-4 | 59.32 | 77.16 | 80.28 | 74.58 | 72.51 |
| GPT-3.5 터보 | 42.31 | 61.17 | 53.81 | 52.92 | 56.25 |
| llama-13b | 27.54 | 35.14 | 28.83 | 23.38 | 39.52 |
| llama2-13b | 34.08 | 47.42 | 35.04 | 29.74 | 42.12 |
| Vicuna-13b | 28.38 | 40.99 | 34.80 | 27.67 | 40.66 |
| 중국-알파카 -Plus-13B | 35.32 | 46.31 | 27.49 | 32.66 | 35.87 |
| xverse-13b | 46.42 | 58.08 | 32.99 | 58.76 | 41.34 |
| BAICHUAN-13B-베이스 | 41.34 | 51.77 | 29.07 | 43.67 | 39.60 |
| Baichuan2-13B-베이스 | 47.40 | 59.33 | 40.38 | 61.62 | 42.86 |
수학 분야에서는 OpenCompass 평가 프레임 워크를 사용하여 GSM8K 및 Math DataSets 4-샷을 테스트했습니다.
코드 필드는 Humaneval 및 MBPP 데이터 세트를 사용합니다. OpenCompass를 사용하여 HumaneVal 0-Shot 및 MBPP 데이터 세트 3-샷을 테스트했습니다.
| GSM8K | 수학 | Humaneval | MBPP | |
|---|---|---|---|---|
| 4 샷 | 4 샷 | 0 샷 | 3 샷 | |
| GPT-4 | 89.99 | 40.20 | 69.51 | 63.60 |
| GPT-3.5 터보 | 57.77 | 13.96 | 52.44 | 61.40 |
| llama-7b | 9.78 | 3.02 | 11.59 | 14.00 |
| llama2-7b | 16.22 | 3.24 | 12.80 | 14.80 |
| MPT-7B | 8.64 | 2.90 | 14.02 | 23.40 |
| 팔콘 -7b | 5.46 | 1.68 | - | 10.20 |
| chatglm2-6b | 28.89 | 6.40 | 9.15 | 9.00 |
| Baichuan-7b | 9.17 | 2.54 | 9.20 | 6.60 |
| Baichuan2-7B-베이스 | 24.49 | 5.58 | 18.29 | 24.20 |
| GSM8K | 수학 | Humaneval | MBPP | |
|---|---|---|---|---|
| 4 샷 | 4 샷 | 0 샷 | 3 샷 | |
| GPT-4 | 89.99 | 40.20 | 69.51 | 63.60 |
| GPT-3.5 터보 | 57.77 | 13.96 | 52.44 | 61.40 |
| llama-13b | 20.55 | 3.68 | 15.24 | 21.40 |
| llama2-13b | 28.89 | 4.96 | 15.24 | 27.00 |
| Vicuna-13b | 28.13 | 4.36 | 16.46 | 15.00 |
| 중국-알파카 -Plus-13B | 11.98 | 2.50 | 16.46 | 20.00 |
| xverse-13b | 18.20 | 2.18 | 15.85 | 16.80 |
| BAICHUAN-13B-베이스 | 26.76 | 4.84 | 11.59 | 22.80 |
| Baichuan2-13B-베이스 | 52.77 | 10.08 | 17.07 | 30.20 |
Flores-101 데이터 세트를 사용하여 모델의 다국어 기능을 평가했습니다. Flores-101은 전 세계 101 개 언어를 포함합니다. 데이터는 뉴스, 여행 가이드 및 서적과 같은 다양한 분야에서 나옵니다. 우리는 독일어와 일본어뿐만 아니라 공식 유엔 언어 (아랍어, 중국어, 영어, 프랑스어, 러시아어 및 스페인어)를 시험 언어로 선택했습니다. 우리는 OpenCompass를 사용하여 Flores-101의 7 개의 하위 작업에서 중국-영어, 중국-프랑스, 중국-스페인, 중국-아랍, 중국-러시아, 중국-일본 및 중국-독일을 포함하여 8 샷 테스트를 수행했습니다.
| CN-EN | CN-FR | CN-ES | CN-AR | CN-RU | CN-JP | CN-DE | 평균 | |
|---|---|---|---|---|---|---|---|---|
| GPT-4 | 29.94 | 29.56 | 20.01 | 10.76 | 18.62 | 13.26 | 20.83 | 20.43 |
| GPT-3.5 터보 | 27.67 | 26.15 | 19.58 | 10.73 | 17.45 | 1.82 | 19.70 | 17.59 |
| llama-7b | 17.27 | 12.02 | 9.54 | 0.00 | 4.47 | 1.41 | 8.73 | 7.63 |
| llama2-7b | 25.76 | 15.14 | 11.92 | 0.79 | 4.99 | 2.20 | 10.15 | 10.14 |
| MPT-7B | 20.77 | 9.53 | 8.96 | 0.10 | 3.54 | 2.91 | 6.54 | 7.48 |
| 팔콘 -7b | 22.13 | 15.67 | 9.28 | 0.11 | 1.35 | 0.41 | 6.41 | 7.91 |
| chatglm2-6b | 22.28 | 9.42 | 7.77 | 0.64 | 1.78 | 0.26 | 4.61 | 6.68 |
| Baichuan-7b | 25.07 | 16.51 | 12.72 | 0.41 | 6.66 | 2.24 | 9.86 | 10.50 |
| Baichuan2-7B-베이스 | 27.27 | 20.87 | 16.17 | 1.39 | 11.21 | 3.11 | 12.76 | 13.25 |
| CN-EN | CN-FR | CN-ES | CN-AR | CN-RU | CN-JP | CN-DE | 평균 | |
|---|---|---|---|---|---|---|---|---|
| GPT-4 | 29.94 | 29.56 | 20.01 | 10.76 | 18.62 | 13.26 | 20.83 | 20.43 |
| GPT-3.5 터보 | 27.67 | 26.15 | 19.58 | 10.73 | 17.45 | 1.82 | 19.70 | 17.59 |
| llama-13b | 21.75 | 16.16 | 13.29 | 0.58 | 7.61 | 0.41 | 10.66 | 10.07 |
| llama2-13b | 25.44 | 19.25 | 17.49 | 1.38 | 10.34 | 0.13 | 11.13 | 12.17 |
| Vicuna-13b | 22.63 | 18.04 | 14.67 | 0.70 | 9.27 | 3.59 | 10.25 | 11.31 |
| 중국-알파카 -Plus-13B | 22.53 | 13.82 | 11.29 | 0.28 | 1.52 | 0.31 | 8.13 | 8.27 |
| xverse-13b | 29.26 | 24.03 | 16.67 | 2.78 | 11.61 | 3.08 | 14.26 | 14.53 |
| BAICHUAN-13B-베이스 | 30.24 | 20.90 | 15.92 | 0.98 | 9.65 | 2.64 | 12.00 | 13.19 |
| Baichuan2-13B-베이스 | 30.61 | 22.11 | 17.27 | 2.39 | 14.17 | 11.58 | 14.53 | 16.09 |
추론에 필요한 모델 가중치, 소스 코드 및 구성은 Hugging Face에 게시되었습니다. 우리는 여기서 다양한 추론 방법을 보여줍니다. 이 프로그램은 포옹 얼굴에서 필요한 자원을 자동으로 다운로드합니다.
pip install -r requirements.txt >> > import torch
>> > from transformers import AutoModelForCausalLM , AutoTokenizer
>> > from transformers . generation . utils import GenerationConfig
>> > tokenizer = AutoTokenizer . from_pretrained ( "baichuan-inc/Baichuan2-13B-Chat" , use_fast = False , trust_remote_code = True )
>> > model = AutoModelForCausalLM . from_pretrained ( "baichuan-inc/Baichuan2-13B-Chat" , device_map = "auto" , torch_dtype = torch . bfloat16 , trust_remote_code = True )
>> > model . generation_config = GenerationConfig . from_pretrained ( "baichuan-inc/Baichuan2-13B-Chat" )
>> > messages = []
>> > messages . append ({ "role" : "user" , "content" : "解释一下“温故而知新”" })
>> > response = model . chat ( tokenizer , messages )
>> > print ( response )
"温故而知新"是一句中国古代的成语,出自《论语·为政》篇。这句话的意思是:通过回顾过去,我们可以发现新的知识和理解。换句话说,学习历史和经验可以让我们更好地理解现在和未来。
这句话鼓励我们在学习和生活中不断地回顾和反思过去的经验,从而获得新的启示和成长。通过重温旧的知识和经历,我们可以发现新的观点和理解,从而更好地应对不断变化的世界和挑战。 >> > from transformers import AutoModelForCausalLM , AutoTokenizer
>> > tokenizer = AutoTokenizer . from_pretrained ( "baichuan-inc/Baichuan2-13B-Base" , trust_remote_code = True )
>> > model = AutoModelForCausalLM . from_pretrained ( "baichuan-inc/Baichuan2-13B-Base" , device_map = "auto" , trust_remote_code = True )
>> > inputs = tokenizer ( '登鹳雀楼->王之涣n夜雨寄北->' , return_tensors = 'pt' )
>> > inputs = inputs . to ( 'cuda:0' )
>> > pred = model . generate ( ** inputs , max_new_tokens = 64 , repetition_penalty = 1.1 )
>> > print ( tokenizer . decode ( pred . cpu ()[ 0 ], skip_special_tokens = True ))
登鹳雀楼- >王之涣
夜雨寄北- >李商隐위의 두 코드에서 모델은 지정된
device_map='auto'로드하고 사용 가능한 모든 그래픽 카드가 사용됩니다. 사용할 장치를 지정 해야하는 경우export CUDA_VISIBLE_DEVICES=0,1(그래픽 카드 0과 1이 사용됨)과 같은 메소드를 사용할 수 있습니다.
python cli_demo.py이 명령 줄 도구는 채팅 시나리오 용으로 설계 되었으므로이 도구를 사용하는 기본 모델을 지원하지 않습니다.
다음 명령을 실행하기 위해 Streamlit에 의존하면 웹 서비스가 로컬로 시작되며 콘솔에서 제공 한 주소는 브라우저에 배치되어 액세스 할 수 있습니다. 이 웹 데모 도구는 채팅 시나리오 용으로 설계 되었으므로이 도구를 사용하여 기본 모델을 호출하는 데 도움이되지 않습니다.
streamlit run web_demo.py用户:找到下列数组的中位数[3.1,6.2,1.3,8.4,10.5,11.6,2.1],请用python代码完成以上功能
Baichuan 2:def find_median(numbers):
numbers.sort()
length = len(numbers)
if length % 2 == 0:
return (numbers[length // 2 - 1] + numbers[length // 2]) / 2
else:
return numbers[length // 2]
numbers = [3.1, 6.2, 1.3, 8.4, 10.5, 11.6, 2.1]
print(find_median(numbers))
用户:鸡和兔在一个笼子里,共有26个头,68只脚,那么鸡有多少只,兔有多少只?
Baichuan 2:我们可以用代数方法来解决这个问题。假设鸡的数量为x,兔子的数量为y。根据题目给出的信息,我们可以得到以下两个方程:
1. x + y = 26 (头的总数)
2. 2x + 4y = 68 (脚的总数)
现在我们需要解这个二元一次方程组。首先从第一个方程中解出x:
x = 26 - y
然后将x的表达式代入第二个方程:
2(26 - y) + 4y = 68
52 - 2y + 4y = 68
2y = 16
接下来我们求解y的值:
y = 16 / 2
y = 8
现在我们得到了兔子的数量是8只。将y的值代入x的表达式求得鸡的数量:
x = 26 - 8
x = 18
所以鸡有18只,兔子有8只。
用户:从现在开始,请你将我接下来说的每一句话翻译成英语,准备好了吗?
Baichuan 2:I'm ready to translate every word you say next into English.
用户:你好
Baichuan 2:Hello
用户:我是Baichuan 2,很高兴认识大家
Baichuan 2:I am Baichuan 2, and I am very happy to meet everyone.
用户:希望通过大家的共同努力,早日迎接AGI时代的到来
Baichuan 2:I hope through the joint efforts of all of us, we can welcome the arrival of the AGI era as soon as possible.
用户:以下物理常识题目,哪一个是错误的?A.在自然环境下,声音在固体中传播速度最快。B.牛顿第一定律:一个物体如果不受力作用,将保持静止或匀速直线运动的状态。C.牛顿第三定律:对于每个作用力,都有一个相等而反向的反作用力。D.声音在空气中的传播速度为1000m/s。
Baichuan 2:本题考查物理基本概念和原理的理解和应用能力。
A项:声音的传播需要介质,在固体、液体和气体的三种介质中,声音在固体中的传播速度是最快的,故A正确; B项:牛顿第一定律是惯性定律,其内容是:一个物体如果没有受到外力的作用,要么保持静止状态,要么保持匀速直线运动状态,直到有外力迫使它改变运动状态为止,故B正确; C项:牛顿第三定律的内容是:对于每一个作用力,都有一个大小相等、方向相反的反作用力,这两个力分别作用在两个相互作用的物体上,故C错误; D项:声音在空气中以波的形式传播,其传播速度与介质的温度、湿度等因素有关,一般情况下,声音在空气中的传播速度约为340m/s左右,而不是1000m/s,故D错误。 因此,本题的正确答案是 D 。
用户:I'm Mike 。I am going to have a busy weekend。On Saturday,I am going to learn how to swim。I will go with my father。Then we are going to have lunch in the restaurant。In the afternoon,we are going to the zoo。We are going to see the pandas。On Sunday,I will finish my homework in the morning。In the afternoon,my parents and I are going to visit my grandparents。We will have dinner together。
阅读短文,判断正确和错误!正确请写T,错误请写F:
1.Mike is going to have a busy weekend()
2.Mike is going to learn how to swim with his father()
3.They are going to have lunch at home()
Baichuan 2:1. T(正确的)
2. T(正确的)
3. F(错误的)
다른 사용자와 다른 플랫폼이 Baichuan 2 모델을 실행할 수 있도록하기 위해, 우리는 Baichuan 2 모델 (Baichuan2-7B-Chat 및 Baichuan2-13B-Chat 포함)에 해당하는 정량적 작업을 수행하여 사용자가 자체 플랫폼에서 Bachuan 2 모델을 빠르고 효율적으로 배포 할 수 있도록했습니다.
Baichuan 2는 커뮤니티 주류 정량적 접근법 인 Bitsandbytes를 채택합니다. 이 방법은 양자화 효과가 기본적으로 변압기 카레에 통합되지 않았으며 커뮤니티에서 널리 사용되었습니다. Bitsandbytes는 8bits 및 4bits Quantization을 지원하며, 4bits는 FP4 및 NF4 형식을 지원합니다.
이 양자화 방법에 따라 Baichuan 2는 온라인 양자화와 오프라인 양자화의 두 가지 모드를 지원합니다.
온라인 양자화의 경우, 우리는 8BITS 및 quantize() 양자화를 지원합니다. 사용법은 Baichuan cuda() 13B 프로젝트와 유사합니다. 전체 모델로드를 구현하는 코드는 매우 간단합니다.
8BITS 온라인 정량화 :
model = AutoModelForCausalLM . from_pretrained ( "baichuan-inc/Baichuan2-7B-Chat" , torch_dtype = torch . float16 , trust_remote_code = True )
model = model . quantize ( 8 ). cuda () 4BITS 온라인 양자화 :
model = AutoModelForCausalLM . from_pretrained ( "baichuan-inc/Baichuan2-7B-Chat" , torch_dtype = torch . float16 , trust_remote_code = True )
model = model . quantize ( 4 ). cuda () from_pretrained 인터페이스를 사용하면 일반적으로 device_map="auto" 를 추가하면이 매개 변수를 제거해야합니다. 그렇지 않으면 오류 가보고됩니다.
사용자의 사용을 용이하게하기 위해 오프라인 양자화 된 버전 Baichuan2-7B-Chat-4bits를 제공하여 사용자가 다운로드 할 수 있습니다. 사용자가 Baichuan2-7B-Chat-4bits 모델을로드하는 것은 매우 간단합니다.
model = AutoModelForCausalLM . from_pretrained ( "baichuan-inc/Baichuan2-7B-Chat-4bits" , device_map = "auto" , trust_remote_code = True )8BITS 오프라인 양자화의 경우 Hugging Face Transformers 라이브러리가 해당 API 인터페이스를 제공하여 8BITS 정량적 모델의 저장 및 로딩을 쉽게 구현할 수 있기 때문에 해당 버전을 제공하지 않습니다. 사용자는 다음과 같은 방법으로 8bits 모델 저장 및로드를 실현할 수 있습니다.
# Model saving: model_id is the original model directory, and quant8_saved_dir is the directory where the 8bits quantized model is saved.
model = AutoModelForCausalLM . from_pretrained ( model_id , load_in_8bit = True , device_map = "auto" , trust_remote_code = True )
model . save_pretrained ( quant8_saved_dir )
model = AutoModelForCausalLM . from_pretrained ( quant8_saved_dir , device_map = "auto" , trust_remote_code = True )양자화 전후 비디오 메모리 사용 비교 (GB의 GPU MEM) :
| 정도 | Baichuan2-7b | Baichuan2-13b |
|---|---|---|
| BF16 / FP16 | 15.3 | 27.5 |
| 8bits | 8.0 | 16.1 |
| 4BITS | 5.1 | 8.6 |
양자화 후 각 벤치 마크의 결과 및 원본 버전은 다음과 같습니다.
| 모델 5 샷 | C-Eval | MMLU | cmmlu |
|---|---|---|---|
| Baichuan2-13B-Chat | 56.74 | 57.32 | 59.68 |
| Baichuan2-13B-Chat-4bits | 56.05 | 56.24 | 58.82 |
| Baichuan2-7B-Chat | 54.35 | 52.93 | 54.99 |
| Baichuan2-7B-Chat-4bits | 53.04 | 51.72 | 52.84 |
C-Eval은 VAL 세트에서 수행 된 평가입니다
보시다시피, BFLOAT16에 비해 4BIT의 정확도 손실은 약 1-2 % 포인트입니다.
Baichuan 2 모델은 CPU 추론을 지원하지만 CPU 추론 속도는 비교적 느리다는 점을 강조해야합니다. 모델 로딩 방법은 다음과 같이 수정해야합니다.
# Taking Baichuan2-7B-Chat as an example
model = AutoModelForCausalLM . from_pretrained ( "baichuan-inc/Baichuan2-7B-Chat" , torch_dtype = torch . float32 , trust_remote_code = True ) 많은 사용자가 Baichuan 1 (Baichuan-7B, Baichuan-13B)에 대해 많은 최적화 작업을 수행하여 컴파일 최적화, 양자화 등을 제로 비용으로 Baichuan 2에 적용하기 위해 Baichuan 2 모델의 오프라인 변환을 수행 할 수 있으며, Baichuan 1 모델로 사용할 수 있습니다. 구체적으로, 사용자는 다음 스크립트 만 사용하여 Baichuan 2 모델 오프라인에서 LM_HEAD의 마지막 레이어를 정규화하고 lm_head.weight 교체하면됩니다. 교체 후 Baichuan 1 모델과 같이 변환 된 모델을 컴파일하고 최적화 할 수 있습니다.
import torch
import os
ori_model_dir = 'your Baichuan 2 model directory'
# To avoid overwriting the original model, it's best to save the converted model to another directory before replacing it
new_model_dir = 'your normalized lm_head weight Baichuan 2 model directory'
model = torch . load ( os . path . join ( ori_model_dir , 'pytorch_model.bin' ))
lm_head_w = model [ 'lm_head.weight' ]
lm_head_w = torch . nn . functional . normalize ( lm_head_w )
model [ 'lm_head.weight' ] = lm_head_w
torch . save ( model , os . path . join ( new_model_dir , 'pytorch_model.bin' ))git clone https://github.com/baichuan-inc/Baichuan2.git
cd Baichuan2/fine-tune
pip install -r requirements.txt아래에서 우리는 미세 조정 Baichuan2-7B- 기반을위한 독립형 교육 예제를 제공합니다.
교육 데이터 : data/belle_chat_ramdon_10k.json , 샘플 데이터는 Multiturn_chat_0.8m에서 샘플링되며 형식 변환이 수행됩니다. 주로 여러 라운드의 데이터를 훈련시키는 방법을 보여 주며 그 효과를 보장하지 않습니다.
hostfile= " "
deepspeed --hostfile= $hostfile fine-tune.py
--report_to " none "
--data_path " data/belle_chat_ramdon_10k.json "
--model_name_or_path " baichuan-inc/Baichuan2-7B-Base "
--output_dir " output "
--model_max_length 512
--num_train_epochs 4
--per_device_train_batch_size 16
--gradient_accumulation_steps 1
--save_strategy epoch
--learning_rate 2e-5
--lr_scheduler_type constant
--adam_beta1 0.9
--adam_beta2 0.98
--adam_epsilon 1e-8
--max_grad_norm 1.0
--weight_decay 1e-4
--warmup_ratio 0.0
--logging_steps 1
--gradient_checkpointing True
--deepspeed ds_config.json
--bf16 True
--tf32 True멀티 머신 교육의 경우 호스트 파일 만 제공하면 컨텐츠가 다음과 유사합니다.
ip1 slots=8
ip2 slots=8
ip3 slots=8
ip4 slots=8
....
동시에 훈련 스크립트에서 HOSFTFILE의 경로를 지정하십시오.
hostfile= " /path/to/hostfile "
deepspeed --hostfile= $hostfile fine-tune.py
--report_to " none "
--data_path " data/belle_chat_ramdon_10k.json "
--model_name_or_path " baichuan-inc/Baichuan2-7B-Base "
--output_dir " output "
--model_max_length 512
--num_train_epochs 4
--per_device_train_batch_size 16
--gradient_accumulation_steps 1
--save_strategy epoch
--learning_rate 2e-5
--lr_scheduler_type constant
--adam_beta1 0.9
--adam_beta2 0.98
--adam_epsilon 1e-8
--max_grad_norm 1.0
--weight_decay 1e-4
--warmup_ratio 0.0
--logging_steps 1
--gradient_checkpointing True
--deepspeed ds_config.json
--bf16 True
--tf32 True코드는 이미 LORA와 같은 경량 미세 조정을 지원합니다.
--use_lora True LORA의 특정 구성은 fine-tune.py 스크립트에서 찾을 수 있습니다.
LORA를 미세 조정 한 후 다음 명령을 사용하여 모델을로드 할 수 있습니다.
from peft import AutoPeftModelForCausalLM
model = AutoPeftModelForCausalLM . from_pretrained ( "output" , trust_remote_code = True )2.6 조 토큰으로 Baichuan2-7B-Base 모델을 훈련시키는 것 외에도 커뮤니티 연구 (다운로드 주소)를 위해 또 다른 11 개의 중간 체크 포인트 (각각 약 0.2 ~ 2.4 조 토큰)를 제공합니다. 다음 그림은 C-Eval, MMLU 및 CMMLU의 세 가지 벤치 마크에서 이러한 체크 포인트의 영향을 보여줍니다.
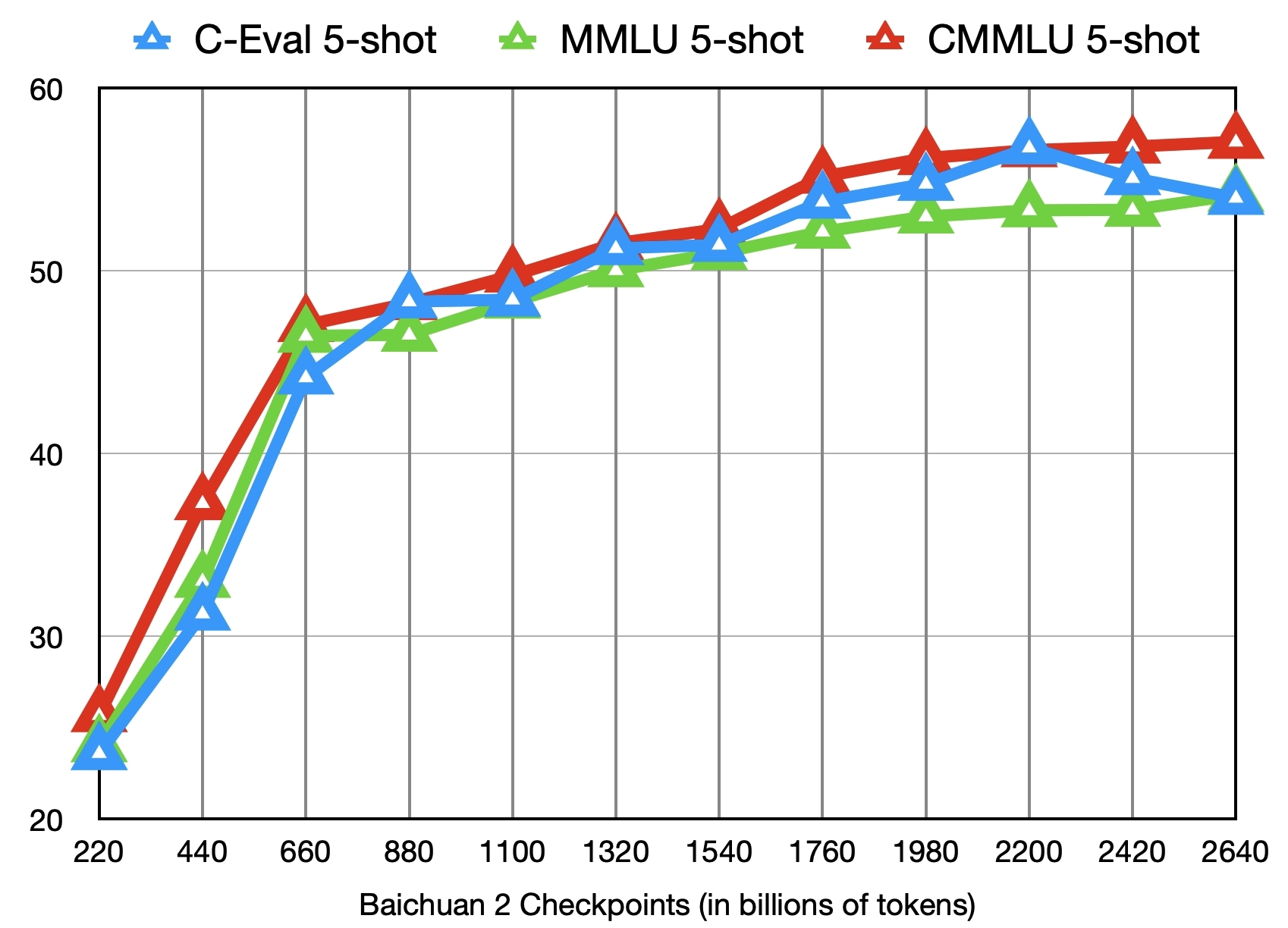
우리는 Baichuan 2에 대한 커뮤니티와 생태계 지원을 계속 업데이트 할 것입니까 ???
Core ™/Xiang® 확장 가능한 프로세서 또는 Ruixuan ™ GPU를 사용하여 Baichuan2-7b/Chat, Baichuan2-13B/채팅 모델을 배포하십시오.
더 나은 추론 성능을 달성하기 위해 BigDL-LLM (CPU, GPU)이 권장됩니다.
노트북 지원을 포함한 중국 운영 매뉴얼
로딩, 최적화, 저장 방법 등
모델 미세 조정 : Baichuan 2 (7b)는 기본적으로 Pytorch (2.1.0) + 변압기 (4.36.0) + DeepSpeed (0.12.4) + 가속 (0.25.0) 모델 미세 조정을 지원했습니다.
추론 배치 : Baichuan 2 (7b)는 기본적으로 Ascend NPU 추론을 지원했으며 추가 적응없이 사용할 수 있습니다.
Mindformers는 Mindspore 프레임 워크를 기반으로하는 풀 프로세스 개발 키트이며 대규모 모델 교육, 미세 조정, 평가, 추론 및 배포를 지원합니다.
Shengsi Big Model Platform은 Shengsi Mindspore AI 프레임 워크, Mindformers Big Model Development Kit 및 Ascend 하드웨어 컴퓨팅 파워를 기반으로하며 Baichuan2-7B 대형 모델 기능을 대중에게 개방하며 모든 사람이 온라인 경험을 환영합니다.
Llama- 효율적인 조정은 Baichuan 2 모델의 미세 조정 및 지속적인 훈련을 지원했습니다.
Baichuan2 (7b/13b)는 Taichu T100 가속 카드 추론을 지원하며 시험 채널은 공식적으로 일반인에게 개방되었습니다.
이에 따라 개발 팀은 iOS, Android, 웹 페이지 또는 기타 플랫폼에서 Baichuan 2 모델을 기반으로 한 앱을 개발하지 않았다고 선언합니다. 우리는 모든 사용자에게 Baichuan 2 모델을 사용하여 국가 사회 보장 또는 불법을 위험에 빠뜨리는 활동을 수행하지 말라고 강력히 요구합니다. 또한 사용자는 보안 검토 및 등록되지 않은 인터넷 서비스에 Baichuan 2 모델을 사용하지 말 것을 요청받습니다. 우리는 모든 사용자 가이 원칙을 준수하고 표준화 된 법적 환경에서 과학 및 기술 개발을 수행 할 수 있기를 바랍니다.
우리는 모델 교육 중에 사용되는 데이터를 준수하기 위해 최선을 다했습니다. 그러나 우리의 큰 노력에도 불구하고 모델과 데이터의 복잡성으로 인해 여전히 예상치 못한 문제가 있습니다. 따라서, 우리는 데이터 보안 문제, 여론 위험 또는 오해의 소지, 남용, 보급 또는 부적절한 사용으로 인한 위험 및 문제를 포함하여 Baichuan 2 오픈 소스 모델 사용으로 인해 발생하는 문제에 대해 어떠한 책임도 없을 것입니다.
커뮤니티는 Baichuan 2 모델을 사용하여 Apache 2.0 및 Baichuan 2 Model Community License Agreement를 따릅니다. Baichuan 2 모델은 상업적으로 유용합니다. Baichuan 2 모델 또는 상업적 목적으로 파생 상품을 사용하려면 주제가 다음 조건을 충족하는지 확인하십시오.
위의 조건이 충족되면 다음 이메일 주소 [email protected]을 통해 Baichuan 2 Model Community License 계약이 요구하는 신청 자료를 제출해야합니다. 검토가 승인 된 후, Baichuan은 귀하에게 비 독점적이며 전 세계적으로 전환 할 수없고 공개 할 수없고 취소 가능한 상업용 저작권 라이센스를 부여합니다.
우리의 작업을 인용하려면 다음 참조를 사용하십시오.
@article{baichuan2023baichuan2,
title={Baichuan 2: Open Large-scale Language Models},
author={Baichuan},
journal={arXiv preprint arXiv:2309.10305},
url={https://arxiv.org/abs/2309.10305},
year={2023}
}


