Baichuan2
1.0.0
?

Aplikasi Baixiaoying telah diluncurkan secara resmi! AI Assistants yang tahu cara mencari dan mengajukan pertanyaan, mencari Baixiao di toko aplikasi utama, dipersilakan untuk mengunduh dan mengalaminya?
Bahasa Inggris |
[ 2023.12.29 ] ??? di dalam:
Versi rilis dan tautan unduhan ditampilkan di tabel berikut:
| Model dasar | Sejajarkan model | Model perataan 4bits kuantisasi | |
|---|---|---|---|
| 7b | ? | ? | ? |
| 13b | ? | ? | ? |
Kami secara luas menguji model pada dataset otoritatif Cina dan Inggris dan multibahasa dalam enam bidang: Umum, Hukum, Medis, Matematika, Kode dan Terjemahan Multilingual.
Dalam domain umum kami melakukan tes 5-shot pada dataset berikut.
| C-eval | Mmlu | Cmmlu | Gaokao | Ageval | BBH | |
|---|---|---|---|---|---|---|
| 5-shot | 5-shot | 5-shot | 5-shot | 5-shot | 3-shot | |
| GPT-4 | 68.40 | 83.93 | 70.33 | 66.15 | 63.27 | 75.12 |
| GPT-3.5 Turbo | 51.10 | 68.54 | 54.06 | 47.07 | 46.13 | 61.59 |
| Llama-7b | 27.10 | 35.10 | 26.75 | 27.81 | 28.17 | 32.38 |
| Llama2-7b | 28.90 | 45.73 | 31.38 | 25.97 | 26.53 | 39.16 |
| MPT-7B | 27.15 | 27.93 | 26.00 | 26.54 | 24.83 | 35.20 |
| Falcon-7b | 24.23 | 26.03 | 25.66 | 24.24 | 24.10 | 28.77 |
| Chatglm2-6b | 50.20 | 45.90 | 49.00 | 49.44 | 45.28 | 31.65 |
| Baichuan-7b | 42.80 | 42.30 | 44.02 | 36.34 | 34.44 | 32.48 |
| BAICHUAN2-7B-BASE | 54.00 | 54.16 | 57.07 | 47.47 | 42.73 | 41.56 |
| C-eval | Mmlu | Cmmlu | Gaokao | Ageval | BBH | |
|---|---|---|---|---|---|---|
| 5-shot | 5-shot | 5-shot | 5-shot | 5-shot | 3-shot | |
| GPT-4 | 68.40 | 83.93 | 70.33 | 66.15 | 63.27 | 75.12 |
| GPT-3.5 Turbo | 51.10 | 68.54 | 54.06 | 47.07 | 46.13 | 61.59 |
| Llama-13b | 28.50 | 46.30 | 31.15 | 28.23 | 28.22 | 37.89 |
| Llama2-13b | 35.80 | 55.09 | 37.99 | 30.83 | 32.29 | 46.98 |
| Vicuna-13b | 32.80 | 52.00 | 36.28 | 30.11 | 31.55 | 43.04 |
| China-Alpaca-plus-13b | 38.80 | 43.90 | 33.43 | 34.78 | 35.46 | 28.94 |
| Xverse-13b | 53.70 | 55.21 | 58.44 | 44.69 | 42.54 | 38.06 |
| BAICHUAN-13B-BASE | 52.40 | 51.60 | 55.30 | 49.69 | 43.20 | 43.01 |
| BAICHUAN2-13B-BASE | 58.10 | 59.17 | 61.97 | 54.33 | 48.17 | 48.78 |
Di bidang hukum kami menggunakan dataset JEC-QA. Dataset JEC-QA berasal dari Pemeriksaan Yudisial Nasional China. Kami hanya mempertahankan pertanyaan pilihan tunggal. Kami mengadopsi skema evaluasi yang sama sebagai C-eval.
Lapangan medis menggunakan disiplin ilmu terkait medis, MEDQA dan MEDMCQA dalam dataset domain umum (C-Eval, MMLU, CMMLU). Kami mengadopsi skema evaluasi yang sama sebagai C-eval.
Kami melakukan tes 5-shot pada dataset di atas.
| JEC-QA | Ceval-mmlu-cmmlu | Medqa-usmle | Medqa-mcmle | Medmcqa | |
|---|---|---|---|---|---|
| 5-shot | 5-shot | 5-shot | 5-shot | 5-shot | |
| GPT-4 | 59.32 | 77.16 | 80.28 | 74.58 | 72.51 |
| GPT-3.5 Turbo | 42.31 | 61.17 | 53.81 | 52.92 | 56.25 |
| Llama-7b | 27.45 | 33.34 | 24.12 | 21.72 | 27.45 |
| Llama2-7b | 29.20 | 36.75 | 27.49 | 24.78 | 37.93 |
| MPT-7B | 27.45 | 26.67 | 16.97 | 19.79 | 31.96 |
| Falcon-7b | 23.66 | 25.33 | 21.29 | 18.07 | 33.88 |
| Chatglm2-6b | 40.76 | 44.54 | 26.24 | 45.53 | 30.22 |
| Baichuan-7b | 34.64 | 42.37 | 27.42 | 39.46 | 31.39 |
| BAICHUAN2-7B-BASE | 44.46 | 56.39 | 32.68 | 54.93 | 41.73 |
| JEC-QA | Ceval-mmlu-cmmlu | Medqa-usmle | Medqa-mcmle | Medmcqa | |
|---|---|---|---|---|---|
| 5-shot | 5-shot | 5-shot | 5-shot | 5-shot | |
| GPT-4 | 59.32 | 77.16 | 80.28 | 74.58 | 72.51 |
| GPT-3.5 Turbo | 42.31 | 61.17 | 53.81 | 52.92 | 56.25 |
| Llama-13b | 27.54 | 35.14 | 28.83 | 23.38 | 39.52 |
| Llama2-13b | 34.08 | 47.42 | 35.04 | 29.74 | 42.12 |
| Vicuna-13b | 28.38 | 40.99 | 34.80 | 27.67 | 40.66 |
| China-Alpaca-plus-13b | 35.32 | 46.31 | 27.49 | 32.66 | 35.87 |
| Xverse-13b | 46.42 | 58.08 | 32.99 | 58.76 | 41.34 |
| BAICHUAN-13B-BASE | 41.34 | 51.77 | 29.07 | 43.67 | 39.60 |
| BAICHUAN2-13B-BASE | 47.40 | 59.33 | 40.38 | 61.62 | 42.86 |
Di bidang matematika, kami menggunakan kerangka evaluasi opencompass untuk menguji GSM8K dan kumpulan data matematika 4-shot.
Bidang kode menggunakan dataset Humaneval dan MBPP. Kami menggunakan OpenCompass untuk menguji Humaneval 0-Shot dan MBPP Dataset 3-shot.
| GSM8K | Matematika | Humaneval | Mbpp | |
|---|---|---|---|---|
| 4-shot | 4-shot | 0-shot | 3-shot | |
| GPT-4 | 89.99 | 40.20 | 69.51 | 63.60 |
| GPT-3.5 Turbo | 57.77 | 13.96 | 52.44 | 61.40 |
| Llama-7b | 9.78 | 3.02 | 11.59 | 14.00 |
| Llama2-7b | 16.22 | 3.24 | 12.80 | 14.80 |
| MPT-7B | 8.64 | 2.90 | 14.02 | 23.40 |
| Falcon-7b | 5.46 | 1.68 | - | 10.20 |
| Chatglm2-6b | 28.89 | 6.40 | 9.15 | 9.00 |
| Baichuan-7b | 9.17 | 2.54 | 9.20 | 6.60 |
| BAICHUAN2-7B-BASE | 24.49 | 5.58 | 18.29 | 24.20 |
| GSM8K | Matematika | Humaneval | Mbpp | |
|---|---|---|---|---|
| 4-shot | 4-shot | 0-shot | 3-shot | |
| GPT-4 | 89.99 | 40.20 | 69.51 | 63.60 |
| GPT-3.5 Turbo | 57.77 | 13.96 | 52.44 | 61.40 |
| Llama-13b | 20.55 | 3.68 | 15.24 | 21.40 |
| Llama2-13b | 28.89 | 4.96 | 15.24 | 27.00 |
| Vicuna-13b | 28.13 | 4.36 | 16.46 | 15.00 |
| China-Alpaca-plus-13b | 11.98 | 2.50 | 16.46 | 20.00 |
| Xverse-13b | 18.20 | 2.18 | 15.85 | 16.80 |
| BAICHUAN-13B-BASE | 26.76 | 4.84 | 11.59 | 22.80 |
| BAICHUAN2-13B-BASE | 52.77 | 10.08 | 17.07 | 30.20 |
Kami menggunakan dataset Flores-101 untuk mengevaluasi kemampuan multibahasa model. Flores-101 mencakup 101 bahasa di seluruh dunia. Data -datanya berasal dari berbagai bidang seperti berita, pemandu perjalanan, dan buku. Kami memilih bahasa PBB resmi (Arab, Cina, Inggris, Prancis, Rusia dan Spanyol) serta Jerman dan Jepang sebagai bahasa uji. Kami menggunakan OpenCompass untuk melakukan tes 8-shot pada tujuh subtugas di Flores-101, termasuk Cina-Inggris, Cina-Prancis, SPAIN Tiongkok, Cina-Arab, China-Rusia, Cina-Jepang, dan Cina-Jerman.
| Cn-en | CN-Fr | CN-ES | CN-AR | CN-RU | CN-JP | Cn-de | Rata-rata | |
|---|---|---|---|---|---|---|---|---|
| GPT-4 | 29.94 | 29.56 | 20.01 | 10.76 | 18.62 | 13.26 | 20.83 | 20.43 |
| GPT-3.5 Turbo | 27.67 | 26.15 | 19.58 | 10.73 | 17.45 | 1.82 | 19.70 | 17.59 |
| Llama-7b | 17.27 | 12.02 | 9.54 | 0,00 | 4.47 | 1.41 | 8.73 | 7.63 |
| Llama2-7b | 25.76 | 15.14 | 11.92 | 0.79 | 4.99 | 2.20 | 10.15 | 10.14 |
| MPT-7B | 20.77 | 9.53 | 8.96 | 0.10 | 3.54 | 2.91 | 6.54 | 7.48 |
| Falcon-7b | 22.13 | 15.67 | 9.28 | 0.11 | 1.35 | 0.41 | 6.41 | 7.91 |
| Chatglm2-6b | 22.28 | 9.42 | 7.77 | 0.64 | 1.78 | 0.26 | 4.61 | 6.68 |
| Baichuan-7b | 25.07 | 16.51 | 12.72 | 0.41 | 6.66 | 2.24 | 9.86 | 10.50 |
| BAICHUAN2-7B-BASE | 27.27 | 20.87 | 16.17 | 1.39 | 11.21 | 3.11 | 12.76 | 13.25 |
| Cn-en | CN-Fr | CN-ES | CN-AR | CN-RU | CN-JP | Cn-de | Rata-rata | |
|---|---|---|---|---|---|---|---|---|
| GPT-4 | 29.94 | 29.56 | 20.01 | 10.76 | 18.62 | 13.26 | 20.83 | 20.43 |
| GPT-3.5 Turbo | 27.67 | 26.15 | 19.58 | 10.73 | 17.45 | 1.82 | 19.70 | 17.59 |
| Llama-13b | 21.75 | 16.16 | 13.29 | 0,58 | 7.61 | 0.41 | 10.66 | 10.07 |
| Llama2-13b | 25.44 | 19.25 | 17.49 | 1.38 | 10.34 | 0.13 | 11.13 | 12.17 |
| Vicuna-13b | 22.63 | 18.04 | 14.67 | 0,70 | 9.27 | 3.59 | 10.25 | 11.31 |
| China-Alpaca-plus-13b | 22.53 | 13.82 | 11.29 | 0.28 | 1.52 | 0.31 | 8.13 | 8.27 |
| Xverse-13b | 29.26 | 24.03 | 16.67 | 2.78 | 11.61 | 3.08 | 14.26 | 14.53 |
| BAICHUAN-13B-BASE | 30.24 | 20.90 | 15.92 | 0.98 | 9.65 | 2.64 | 12.00 | 13.19 |
| BAICHUAN2-13B-BASE | 30.61 | 22.11 | 17.27 | 2.39 | 14.17 | 11.58 | 14.53 | 16.09 |
Model bobot, kode sumber, dan konfigurasi yang diperlukan untuk inferensi telah diterbitkan di Face Memeluk. Kami menunjukkan berbagai cara penalaran di sini. Program akan secara otomatis mengunduh sumber daya yang diperlukan dari memeluk wajah.
pip install -r requirements.txt >> > import torch
>> > from transformers import AutoModelForCausalLM , AutoTokenizer
>> > from transformers . generation . utils import GenerationConfig
>> > tokenizer = AutoTokenizer . from_pretrained ( "baichuan-inc/Baichuan2-13B-Chat" , use_fast = False , trust_remote_code = True )
>> > model = AutoModelForCausalLM . from_pretrained ( "baichuan-inc/Baichuan2-13B-Chat" , device_map = "auto" , torch_dtype = torch . bfloat16 , trust_remote_code = True )
>> > model . generation_config = GenerationConfig . from_pretrained ( "baichuan-inc/Baichuan2-13B-Chat" )
>> > messages = []
>> > messages . append ({ "role" : "user" , "content" : "解释一下“温故而知新”" })
>> > response = model . chat ( tokenizer , messages )
>> > print ( response )
"温故而知新"是一句中国古代的成语,出自《论语·为政》篇。这句话的意思是:通过回顾过去,我们可以发现新的知识和理解。换句话说,学习历史和经验可以让我们更好地理解现在和未来。
这句话鼓励我们在学习和生活中不断地回顾和反思过去的经验,从而获得新的启示和成长。通过重温旧的知识和经历,我们可以发现新的观点和理解,从而更好地应对不断变化的世界和挑战。 >> > from transformers import AutoModelForCausalLM , AutoTokenizer
>> > tokenizer = AutoTokenizer . from_pretrained ( "baichuan-inc/Baichuan2-13B-Base" , trust_remote_code = True )
>> > model = AutoModelForCausalLM . from_pretrained ( "baichuan-inc/Baichuan2-13B-Base" , device_map = "auto" , trust_remote_code = True )
>> > inputs = tokenizer ( '登鹳雀楼->王之涣n夜雨寄北->' , return_tensors = 'pt' )
>> > inputs = inputs . to ( 'cuda:0' )
>> > pred = model . generate ( ** inputs , max_new_tokens = 64 , repetition_penalty = 1.1 )
>> > print ( tokenizer . decode ( pred . cpu ()[ 0 ], skip_special_tokens = True ))
登鹳雀楼- >王之涣
夜雨寄北- >李商隐Dalam dua kode di atas, model memuat
device_map='auto'yang ditentukan dan semua kartu grafis yang tersedia akan digunakan. Jika Anda perlu menentukan perangkat yang akan digunakan, Anda dapat menggunakan metode sepertiexport CUDA_VISIBLE_DEVICES=0,1(kartu grafis 0 dan 1 digunakan).
python cli_demo.pyAlat baris perintah ini dirancang untuk skenario obrolan, jadi kami tidak mendukung model basis panggilan menggunakan alat ini.
Mengandalkan streamlit untuk menjalankan perintah berikut, layanan web akan dimulai secara lokal dan alamat yang diberikan oleh konsol akan ditempatkan ke browser untuk diakses. Alat demo web ini dirancang untuk skenario obrolan, jadi kami tidak mendukung model basis panggilan menggunakan alat ini.
streamlit run web_demo.py用户:找到下列数组的中位数[3.1,6.2,1.3,8.4,10.5,11.6,2.1],请用python代码完成以上功能
Baichuan 2:def find_median(numbers):
numbers.sort()
length = len(numbers)
if length % 2 == 0:
return (numbers[length // 2 - 1] + numbers[length // 2]) / 2
else:
return numbers[length // 2]
numbers = [3.1, 6.2, 1.3, 8.4, 10.5, 11.6, 2.1]
print(find_median(numbers))
用户:鸡和兔在一个笼子里,共有26个头,68只脚,那么鸡有多少只,兔有多少只?
Baichuan 2:我们可以用代数方法来解决这个问题。假设鸡的数量为x,兔子的数量为y。根据题目给出的信息,我们可以得到以下两个方程:
1. x + y = 26 (头的总数)
2. 2x + 4y = 68 (脚的总数)
现在我们需要解这个二元一次方程组。首先从第一个方程中解出x:
x = 26 - y
然后将x的表达式代入第二个方程:
2(26 - y) + 4y = 68
52 - 2y + 4y = 68
2y = 16
接下来我们求解y的值:
y = 16 / 2
y = 8
现在我们得到了兔子的数量是8只。将y的值代入x的表达式求得鸡的数量:
x = 26 - 8
x = 18
所以鸡有18只,兔子有8只。
用户:从现在开始,请你将我接下来说的每一句话翻译成英语,准备好了吗?
Baichuan 2:I'm ready to translate every word you say next into English.
用户:你好
Baichuan 2:Hello
用户:我是Baichuan 2,很高兴认识大家
Baichuan 2:I am Baichuan 2, and I am very happy to meet everyone.
用户:希望通过大家的共同努力,早日迎接AGI时代的到来
Baichuan 2:I hope through the joint efforts of all of us, we can welcome the arrival of the AGI era as soon as possible.
用户:以下物理常识题目,哪一个是错误的?A.在自然环境下,声音在固体中传播速度最快。B.牛顿第一定律:一个物体如果不受力作用,将保持静止或匀速直线运动的状态。C.牛顿第三定律:对于每个作用力,都有一个相等而反向的反作用力。D.声音在空气中的传播速度为1000m/s。
Baichuan 2:本题考查物理基本概念和原理的理解和应用能力。
A项:声音的传播需要介质,在固体、液体和气体的三种介质中,声音在固体中的传播速度是最快的,故A正确; B项:牛顿第一定律是惯性定律,其内容是:一个物体如果没有受到外力的作用,要么保持静止状态,要么保持匀速直线运动状态,直到有外力迫使它改变运动状态为止,故B正确; C项:牛顿第三定律的内容是:对于每一个作用力,都有一个大小相等、方向相反的反作用力,这两个力分别作用在两个相互作用的物体上,故C错误; D项:声音在空气中以波的形式传播,其传播速度与介质的温度、湿度等因素有关,一般情况下,声音在空气中的传播速度约为340m/s左右,而不是1000m/s,故D错误。 因此,本题的正确答案是 D 。
用户:I'm Mike 。I am going to have a busy weekend。On Saturday,I am going to learn how to swim。I will go with my father。Then we are going to have lunch in the restaurant。In the afternoon,we are going to the zoo。We are going to see the pandas。On Sunday,I will finish my homework in the morning。In the afternoon,my parents and I are going to visit my grandparents。We will have dinner together。
阅读短文,判断正确和错误!正确请写T,错误请写F:
1.Mike is going to have a busy weekend()
2.Mike is going to learn how to swim with his father()
3.They are going to have lunch at home()
Baichuan 2:1. T(正确的)
2. T(正确的)
3. F(错误的)
Untuk memungkinkan pengguna yang berbeda dan platform yang berbeda untuk menjalankan model Baichuan 2, kami telah melakukan pekerjaan kuantitatif yang sesuai untuk model Baichuan 2 (termasuk Baichuan2-7B-CHAT dan Baichuan2-13b-CHAT) untuk memfasilitasi pengguna untuk dengan cepat dan efisien menggunakan model Baichuan 2 di platform mereka sendiri.
Baichuan 2 mengadopsi pendekatan kuantitatif arus utama komunitas: Bitsandbytes. Metode ini dapat memastikan bahwa efek kuantisasi pada dasarnya tidak hilang. Bitsandbytes mendukung kuantisasi 8bits dan 4bits, di mana 4bits mendukung format FP4 dan NF4.
Berdasarkan metode kuantisasi ini, Baichuan 2 mendukung dua mode: kuantisasi online dan kuantisasi offline.
Untuk kuantisasi online, kami mendukung kuantisasi quantize() dan cuda() . Kode untuk mengimplementasikan seluruh model pemuatan sangat sederhana.
Kuantifikasi online 8bits:
model = AutoModelForCausalLM . from_pretrained ( "baichuan-inc/Baichuan2-7B-Chat" , torch_dtype = torch . float16 , trust_remote_code = True )
model = model . quantize ( 8 ). cuda () Kuantisasi online 4bits:
model = AutoModelForCausalLM . from_pretrained ( "baichuan-inc/Baichuan2-7B-Chat" , torch_dtype = torch . float16 , trust_remote_code = True )
model = model . quantize ( 4 ). cuda () Perlu dicatat bahwa ketika menggunakan antarmuka from_pretrained , pengguna umumnya akan menambahkan device_map="auto" . Saat menggunakan kuantisasi online, parameter ini perlu dihapus, jika tidak kesalahan akan dilaporkan.
Untuk memfasilitasi penggunaan pengguna, kami menyediakan versi offline kuantisasi Baichuan2-7B-CHAT-4BIT untuk diunduh pengguna. Sangat sederhana bagi pengguna untuk memuat model Baichuan2-7B-CHAT-4Bits, hanya perlu dieksekusi:
model = AutoModelForCausalLM . from_pretrained ( "baichuan-inc/Baichuan2-7B-Chat-4bits" , device_map = "auto" , trust_remote_code = True )Untuk kuantisasi offline 8bits, kami tidak menyediakan versi yang sesuai, karena perpustakaan Face Transformers yang memeluk menyediakan antarmuka API yang sesuai, yang dapat dengan mudah mengimplementasikan penyimpanan dan pemuatan model kuantitatif 8bits. Pengguna dapat mewujudkan penghematan dan pemuatan model 8bits dengan cara berikut:
# Model saving: model_id is the original model directory, and quant8_saved_dir is the directory where the 8bits quantized model is saved.
model = AutoModelForCausalLM . from_pretrained ( model_id , load_in_8bit = True , device_map = "auto" , trust_remote_code = True )
model . save_pretrained ( quant8_saved_dir )
model = AutoModelForCausalLM . from_pretrained ( quant8_saved_dir , device_map = "auto" , trust_remote_code = True )Perbandingan Penggunaan Memori Video Sebelum dan Setelah Kuantisasi (GPU MEM dalam GB):
| Presisi | Baichuan2-7b | Baichuan2-13b |
|---|---|---|
| BF16 / FP16 | 15.3 | 27.5 |
| 8bits | 8.0 | 16.1 |
| 4bits | 5.1 | 8.6 |
Hasil dan versi asli pada setiap tolok ukur setelah kuantisasi ditunjukkan di bawah ini:
| Model 5-shot | C-eval | Mmlu | Cmmlu |
|---|---|---|---|
| Baichuan2-13b-CHAT | 56.74 | 57.32 | 59.68 |
| Baichuan2-13B-CHAT-4Bits | 56.05 | 56.24 | 58.82 |
| Baichuan2-7B-CHAT | 54.35 | 52.93 | 54.99 |
| Baichuan2-7B-CHAT-4Bits | 53.04 | 51.72 | 52.84 |
C-eval adalah evaluasi yang dilakukan pada set valnya
Seperti yang Anda lihat, hilangnya akurasi 4bits relatif terhadap bfloat16 adalah sekitar 1-2 poin persentase.
Model Baichuan 2 mendukung inferensi CPU, tetapi harus ditekankan bahwa kecepatan inferensi CPU relatif lambat. Metode pemuatan model perlu dimodifikasi sebagai berikut:
# Taking Baichuan2-7B-Chat as an example
model = AutoModelForCausalLM . from_pretrained ( "baichuan-inc/Baichuan2-7B-Chat" , torch_dtype = torch . float32 , trust_remote_code = True ) Karena banyak pengguna telah melakukan banyak pekerjaan optimisasi pada Baichuan 1 (Baichuan-7b, Baichuan-13b), seperti optimasi kompilasi, kuantisasi, dll. Untuk menerapkan pekerjaan ini ke Baichuan 2 dengan biaya nol, mereka dapat melakukan konversi offline dari model Baichuan 2, dan setelah konversi, mereka dapat digunakan sebagai BAICHUAN 1. Secara khusus, pengguna hanya perlu menggunakan skrip berikut untuk menormalkan lapisan terakhir LM_HEAD di model Baichuan 2 offline dan mengganti lm_head.weight . Setelah penggantian, Anda dapat mengkompilasi dan mengoptimalkan model yang dikonversi seperti model Baichuan 1.
import torch
import os
ori_model_dir = 'your Baichuan 2 model directory'
# To avoid overwriting the original model, it's best to save the converted model to another directory before replacing it
new_model_dir = 'your normalized lm_head weight Baichuan 2 model directory'
model = torch . load ( os . path . join ( ori_model_dir , 'pytorch_model.bin' ))
lm_head_w = model [ 'lm_head.weight' ]
lm_head_w = torch . nn . functional . normalize ( lm_head_w )
model [ 'lm_head.weight' ] = lm_head_w
torch . save ( model , os . path . join ( new_model_dir , 'pytorch_model.bin' ))git clone https://github.com/baichuan-inc/Baichuan2.git
cd Baichuan2/fine-tune
pip install -r requirements.txtDi bawah ini kami memberikan contoh pelatihan yang berdiri sendiri untuk menyempurnakan Baichuan2-7B-base.
Data Pelatihan: data/belle_chat_ramdon_10k.json , data sampel diambil dari multiturn_chat_0.8m, dan konversi format dilakukan. Ini terutama menunjukkan cara melatih beberapa putaran data, dan tidak menjamin efeknya.
hostfile= " "
deepspeed --hostfile= $hostfile fine-tune.py
--report_to " none "
--data_path " data/belle_chat_ramdon_10k.json "
--model_name_or_path " baichuan-inc/Baichuan2-7B-Base "
--output_dir " output "
--model_max_length 512
--num_train_epochs 4
--per_device_train_batch_size 16
--gradient_accumulation_steps 1
--save_strategy epoch
--learning_rate 2e-5
--lr_scheduler_type constant
--adam_beta1 0.9
--adam_beta2 0.98
--adam_epsilon 1e-8
--max_grad_norm 1.0
--weight_decay 1e-4
--warmup_ratio 0.0
--logging_steps 1
--gradient_checkpointing True
--deepspeed ds_config.json
--bf16 True
--tf32 TrueUntuk pelatihan multi-mesin, Anda hanya perlu memberikan hostfile, dan kontennya mirip dengan yang berikut:
ip1 slots=8
ip2 slots=8
ip3 slots=8
ip4 slots=8
....
Pada saat yang sama, tentukan jalur ke hosftfile dalam skrip pelatihan:
hostfile= " /path/to/hostfile "
deepspeed --hostfile= $hostfile fine-tune.py
--report_to " none "
--data_path " data/belle_chat_ramdon_10k.json "
--model_name_or_path " baichuan-inc/Baichuan2-7B-Base "
--output_dir " output "
--model_max_length 512
--num_train_epochs 4
--per_device_train_batch_size 16
--gradient_accumulation_steps 1
--save_strategy epoch
--learning_rate 2e-5
--lr_scheduler_type constant
--adam_beta1 0.9
--adam_beta2 0.98
--adam_epsilon 1e-8
--max_grad_norm 1.0
--weight_decay 1e-4
--warmup_ratio 0.0
--logging_steps 1
--gradient_checkpointing True
--deepspeed ds_config.json
--bf16 True
--tf32 TrueKode sudah mendukung penyempurnaan ringan seperti Lora.
--use_lora True Konfigurasi spesifik LORA dapat ditemukan dalam skrip fine-tune.py .
Setelah menyempurnakan dengan Lora, Anda dapat menggunakan perintah berikut untuk memuat model:
from peft import AutoPeftModelForCausalLM
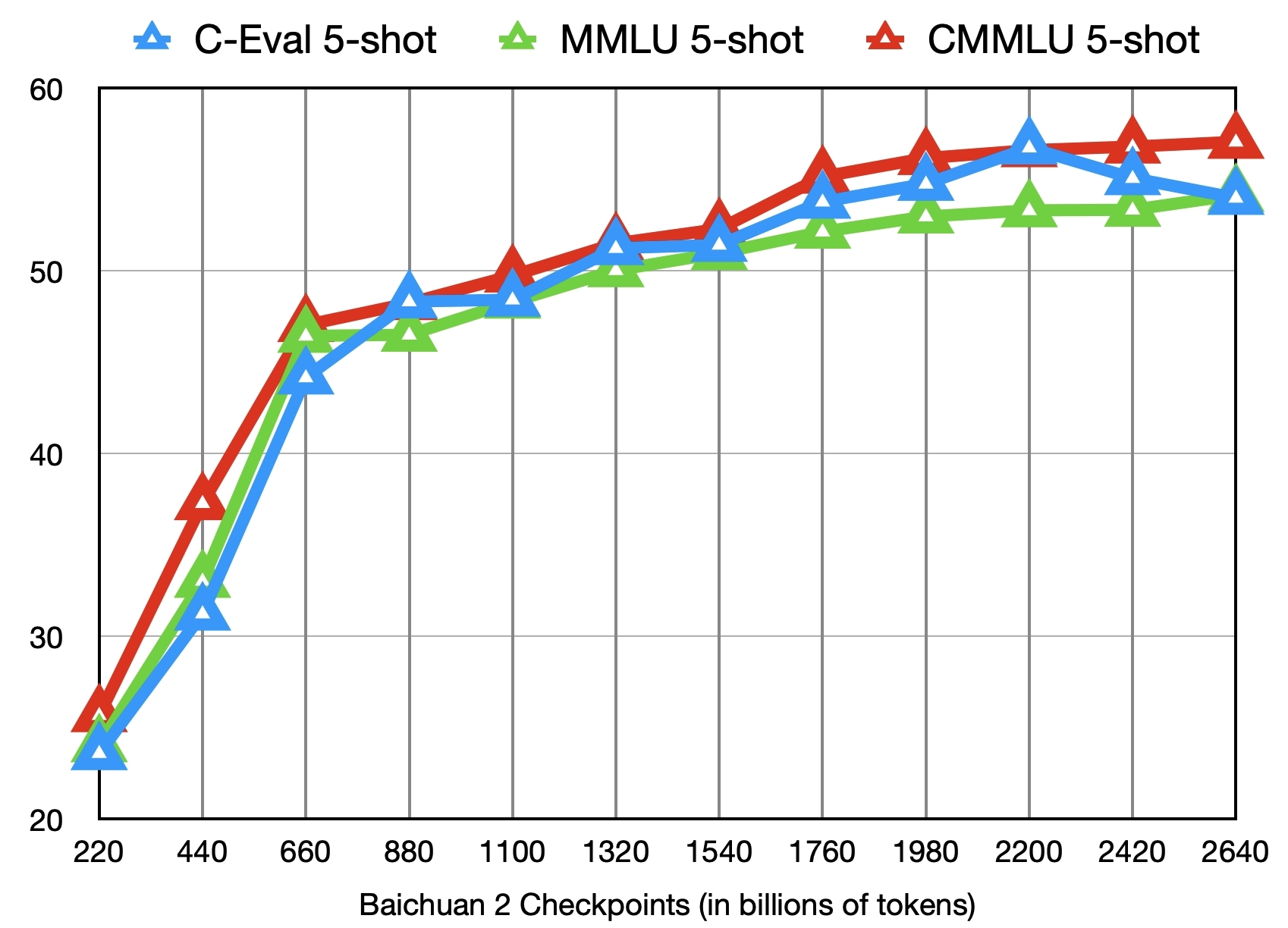
model = AutoPeftModelForCausalLM . from_pretrained ( "output" , trust_remote_code = True )Selain melatih model baichuan2-7b-base dengan 2,6 triliun token, kami juga menyediakan 11 pos pemeriksaan menengah lainnya (masing-masing dilatih masing-masing sekitar 0,2 hingga 2,4 triliun token) untuk penelitian komunitas (alamat unduhan). Gambar berikut menunjukkan efek perubahan pos pemeriksaan ini pada tiga tolok ukur C-eval, MMLU, dan CMMLU:
??? Kami akan terus memperbarui komunitas dan dukungan ekosistem untuk Baichuan 2 di sini ???
Deploy Baichuan2 - 7b/Chat, Baichuan2 - 13B/Chat Model Menggunakan Core ™/Xiang® Scalable Processor atau dengan Ruixuan ™ GPU.
BIGDL-LLM (CPU, GPU) disarankan untuk mencapai kinerja inferensi yang lebih baik.
Manual Operasi Cina, termasuk dukungan notebook
Memuat, optimasi, metode penghematan, dll.
Model fine-tuning: Baichuan 2 (7b) telah secara asli mendukung pytorch (2.1.0) + transformer (4.36.0) + DeepSpeed (0.12.4) + percepatan (0.25.0) fine-tuning model, yang dapat digunakan tanpa adaptasi tambahan.
Penyebaran Inferensi: Baichuan 2 (7b) telah secara native mendukung inferensi NPU Ascend dan dapat digunakan tanpa adaptasi tambahan.
MindFormers adalah kit pengembangan proses penuh berdasarkan kerangka kerja Mindspore dan mendukung pelatihan model skala besar, penyempurnaan, evaluasi, penalaran dan penyebaran.
Platform Shengsi Big Model didasarkan pada kerangka kerja AI Shengsi Mindspore, MindFormer Big Model Development Kit dan Ascend Hardware Computing Power, dan membuka kemampuan model besar Baichuan2-7B kepada publik, dan semua orang dipersilakan untuk mengalaminya secara online.
Llama-efisien tuning telah mendukung penyesuaian dan pelatihan berkelanjutan dari model Baichuan 2.
Baichuan2 (7b/13b) mendukung penalaran kartu akselerasi Taichu T100, dan saluran persidangan telah secara resmi dibuka untuk umum.
Kami dengan ini menyatakan bahwa tim pengembangan kami belum mengembangkan aplikasi apa pun berdasarkan model Baichuan 2, baik di iOS, Android, halaman web, atau platform lainnya. Kami sangat meminta semua pengguna untuk tidak menggunakan model Baichuan 2 untuk melakukan kegiatan apa pun yang membahayakan Jaminan Sosial Nasional atau ilegal. Selain itu, pengguna juga diminta untuk tidak menggunakan model Baichuan 2 untuk layanan internet yang belum ditinjau dan terdaftar dengan benar. Kami berharap bahwa semua pengguna dapat mematuhi prinsip ini dan memastikan bahwa pengembangan sains dan teknologi dapat dilakukan dalam lingkungan standar dan hukum.
Kami telah melakukan semua yang kami bisa untuk memastikan kepatuhan dengan data yang digunakan selama pelatihan model. Namun, terlepas dari upaya besar kami, masih ada beberapa masalah yang tidak terduga karena kompleksitas model dan data. Oleh karena itu, kami tidak akan bertanggung jawab atas masalah apa pun yang timbul dari penggunaan model open source Baichuan 2, termasuk tetapi tidak terbatas pada masalah keamanan data, risiko opini publik, atau risiko dan masalah apa pun yang timbul dari penyalahgunaan, penyalahgunaan, penyebaran atau penggunaan model yang tidak tepat.
Komunitas menggunakan model Baichuan 2 untuk mengikuti Perjanjian Lisensi Komunitas Model Baichuan 2. Model Baichuan 2 berguna secara komersial.
Jika kondisi di atas dipenuhi, Anda perlu mengirimkan materi aplikasi yang diperlukan oleh perjanjian lisensi komunitas model Baichuan 2 melalui alamat email berikut [email protected]. Setelah ulasan disetujui, Baichuan dengan ini akan memberi Anda non-eksklusif, global, tidak dapat dipindahtangankan, tidak diterbitkan, lisensi hak cipta komersial yang dapat dibatalkan.
Mengutip pekerjaan kami, silakan gunakan referensi berikut:
@article{baichuan2023baichuan2,
title={Baichuan 2: Open Large-scale Language Models},
author={Baichuan},
journal={arXiv preprint arXiv:2309.10305},
url={https://arxiv.org/abs/2309.10305},
year={2023}
}


