tribe
v0.7.6

다중 에이전트 팀을 신속하게 구축하고 조정하는 낮은 코드 도구
경고
이 프로젝트는 현재 큰 발전 중입니다. 중대한 변화가 발생할 수 있습니다.
'두 마음이 하나보다 낫다'는 말을 들었습니까? 에이전트에게도 마찬가지입니다. Tribe는 Langgraph 프레임 워크를 활용하여 에이전트 팀을 쉽게 사용자 정의하고 조정할 수 있습니다. 다른 것들에 능숙한 에이전트들 사이에서 힘든 작업을 분할함으로써 각각은 최선을 다하는 것에 집중할 수 있습니다. 이것은 문제를 더 빠르고 더 좋게 만듭니다.
팀을 구성함으로써 에이전트는보다 복잡한 작업을 수행 할 수 있습니다. 다음은 함께 할 수있는 일에 대한 몇 가지 예입니다.
그리고 더 많은 것들!
배포하기 전에 최소한 값을 변경해야합니다.
SECRET_KEYFIRST_SUPERUSER_PASSWORDPOSTGRES_PASSWORD비밀에서 환경 변수로이를 전달할 수 있습니다.
.env 파일의 일부 환경 변수는 기본값이 changethis 입니다.
비밀 키로 변경하고 비밀 키를 생성하려면 다음 명령을 실행할 수 있습니다.
python -c " import secrets; print(secrets.token_urlsafe(32)) "내용을 복사하여 암호 / 비밀 키로 사용하십시오. 또 다른 안전한 키를 생성하기 위해 다시 실행하십시오.
현지 기계에서 몇 분 안에 일어나서 시작하십시오.
원격 서버에 Tribe를 배포하십시오.
순차적 인 워크 플로에서 에이전트는 순서대로 순서로 정렬되어 작업을 서로 실행합니다. 각 작업은 이전 작업에 따라 달라질 수 있습니다. 이것은 결정적인 순서로 작업을 수행하려는 경우 유용합니다.
이 경우 사용하십시오.
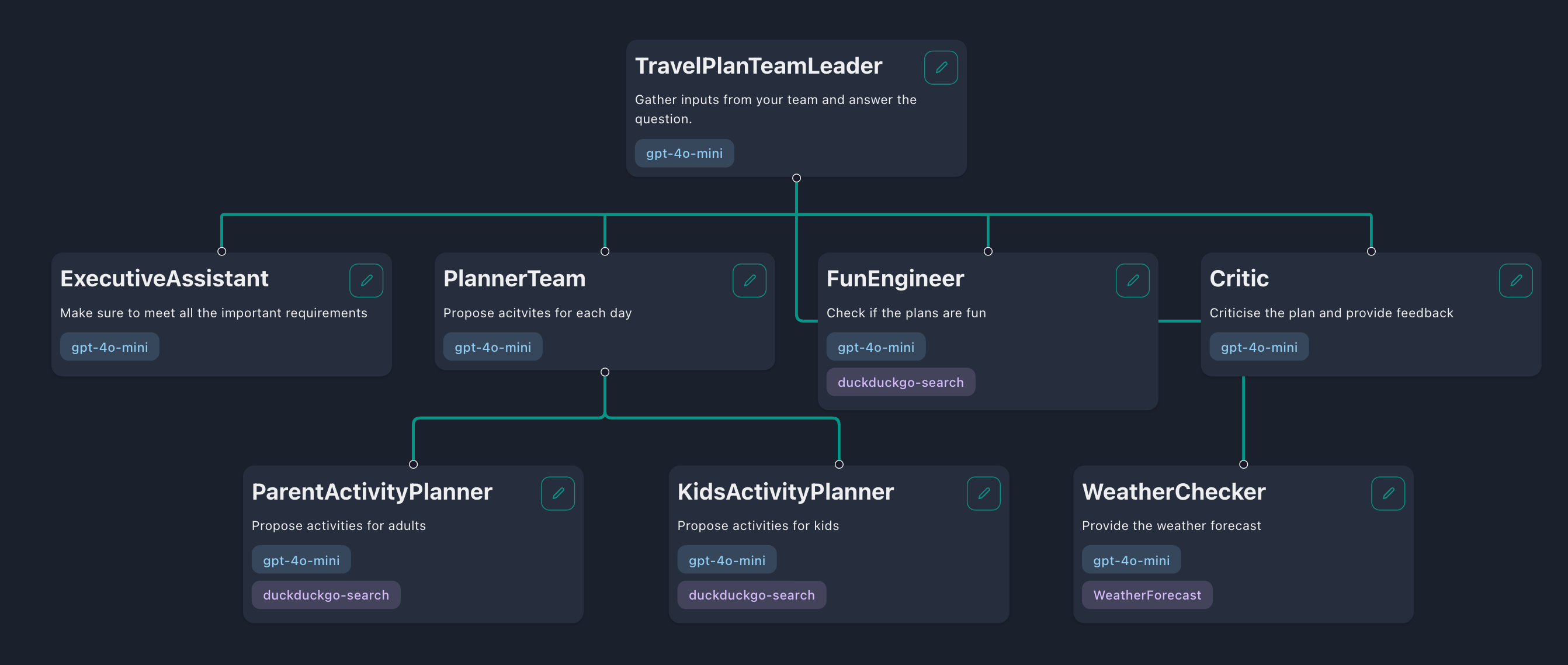
계층 적 워크 플로에서 에이전트는 '팀 리더', '팀원'및 기타 '하위 팀 리더'로 구성된 팀과 같은 구조로 구성됩니다. 팀 리더는 작업을 작은 작업으로 나누고 팀원에게 위임합니다. 팀원이 이러한 작업을 완료하면 그들의 응답은 팀 리더에게 전달되어 사용자에게 응답을 반환하거나 더 많은 작업을 위임하기로 결정합니다.
이 경우 사용하십시오.
기술은 에이전트를 세상과 상호 작용하도록 장비 할 수있는 능력입니다. 예를 들어, 현재 날씨 조건을 확인하거나 웹을 검색하여 최신 뉴스를 검색 할 수있는 기술을 상담원에게 제공 할 수 있습니다. 기본적으로 Tribe는 세 가지 기술을 제공합니다.
간단한 HTTP 요청에 대한 기능 정의를 사용하거나 코드베이스에 사용자 정의 기술을 작성하여 두 가지 방식으로 수행 할 수있는 사용자 정의 기술을 만들 수 있습니다.
기술이 데이터를 가져 오거나 업데이트하기위한 HTTP 요청을 수행하는 경우 기술 정의를 사용하여 가장 간단한 접근법입니다. Tribe에서는 '기술'탭을 탐색하고 '기술 추가'버튼을 클릭하십시오. 그런 다음 기술 정의를 제공하라는 메시지가 표시되며, 이는 에이전트에게 특정 기술을 실행하는 방법에 대해 지시합니다. 이 정의는 다음과 같이 구성되어야합니다.
{
"url" : " https://example.com " ,
"method" : " GET " ,
"headers" : {},
"type" : " function " ,
"function" : {
"name" : " Your skill name " ,
"description" : " Your skill description " ,
"parameters" : {
"type" : " object " ,
"properties" : {
"param1" : {
"type" : " integer " ,
"description" : " Description of the first parameter "
},
"param2" : {
"type" : " string " ,
"enum" : [ " option1 " ],
"description" : " Description of the second parameter "
}
},
"required" : [ " param1 " , " param2 " ]
}
}
}| 열쇠 | 설명 |
|---|---|
url | API 호출의 엔드 포인트 URL. |
method | 요청에 사용 된 HTTP 방법. GET , POST , PUT , PATCH 또는 DELETE 수 있습니다. |
headers | 요청에 포함 할 HTTP 헤더. |
function | 기술에 대한 세부 사항이 포함되어 있습니다. |
function > name | 기술의 이름. 다음과 같은 규칙을 따르십시오 : 문자 (AZ, AZ), 숫자 (0-9), 밑줄 (_) 및 하이픈 (-) 만 허용됩니다. 1 ~ 64 자 사이 길이 여야합니다. |
function > description | 에이전트에게 사용량에 대해 알리는 기술을 설명합니다. |
function > parameters | API가 수락하는 매개 변수에 대한 세부 사항. |
properties > param | 쿼리 또는 신체 매개 변수의 이름. GET 메소드의 경우 쿼리 매개 변수가됩니다. POST , PUT , PATCH 및 DELETE 의 경우 요청 본문에 있습니다. |
param > type | string , number , integer 또는 boolean 수있는 매개 변수의 유형을 지정합니다. |
param > description | 매개 변수의 목적에 대한 컨텍스트를 제공합니다. |
param > enum | 선택적으로, 사전 정의 된 값에서 선택하도록 에이전트를 제한하는 배열을 포함하십시오. |
parameters > required | API 요청에 항상 포함되도록 필요한 매개 변수를 나열합니다. |
간단한 HTTP 요청을 넘어 확장되는 더 복잡한 작업을 위해 Langchain을 사용하면보다 고급 도구를 개발할 수 있습니다. 이러한 도구를 managed_skills 사전에 추가하여 Tribe에 통합 할 수 있습니다. 실제적인 예는 데모 계산기 도구를 참조하십시오. Langchain 도구를 만드는 방법을 배우려면 해당 문서를 참조하십시오.
새 도구를 작성한 후 응용 프로그램을 다시 시작하여 도구가 데이터베이스에 올바르게로드되어 있는지 확인하십시오. 마찬가지로, 도구를 제거 해야하는 경우 툴을 제거 해야하는 경우 managed_skills Dictionary에서 도구를 삭제하고 응용 프로그램이 데이터베이스에서 제거되도록 응용 프로그램을 다시 시작하십시오. 이 방법으로 생성 된 도구는 응용 프로그램의 모든 사용자가 사용할 수 있습니다.
Rag는 추가 데이터로 에이전트의 지식을 증강시키는 기술입니다. 에이전트는 광범위한 주제에 대해 추론 할 수 있지만, 그들의 지식은 훈련 시점까지 공개 데이터로 제한됩니다. 에이전트가 개인 데이터에 대해 추론하기를 원한다면 Tribe를 사용하면 데이터를 업로드하고 에이전트의 지식 기반에 포함 할 데이터를 선택할 수 있습니다. 이를 통해 상담원이 선택한 데이터로 추론 할 수 있으며 전문 지식으로 다른 에이전트를 만들 수 있습니다.
기본적으로 Tribe는 BAAI/bge-small-en-v1.5 사용합니다. 이는 OpenAI Ada-002 보다 가볍고 빠른 영어 임베딩 모델입니다. 문서가 다국어이거나 이미지 임베딩이 필요한 경우 다른 임베딩 모델을 사용할 수 있습니다. .env 파일에서 DENSE_EMBEDDING_MODEL 변경하여 쉽게 수행 할 수 있습니다.
# See the list of supported models: https://qdrant.github.io/fastembed/examples/Supported_Models/
DENSE_EMBEDDING_MODEL=BAAI/bge-small-en-v1.5 # Change this 경고
기존 및 새 임베딩 모델의 벡터 치수가 다르면 Qdrant 컬렉션을 재현해야 할 수도 있습니다. http : //qdrant.localhost/dashboard에서 Qdrant 대시 보드를 통해 컬렉션을 삭제할 수 있습니다. 따라서 어떤 임베딩 모델이 워크 플로에 가장 적합한 지 계획하는 것이 좋습니다.
오픈 소스 모델은 더 저렴하고 실행이 쉬워지고 있으며 일부는 폐쇄 된 모델의 성능과 일치합니다. 개인 정보 보호 및 비용 혜택을 위해 사용하는 것이 좋습니다. 부족을 현지에서 운영하고 오픈 소스 모델을 사용하려면 Ollama를 사용하기 쉽도록 권장합니다.
ollama 에 업데이트하십시오.llama3.1:8b )을 모델 입력 필드에 붙여 넣으십시오.http://host.docker.internal:11434 에서 실행되며 https://localhost:11434 에 맵핑됩니다. 이 설정을 통해 부족은 기본 Ollama 호스트와 의사 소통 할 수 있습니다. 설정이 다른 호스트를 사용하는 경우 'Base URL'입력 필드에 새 호스트를 지정하십시오. Ollama의 도서관에는 다양한 작업에 적합한 수백 개의 오픈 소스 모델이 있습니다. 유스 케이스에 적합한 것을 선택하는 방법은 다음과 같습니다.
Llama3.1 , Mistral Nemo , Firefunction V2 또는 Command-R + 및 도구 통화를 지원하는 다른 모델을 사용하십시오.gemma2 또는 phi3 와 같은 모델을 고려할 수 있습니다. Ollama를 사용하지 않는 경우 OpenAi 채팅 완료 API와 호환되는 오픈 소스 모델을 여전히 실행할 수 있습니다.
단계 :
설치 단계에서 설정 한 이메일과 비밀번호를 사용하여 Tribe에 로그인하십시오.
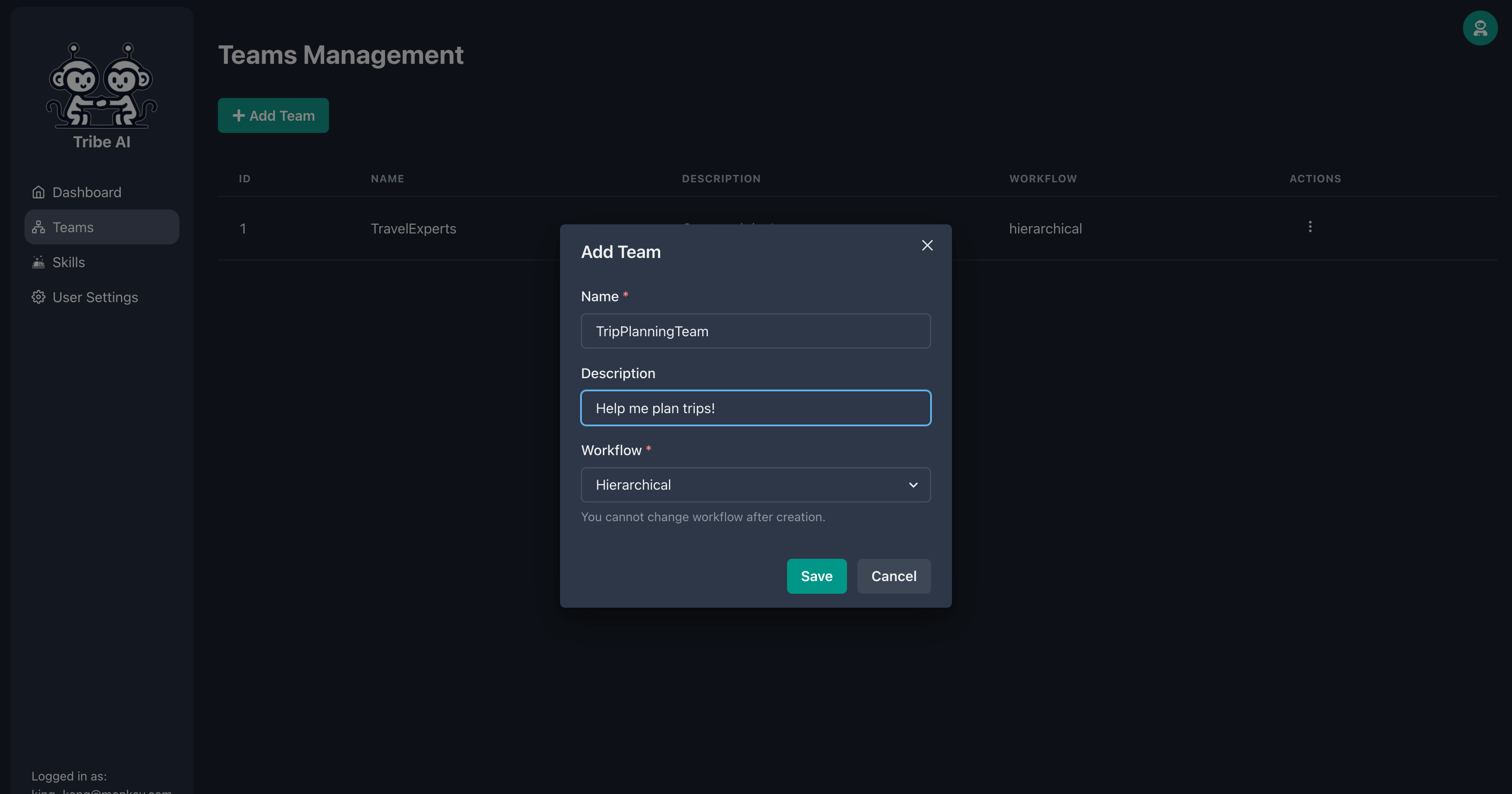
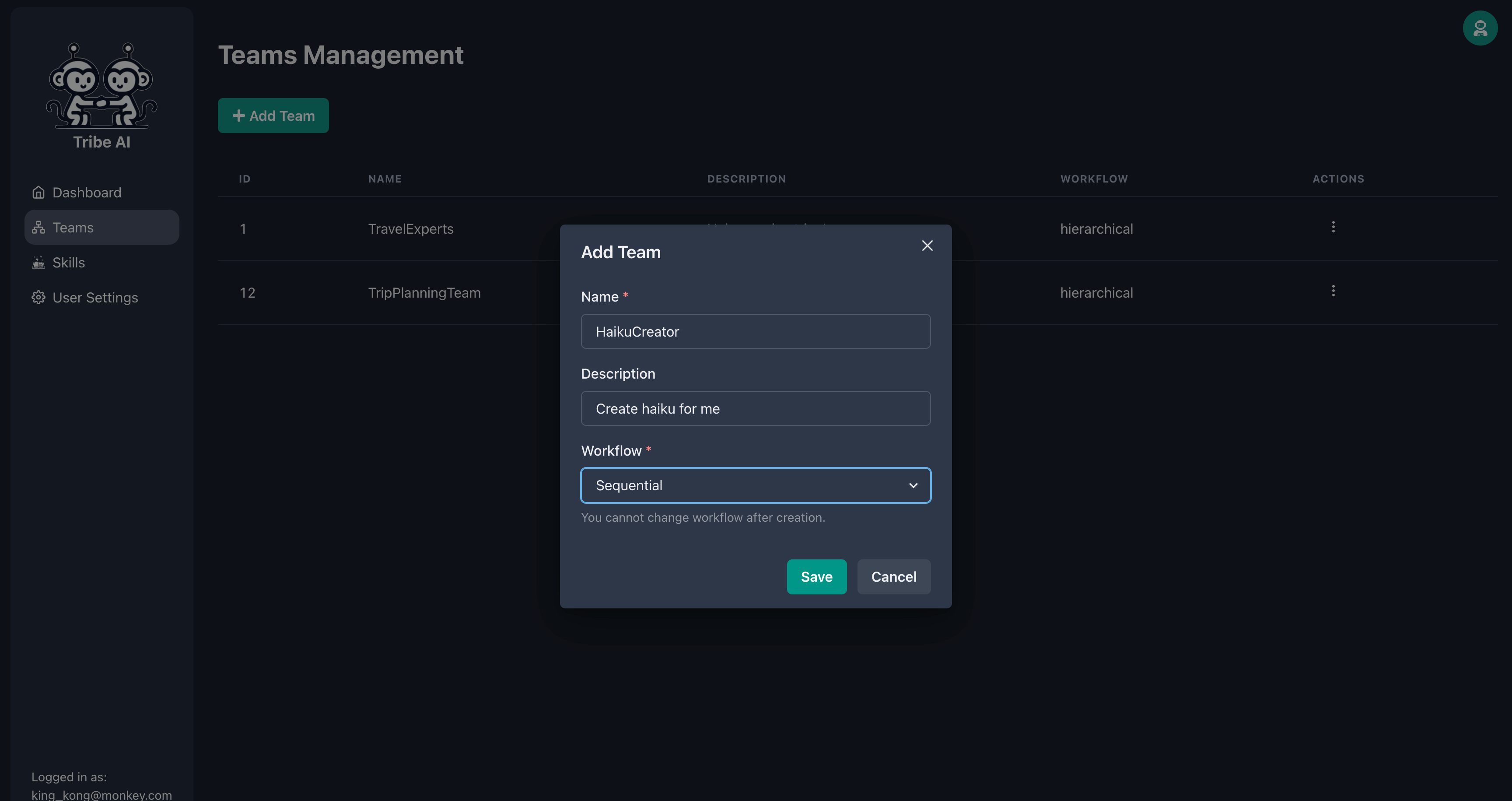
'팀'페이지로 이동하여 '팀 추가'를 클릭하십시오. 팀 이름을 입력하고 '저장'을 클릭하십시오.
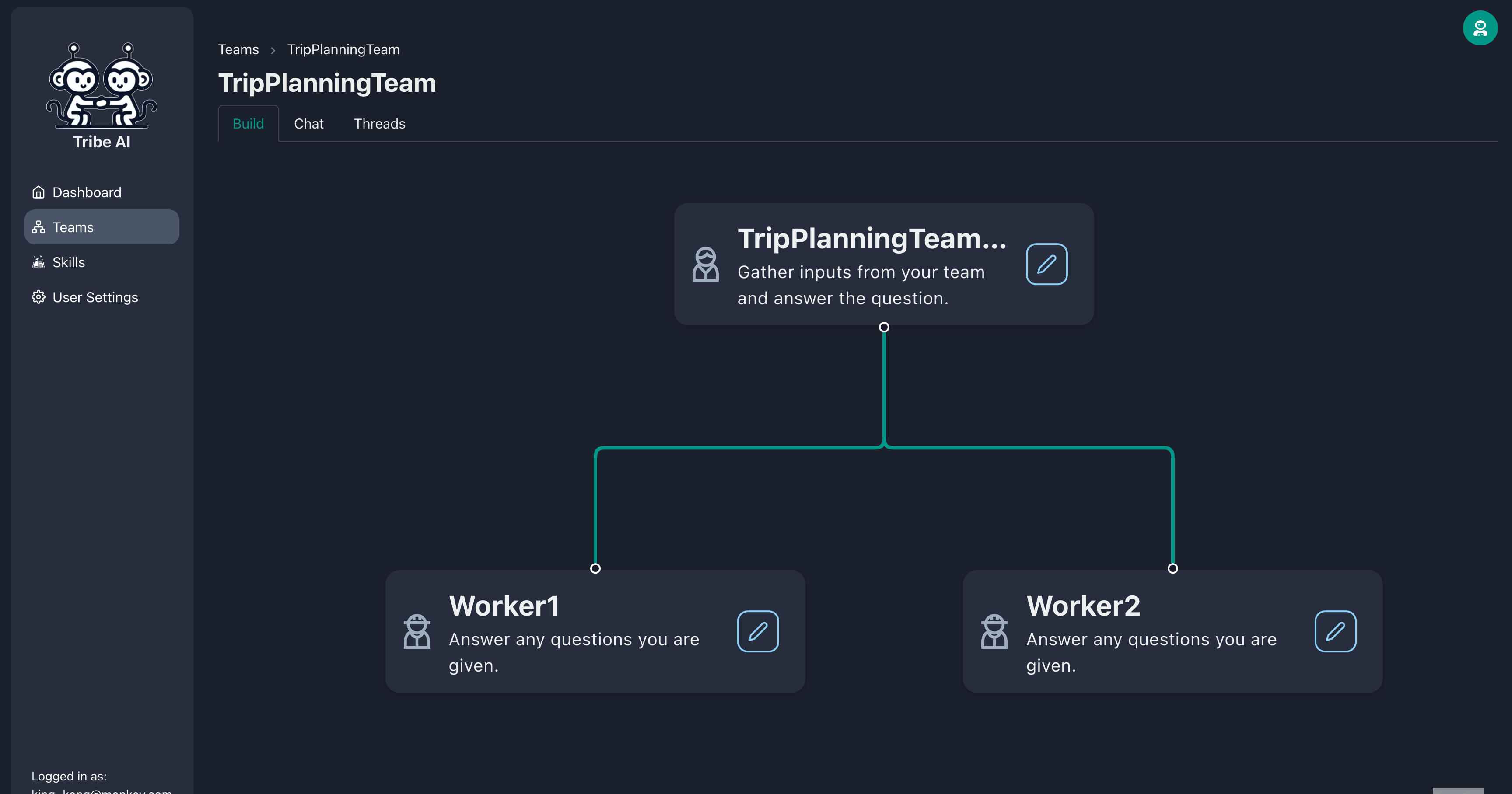
팀 리더 노드의 핸들을 드래그하여 두 명의 추가 팀원을 만듭니다.
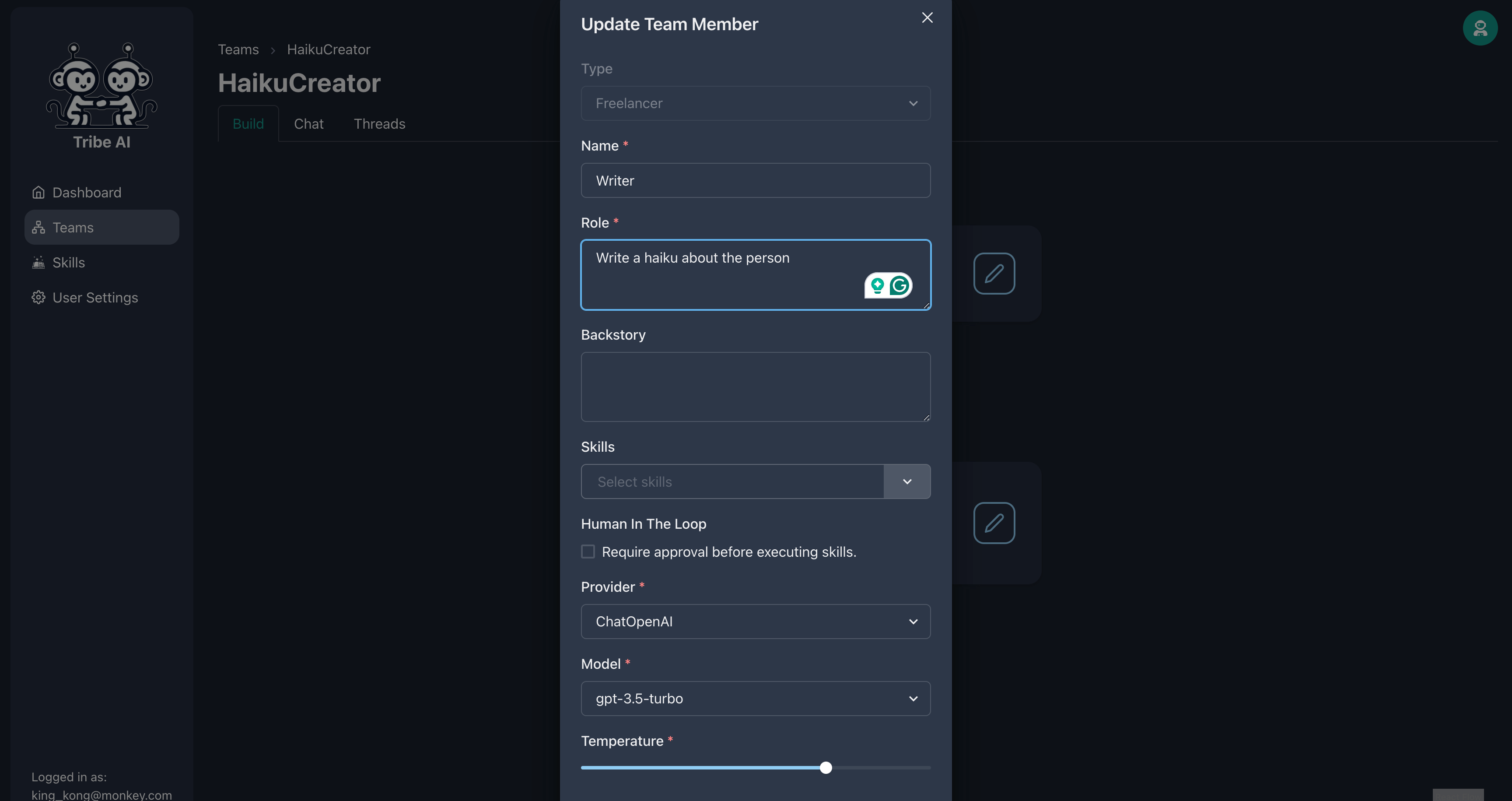
표시된대로 첫 번째 팀원을 업데이트하십시오.
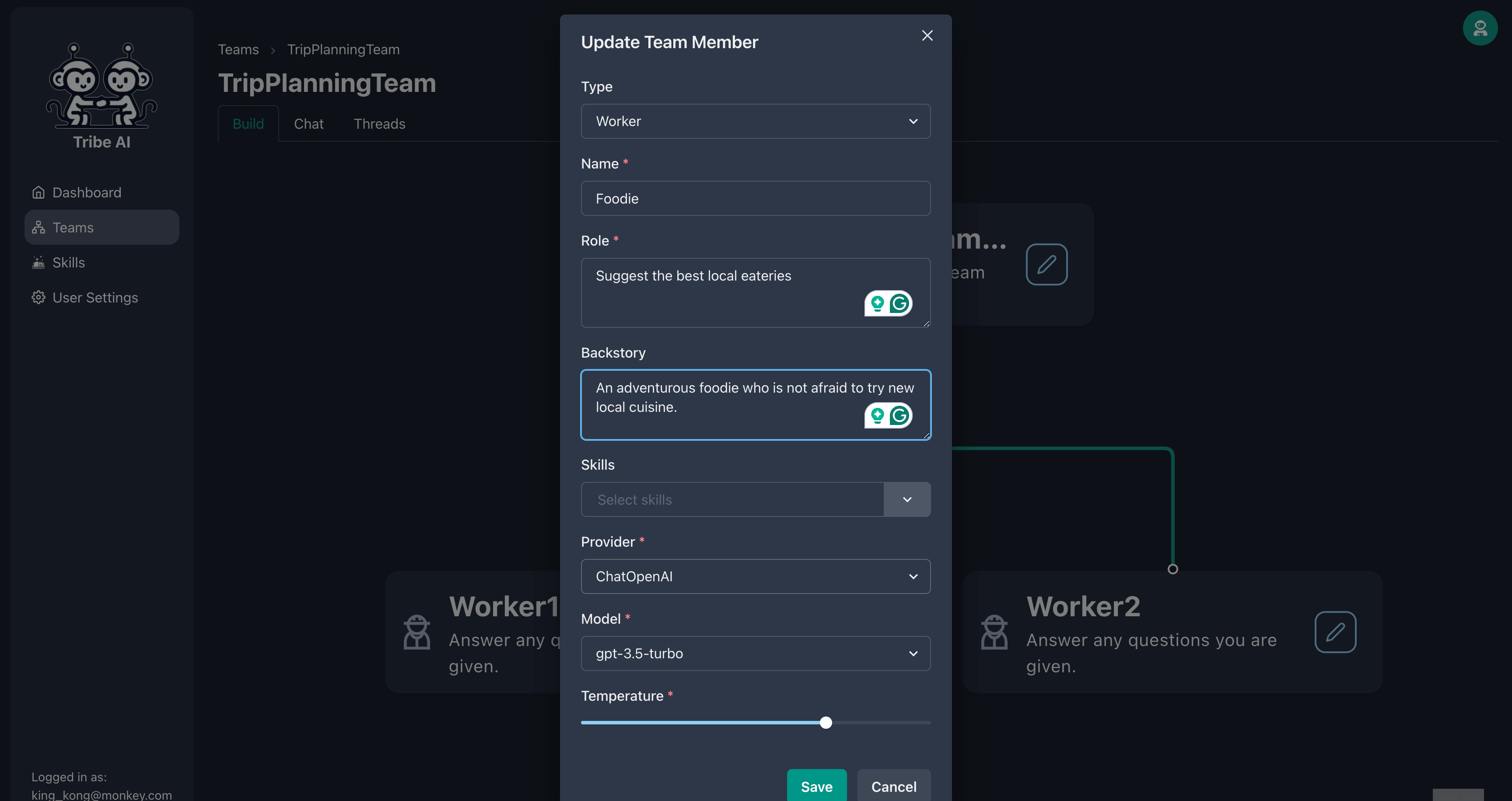
표시된대로 두 번째 팀원을 업데이트하십시오.
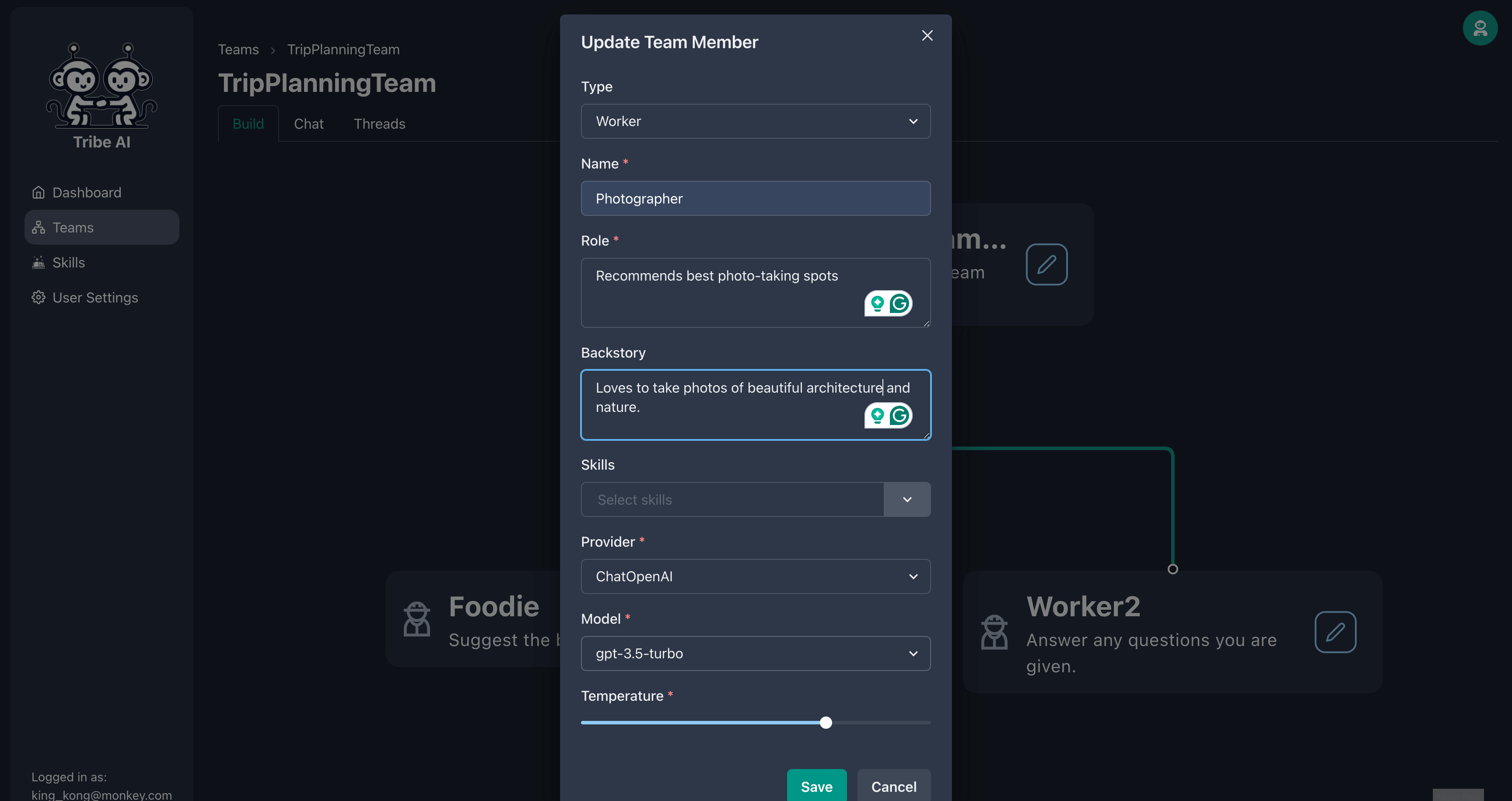
'채팅'탭으로 이동하여 팀에 질문을 보내서 어떻게 응답하는지 확인하십시오.
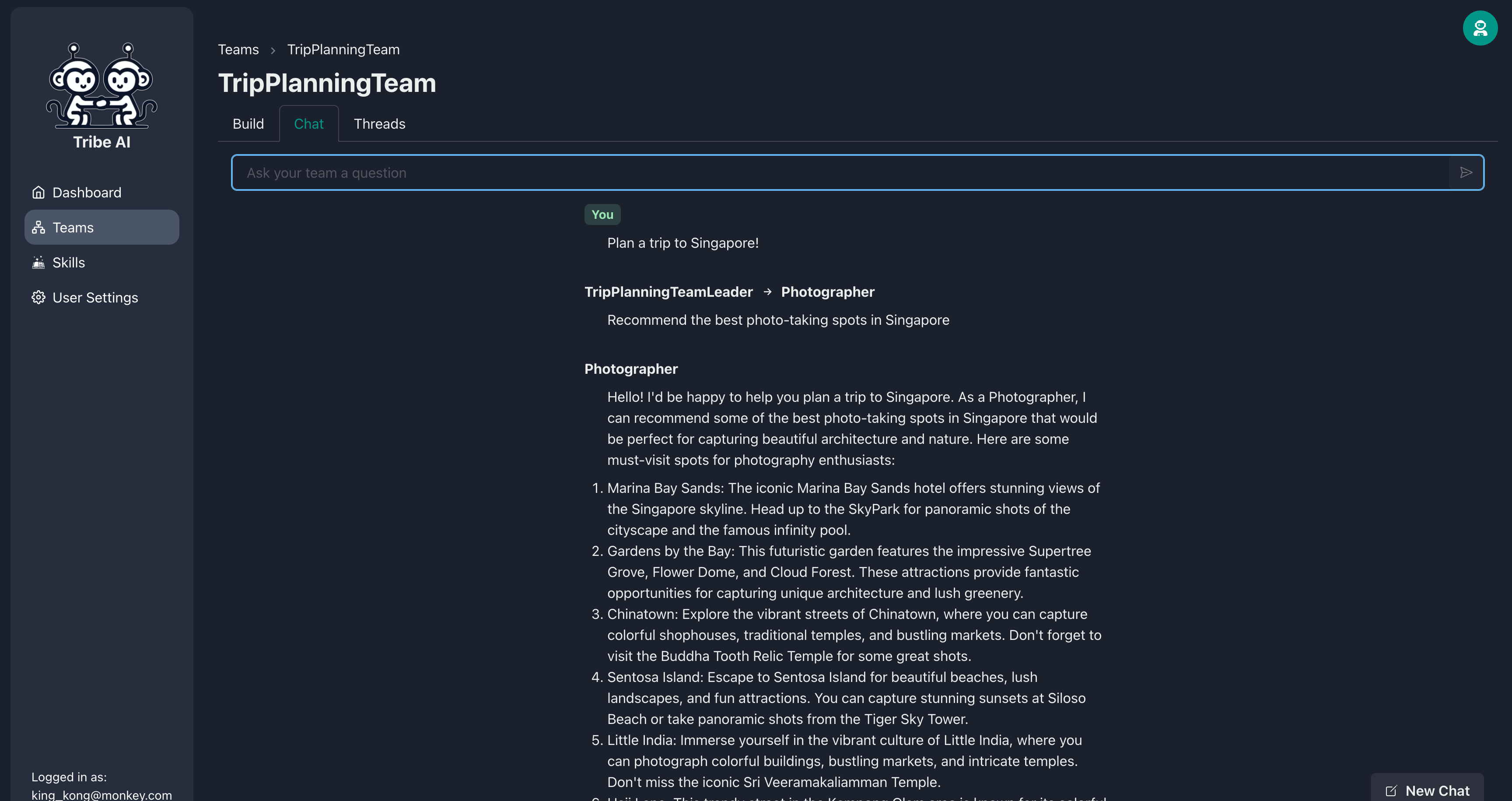
축하해요! 당신은 Tribe의 첫 Multi-Agent 팀과 성공적으로 구축하고 의사 소통했습니다.
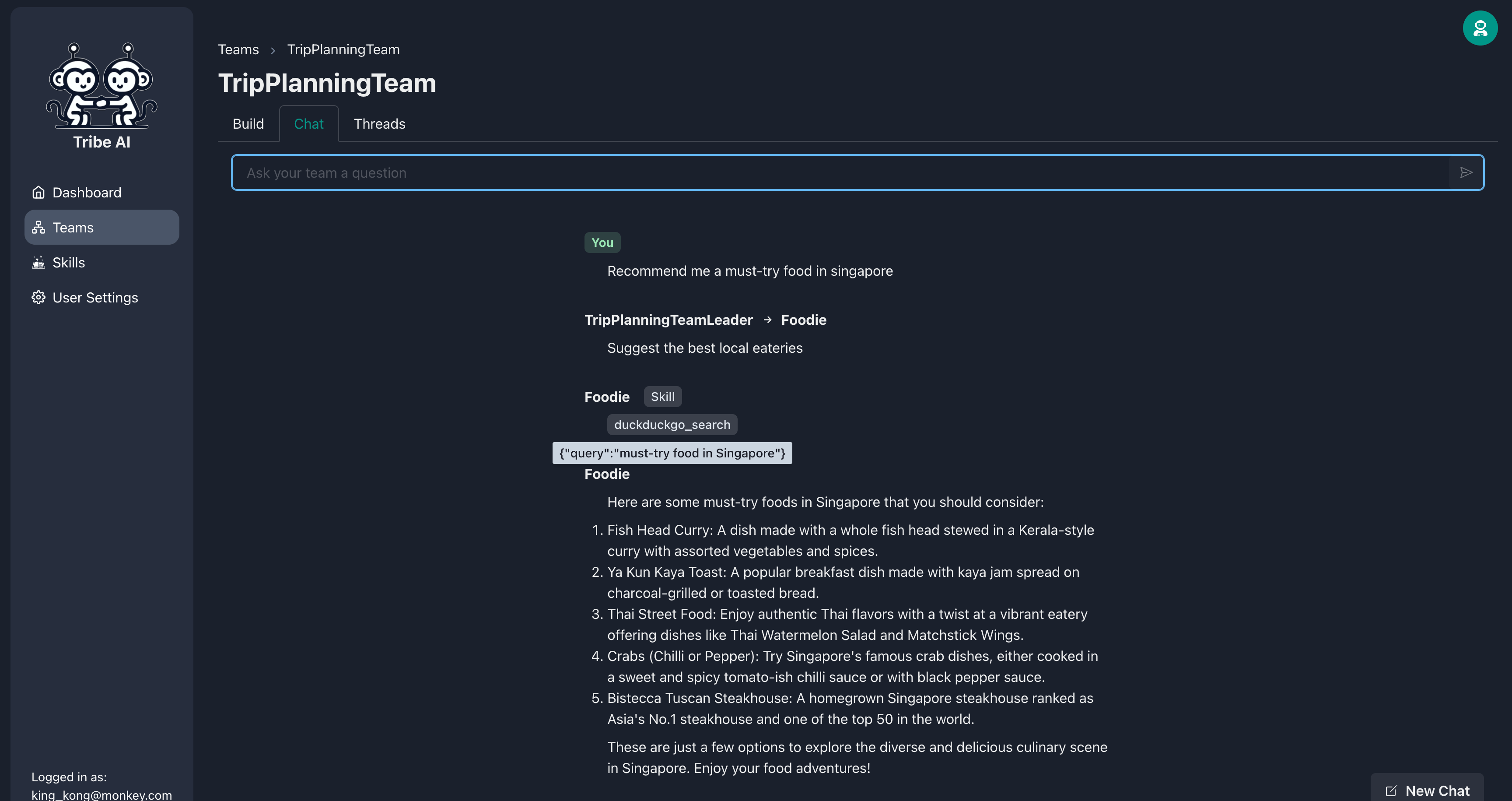
팀원은 일련의 기술을 제공하여 더 많은 일을 할 수 있습니다. 미식가에 기술을 추가하십시오.
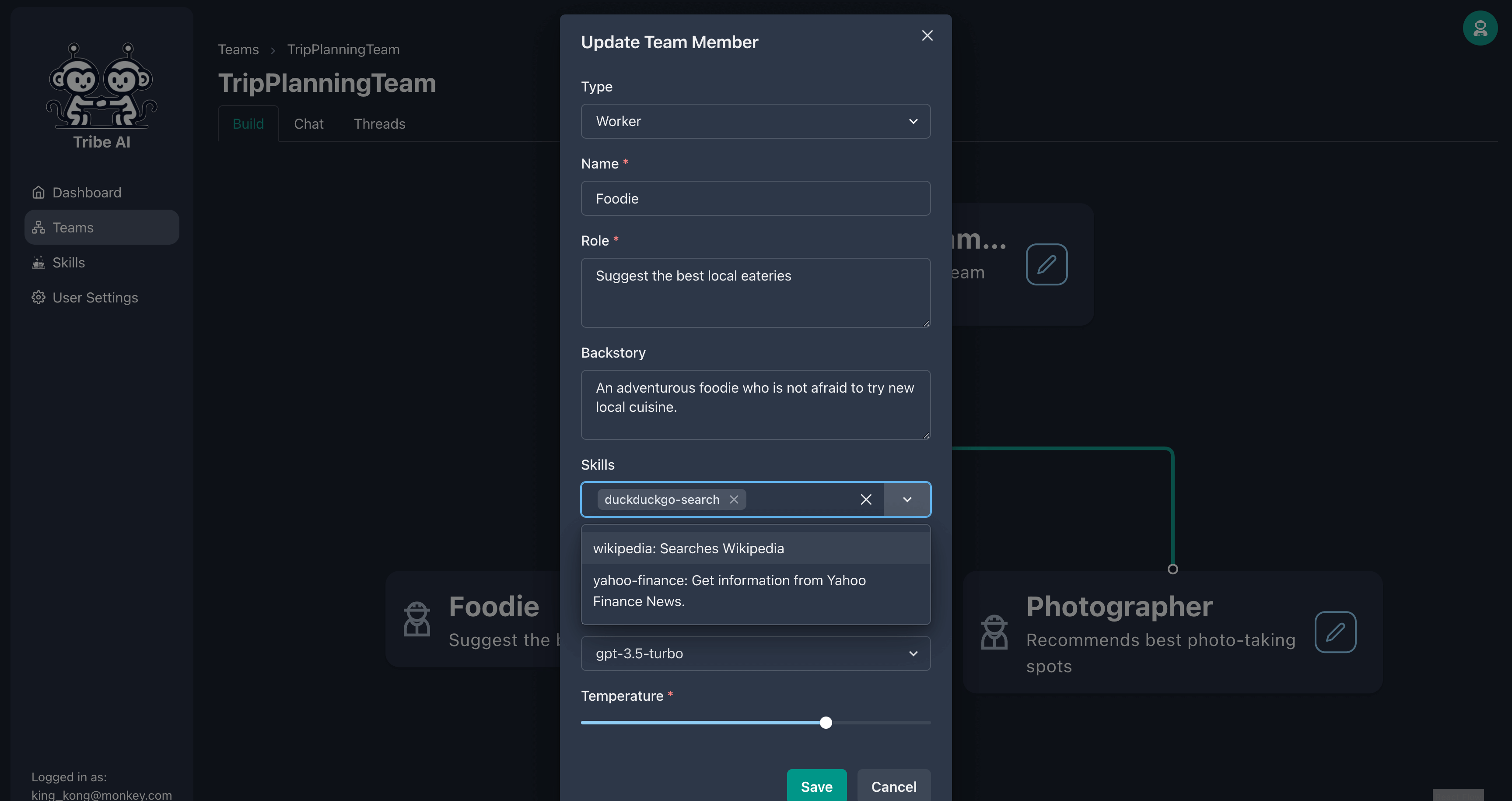
이제 미식가에게 질문을 할 때 웹에서 더 최신 정보를 검색 할 것입니다!
새 팀을 만들고 '순차적'워크 플로를 선택하십시오.
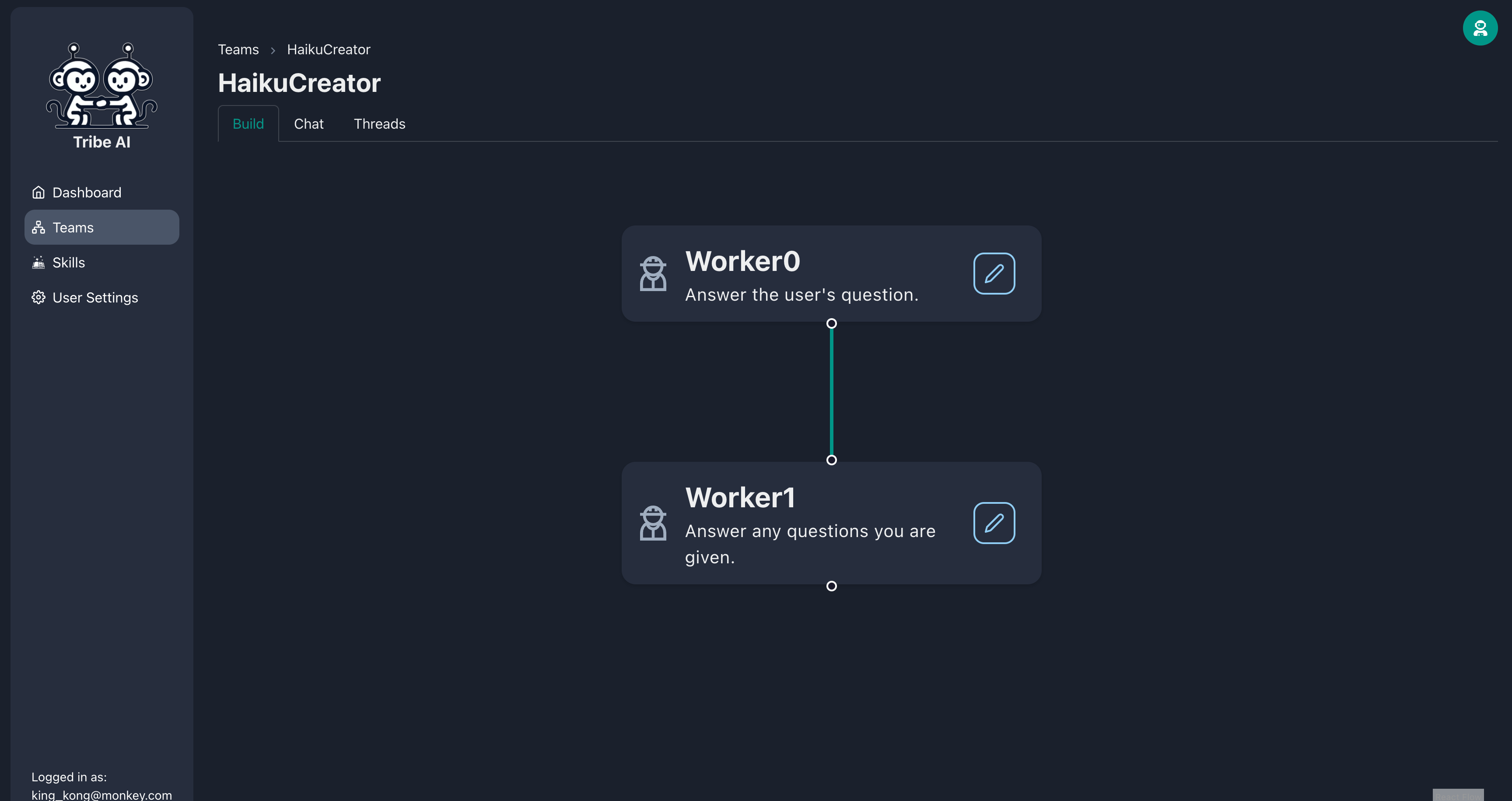
드래그 앤 드롭으로 'Worker0'아래에 다른 팀원을 만듭니다.
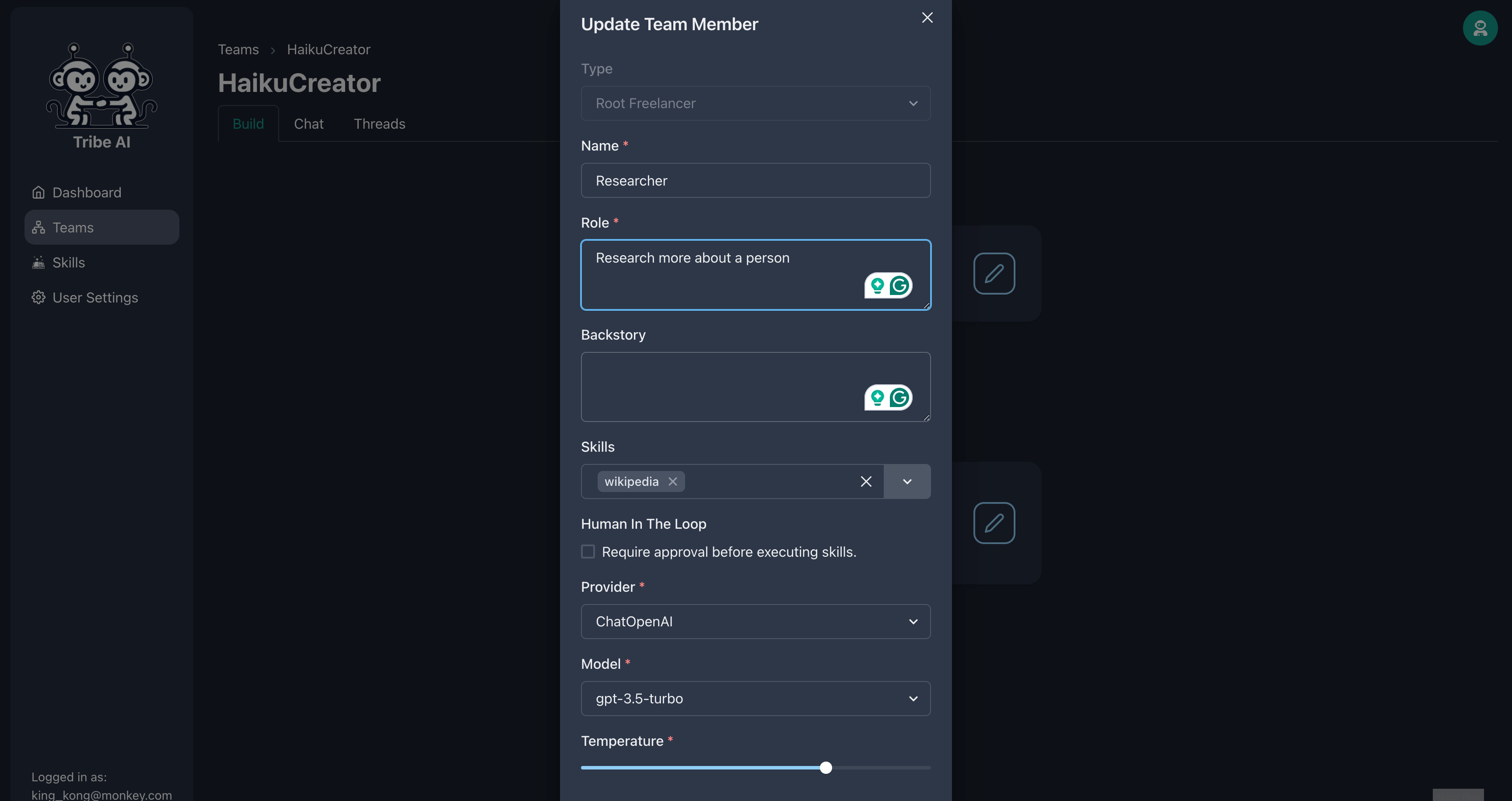
표시된대로 첫 번째 팀원을 업데이트하십시오. 이 팀원에게 'Wikipedia'기술을 제공하십시오.
표시된대로 두 번째 팀원을 업데이트하십시오.
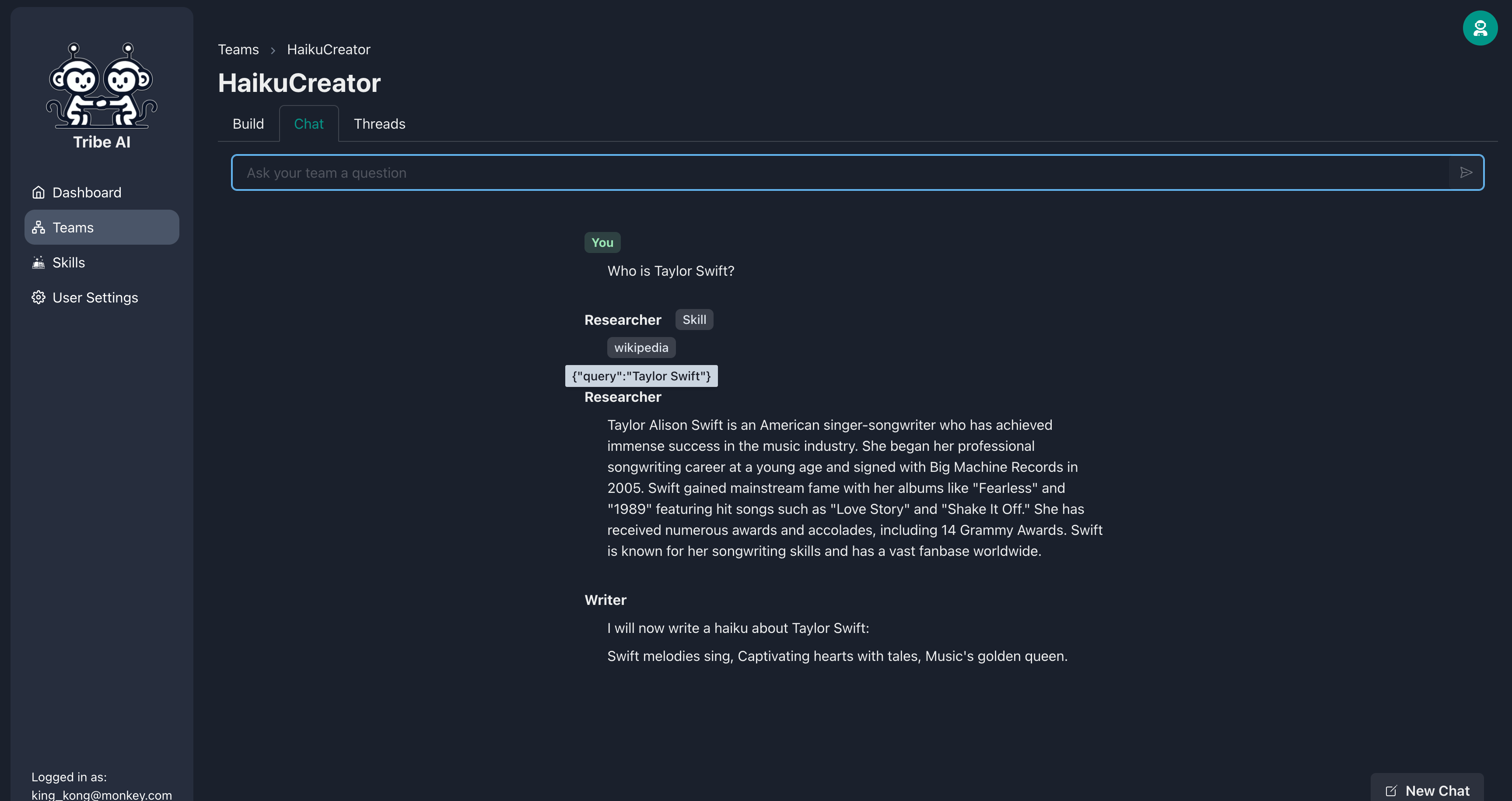
'채팅'탭으로 이동하여 팀에 질문을 보내서 어떻게 응답하는지 확인하십시오. 연구원은 Wikipedia를 사용하여 연구를 수행 할 것입니다. 아주 멋지다!
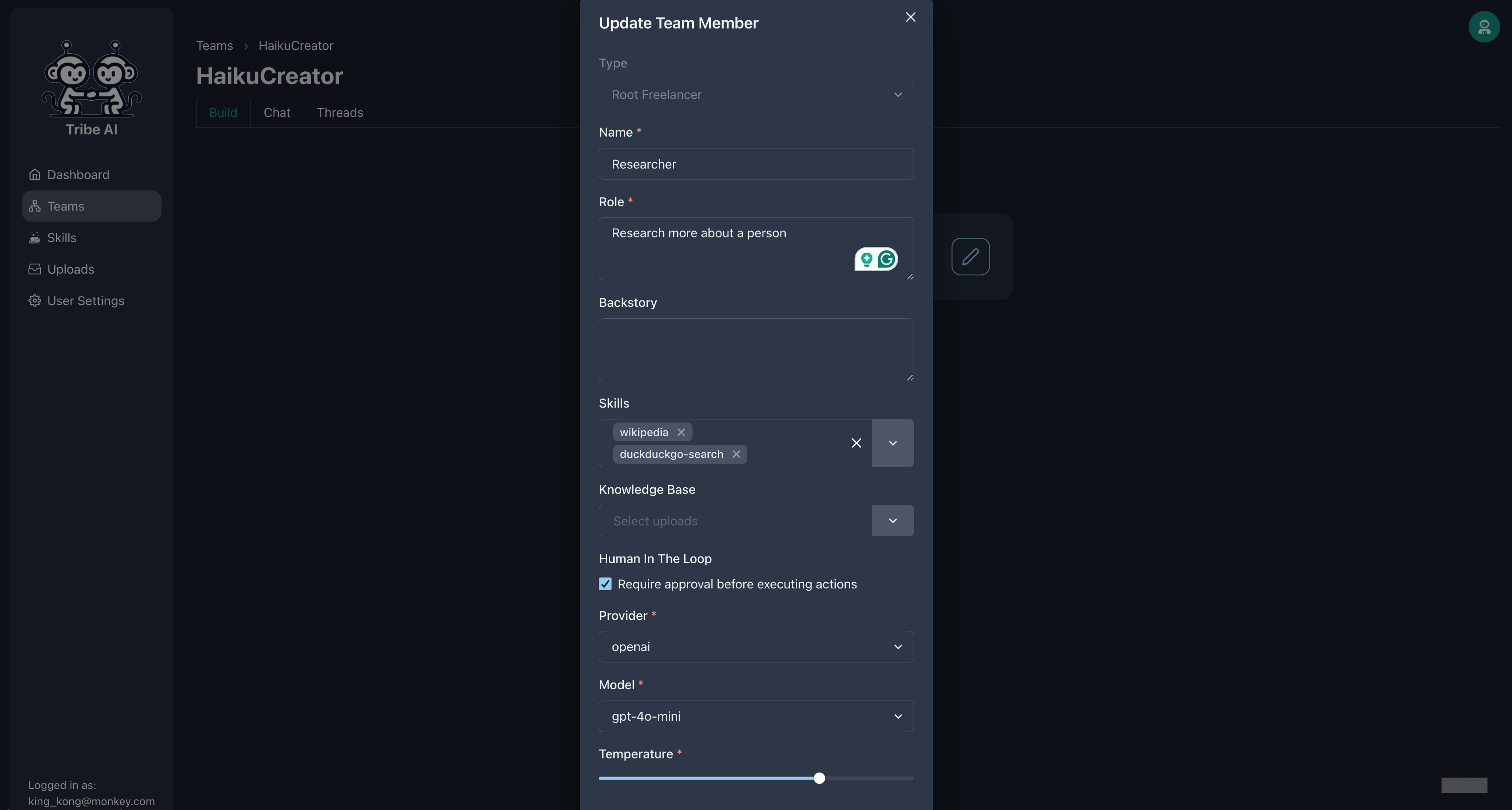
팀 구성원이 기술을 실행하기 전에 승인을 기다리도록 요구할 수 있습니다. 'Duckduckgo-Search'기술을 추가하고 연구원에서 '승인 필요'를 선택하십시오.
이제 연구원이 기술을 실행하기 전에 승인을 요청할 것입니다. 연구원의 검색이 당신이 원하는 것이 아닌 경우, 행동을 거부하고 방향을 제공 할 수있는 선택적인 메시지를 포함하십시오.
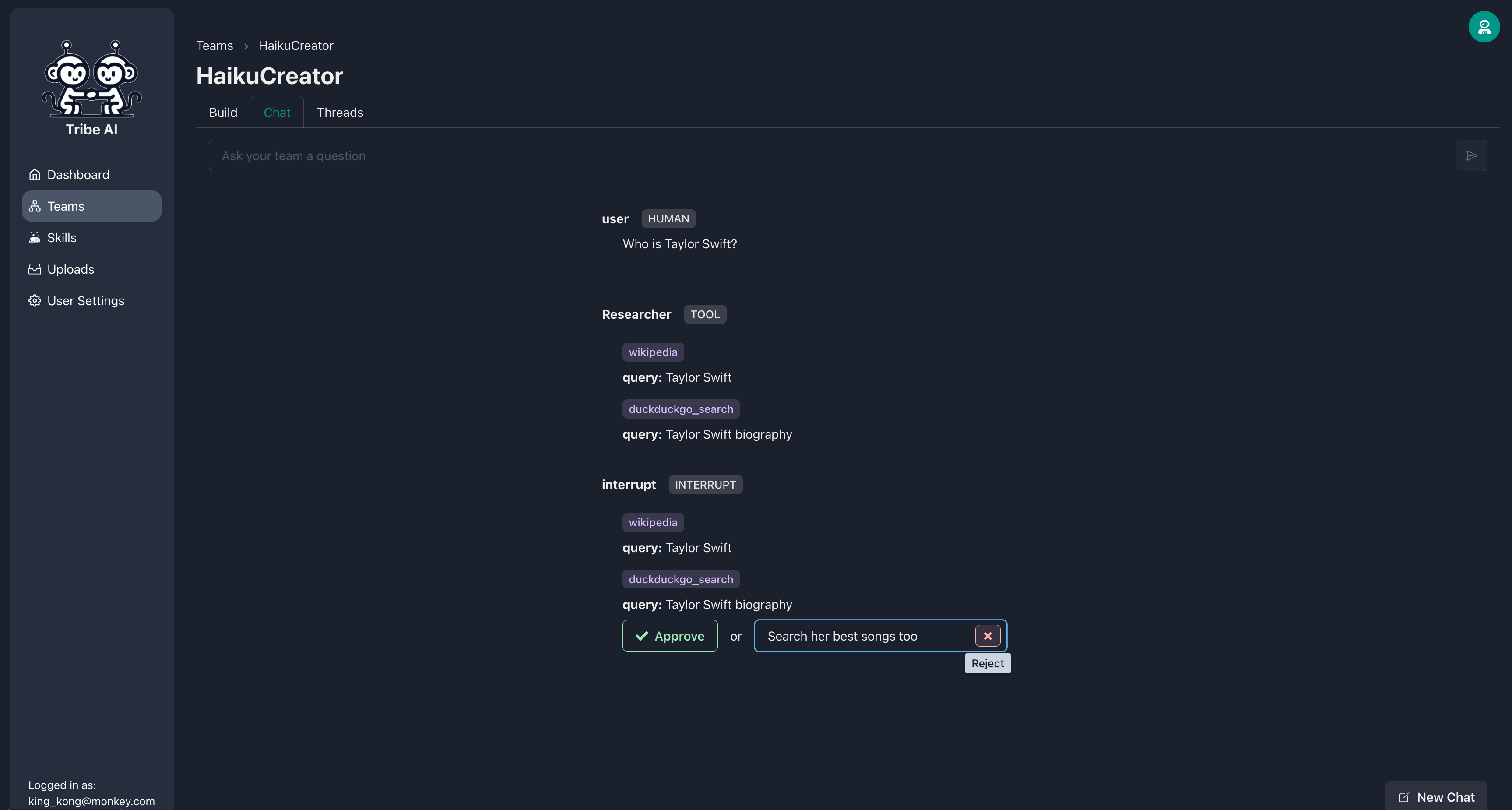
연구원이 요구 사항을 충족하도록 검색을 조정하면 조치를 승인 할 수 있습니다. 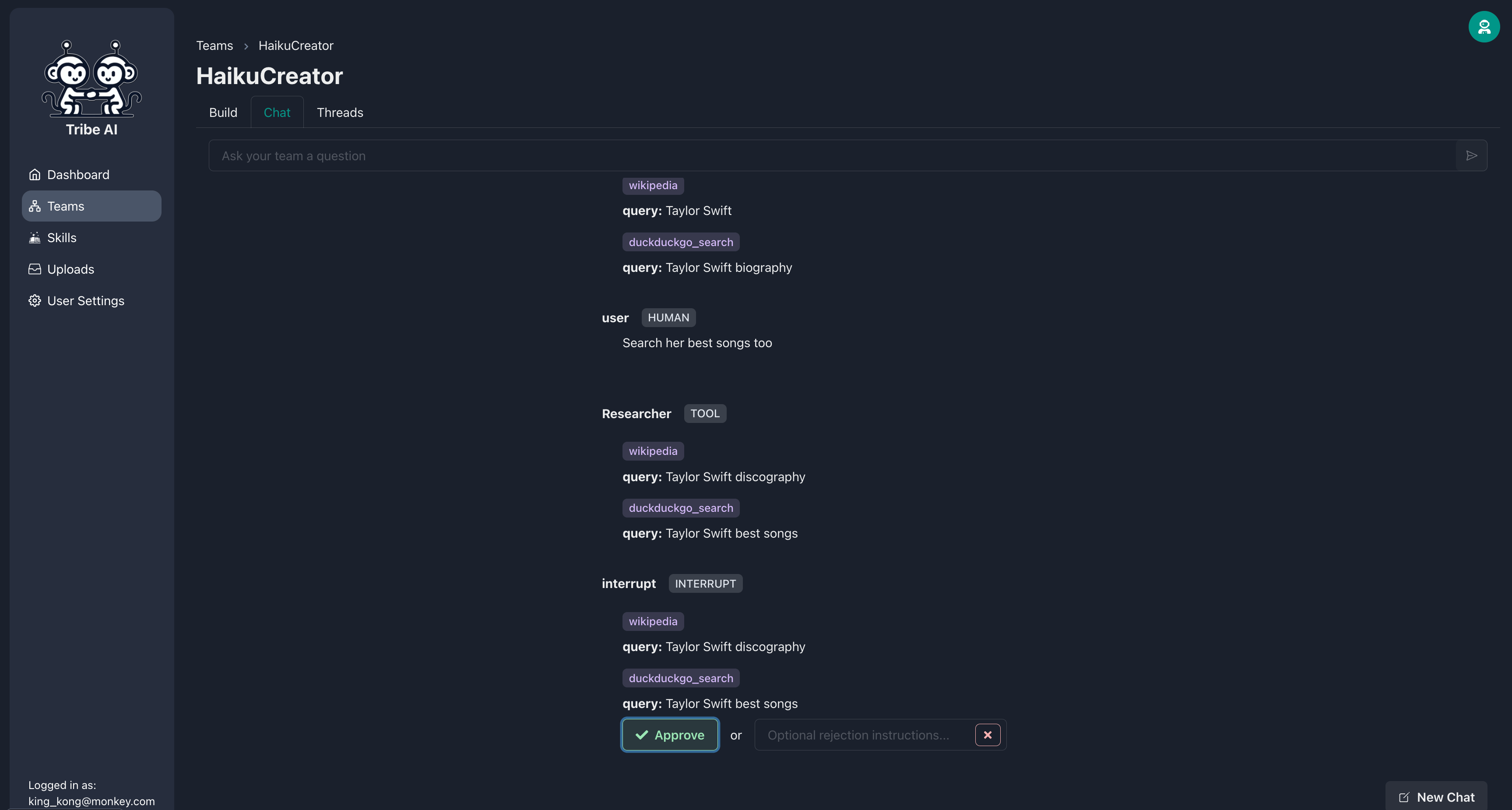
그런 다음 연구원은 지시에 따라 기술을 실행합니다. 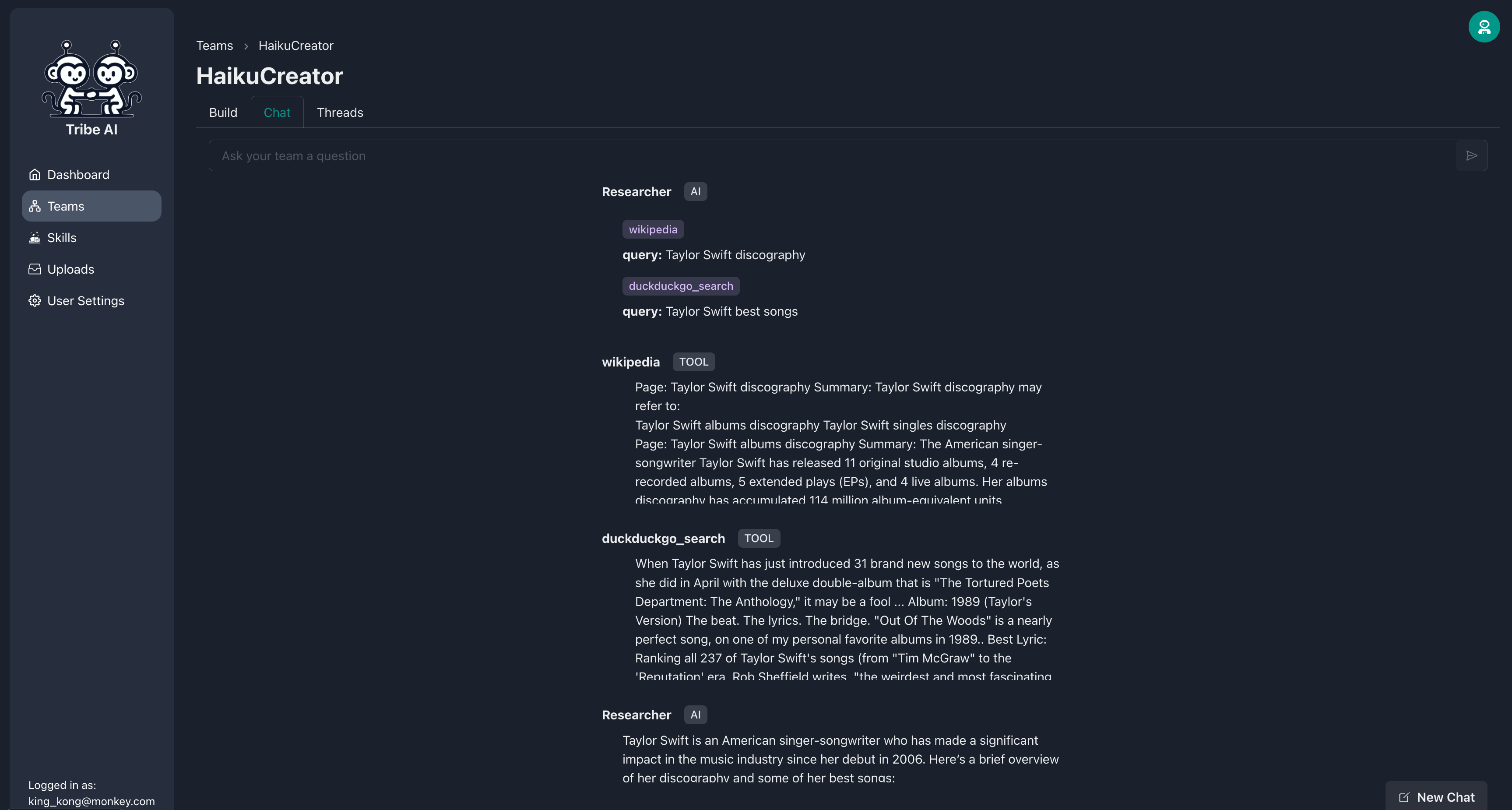
Tribe는 공개적이며 지역 사회의 공헌을 환영합니다! 시작하려면 기여 가이드를 확인하십시오.
기여하는 몇 가지 방법 :
파일 release-notes.md를 확인하십시오.
Tribe는 MIT 라이센스의 조건에 따라 라이센스가 부여됩니다.


