tribe
v0.7.6

マルチエージェントチームを迅速に構築および調整するための低コードツール
警告
このプロジェクトは現在、激しい開発中です。大幅な変更が発生する可能性があることに注意してください。
「二人の心は1つより良い」ということわざを聞いたことがありますか?それはエージェントにも当てはまります。 TribeはLanggraphフレームワークを活用して、エージェントのチームを簡単にカスタマイズおよび調整できるようにします。さまざまなものが得意なエージェントの間で厳しいタスクを分割することにより、それぞれが最善のことに集中することができます。これにより、問題の解決がより速く、より良くなります。
チームを組むことで、エージェントはより複雑なタスクを引き受けることができます。ここに彼らが一緒にできることのいくつかの例があります:
そしてもっとたくさん!
展開する前に、少なくとも次の値を変更してください。
SECRET_KEYFIRST_SUPERUSER_PASSWORDPOSTGRES_PASSWORDこれらを秘密から環境変数として渡すことができます(そしてすべきです)。
.envファイルの一部の環境変数には、 changethisのデフォルト値があります。
秘密の鍵でそれらを変更する必要があります。秘密のキーを生成するには、次のコマンドを実行できます。
python -c " import secrets; print(secrets.token_urlsafe(32)) "コンテンツをコピーして、パスワード /シークレットキーとして使用します。そして、それをもう一度実行して、別の安全なキーを生成します。
立ち上がって、数分以内にローカルマシンで始めましょう。
リモートサーバーに部族を展開します。
シーケンシャルワークフローでは、エージェントは整然としたシーケンスに配置され、タスクを次々に実行します。各タスクは、前のタスクに依存する場合があります。これは、決定論的なシーケンスで次々とタスクを完了する場合に役立ちます。
これを使用する場合:
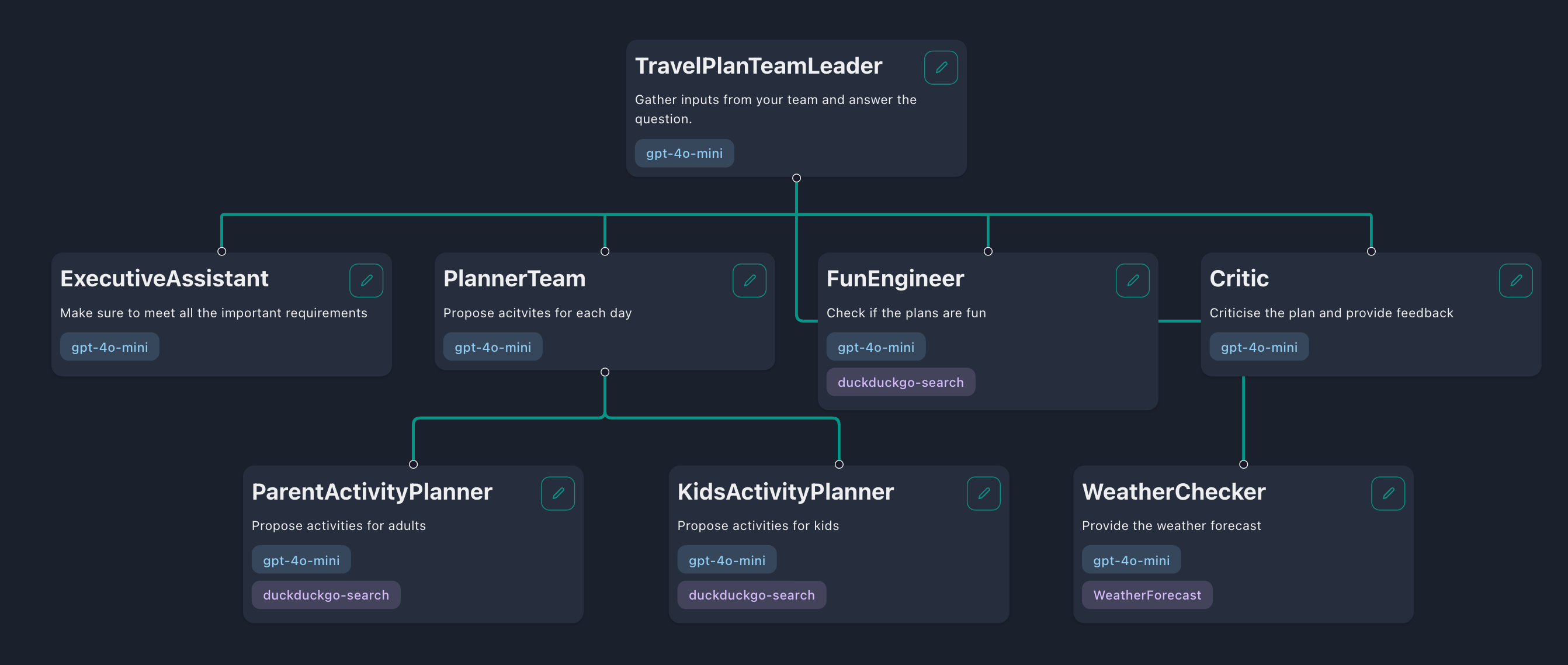
階層的なワークフローでは、エージェントは「チームリーダー」、「チームメンバー」、さらには他の「サブチームリーダー」で構成されるチームのような構造に編成されます。チームリーダーはタスクを小さなタスクに分解し、チームメンバーに委任します。チームメンバーがこれらのタスクを完了した後、彼らの応答はチームリーダーに渡され、チームリーダーはユーザーへの応答を返すか、より多くのタスクを委任することを選択します。
これを使用する場合:
スキルは、世界と対話するためにエージェントを装備できる能力です。たとえば、現在の気象条件を確認したり、最新のニュースをWebで検索するためのスキルをエージェントに提供できます。デフォルトでは、Tribeは3つのスキルを提供します。
おそらく、カスタムスキルを作成することをお勧めします。これは、単純なHTTPリクエストに関数定義を使用するか、コードベースでカスタムスキルを作成することで、2つの方法で実行できます。
スキルがHTTP要求を実行してデータを取得または更新する場合、スキル定義を使用して最も簡単なアプローチです。 Tribeでは、[スキル]タブに移動し、[スキルの追加]ボタンをクリックすることから始めます。その後、スキル定義を提供するように求められ、特定のスキルを実行する方法をエージェントに指示します。この定義は次のように構成する必要があります。
{
"url" : " https://example.com " ,
"method" : " GET " ,
"headers" : {},
"type" : " function " ,
"function" : {
"name" : " Your skill name " ,
"description" : " Your skill description " ,
"parameters" : {
"type" : " object " ,
"properties" : {
"param1" : {
"type" : " integer " ,
"description" : " Description of the first parameter "
},
"param2" : {
"type" : " string " ,
"enum" : [ " option1 " ],
"description" : " Description of the second parameter "
}
},
"required" : [ " param1 " , " param2 " ]
}
}
}| 鍵 | 説明 |
|---|---|
url | API呼び出しのエンドポイントURL。 |
method | リクエストに使用されるHTTPメソッド。 GET 、 POST 、 PUT 、 PATCH 、またはDELETEことができます。 |
headers | リクエストに含めるHTTPヘッダー。 |
function | スキルに関する詳細が含まれています。 |
function > name | スキルの名前。次のルールに従ってください。文字(AZ、AZ)、数字(0-9)、アンダースコア(_)、およびハイフン( - )のみが許可されます。長さは1〜64文字でなければなりません。 |
function > description | エージェントの使用状況について通知するスキルについて説明します。 |
function > parameters | APIが受け入れるパラメーターの詳細。 |
properties > param | クエリまたはボディパラメーターの名前。メソッドGETために、これはクエリパラメーターになります。 POST 、 PUT 、 PATCH 、 DELETEの場合、リクエスト本体にあります。 |
param > type | string 、 number 、 integer 、またはbooleanを使用できるパラメーターのタイプを指定します。 |
param > description | パラメーターの目的に関するコンテキストを提供します。 |
param > enum | オプションでは、事前定義された値から選択するエージェントを制限する配列を含めます。 |
parameters > required | 必要なパラメーターをリストし、それらが常にAPI要求に含まれるようにします。 |
Langchainを使用すると、単純なHTTPリクエストを超えて拡張されるより複雑なタスクを使用すると、より高度なツールを開発できます。これらのツールをThe Tribeに統合することで、 managed_skills辞書に追加できます。実用的な例については、デモ計算機ツールを参照してください。 Langchainツールを作成する方法を学ぶには、ドキュメントを参照してください。
新しいツールを作成した後、アプリケーションを再起動して、ツールがデータベースに適切にロードされていることを確認します。同様に、ツールを削除する必要がある場合は、 managed_skills辞書から削除し、アプリケーションを再起動してデータベースから削除されるようにするだけです。この方法で作成されたツールは、アプリケーションのすべてのユーザーが利用できることに注意してください。
Ragは、追加のデータでエージェントの知識を強化するための手法です。エージェントは幅広いトピックについて推論することができますが、彼らの知識は、訓練された時点までの公開データに限定されています。エージェントにプライベートデータについて推論したい場合は、Tribeを使用すると、データをアップロードし、エージェントの知識ベースに含めるデータを選択できます。これにより、エージェントが選択したデータを推論することができ、専門的な知識を持つさまざまなエージェントを作成できます。
デフォルトでは、TribeはBAAI/bge-small-en-v1.5 OpenAI Ada-002使用しています。ドキュメントが多言語であるか、画像の埋め込みが必要な場合は、別の埋め込みモデルを使用することができます。 .envファイルでDENSE_EMBEDDING_MODEL変更することで、これを簡単に実行できます。
# See the list of supported models: https://qdrant.github.io/fastembed/examples/Supported_Models/
DENSE_EMBEDDING_MODEL=BAAI/bge-small-en-v1.5 # Change this 警告
既存の新しい埋め込みモデルが異なるベクトル寸法の場合、QDRANTコレクションを再現する必要がある場合があります。 http://qdrant.localhost/dashboardのqdrantダッシュボードを介してコレクションを削除できます。したがって、埋め込みモデルがワークフローに最も適していることを事前に計画する方が良いでしょう。
オープンソースモデルは、より安価で実行が容易になりつつあり、閉じたモデルのパフォーマンスと一致するものもあります。プライバシーとコストのメリットのためにそれらを使用することを好むかもしれません。地元で部族を運営していて、オープンソースモデルを使用したい場合は、使いやすさをお勧めします。
ollamaに更新します。llama3.1:8b )をモデル入力フィールドに貼り付けます。http://host.docker.internal:11434で実行され、 https://localhost:11434にマップします。このセットアップにより、部族はデフォルトのオラマホストと通信できます。セットアップが別のホストを使用している場合は、「ベースURL」入力フィールドに新しいホストを指定します。 オラマのライブラリには、さまざまなタスクに適した数百のオープンソースモデルがあります。ユースケースに適したものを選択する方法は次のとおりです。
Llama3.1 、 Mistral Nemo 、 Firefunction V2 、またはCommand-R +などのモデルなど、ツール呼び出しをサポートするモデルを使用します。gemma2やphi3などのモデルを検討することができます。 Ollamaを使用する予定がない場合でも、Openai Chat Completions APIと互換性のあるオープンソースモデルを実行できます。
ステップ:
インストールステップ中に設定した電子メールとパスワードを使用して部族にログインします。
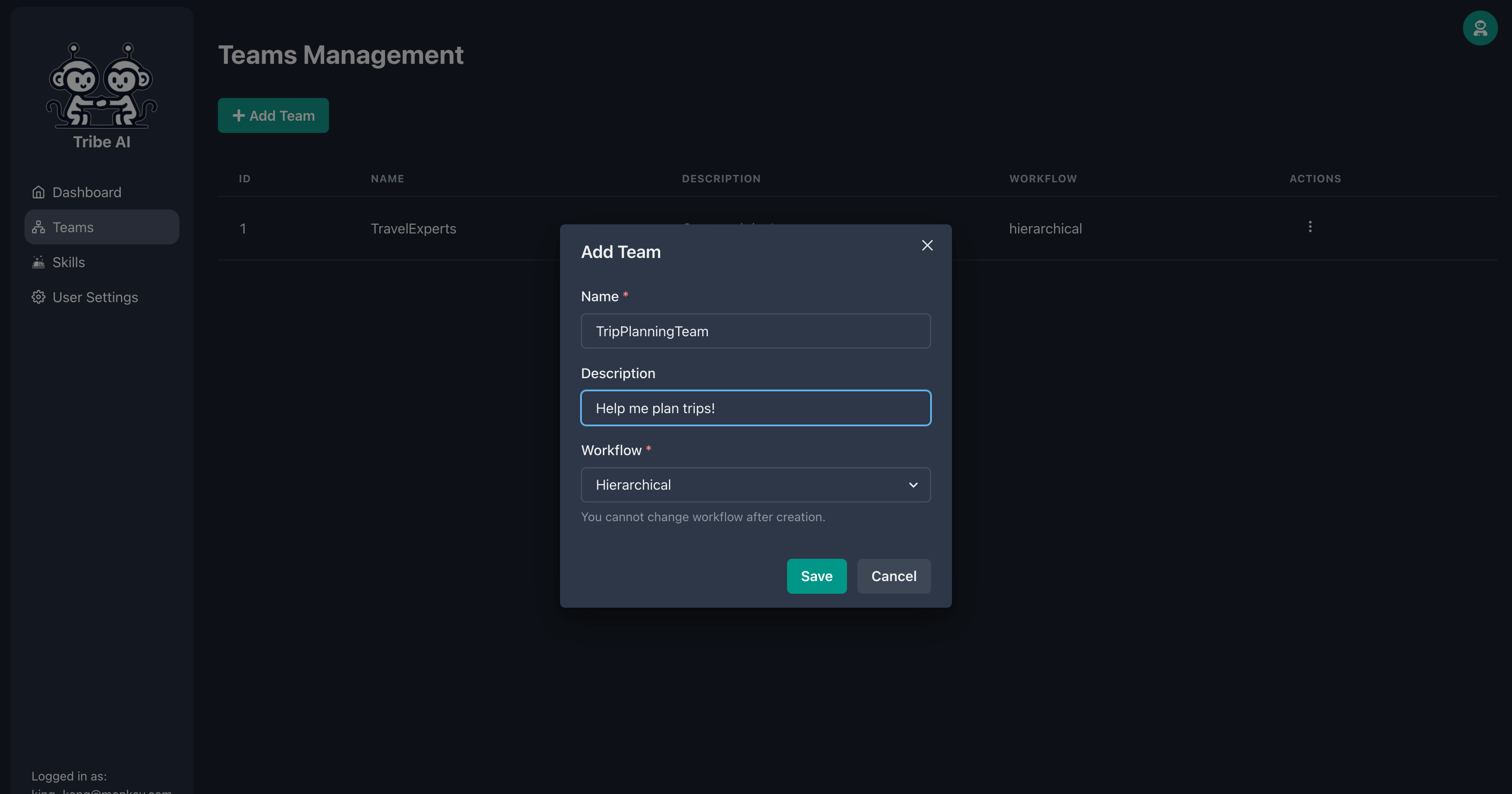
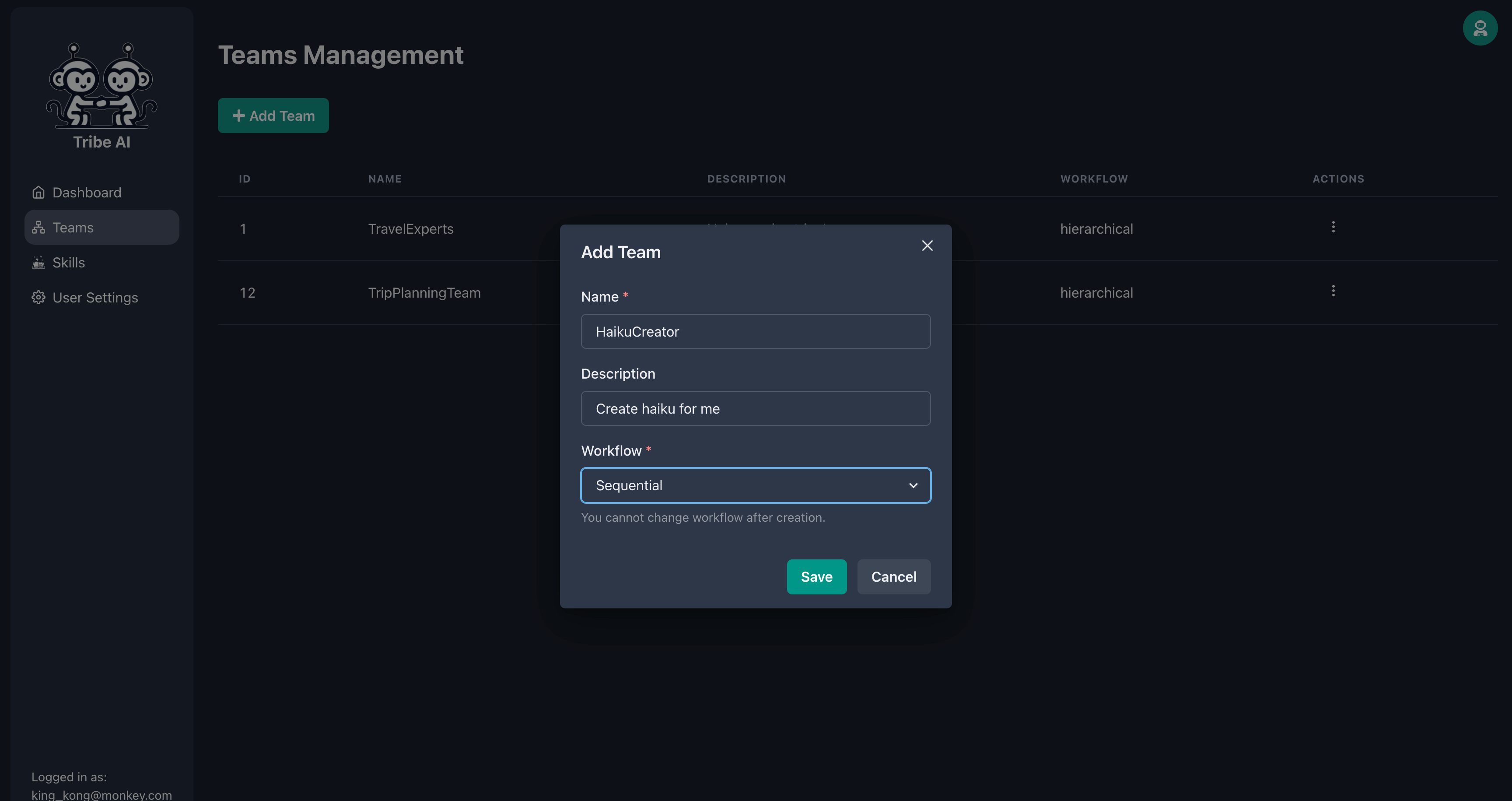
「チーム」ページに移動し、[チームの追加]をクリックします。チームの名前を入力し、[保存]をクリックします。
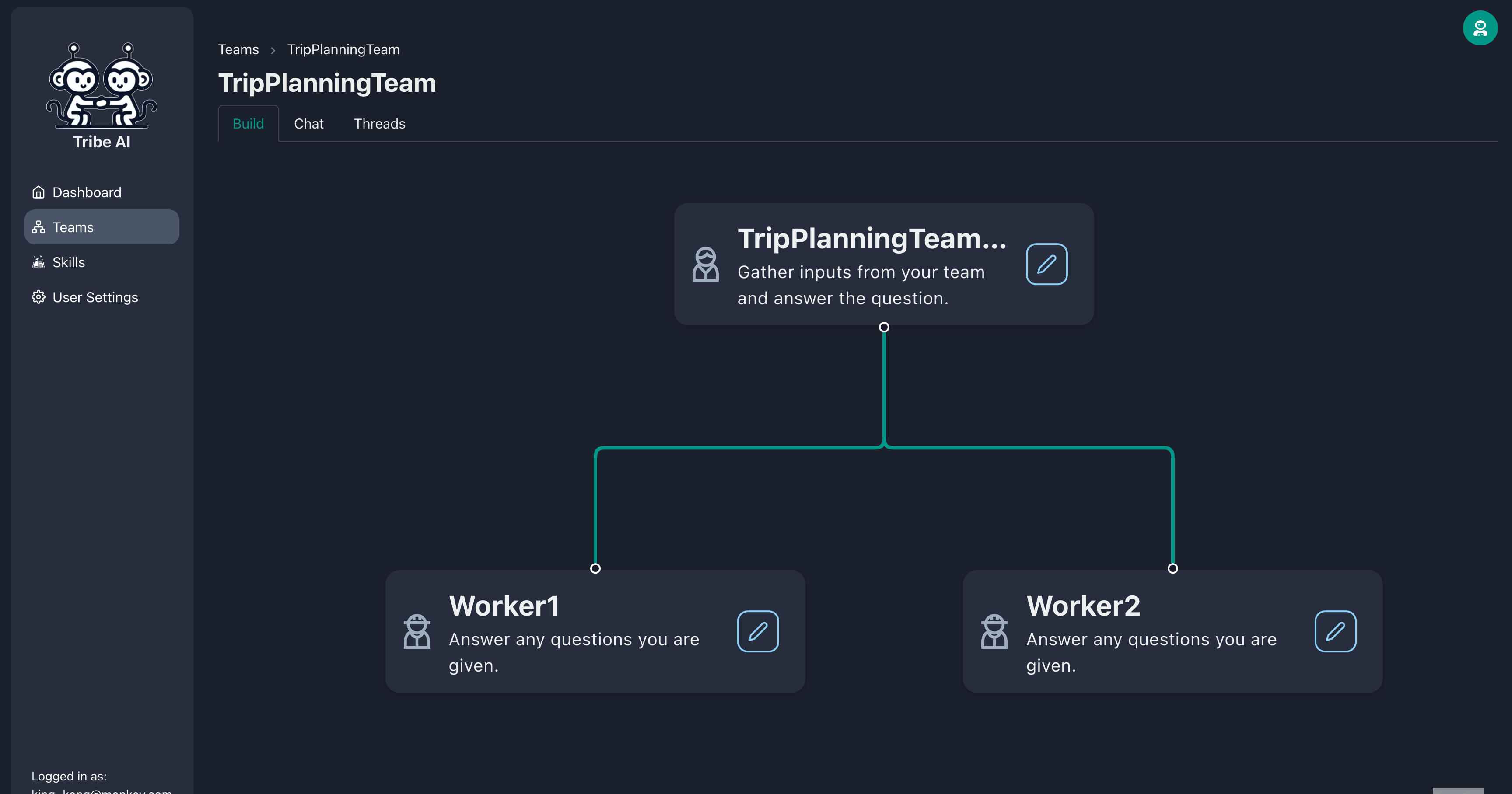
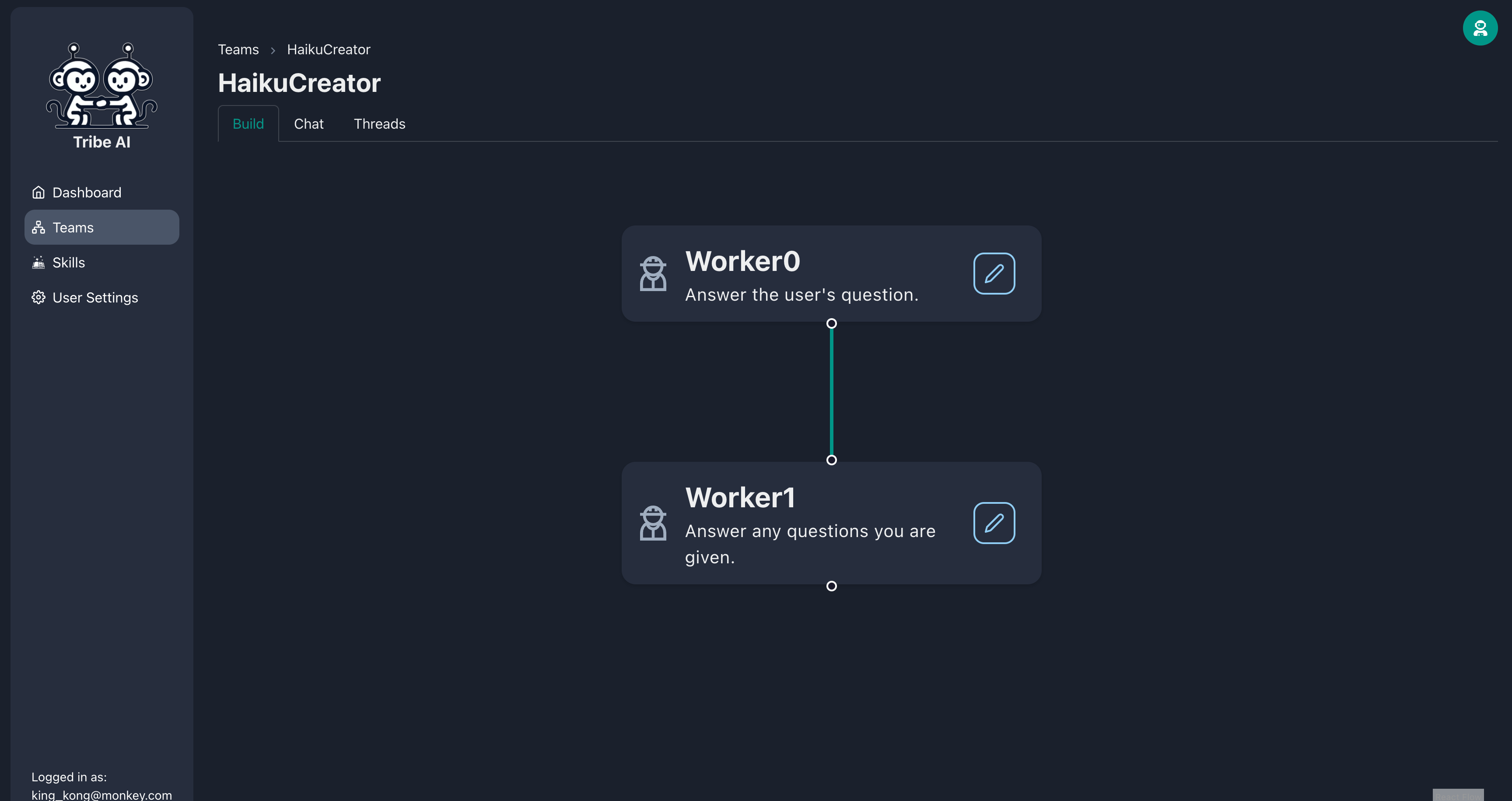
チームリーダーノードのハンドルをドラッグして、2人のチームメンバーを作成します。
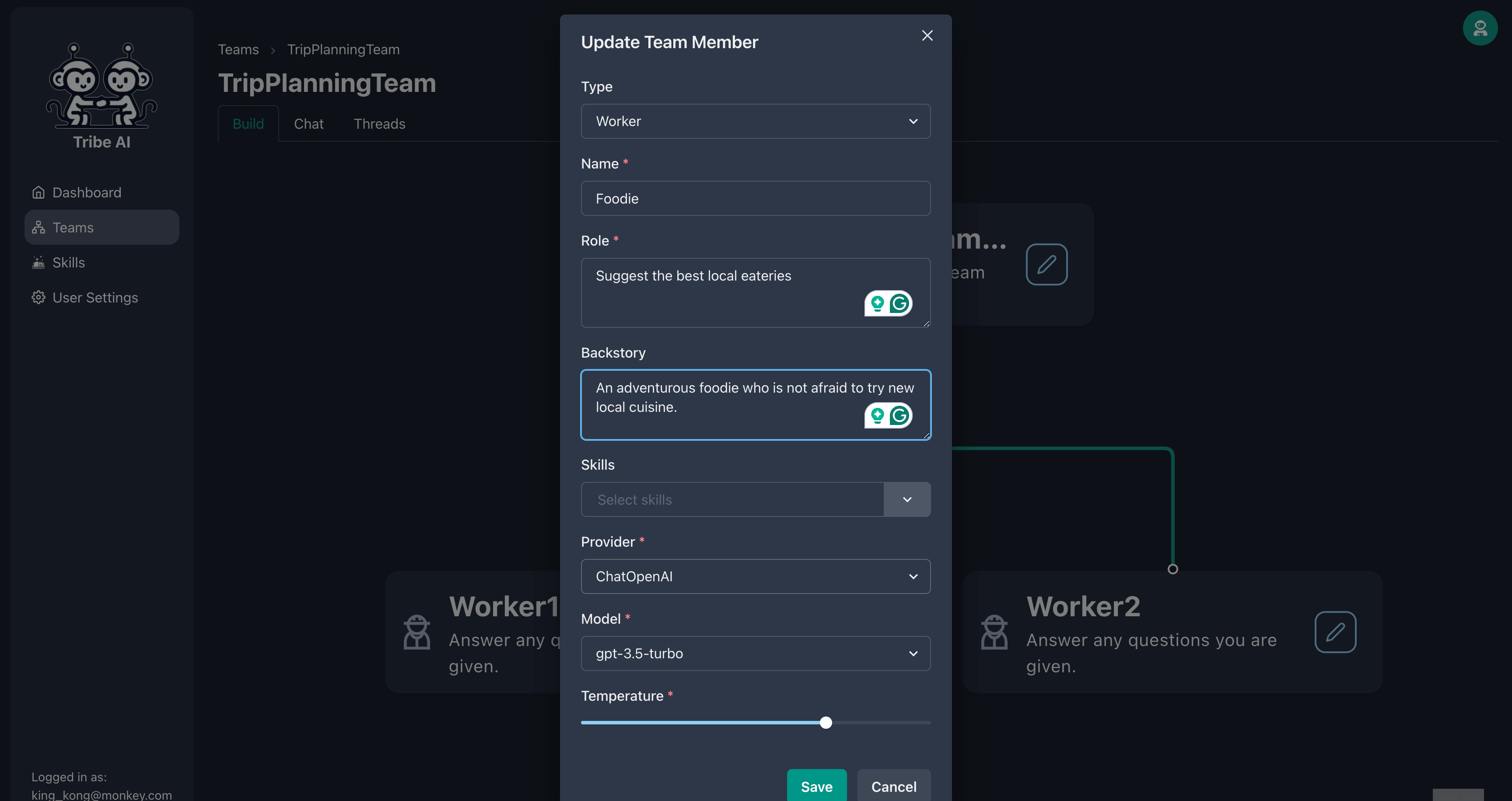
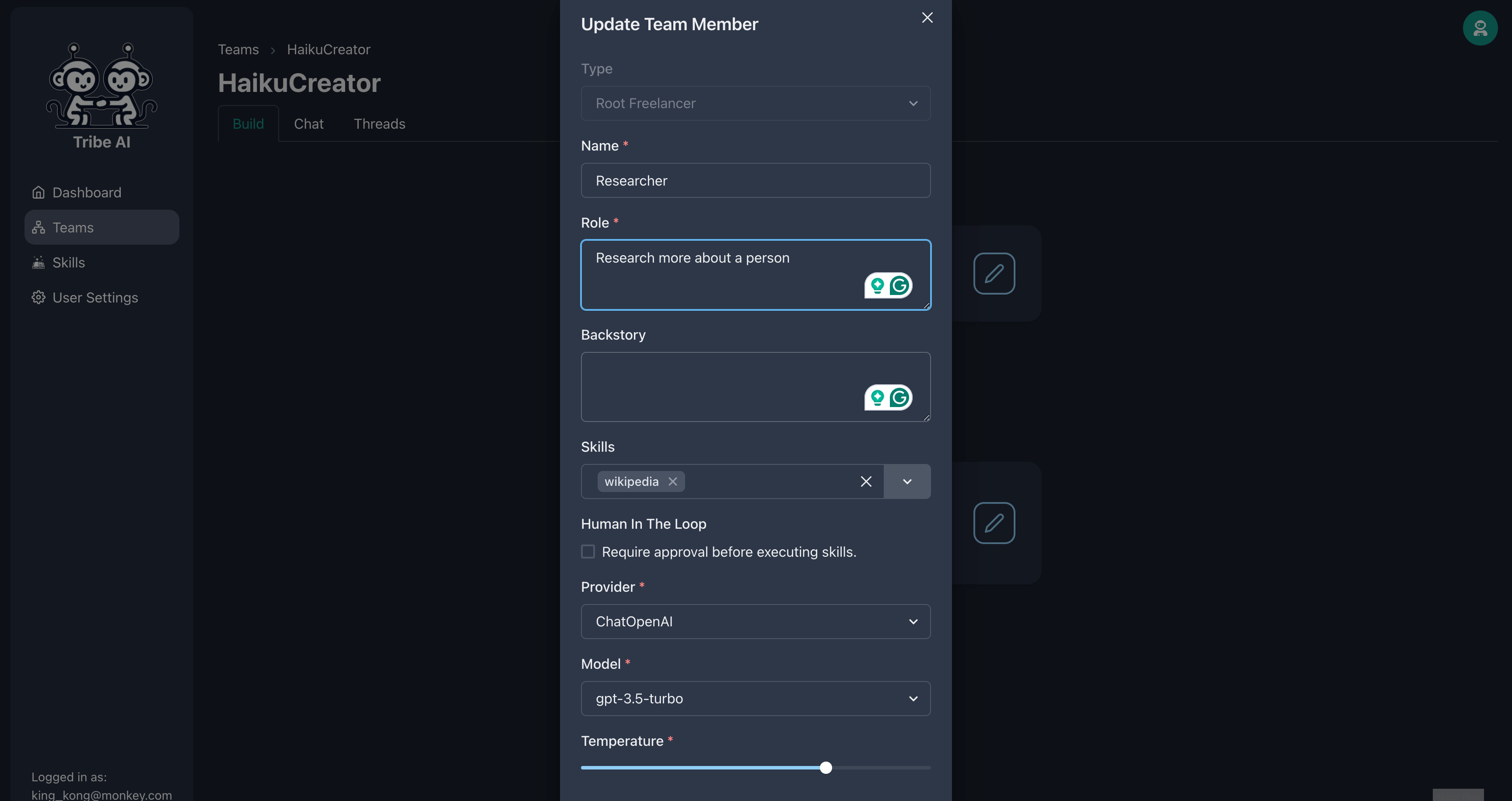
示されているように、最初のチームメンバーを更新します。
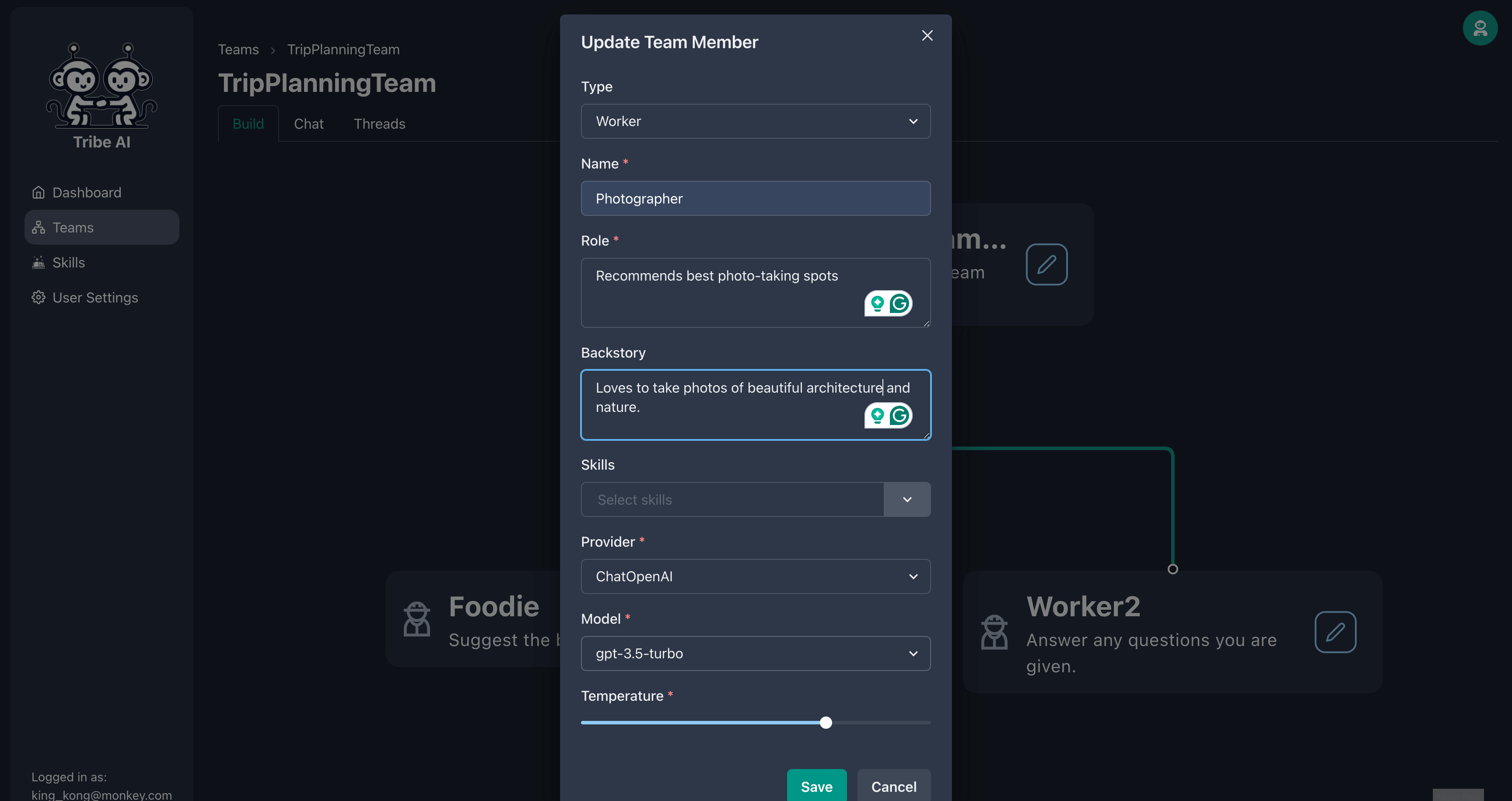
示されているように、2番目のチームメンバーを更新します。
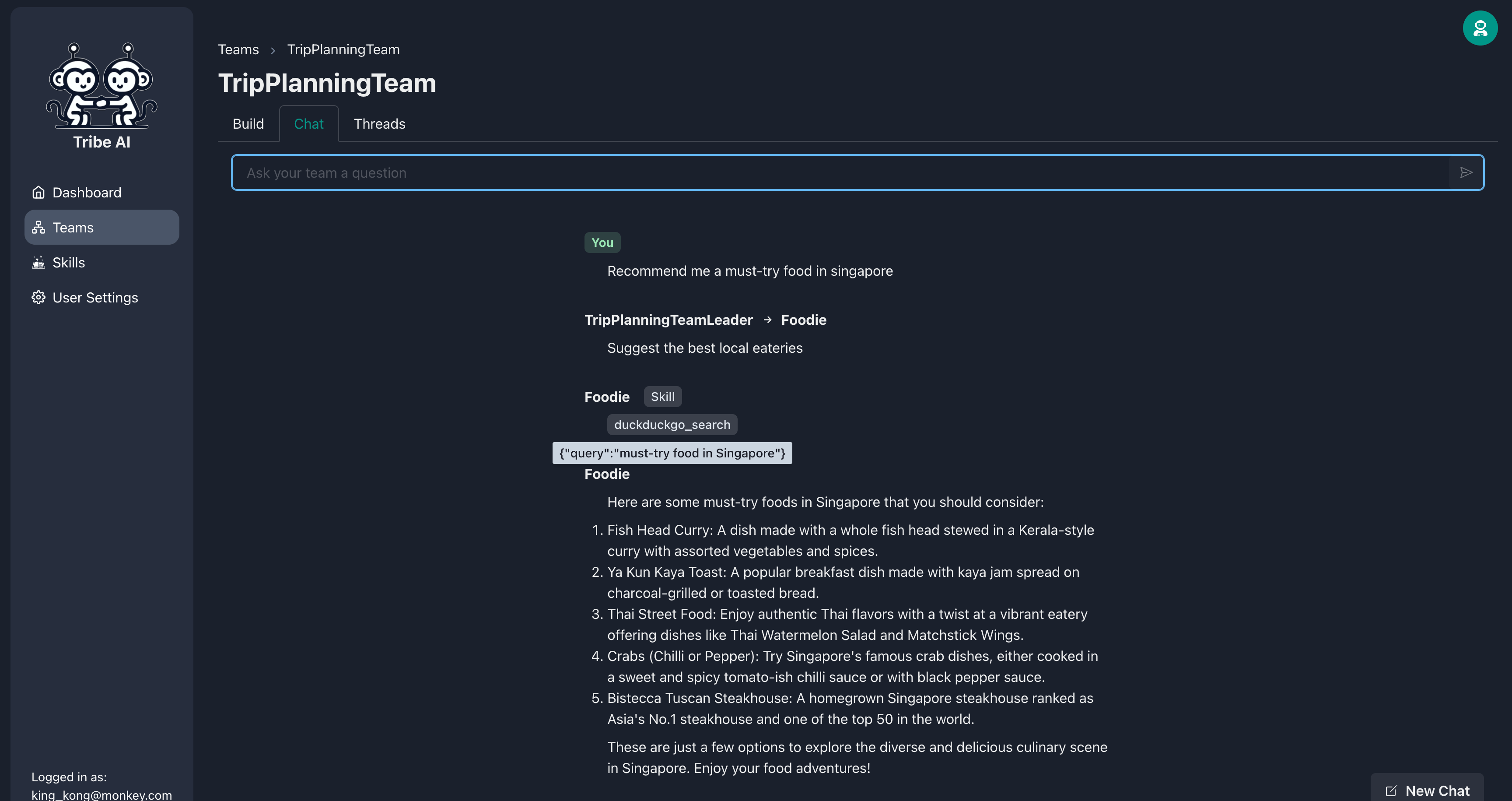
[チャット]タブに移動し、チームに質問を送信して、彼らがどのように反応するかを確認します。
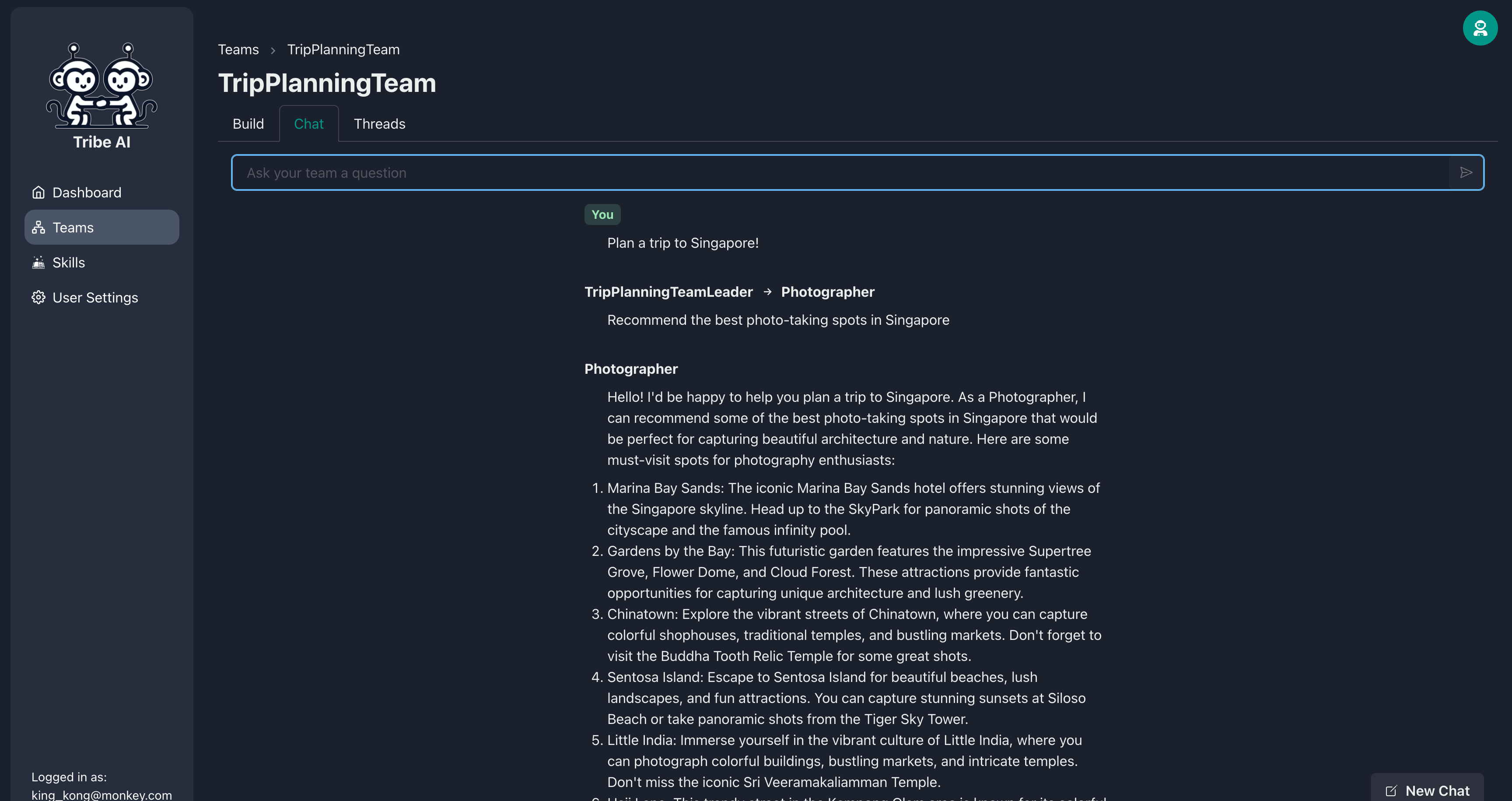
おめでとう!部族で最初のマルチエージェントチームと成功し、コミュニケーションを取りました。
チームメンバーは、一連のスキルを提供することでさらに多くのことを行うことができます。食通にスキルを追加してください。
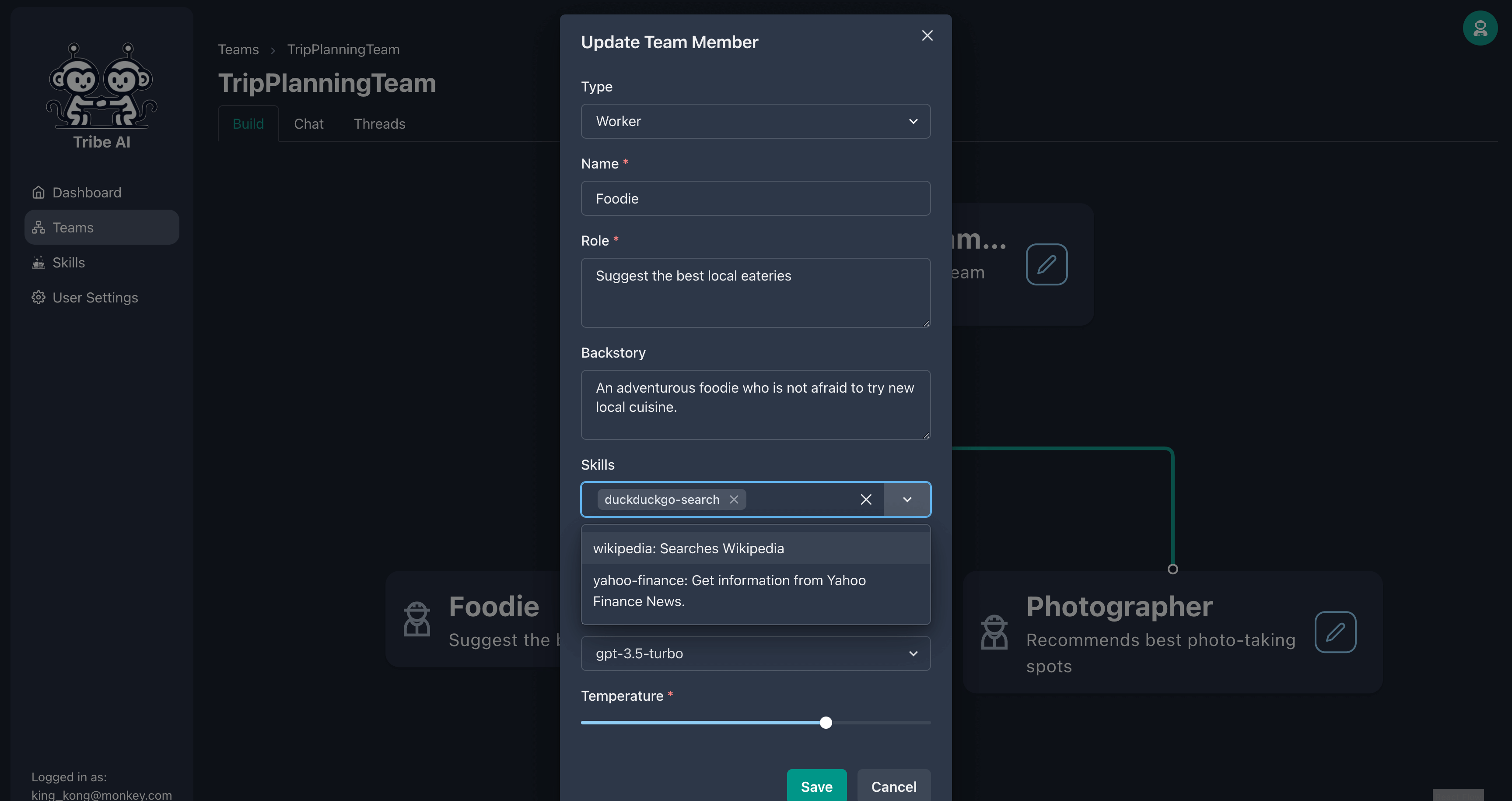
今、あなたがあなたの食通を質問するとき、それはより多くの最新の情報をWebで検索します!
新しいチームを作成し、「シーケンシャル」ワークフローを選択します。
ドラッグアンドドロップして、「Worker0」の下に別のチームメンバーを作成します。
示されているように、最初のチームメンバーを更新します。このチームメンバーに「ウィキペディア」スキルを提供します。
示されているように、2番目のチームメンバーを更新します。
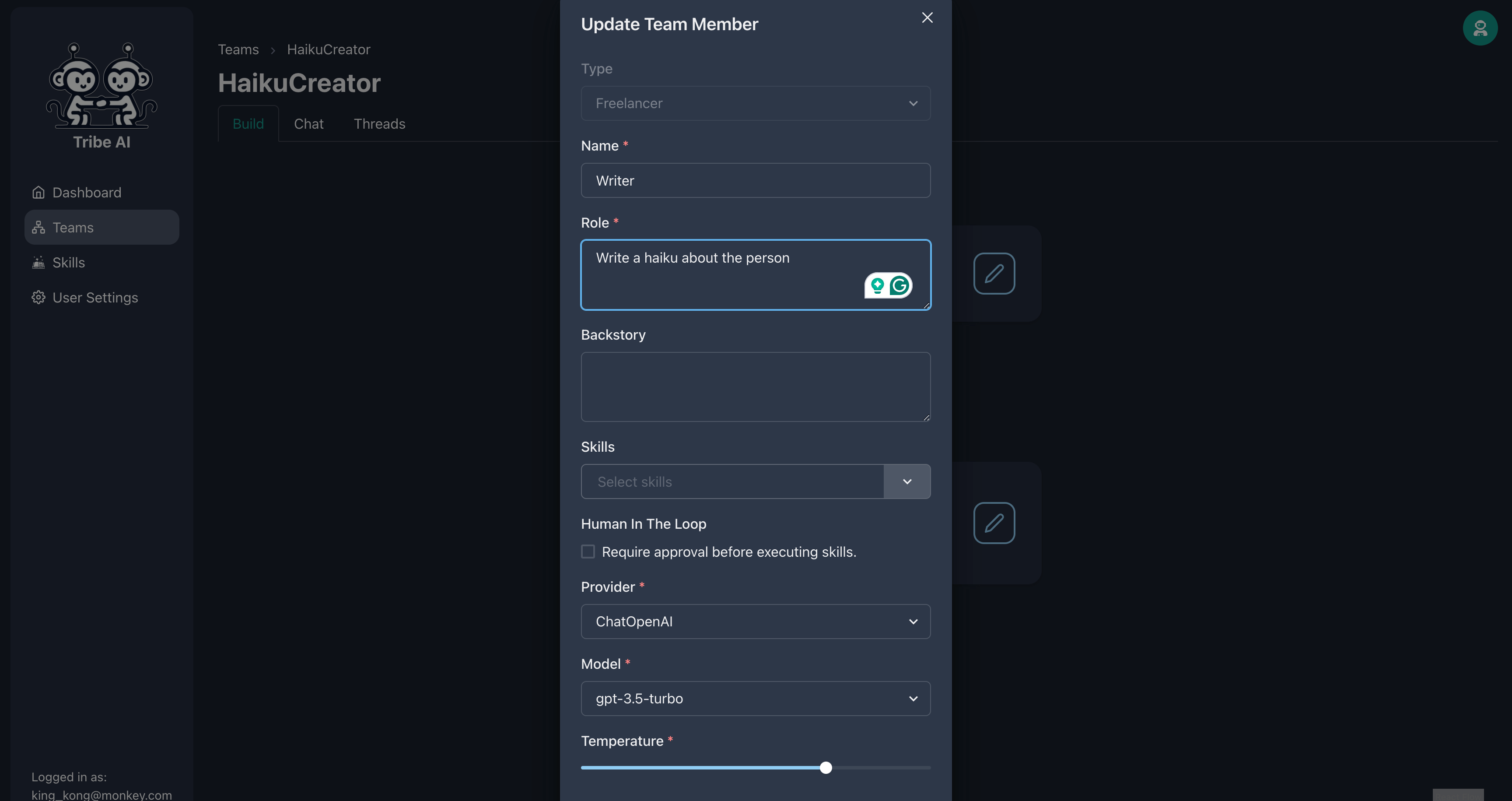
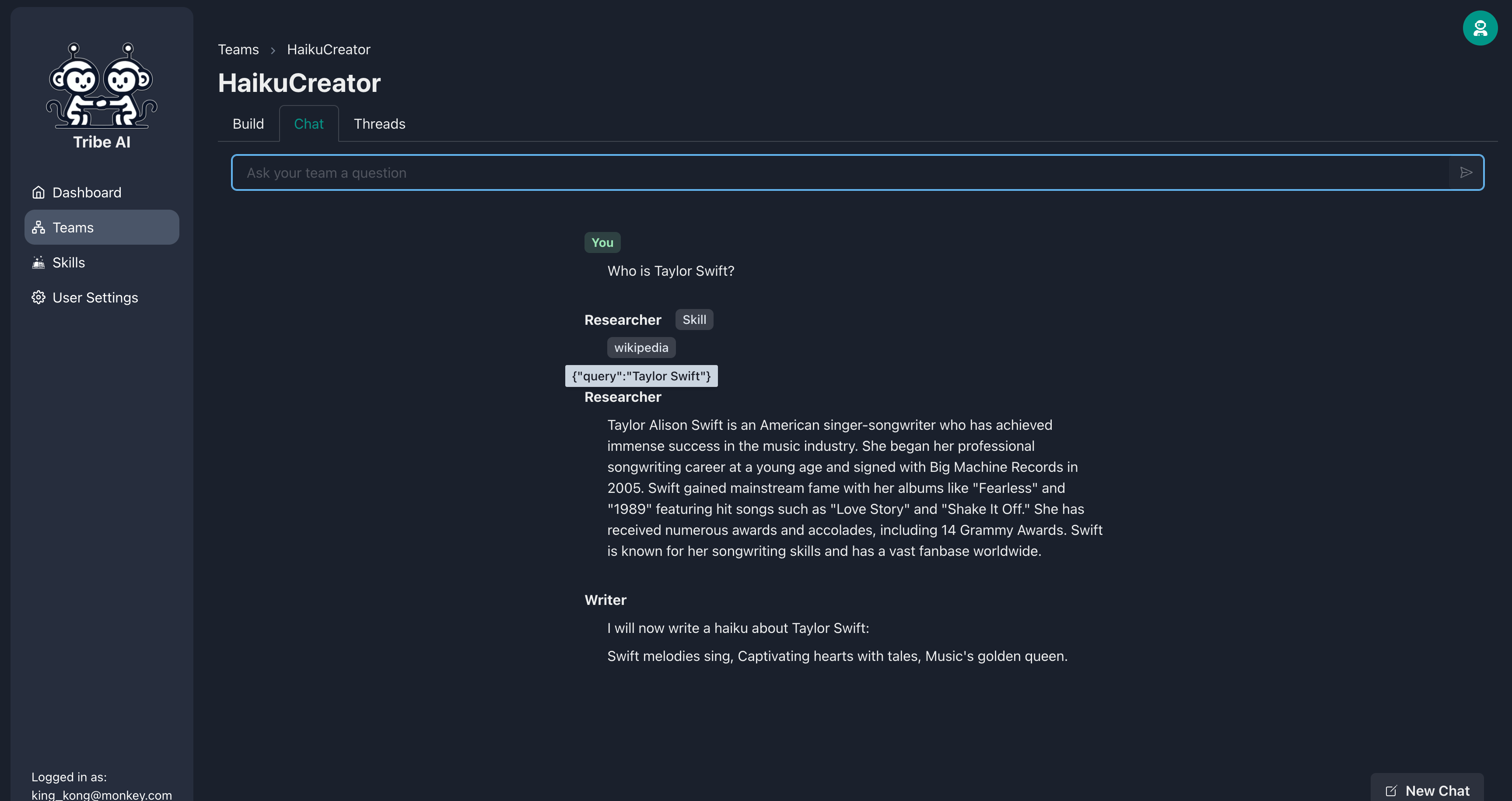
[チャット]タブに移動し、チームに質問を送信して、彼らがどのように反応するかを確認します。研究者はウィキペディアを使用して研究を行うことに注意してください。とてもかっこいい!
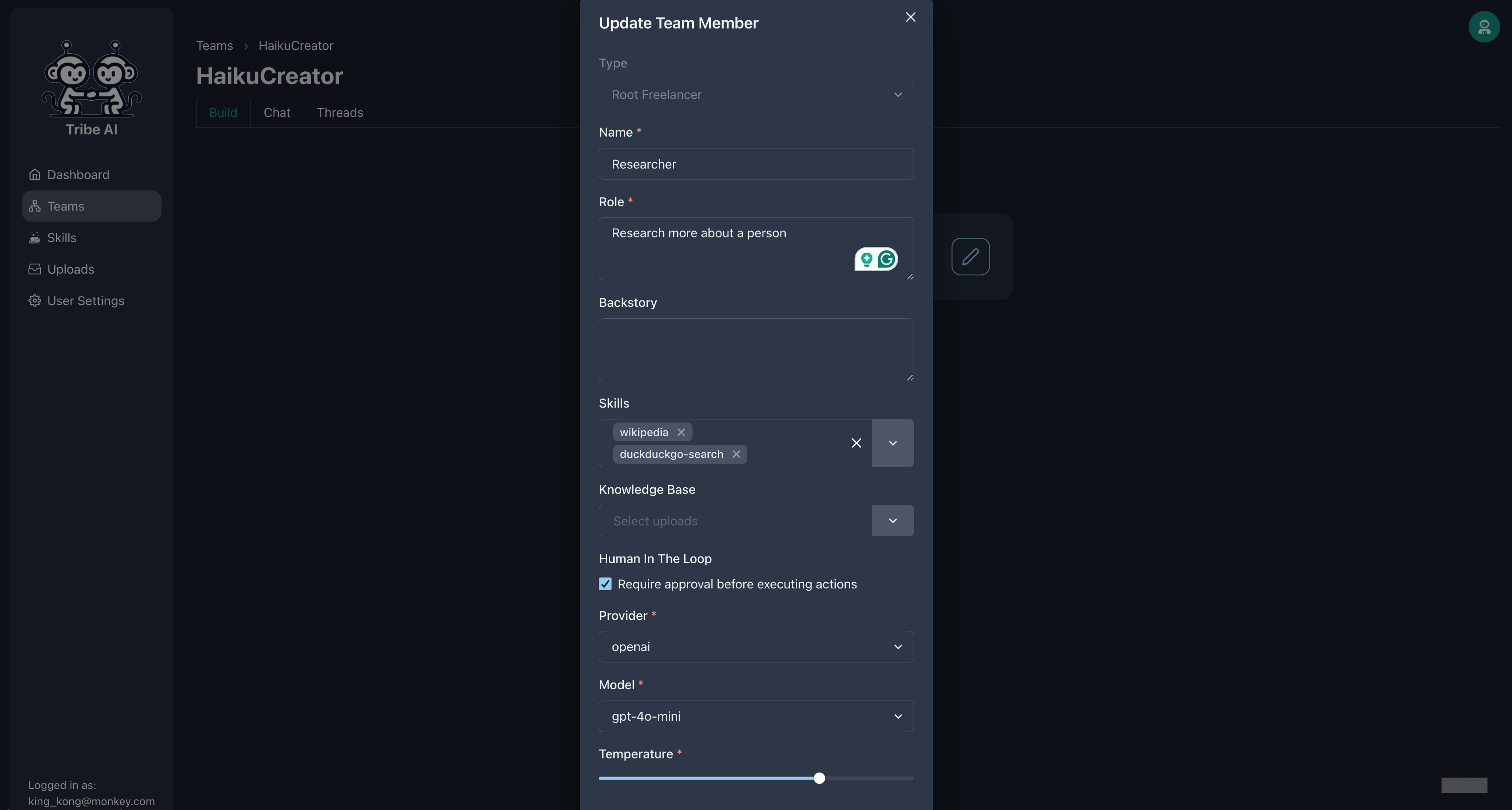
スキルを実行する前に、チームメンバーに承認を待つように要求できます。 「duckduckgo-search」スキルを追加し、研究者に「承認を必要とする」を選択します。
今、研究者がそのスキルを実行する前に、それはあなたの承認を求めます。研究者の検索があなたが望むものではない場合は、アクションを拒否し、オプションのメッセージを含めて指示を提供します。
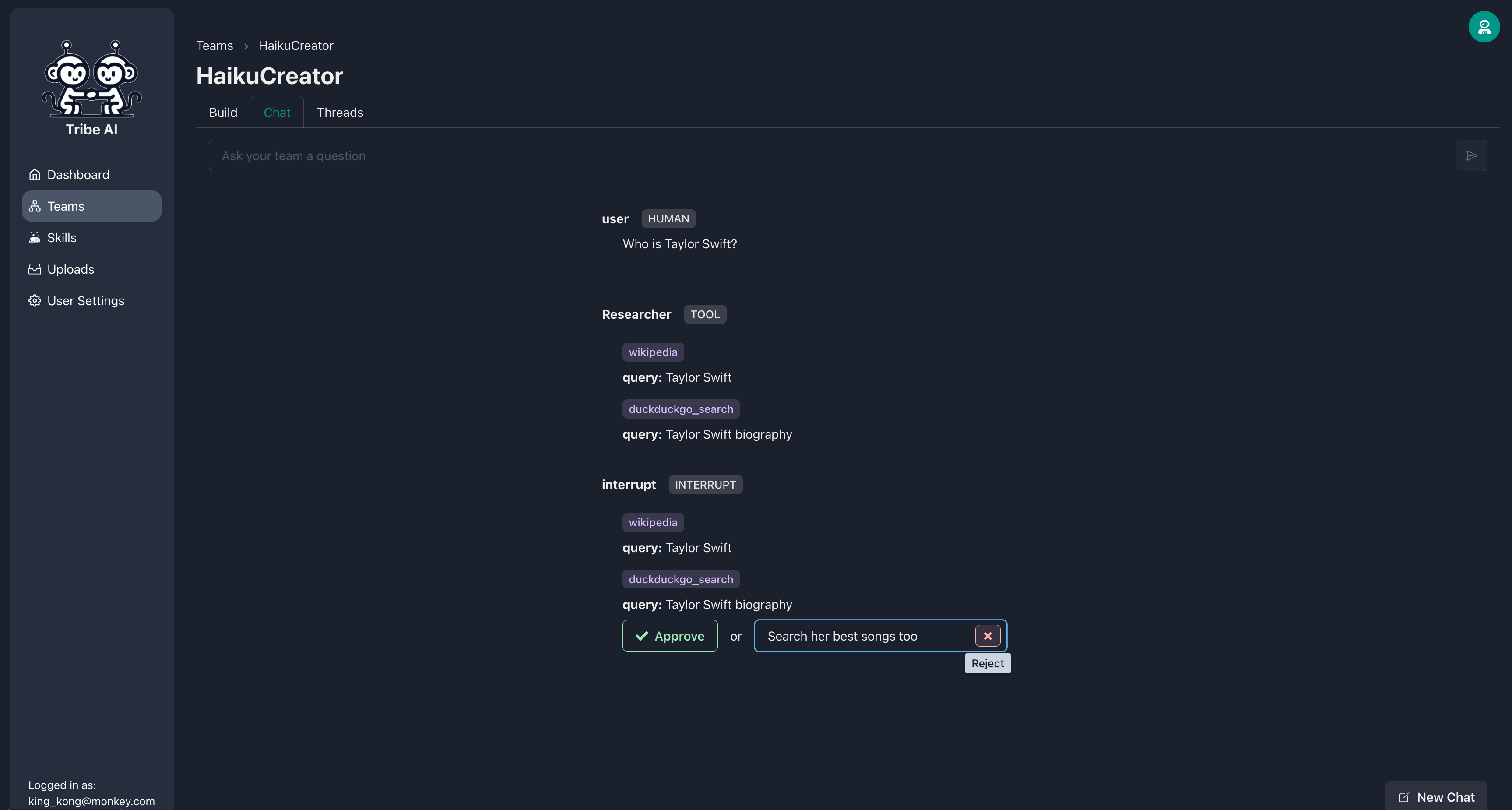
研究者が要件を満たすために検索を調整したら、アクションを承認できます。 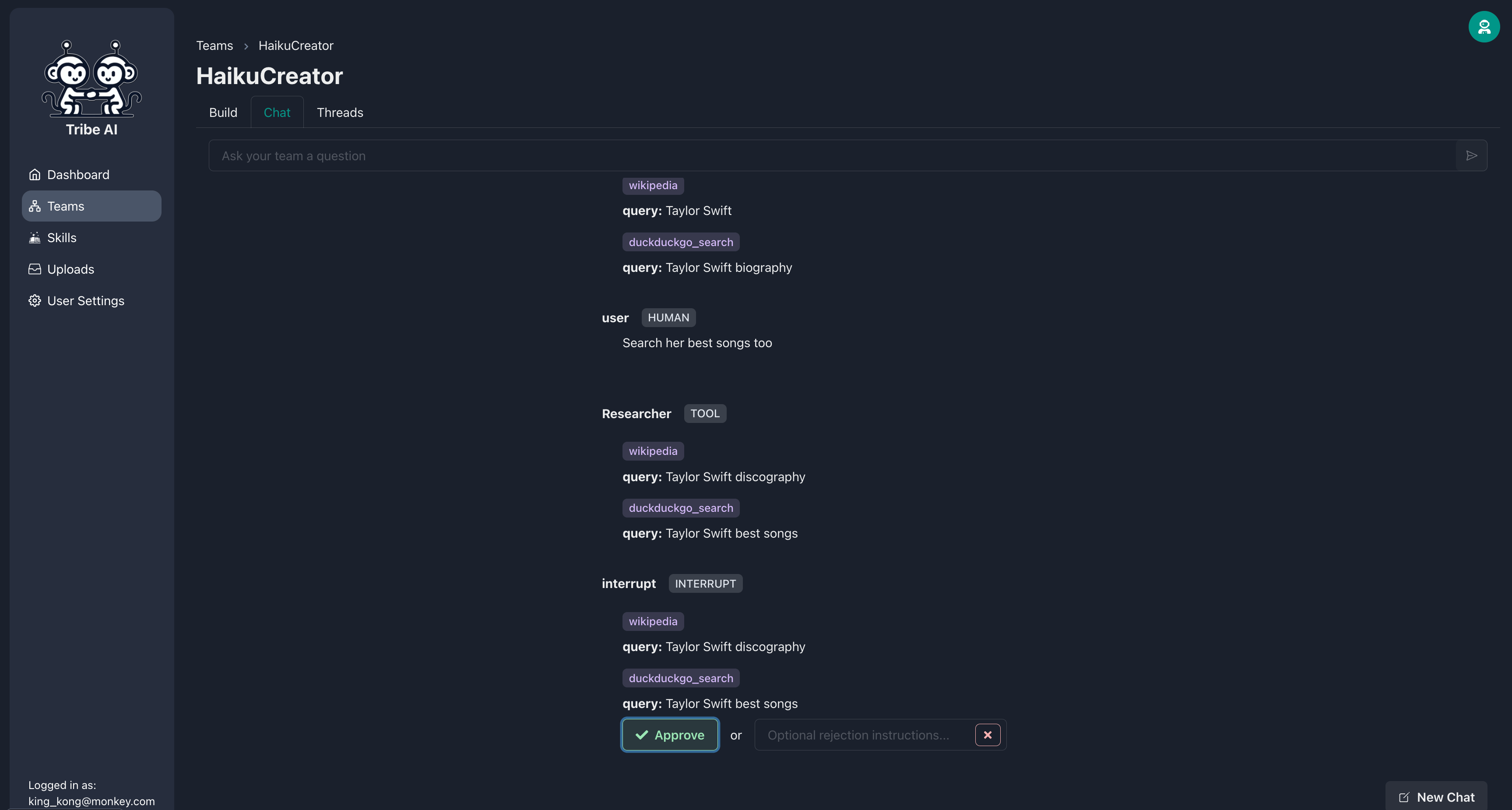
その後、研究者は指示に従ってスキルを実行します。 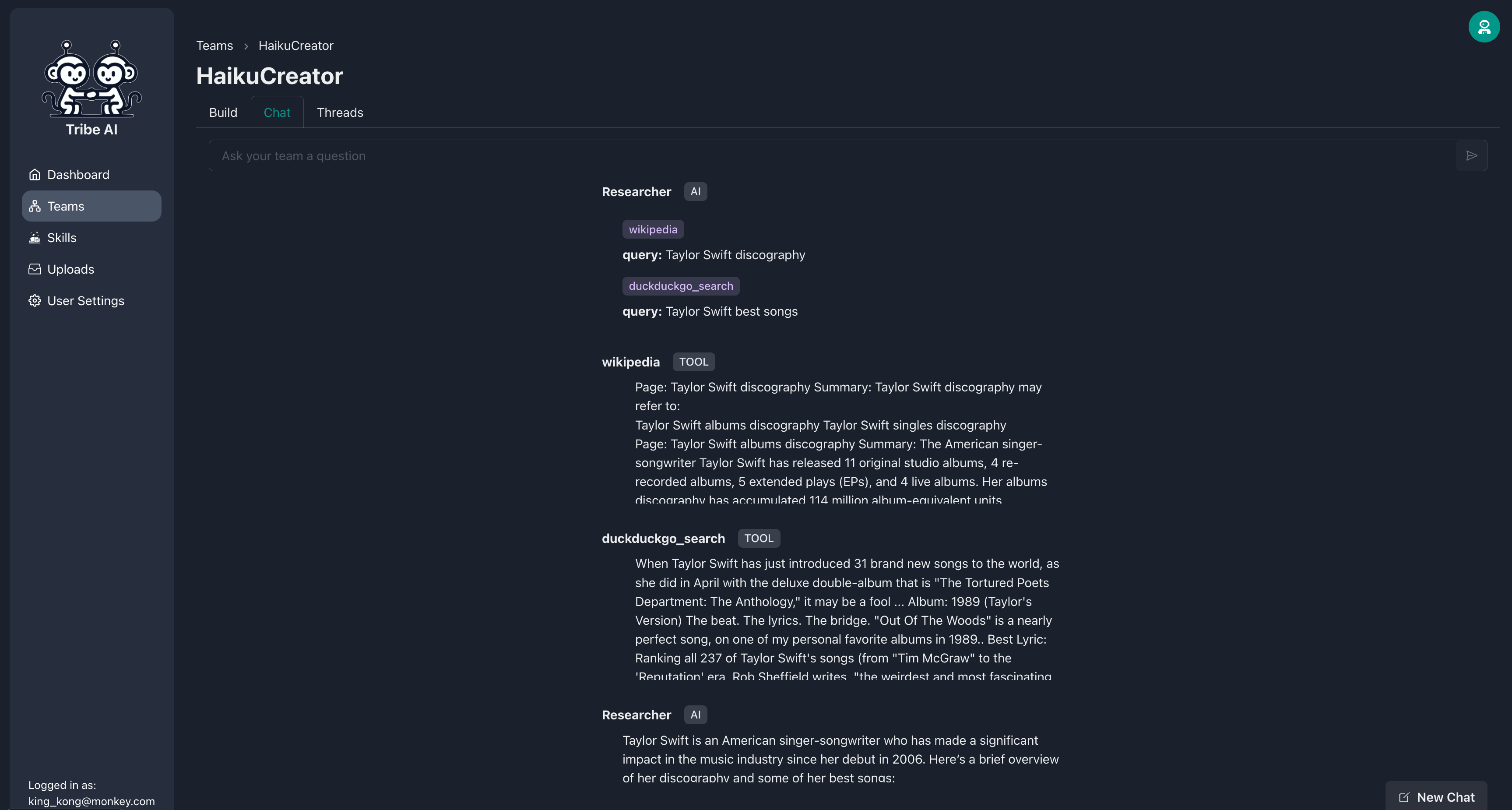
Tribeはオープンソースであり、コミュニティからの歓迎の貢献です!開始するために私たちの貢献ガイドをチェックしてください。
貢献するいくつかの方法:
ファイルリリース-notes.mdを確認してください。
Tribeは、MITライセンスの条件に基づいてライセンスされています。


