tribe
v0.7.6

Outil de code bas pour créer et coordonner rapidement les équipes multi-agents
Avertissement
Ce projet est actuellement en cours de développement intense. Veuillez noter que des changements importants peuvent survenir.
Avez-vous entendu le dicton: «Deux esprits valent mieux qu'un»? C'est vrai pour les agents aussi. La tribu exploite le cadre de Langgraph pour vous permettre de personnaliser et de coordonner facilement les équipes d'agents. En divisant des tâches difficiles entre des agents qui sont bons dans différentes choses, chacun peut se concentrer sur ce qu'il fait le mieux. Cela rend la résolution de problèmes plus rapide et meilleure.
En s'associant, les agents peuvent assumer des tâches plus complexes. Voici quelques exemples de ce qu'ils peuvent faire ensemble:
Et beaucoup plus!
Avant de le déployer, assurez-vous de modifier au moins les valeurs pour:
SECRET_KEYFIRST_SUPERUSER_PASSWORDPOSTGRES_PASSWORDVous pouvez (et devez) les passer comme variables d'environnement des secrets.
Certaines variables d'environnement dans le fichier .env ont une valeur par défaut de changethis .
Vous devez les changer avec une clé secrète, pour générer des clés secrètes, vous pouvez exécuter la commande suivante:
python -c " import secrets; print(secrets.token_urlsafe(32)) "Copiez le contenu et utilisez-le comme mot de passe / clé secrète. Et exécutez-le à nouveau pour générer une autre clé sécurisée.
Levez-vous et commencez en quelques minutes sur votre machine locale.
Déployez la tribu sur votre serveur distant.
Dans un flux de travail séquentiel, vos agents sont disposés dans une séquence ordonnée et exécutent des tâches les unes après les autres. Chaque tâche peut dépendre de la tâche précédente. Ceci est utile si vous voulez que les tâches soient effectuées l'une après l'autre dans une séquence déterministe.
Utilisez-le si:
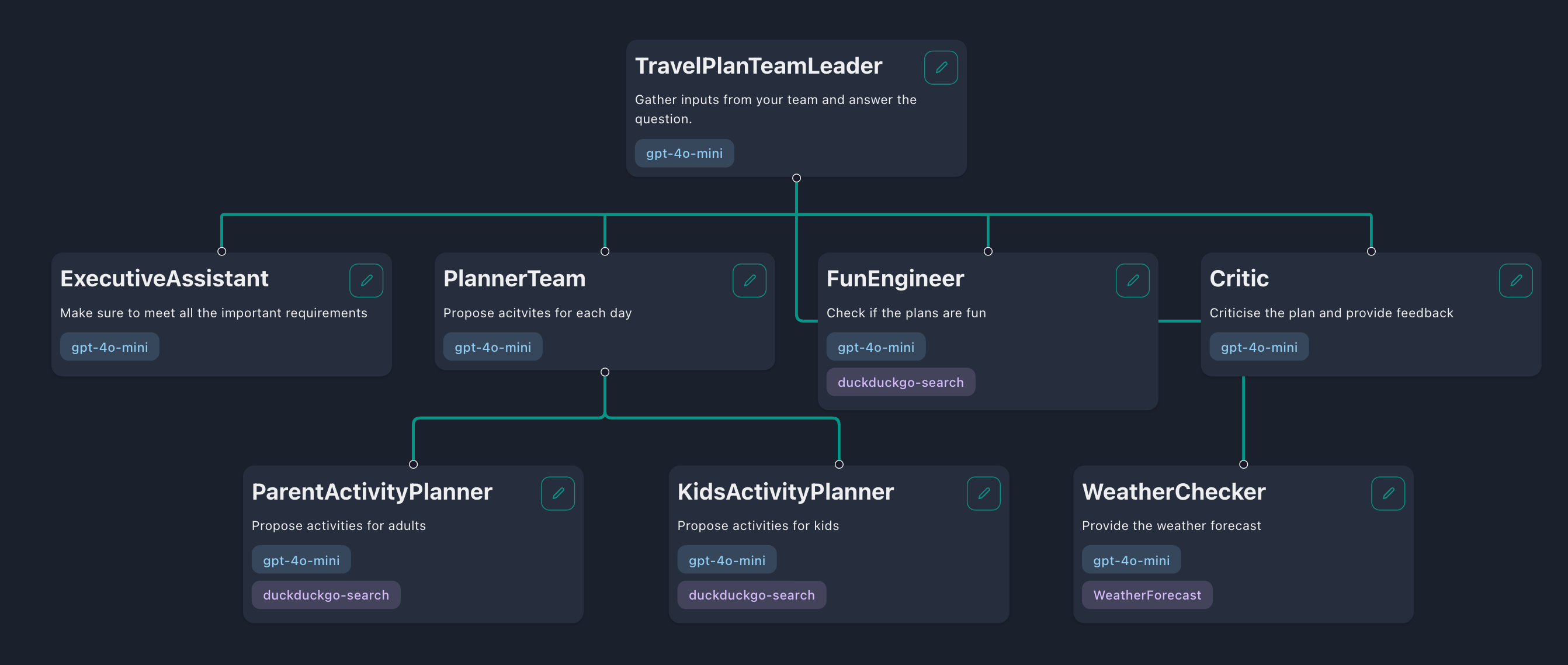
Dans un flux de travail hiérarchique, vos agents sont organisés en une structure en forme d'équipe comprenant un «chef d'équipe», des «membres de l'équipe» et même d'autres «chefs de sous-équipe». Le chef d'équipe décompose la tâche en tâches plus petites et les délégue aux membres de son équipe. Une fois que les membres de l'équipe ont terminé ces tâches, leurs réponses seront transmises au chef d'équipe qui choisit ensuite de retourner la réponse à l'utilisateur ou de déléguer plus de tâches.
Utilisez-le si:
Les compétences sont des capacités dont vous pouvez équiper vos agents pour interagir avec le monde. Par exemple, vous pouvez fournir à votre agent la compétence pour vérifier la condition météorologique actuelle ou rechercher sur le Web les dernières nouvelles. Par défaut, Tribe offre trois compétences:
Vous voudrez probablement créer des compétences personnalisées, ce qui peut être fait de deux manières: en utilisant des définitions de fonction pour des demandes HTTP simples ou en écrivant des compétences personnalisées dans la base de code.
Si votre compétence consiste à effectuer une demande HTTP pour récupérer ou mettre à jour des données, l'utilisation de définitions de compétences est l'approche la plus simple. Dans Tribe, commencez par naviguer dans l'onglet «Compétences» et cliquer sur le bouton «Ajouter des compétences». Vous serez ensuite invité à fournir la définition des compétences, qui instruit votre agent sur la façon d'exécuter la compétence spécifique. Cette définition doit être structurée comme suit:
{
"url" : " https://example.com " ,
"method" : " GET " ,
"headers" : {},
"type" : " function " ,
"function" : {
"name" : " Your skill name " ,
"description" : " Your skill description " ,
"parameters" : {
"type" : " object " ,
"properties" : {
"param1" : {
"type" : " integer " ,
"description" : " Description of the first parameter "
},
"param2" : {
"type" : " string " ,
"enum" : [ " option1 " ],
"description" : " Description of the second parameter "
}
},
"required" : [ " param1 " , " param2 " ]
}
}
}| Clé | Description |
|---|---|
url | L'URL du point de terminaison pour l'appel de l'API. |
method | La méthode HTTP utilisée pour la demande. Il peut être GET , POST , PUT , PATCH ou DELETE . |
headers | Tous les en-têtes HTTP à inclure dans la demande. |
function | Contient des détails sur la compétence: |
function > name | Le nom de la compétence. Suivez ces règles: seules les lettres (AZ, AZ), les chiffres (0-9), les soulignements (_) et les traits de traits (-) sont autorisées; Doit être entre 1 et 64 caractères. |
function > description | Décrit la compétence pour informer l'agent de son utilisation. |
function > parameters | Détails sur les paramètres que l'API accepte. |
properties > param | Le nom du paramètre de requête ou de corps. Pour les méthodes GET , ce sera un paramètre de requête. Pour POST , PUT , PATCH et DELETE , il sera dans le corps de la demande. |
param > type | Spécifie le type de paramètre, qui peut être string , number , integer ou boolean . |
param > description | Fournit un contexte sur l'objectif du paramètre. |
param > enum | Facultativement, incluez un tableau pour restreindre l'agent à sélectionner parmi les valeurs prédéfinies. |
parameters > required | Répertorie les paramètres nécessaires, garantissant qu'ils sont toujours inclus dans la demande d'API. |
Pour des tâches plus complexes qui s'étendent au-delà des simples demandes HTTP, Langchain vous permet de développer des outils plus avancés. Vous pouvez intégrer ces outils dans Tribe en les ajoutant au dictionnaire managed_skills . Pour un exemple pratique, reportez-vous à l'outil de calculatrice de démonstration. Pour apprendre à créer un outil Langchain, veuillez consulter leur documentation.
Après avoir créé un nouvel outil, redémarrez l'application pour vous assurer que l'outil est correctement chargé dans la base de données. De même, si vous devez supprimer un outil, supprimez-le simplement du dictionnaire managed_skills et redémarrez l'application pour vous assurer qu'elle est supprimée de la base de données. Notez que les outils créés de cette façon sont disponibles pour tous les utilisateurs de votre application.
Le chiffon est une technique pour augmenter les connaissances de vos agents avec des données supplémentaires. Les agents peuvent raisonner sur un large éventail de sujets, mais leurs connaissances sont limitées aux données publiques jusqu'au moment où elles ont été formées. Si vous souhaitez que vos agents raisonnent sur les données privées, Tribe vous permet de télécharger vos données et de sélectionner les données à inclure dans la base de connaissances de votre agent. Cela permet à vos agents de raisonner avec les données sélectionnées et vous permet de créer différents agents avec des connaissances spécialisées.
Par défaut, Tribe utilise BAAI/bge-small-en-v1.5 , qui est un modèle d'incorporation d'anglais léger et rapide qui est meilleur que OpenAI Ada-002 . Si vos documents sont multilingues ou nécessitent une intégration d'image, vous pouvez utiliser un autre modèle d'intégration. Vous pouvez facilement le faire en modifiant DENSE_EMBEDDING_MODEL dans votre fichier .env :
# See the list of supported models: https://qdrant.github.io/fastembed/examples/Supported_Models/
DENSE_EMBEDDING_MODEL=BAAI/bge-small-en-v1.5 # Change this Avertissement
Si vos modèles d'intégration existants et nouveaux ont des dimensions vectorielles différentes, vous devrez peut-être recréer votre collection QDRANT. Vous pouvez supprimer la collection via le tableau de bord Qdrant sur http: //qdrant.localhost/dashboard. Par conséquent, il est préférable de planifier à l'avance quel modèle d'intégration est le plus adapté à vos workflows.
Les modèles open source deviennent moins chers et plus faciles à exécuter, et certains correspondent même aux performances des modèles fermés. Vous préférez peut-être les utiliser pour leurs avantages de confidentialité et de coût. Si vous dirigez une tribu localement et que vous souhaitez utiliser des modèles open source, je recommanderais Olllama pour sa facilité d'utilisation.
ollama .llama3.1:8b ) dans le champ de saisie du modèle.http://host.docker.internal:11434 , qui mappe à https://localhost:11434 . Cette configuration permet à Tribe de communiquer avec l'hôte Ollama par défaut. Si votre configuration utilise un hôte différent, spécifiez le nouvel hôte dans le champ de saisie «URL de base». Il existe des centaines de modèles open source dans la bibliothèque d'Olllama adaptés à différentes tâches. Voici comment choisir le bon pour votre cas d'utilisation:
Llama3.1 , Mistral Nemo , Firefunction V2 ou Command-R + et d'autres qui prennent en charge l'appel à outils.gemma2 ou phi3 . Si vous ne prévoyez pas d'utiliser Olllama, vous pouvez toujours exécuter des modèles open source compatibles avec l'API Openai Chat Completion.
Mesures:
Connectez-vous à la tribu à l'aide de l'e-mail et du mot de passe que vous définissez pendant l'étape d'installation.
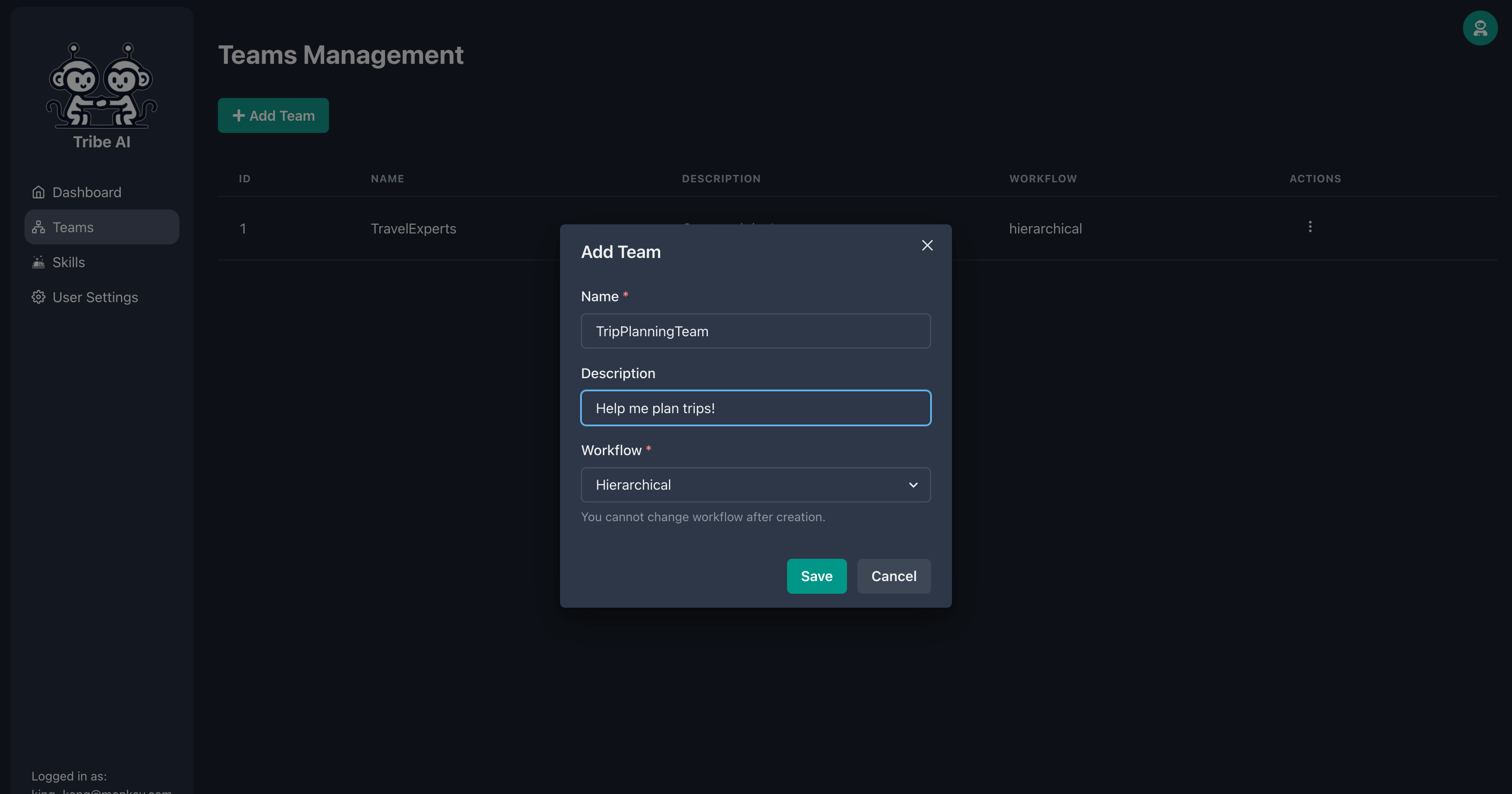
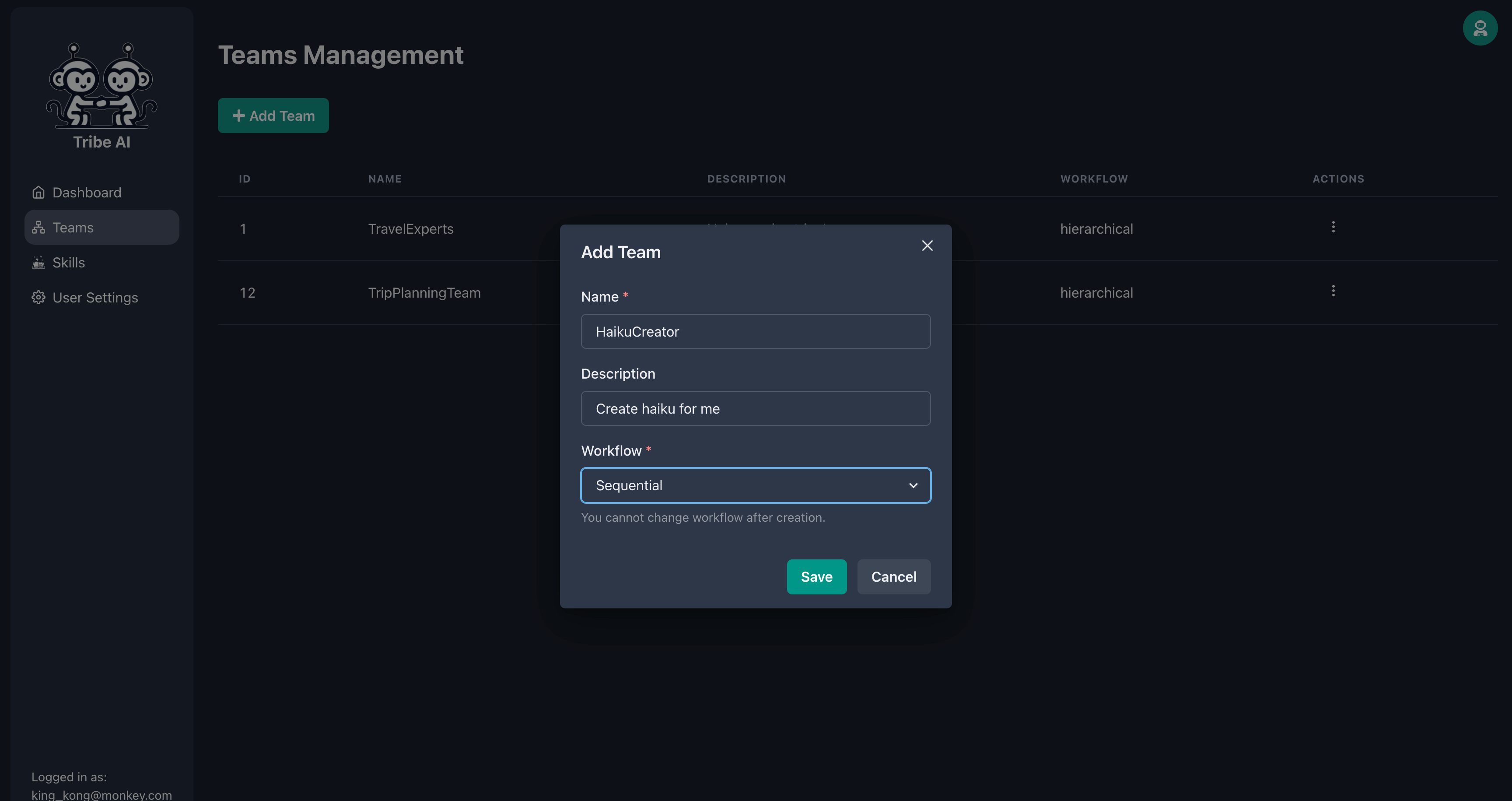
Accédez à la page «Teams» et cliquez sur «Ajouter l'équipe». Entrez un nom pour votre équipe et cliquez sur «Enregistrer».
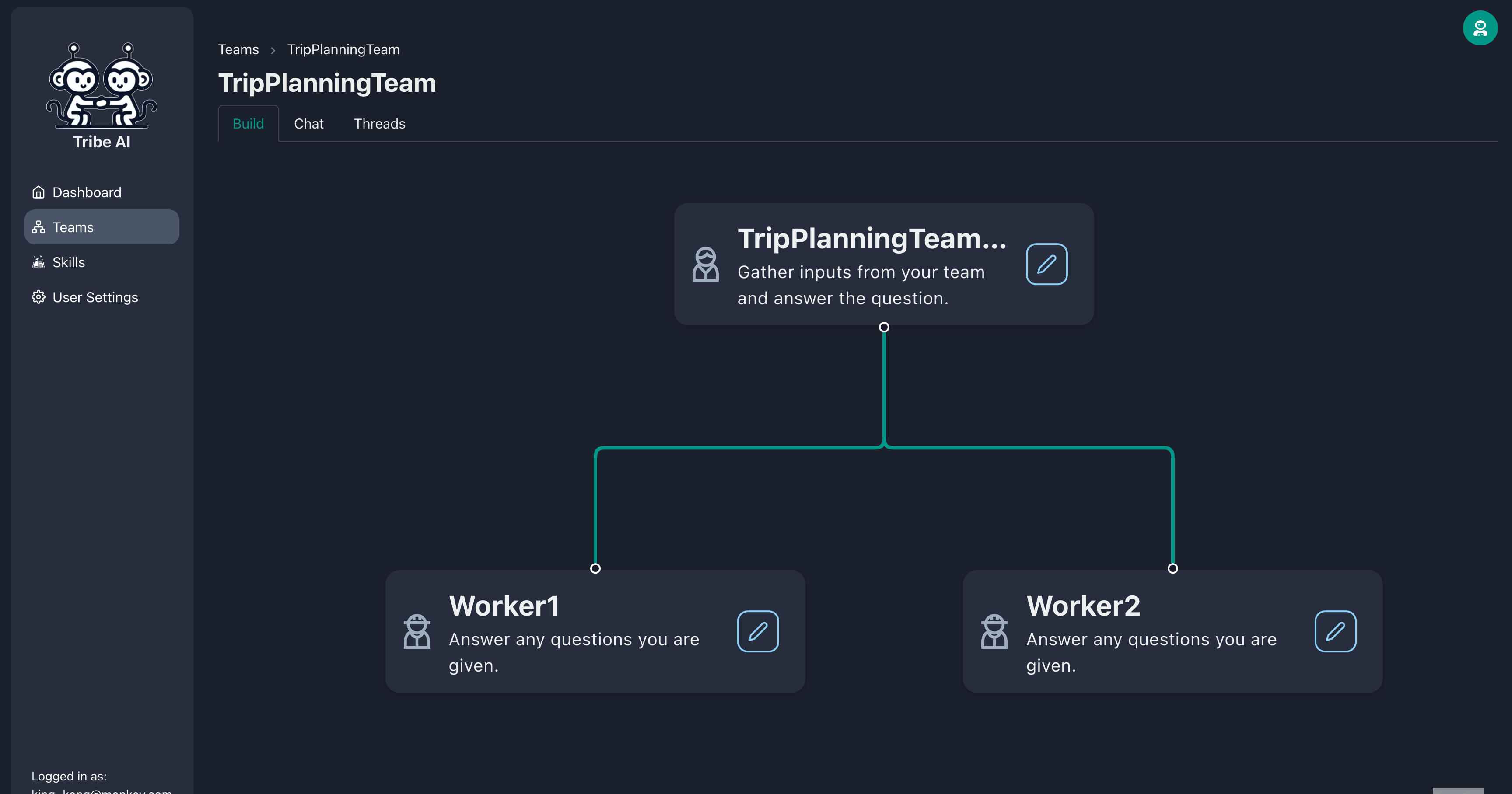
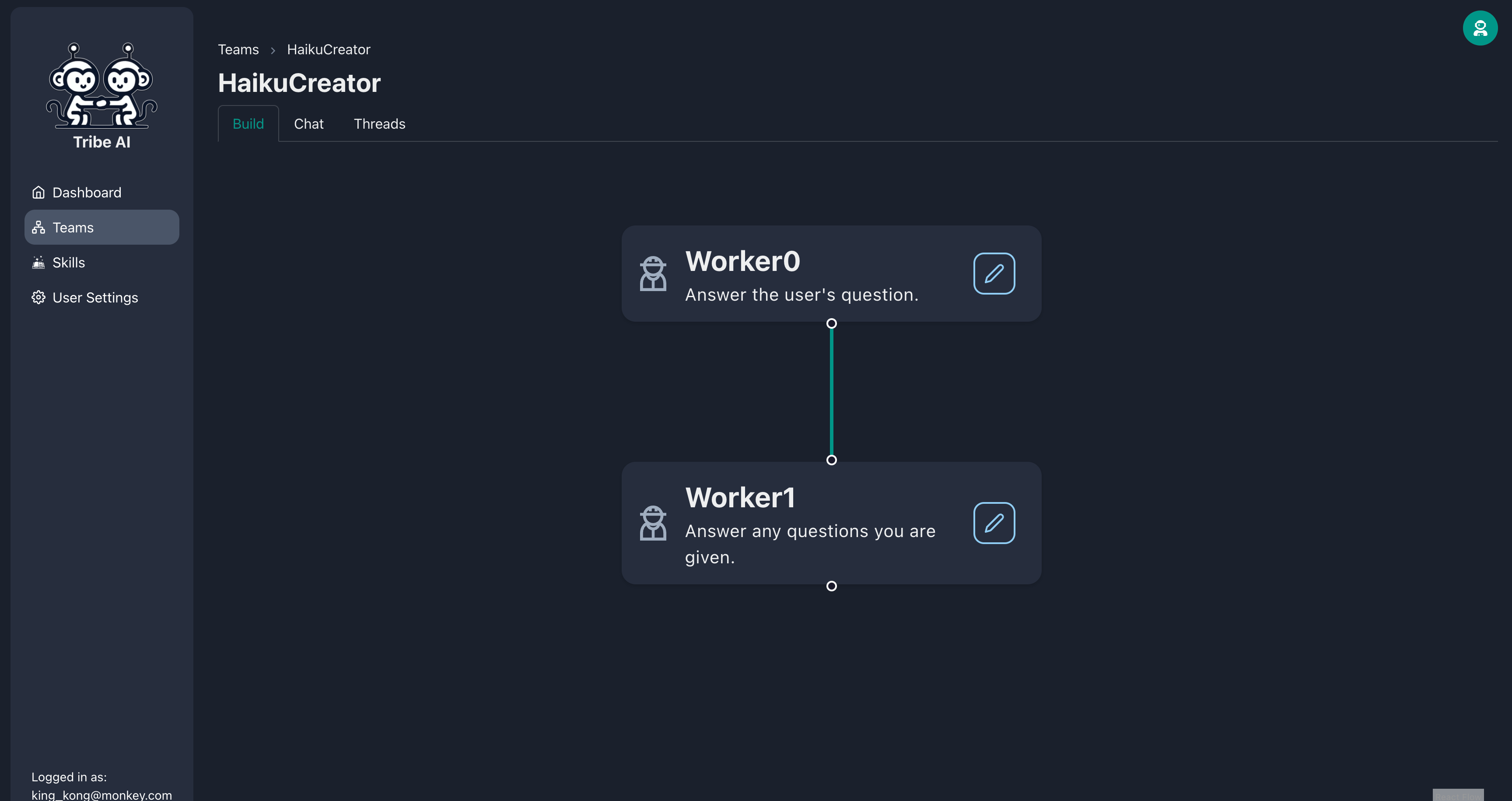
Créez deux membres de l'équipe supplémentaires en faisant glisser la poignée du nœud du leader de l'équipe.
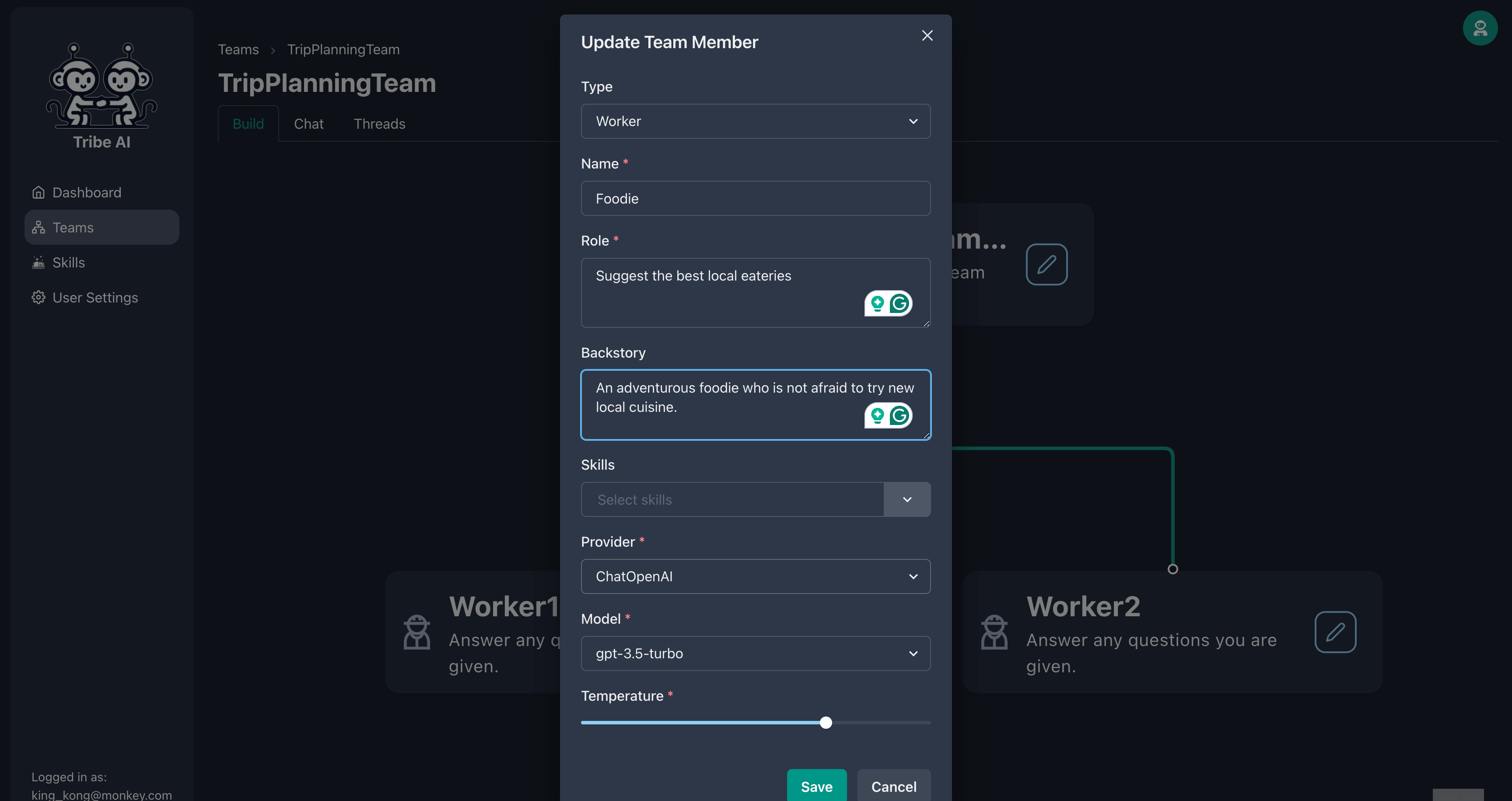
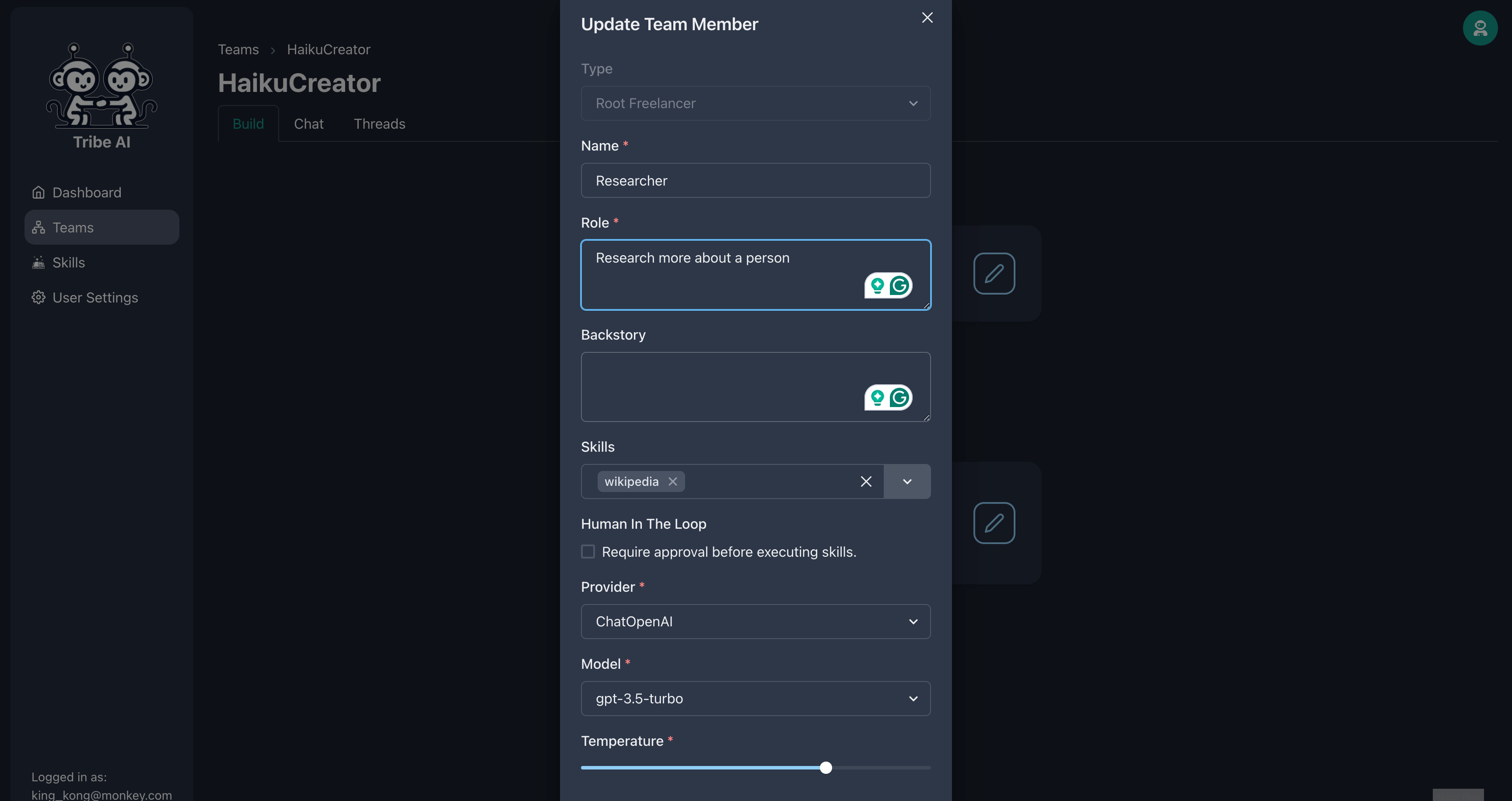
Mettez à jour le premier membre de l'équipe comme indiqué.
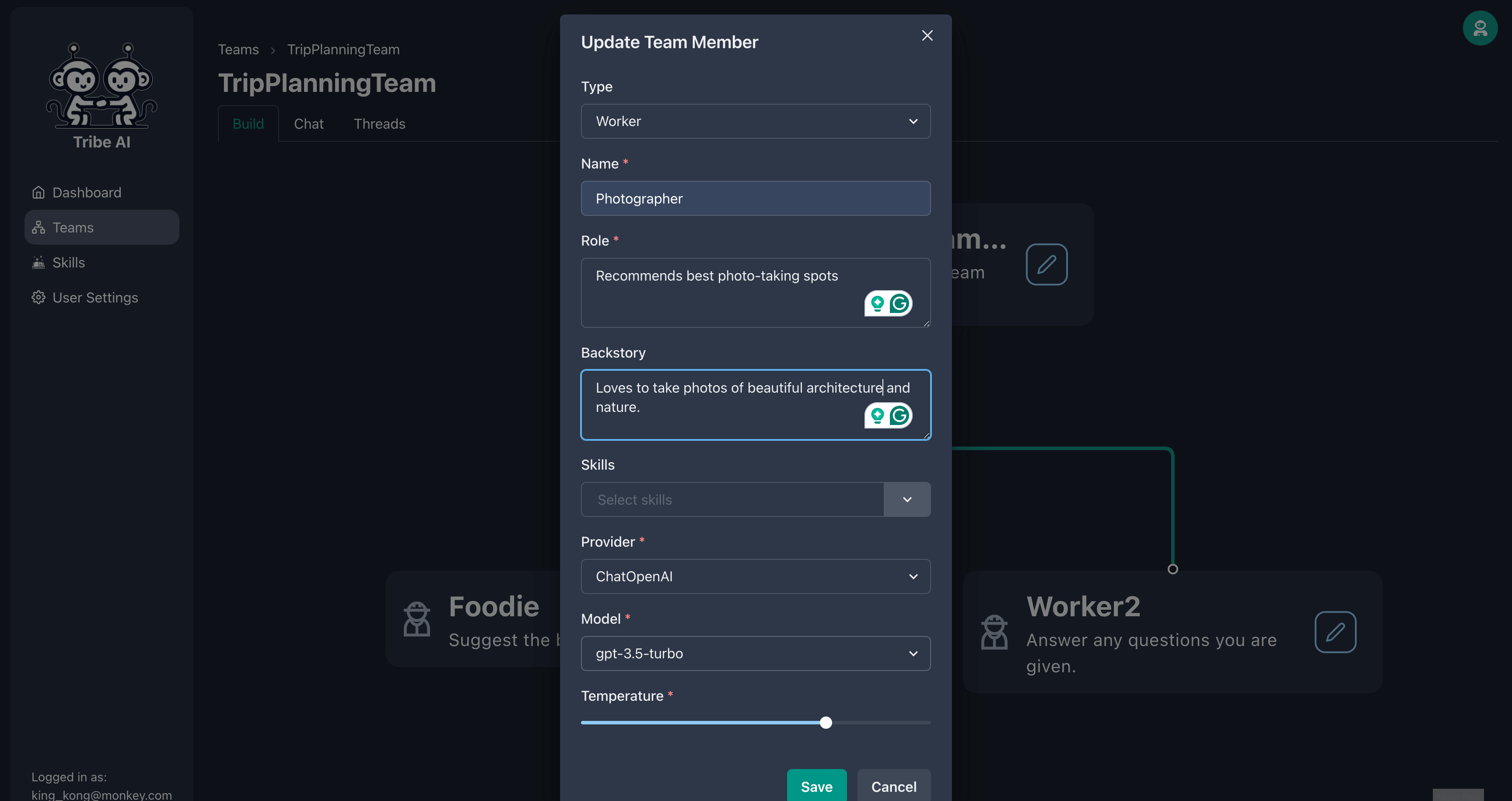
Mettez à jour le deuxième membre de l'équipe comme indiqué.
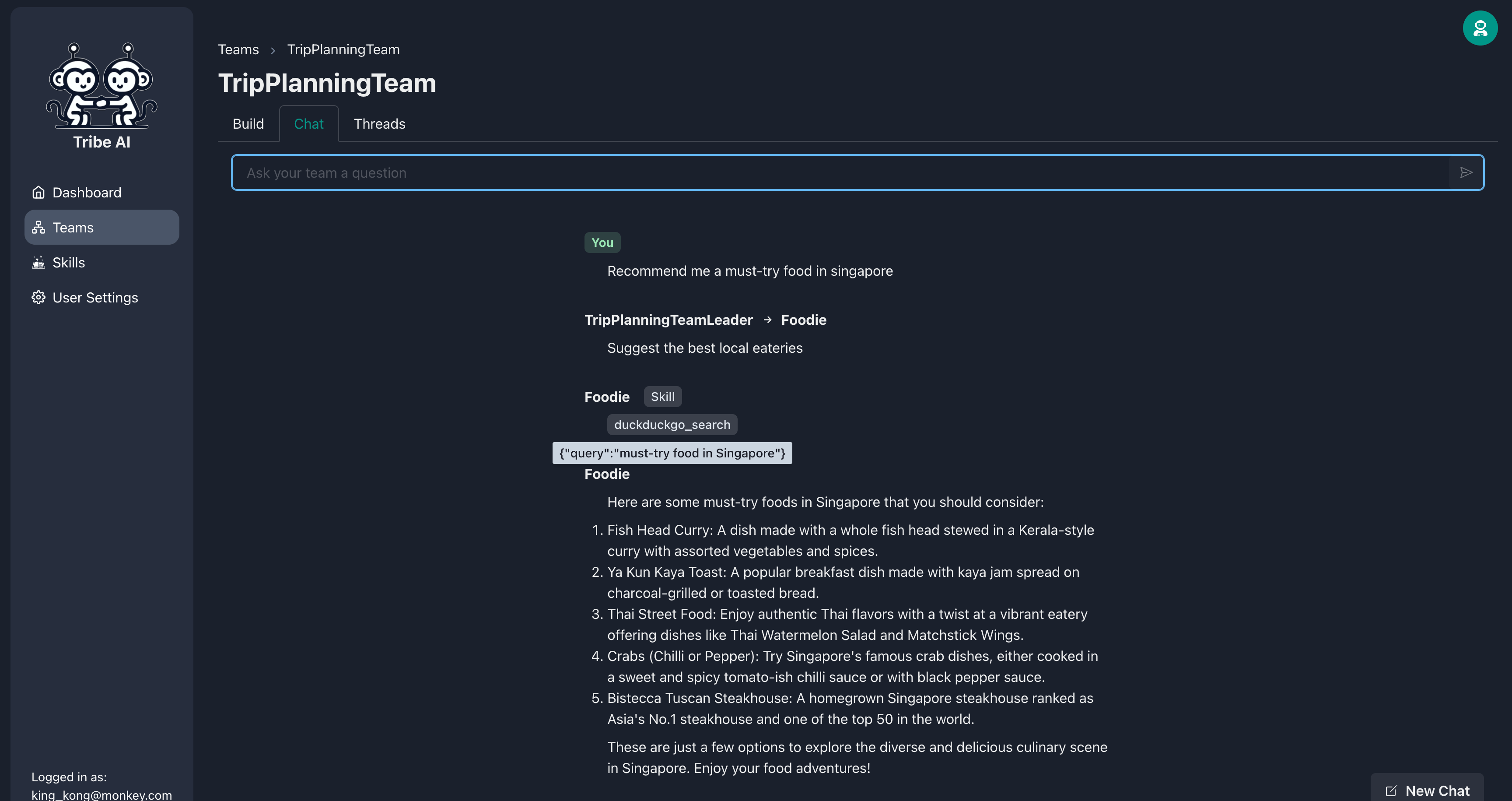
Accédez à l'onglet «Chat» et envoyez une question à votre équipe pour voir comment ils réagissent.
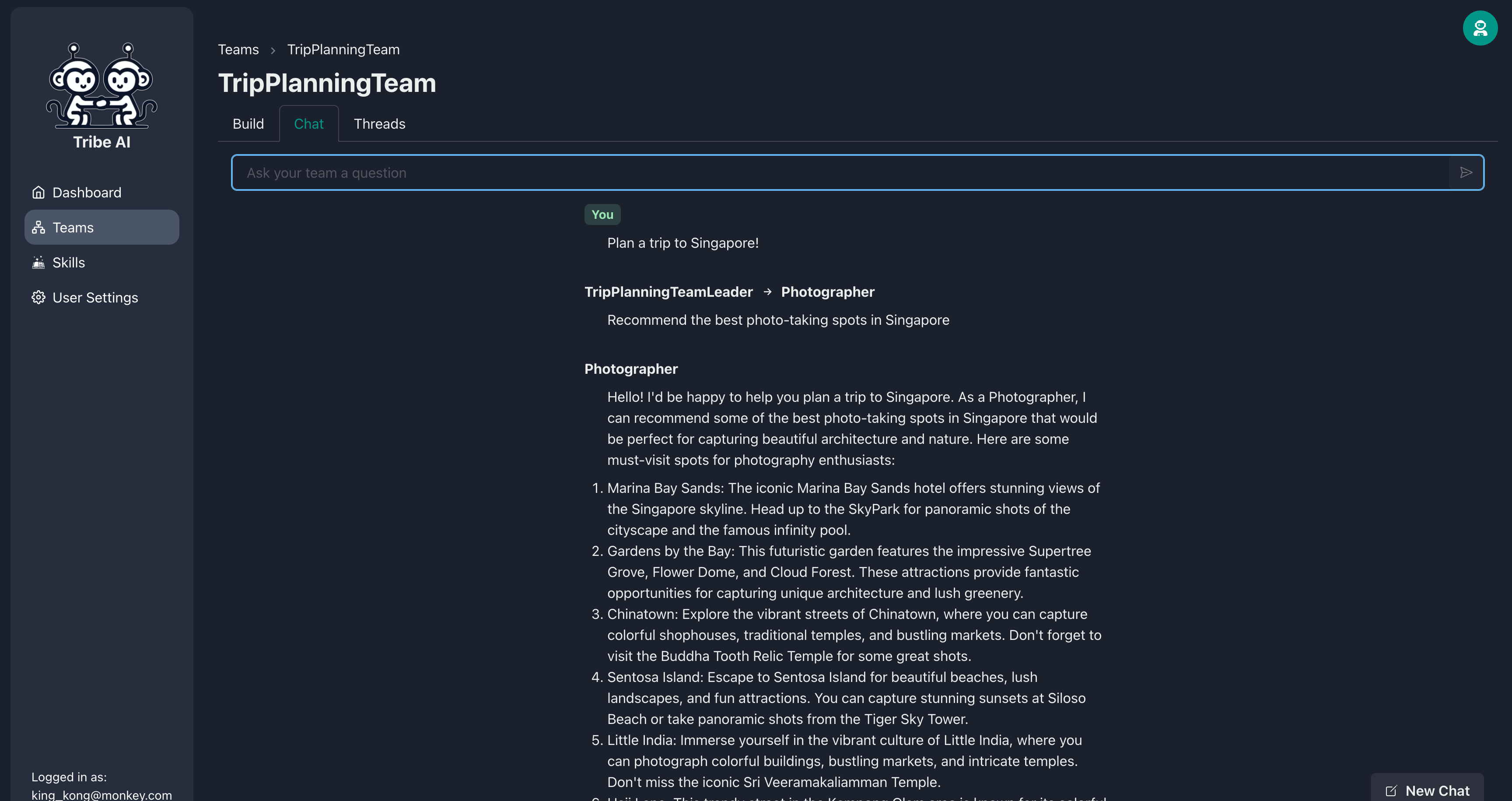
Félicitations! Vous avez réussi à construire et à communiquer avec votre première équipe multi-agents sur Tribe.
Le membre de votre équipe peut en faire plus en lui fournissant un ensemble de compétences. Ajoutez une compétence à votre gourmand.
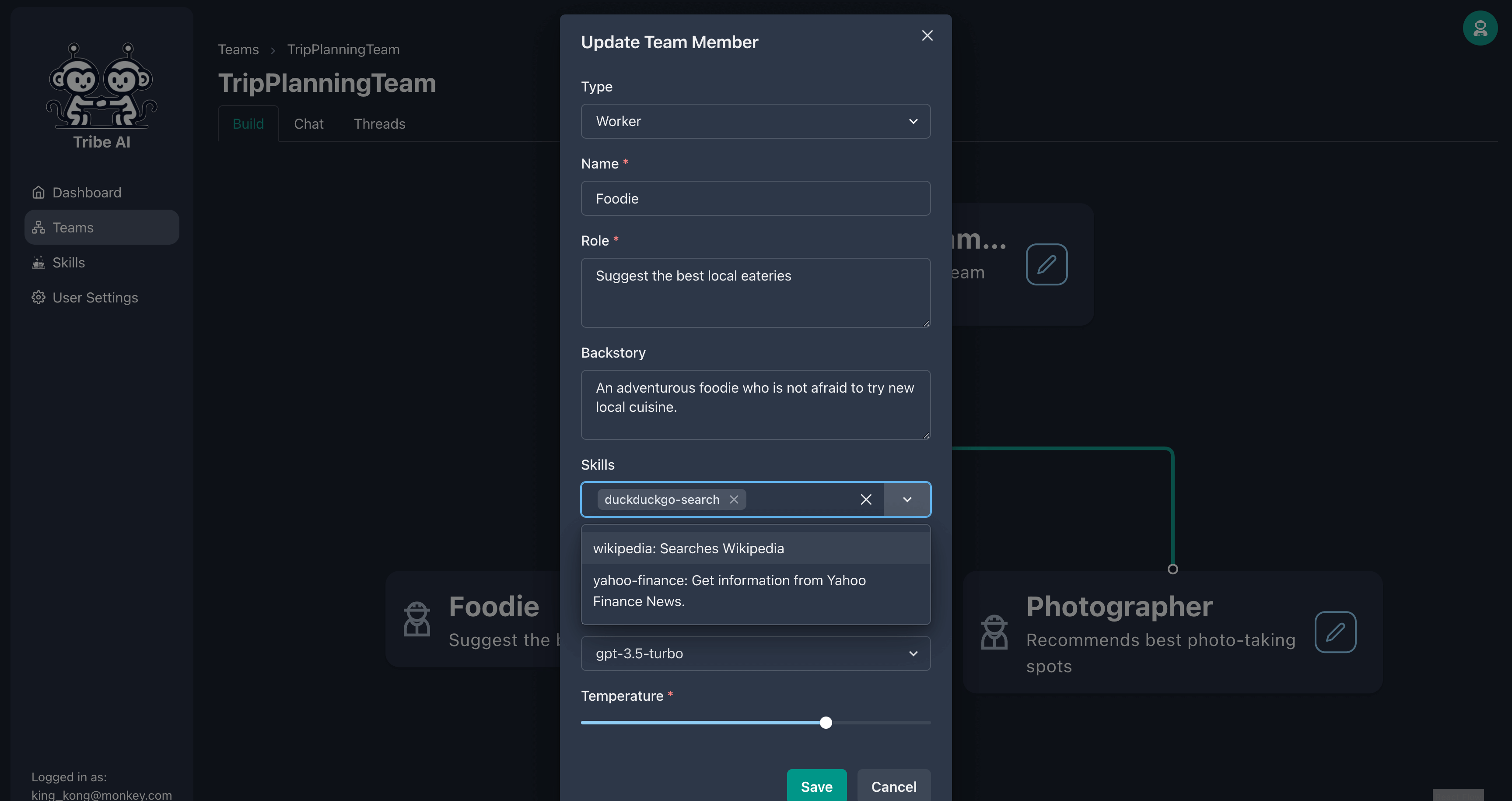
Maintenant, lorsque vous posez une question à votre gourmand, il recherchera sur le Web des informations plus à jour!
Créez une nouvelle équipe et sélectionnez le flux de travail «séquentiel».
Faites glisser et déposez pour créer un autre membre de l'équipe ci-dessous «Worker0».
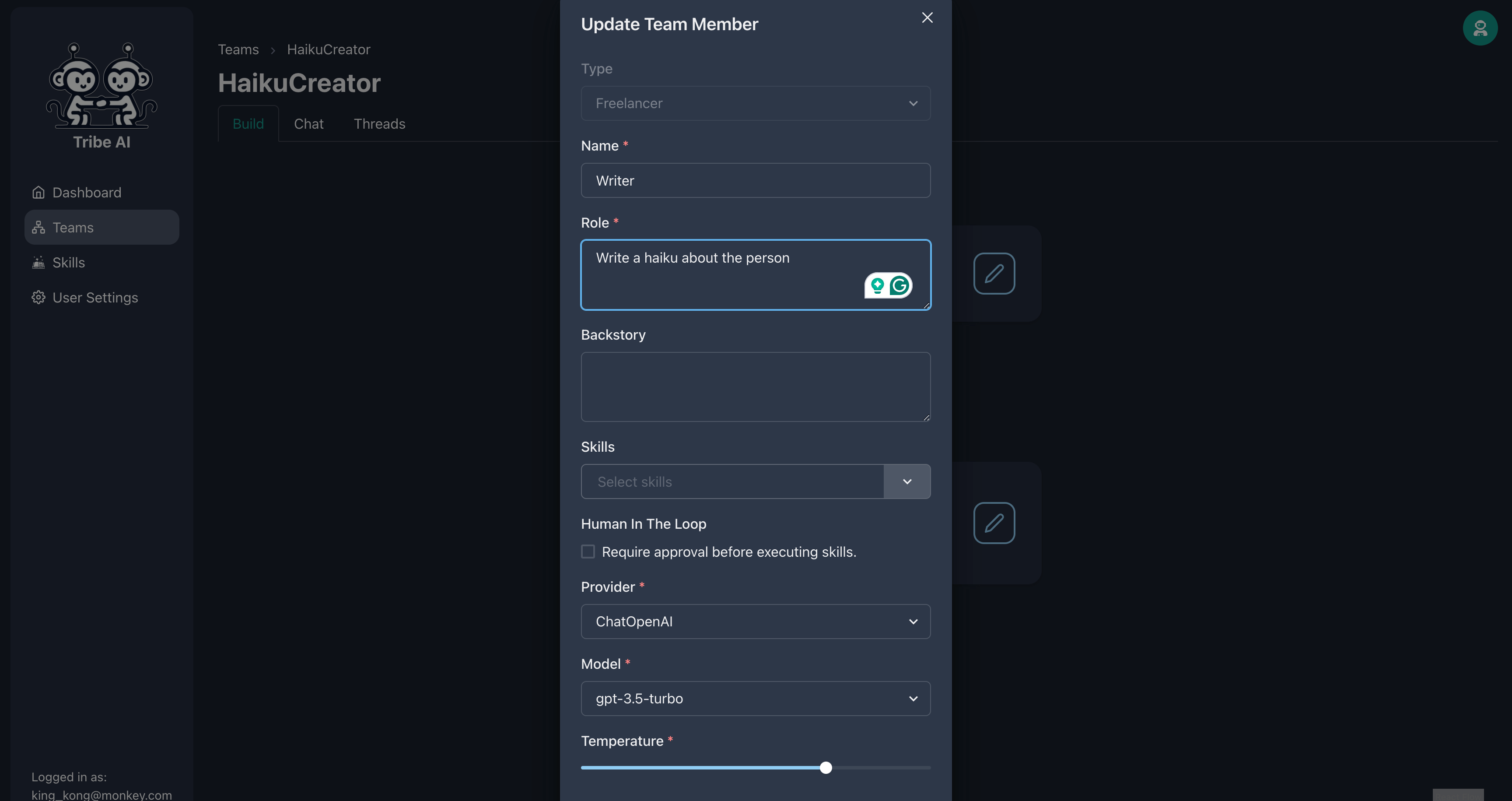
Mettez à jour le premier membre de l'équipe comme indiqué. Fournir la compétence «Wikipedia» à ce membre de l'équipe.
Mettez à jour le deuxième membre de l'équipe comme indiqué.
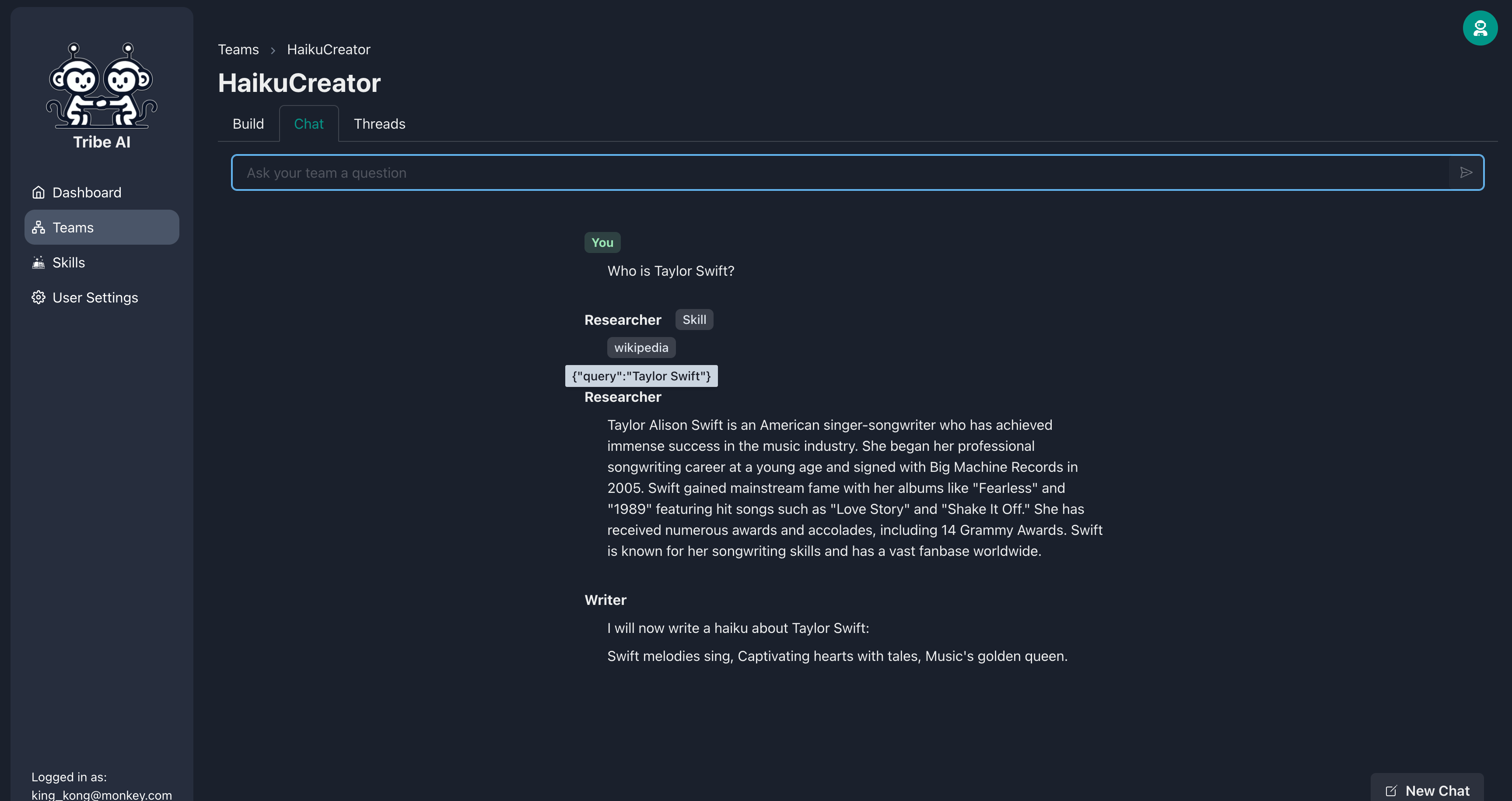
Accédez à l'onglet «Chat» et envoyez une question à votre équipe pour voir comment ils réagissent. Notez que le chercheur utilisera Wikipedia pour faire ses recherches. Très cool!
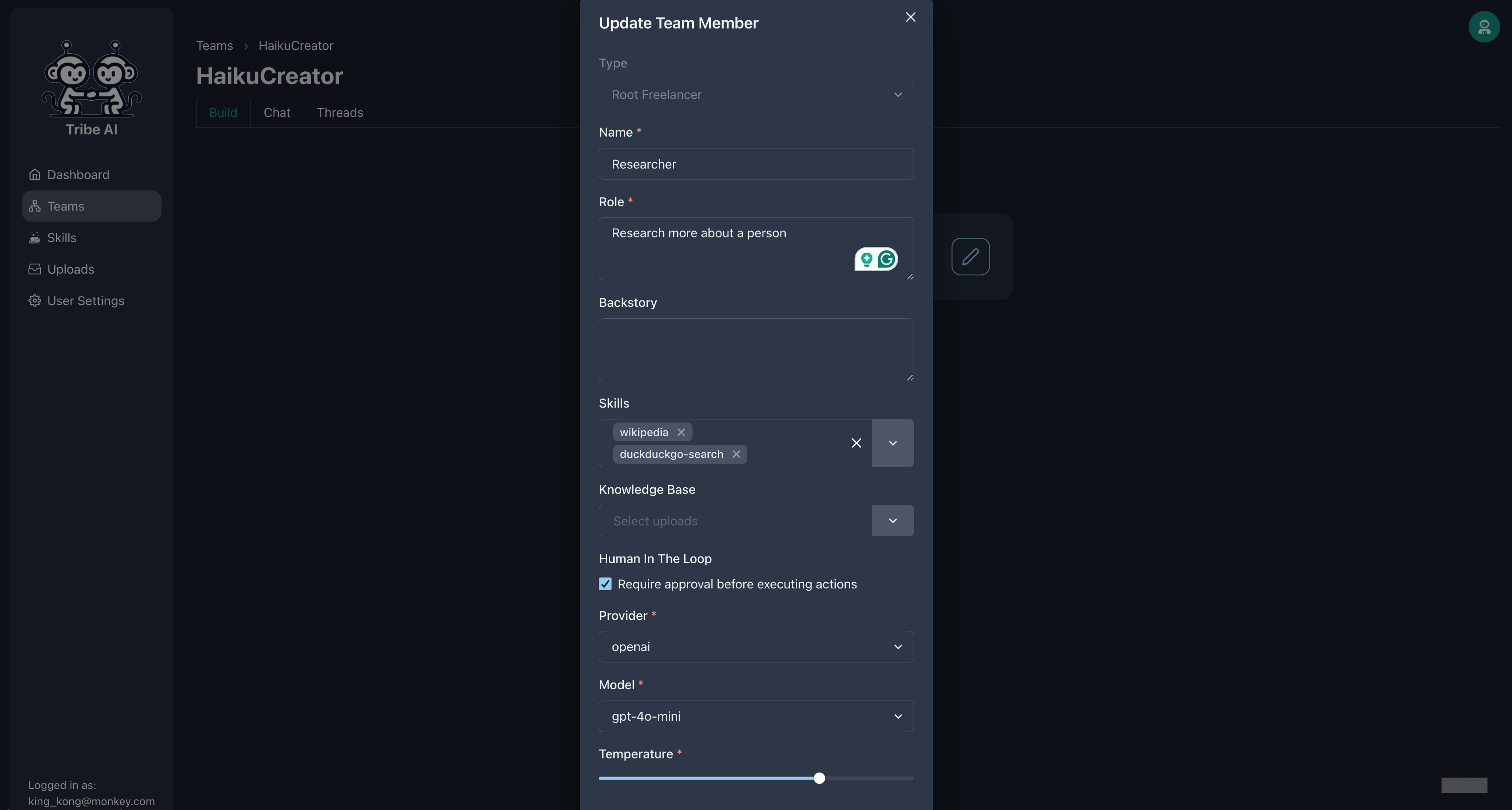
Vous pouvez exiger que les membres de votre équipe attendent votre approbation avant d'exécuter leurs compétences. Ajoutez la compétence «DuckDuckgo-Search» et sélectionnez «nécessiter l'approbation» chez le chercheur.
Maintenant, avant que le chercheur exécute ses compétences, il vous demandera votre approbation. Si la recherche du chercheur n'est pas ce que vous vouliez, rejetez l'action et incluez un message facultatif pour fournir une direction.
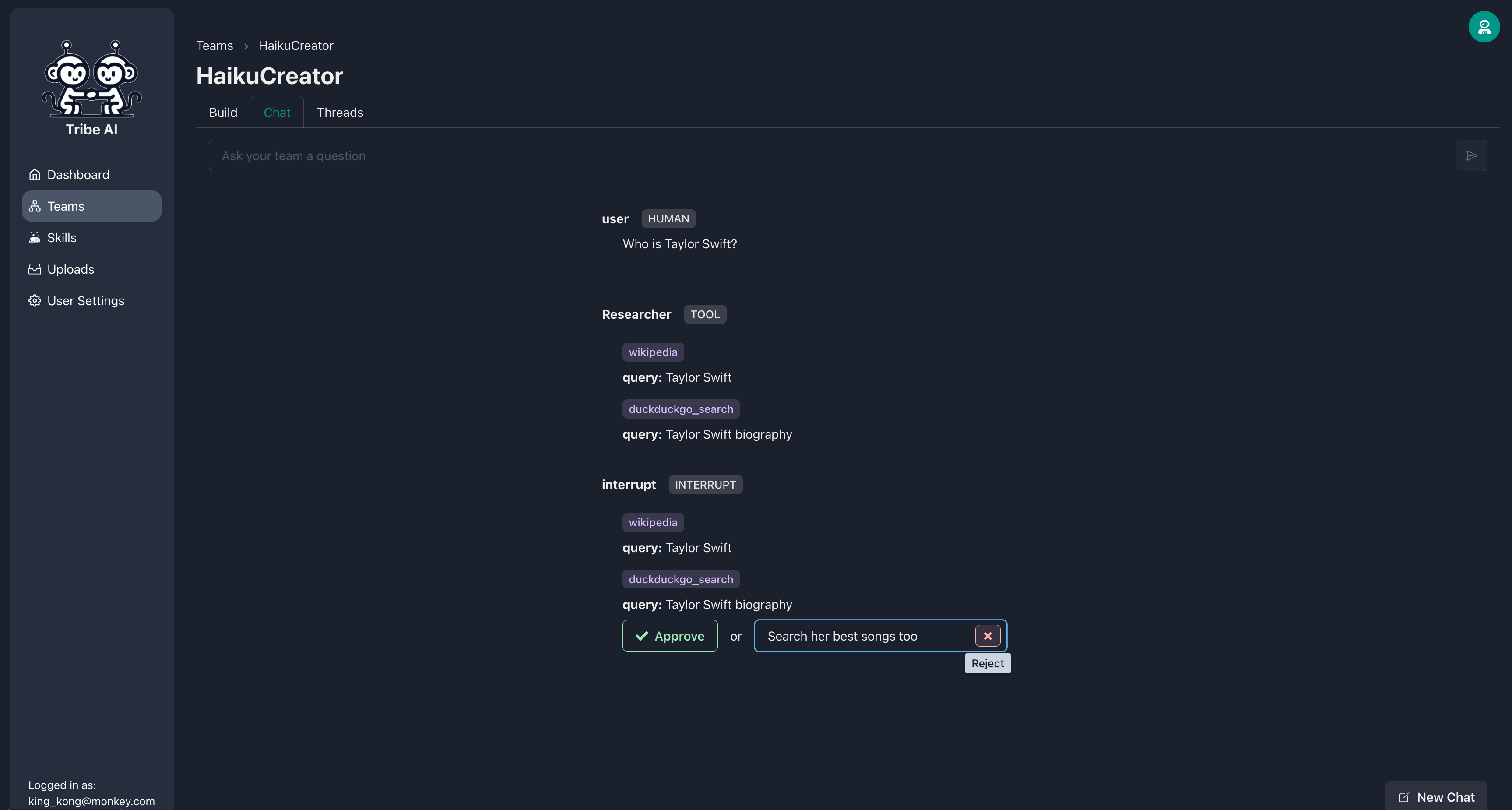
Une fois que le chercheur ajuste la recherche pour répondre à vos besoins, vous pouvez approuver l'action. 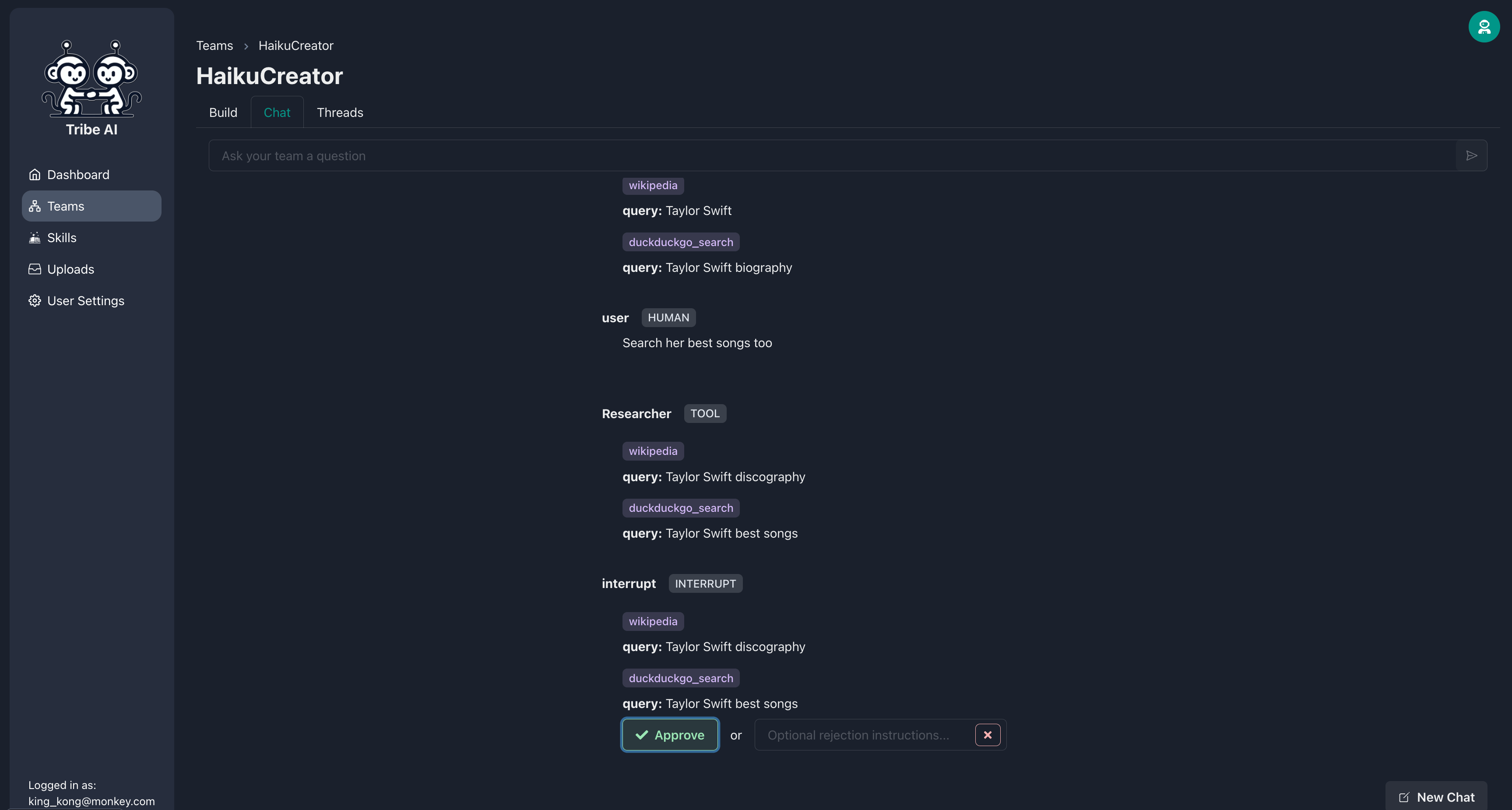
Le chercheur procédera ensuite à l'exécution de ses compétences comme indiqué. 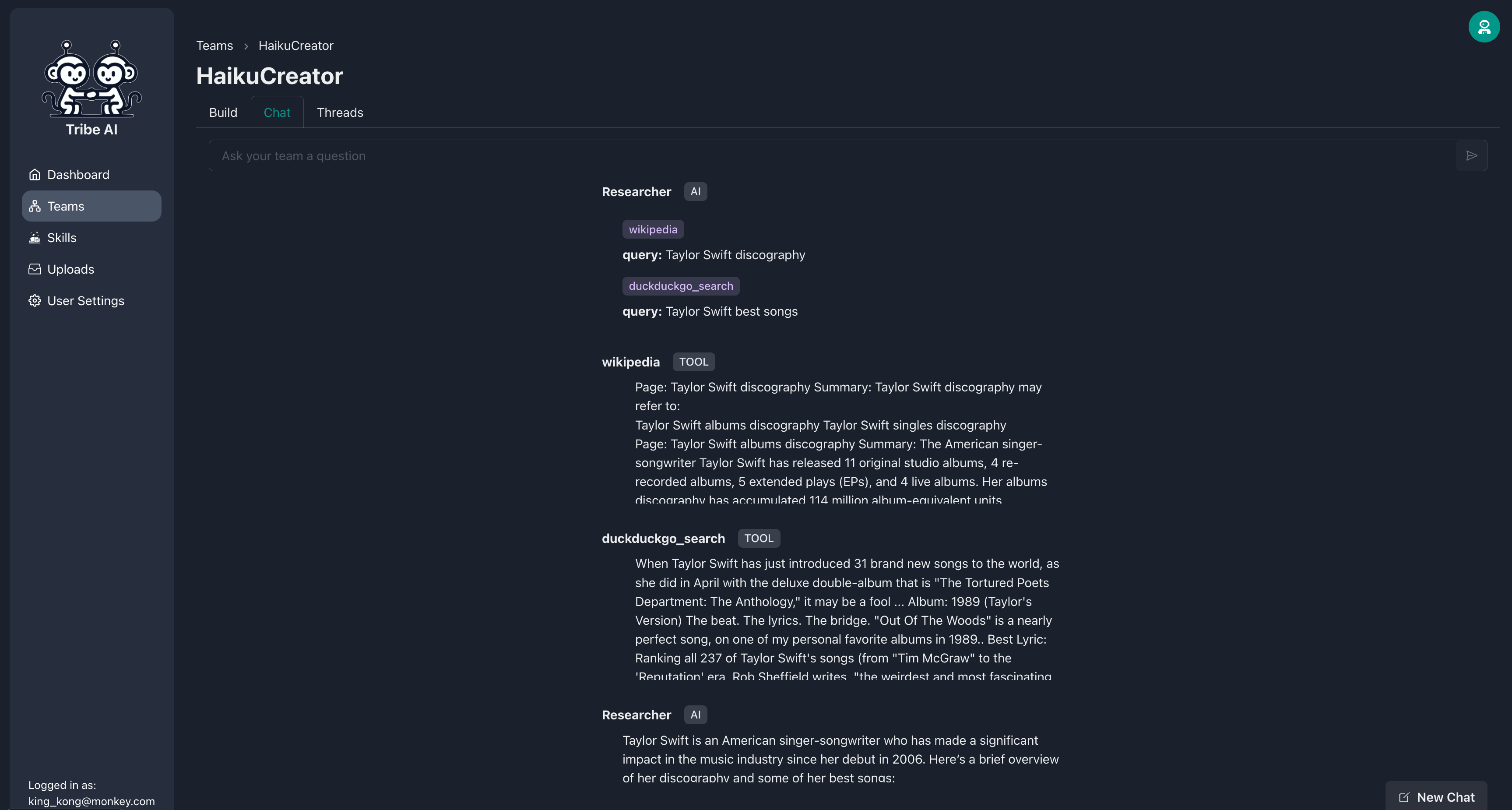
La Tribe est ouverte et bienvenue des contributions de la communauté! Consultez notre guide de contribution pour commencer.
Certaines façons de contribuer:
Vérifiez le fichier Release-notes.md.
La tribu est autorisée en vertu des termes de la licence du MIT.


