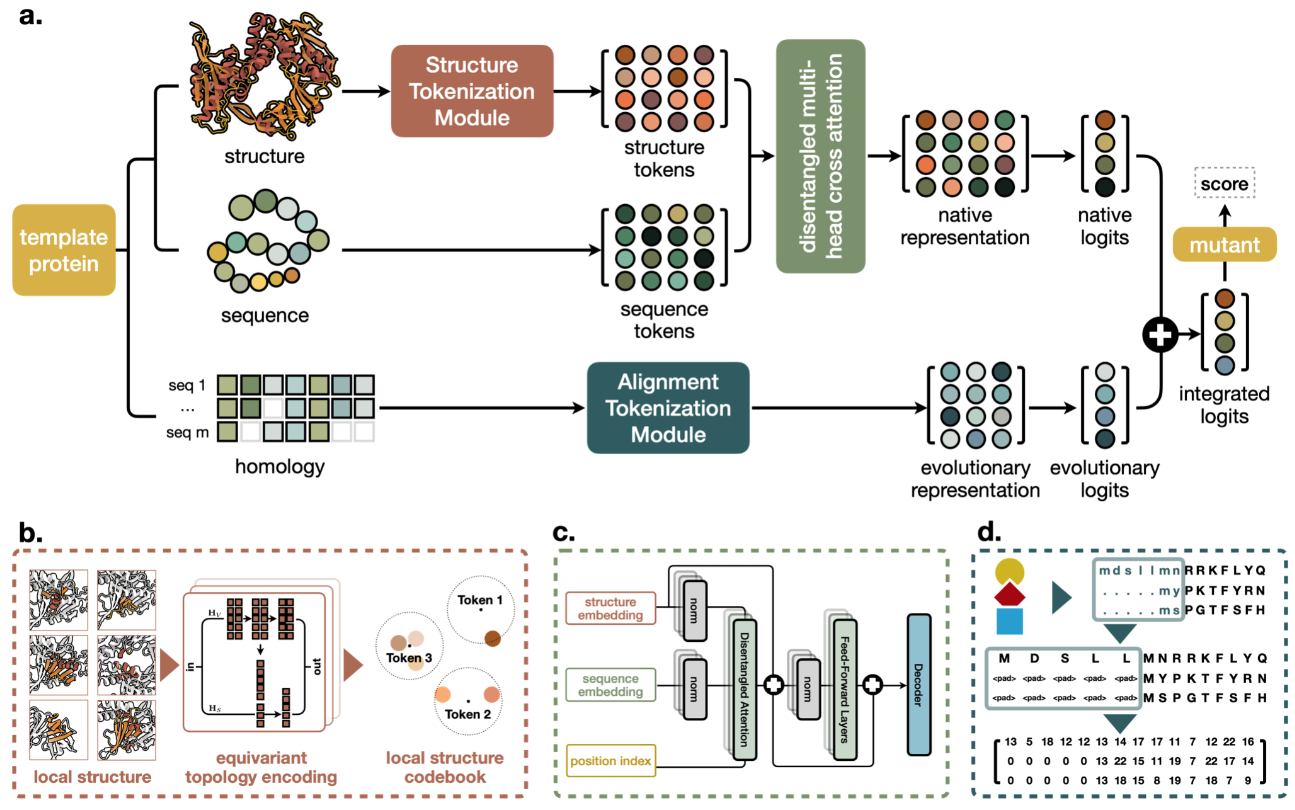
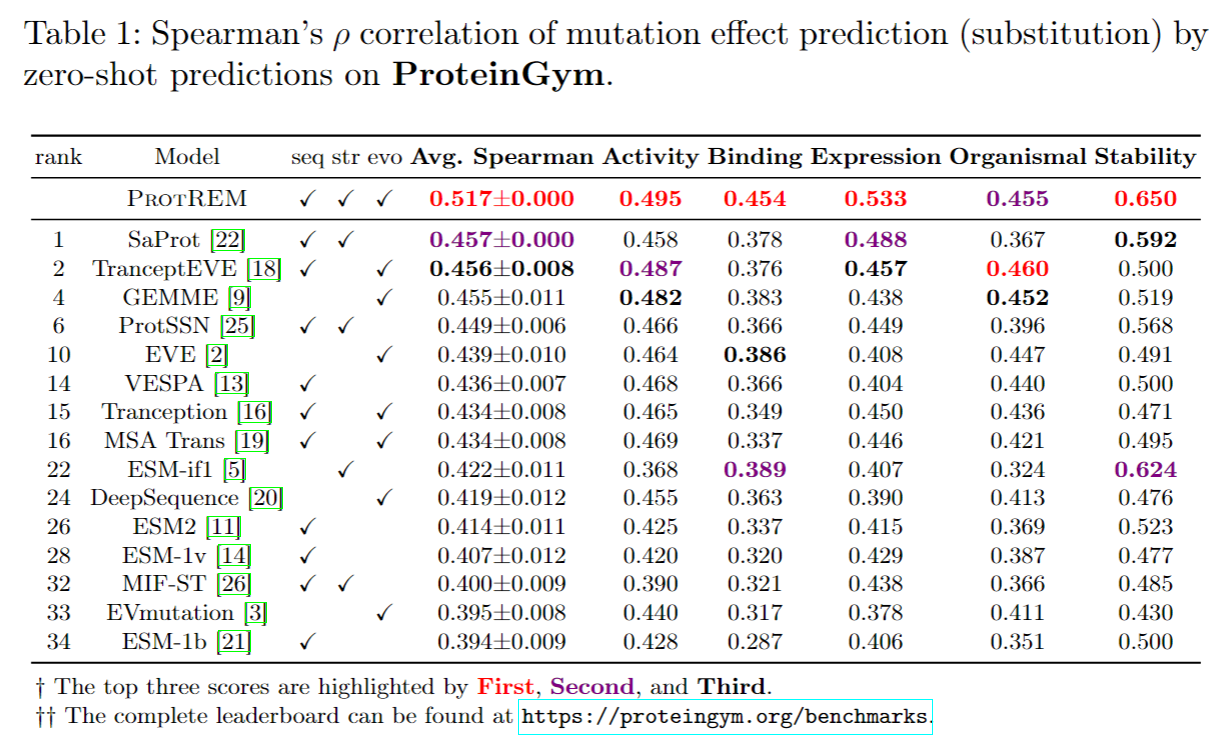
ProREM
1.0.0
ANACONDA3またはMINICONDA3をインストールしていることを確認してください。
conda env create -f environment.yml
conda activate prorem
# We need HMMER and EVCouplings for MSA
# pip install hmmer
# pip install https://github.com/debbiemarkslab/EVcouplings/archive/develop.zip
PLMCをインストールし、 src/single_config_monomer.txtのパスを変更します
git clone https://github.com/debbiemarkslab/plmc.git
cd plmc
make all-openmp cd data/proteingym_v1
wget https://huggingface.co/datasets/tyang816/ProREM/blob/main/aa_seq_aln_a2m.tar.gz
# unzip homology files
tar -xzf aa_seq_aln_a2m.tar.gz
# unzip fasta sequence files
tar -xzf aa_seq.tar.gz
# unzip pdb structure files
tar -xzf pdbs.tar.gz
# unzip structure sequence files
tar -xzf struc_seq.tar.gz
# unzip DMS substitution csv files
tar -xzf substitutions.tar.gzprotein_dir=proteingym_v1
python compute_fitness.py
--base_dir data/ $protein_dir
--out_scores_dir result/ $protein_dirdata/ < your_protein_dir_name >
| ——aa_seq # amino acid sequences
| —— | ——protein1.fasta
| —— | ——protein2.fasta
| ——aa_seq_aln_a2m # homology sequences of EVCouplings
| —— | ——protein1.a2m
| —— | ——protein2.a2m
| ——pdbs # structures
| —— | ——protein1.pdb
| —— | ——protein2.pdb
| ——struc_seq # structure sequences
| —— | ——protein1.fasta
| —— | ——protein2.fasta
| ——substitutions # mutant files
| —— | ——protein1.csv
| —— | ——protein2.csv # step 1: search homology sequences
# your protein name, eg. fluorescent_protein
protein_dir= < your_protein_dir_name >
# your protein path, eg. data/fluorescent_protein/aa_seq/GFP.fasta
query_protein_name= < your_protein_name >
protein_path=data/ $protein_dir /aa_seq/ $query_protein_name .fasta
# your uniprot dataset path
database= < your_path > /uniref100.fasta
evcouplings
-P output/ $protein_dir / $query_protein_name
-p $query_protein_name
-s $protein_path
-d $database
-b " 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9 "
-n 5 src/single_config_monomer.txt
# ? Repeat the searching process until all your proteins are done
# step 2: select a2m file
protein_dir= < your_protein_dir_name >
python src/data/select_msa.py
--input_dir output/ $protein_dir
--output_dir data/ $protein_dir Alphafold3サーバー、Alphafoldデータベース、ESMFold、その他のツールを使用して、構造を取得できます。
ウェットラブの実験については、できる限り高品質の構造を取得してください。
protein_dir= < your_protein_dir_name >
python src/data/get_struc_seq.py
--pdb_dir data/ $protein_dir /pdbs
--out_dir data/ $protein_dir /struc_seqprotein_dir= < your_protein_dir_name >
python compute_fitness.py
--base_dir data/ $protein_dir
--out_scores_dir result/ $protein_dirProtSSN(Elife 2024)またはProSst(Neurips 2024)を使用できます。
A:PROREMとProTSSN入力形式間の変換については、 script/data_format_convert.shを参照できます。プロスストの場合、jsutはアルファを0に変更します。
protein_dir= < your_protein_dir_name >
python compute_fitness.py
--base_dir data/ $protein_dir
--out_scores_dir result/ $protein_dir
--alpha 0
--model_out_name ProSST-2048A:ProTSNは、アミノ酸座標レベルでモデリングを使用し、局所構造のプロスストモデルを使用し、ProremはMSA情報を明示的に導入します。彼らはそれぞれ、実際の実験的評価において独自の利点と欠点を持っています。
コードまたはデータを使用している場合は、作業を引用してください。
@article{tan2024prorem,
title={Retrieval-Enhanced Mutation Mastery: Augmenting Zero-Shot Prediction of Protein Language Model},
author={Tan, Yang and Wang, Ruilin and Wu, Banghao and Hong, Liang and Zhou, Bingxin},
journal={arXiv:2410.21127},
year={2024}
}


