cope
v0.3 All platforms release
c hinese o ld p oem e ditor-古典的な中国の詩を書くための現代のIDE。
MacOSおよびWindowsバイナリについては、[リリース]ページの最新バージョンをダウンロードします。ダウンロードリンク
まず、npmを含むnode.jsをインストールします。
Project Directoryにcdを使用し、 npm installます。これにより、すべての依存関係がインストールされます。
最後に、 npm start 。
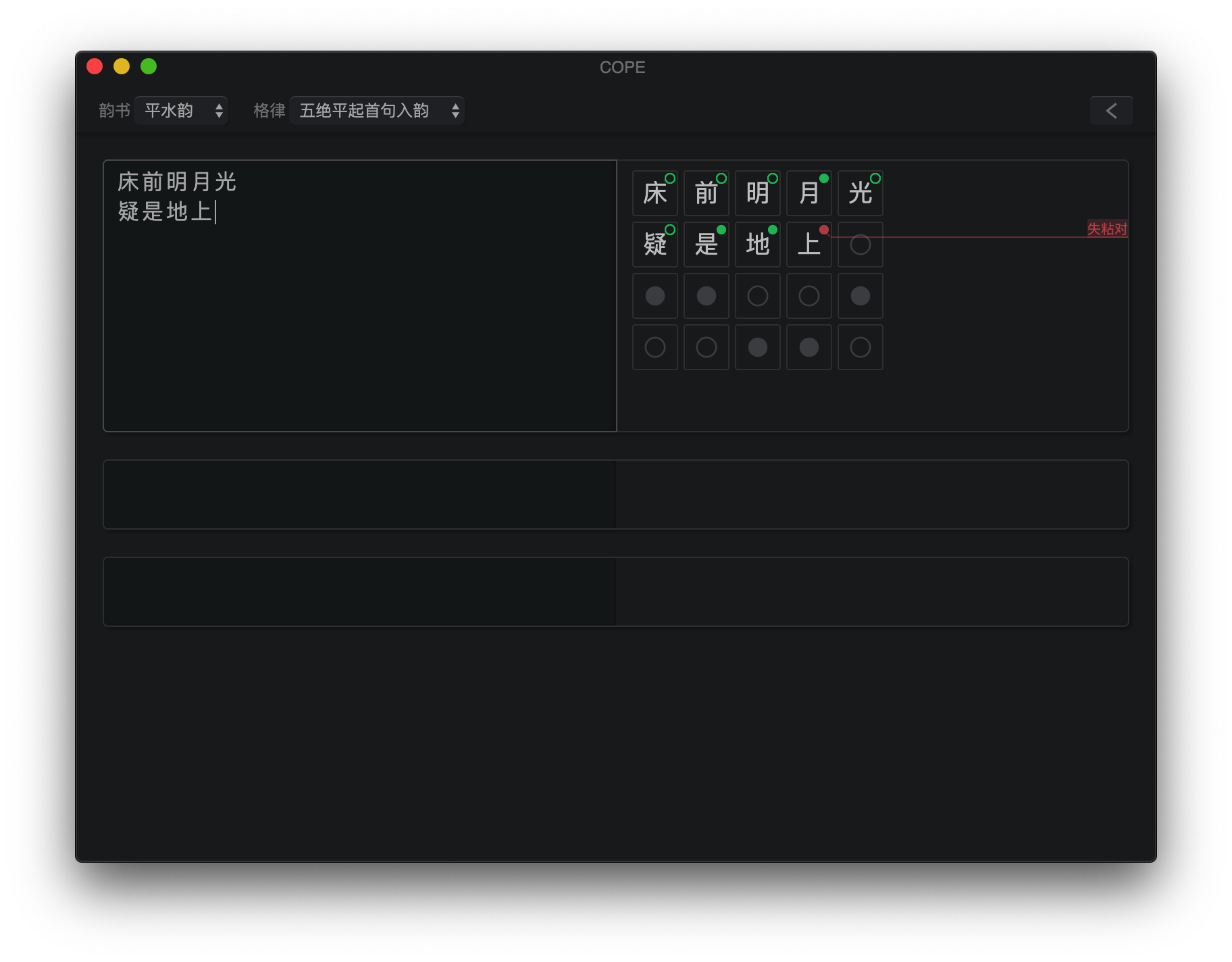
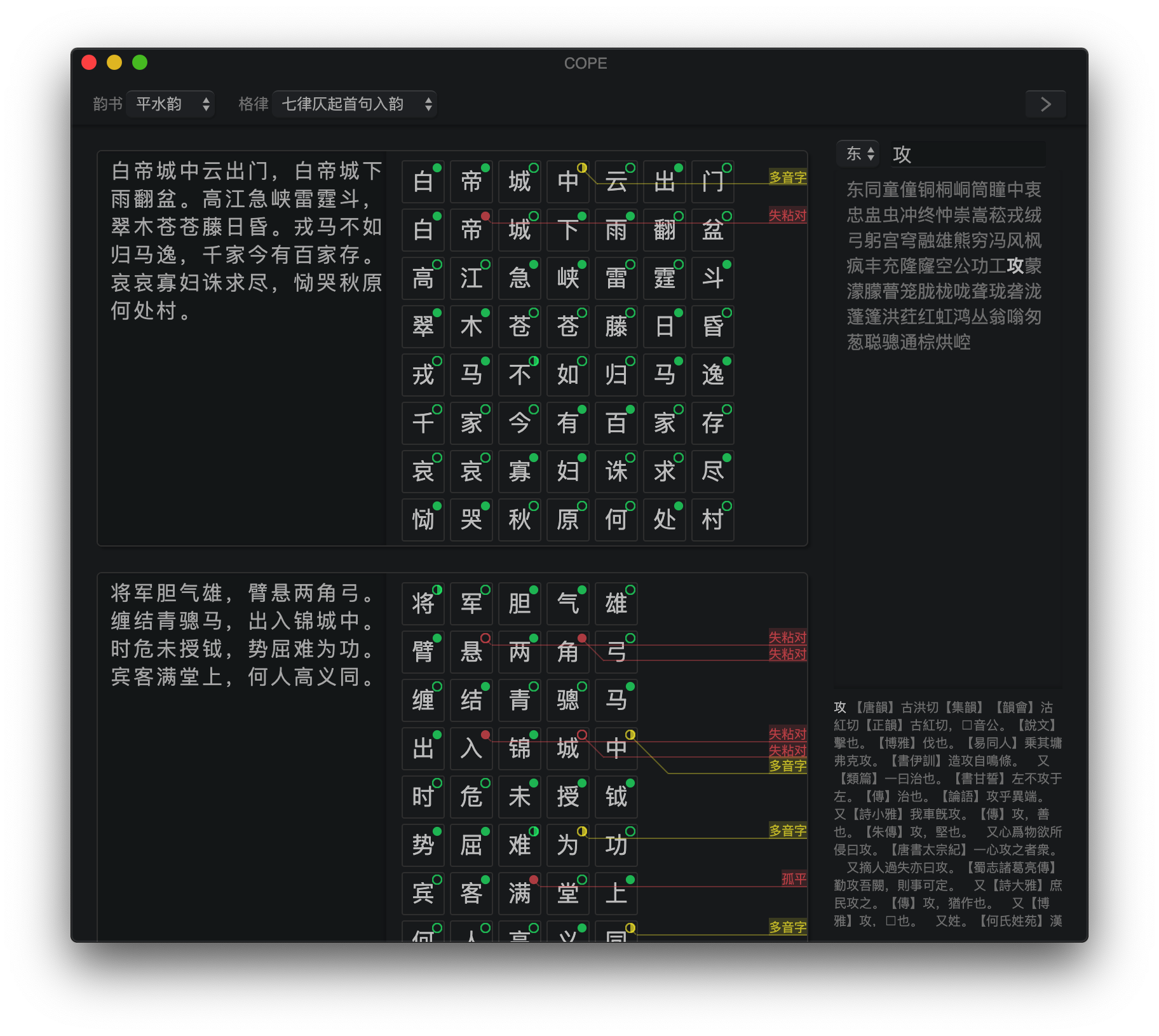
セルの左側をクリックして、内容を編集します。トーンパターンのヒントが右側に表示されます。ツールバーから韻を踏む辞書と詩のフォームを選択します。空のセルが満たされると、新しいセルが自動的に追加されます。または、メニューバーからCellsクリックすることでそれらを管理できます。 Octothorpe( # )の行の前に、詩にコメント/タイトル/帰属を追加します。 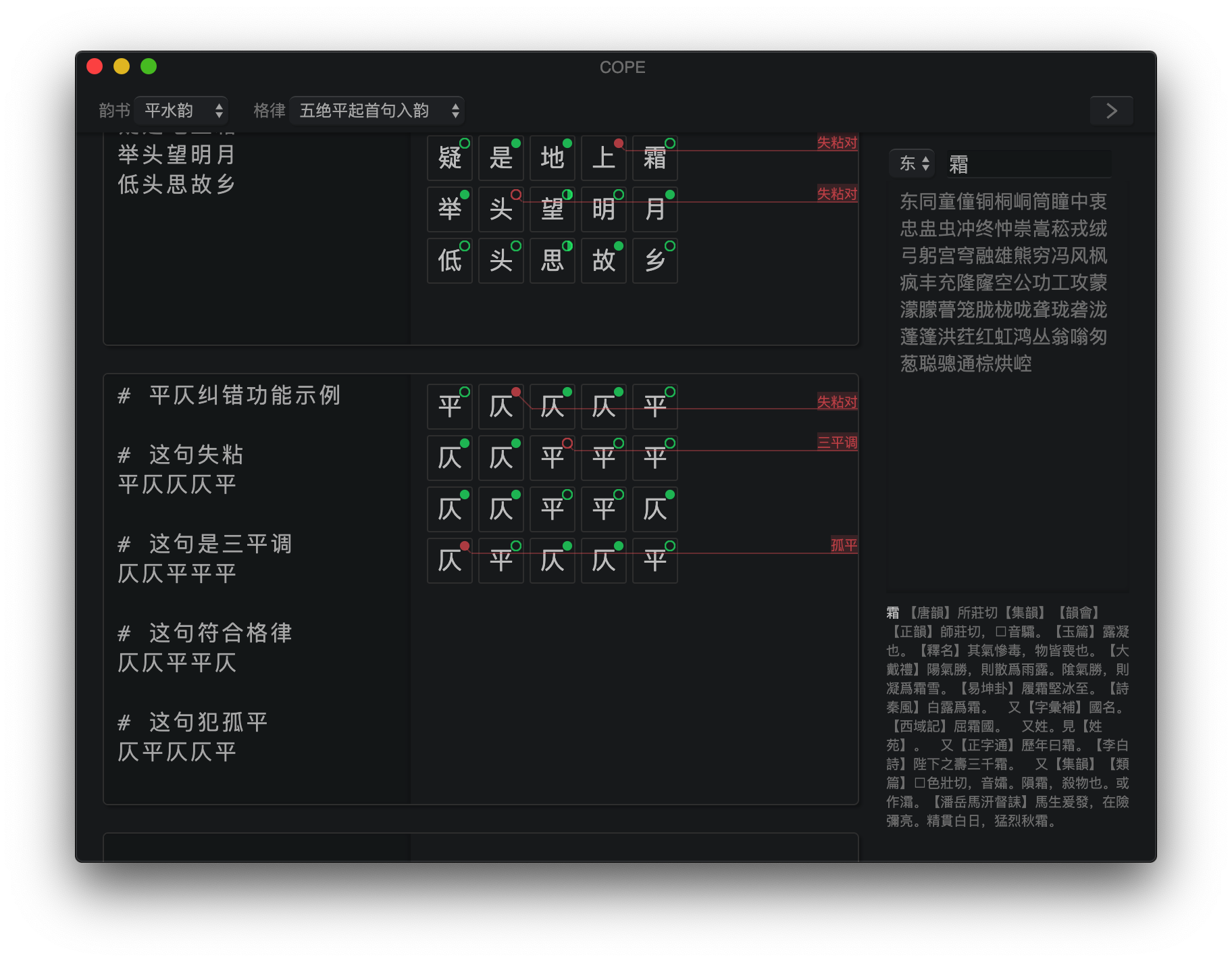
キャラクターを埋める前に、その正しい色調パターンが対応する位置に右に表示されます。そうすると、右上隅に色分けされたアイコンが表示され、キャラクターの色調パターンと、そうでない場合はエラーメッセージを指す線とともに、許容できるかどうかを示します。チェッカーは、「1、3、5、no」の一般的なルールに従いますが、「ソーラーフラット」と「3、レベルの温度」エラーが発生しないことも保証します。詩の韻は自動的に推測され、韻を踏む必要がある各キャラクターに対してチェックされます。
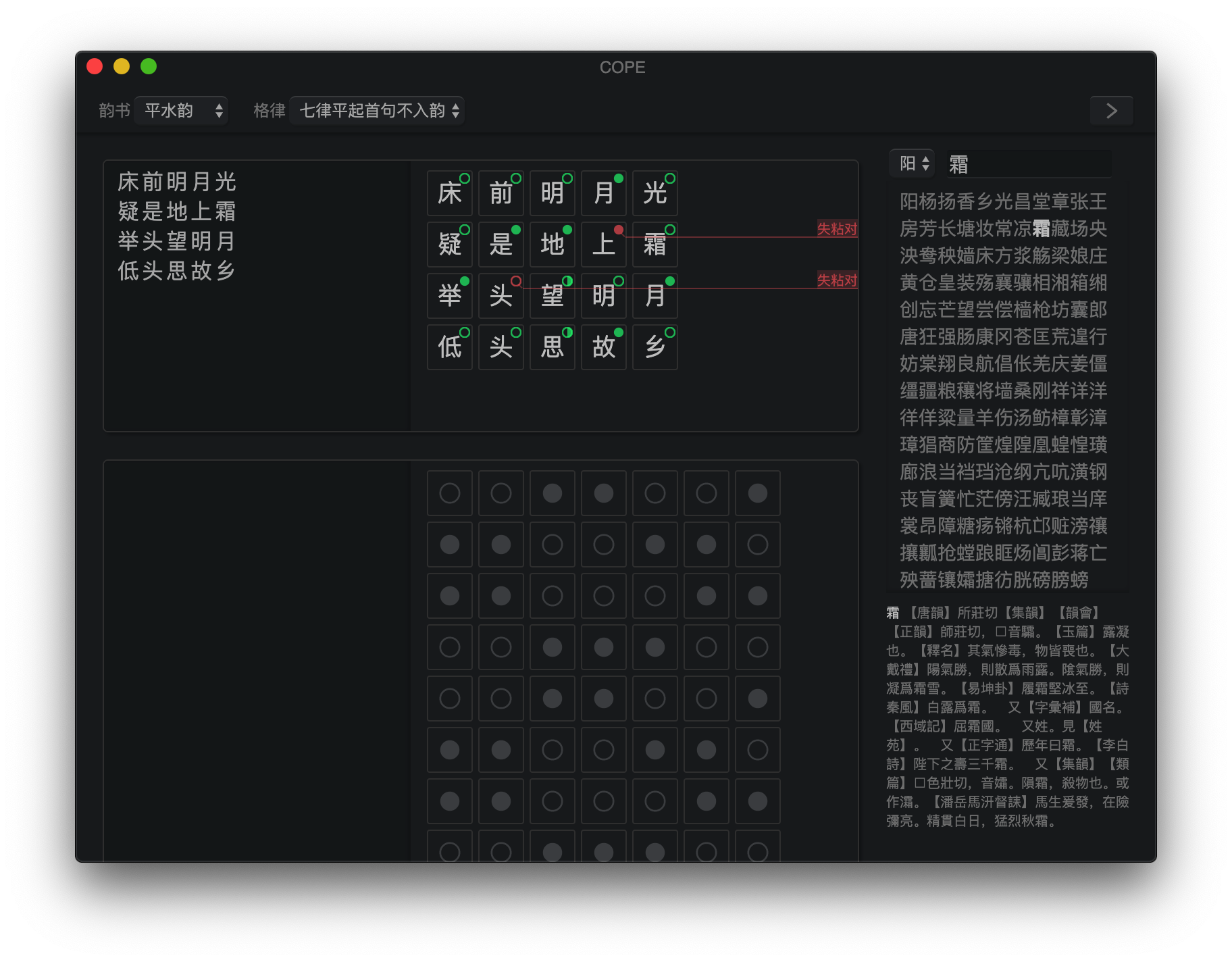
ツールバーの右側の<ボタンをクリックすると、リスミング辞書とKang XI辞書を開くことができます。検索バーの文字を入力すると、現在のリズムグループにある場合に強調表示されます。 Enterを押して、それが属するリズムグループにジャンプします。グループ内の文字をクリックして、Kang XI Dictionaryでその定義を表示します。
あなたの詩が、メニューバーのAnalysisメニューから選んだタン王朝の詩人の詩とどのように比較されるかを見ることができます。
Quan Tang Shiの詩にワードバッグモデルを適用することにより、256のTang Dynasty Poetsのそれぞれに対して1024D機能ベクトルが生成されます。ユーザーの詩のために同様のベクトルが生成されます。 UMAPは次元を2に減らすために使用されるため、ユーザーは詩がタン王朝の詩人の間の特徴空間にある場所を見ることができます。最近傍のリストが左上に示されています。
(弓モデルのパフォーマンスに関する注意:64の最も多産な詩の詩の24153詩で使用する場合、弓ベクターの最近傍の精度を見つけることで駆動される分類器は、33.4%、トップ5精度は65.6%、上位10精度は79.8%です。)
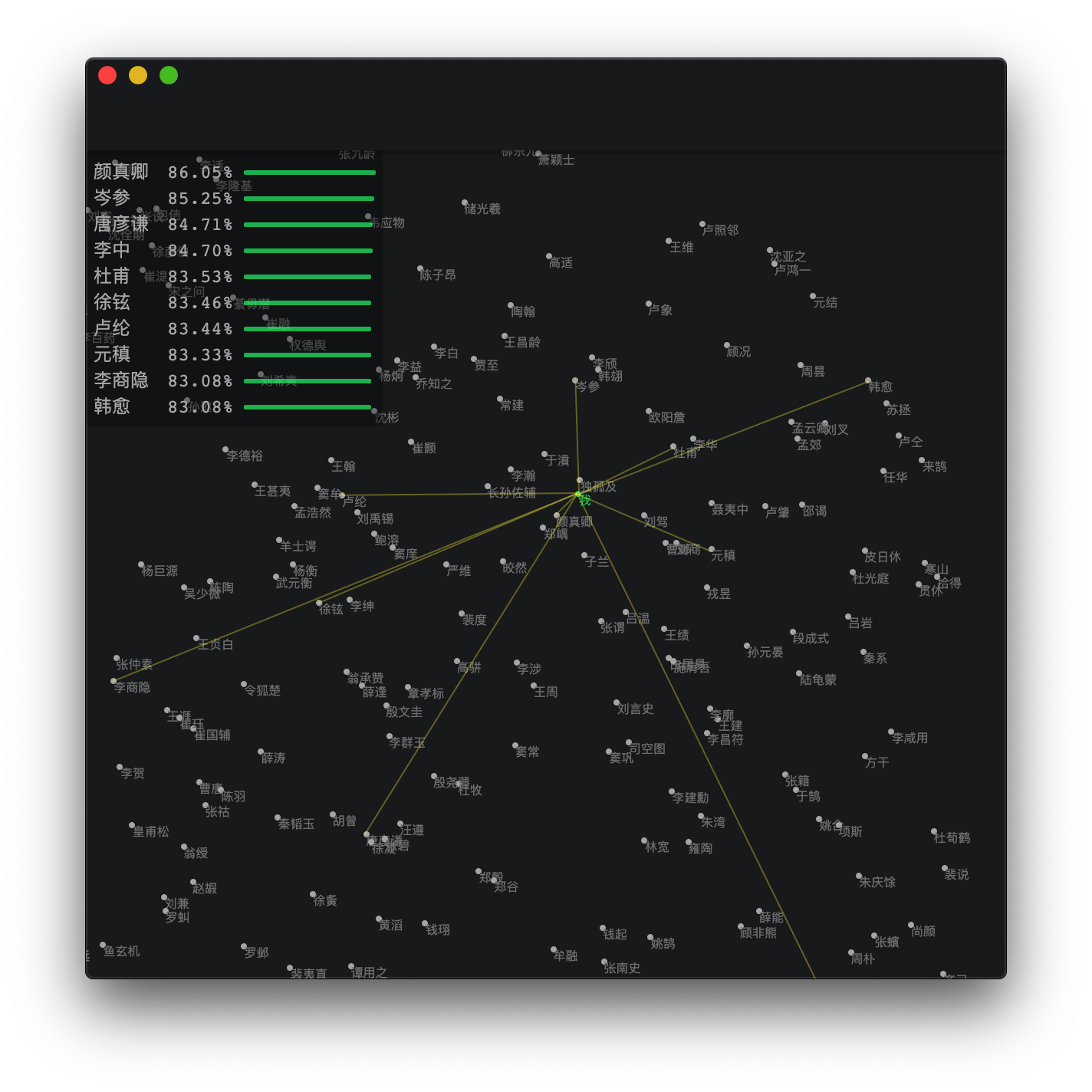 上の写真は、Li Shangyinの「DU労働者の座席の座席を残す」の手術の結果を示しています。この詩は、デュフーのスタイルを模倣したYishanの作品でなければなりません。アルゴリズムの操作結果は、両方が詩のスタイルの上位10の類似点内にあることを示しています。
上の写真は、Li Shangyinの「DU労働者の座席の座席を残す」の手術の結果を示しています。この詩は、デュフーのスタイルを模倣したYishanの作品でなければなりません。アルゴリズムの操作結果は、両方が詩のスタイルの上位10の類似点内にあることを示しています。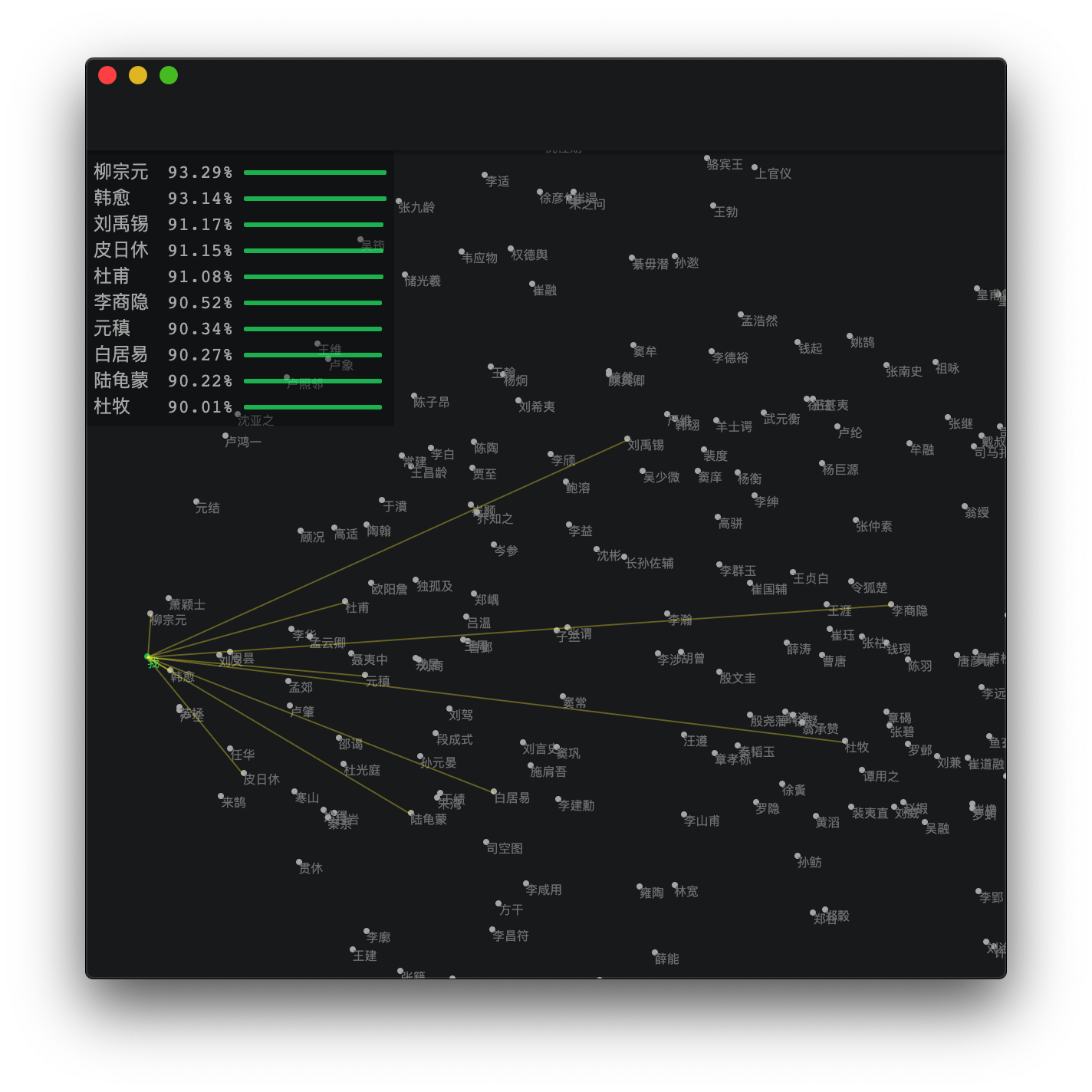 上の写真は、Li Shangyinの「Han Stele」の手術の結果を示しています。この詩は、ハンユのスタイルを模倣したYishanの作品でなければなりません。アルゴリズムの操作結果は、両方が詩のスタイルの上位10の類似点内にあることを示しています。
上の写真は、Li Shangyinの「Han Stele」の手術の結果を示しています。この詩は、ハンユのスタイルを模倣したYishanの作品でなければなりません。アルゴリズムの操作結果は、両方が詩のスタイルの上位10の類似点内にあることを示しています。
ユーザーの詩の各行について、 Quan Tang Shiは検索されて、それに最も似た行を見つけます。これは、過去の偉大なマスターがどのように同様の意味をもたらしたかを示すため、ユーザーがより良い詩を書くのに役立つかもしれません。
 上の写真は、清王朝のhuangジンレンによる詩「qihuai」の作戦の結果を示しています。詩の最初の2つのカプレットは、アルゴリズムの正しい調査のためのLi Yishanとして使用する必要があります。
上の写真は、清王朝のhuangジンレンによる詩「qihuai」の作戦の結果を示しています。詩の最初の2つのカプレットは、アルゴリズムの正しい調査のためのLi Yishanとして使用する必要があります。
現在の詩で満たされていないまたは暴力的な色調のルールがないキャラクターは、推奨される編集に自動的に置き換えられます。オプションでは、二重性/シングルとスタンドアロンを使用します。詩のスタイル(詩スタイル)は、タン王朝の詩人のスタイルからも選択できます。この機能は、詩全体を生成するためにも使用できますが(そしてかなりうまくいきます)、そのような使用は、編集者としてのソフトウェアの目的と一致しないため、奨励されていません。完全な中国の詩ジェネレーターについては、私のこのプロジェクトをチェックしてください。
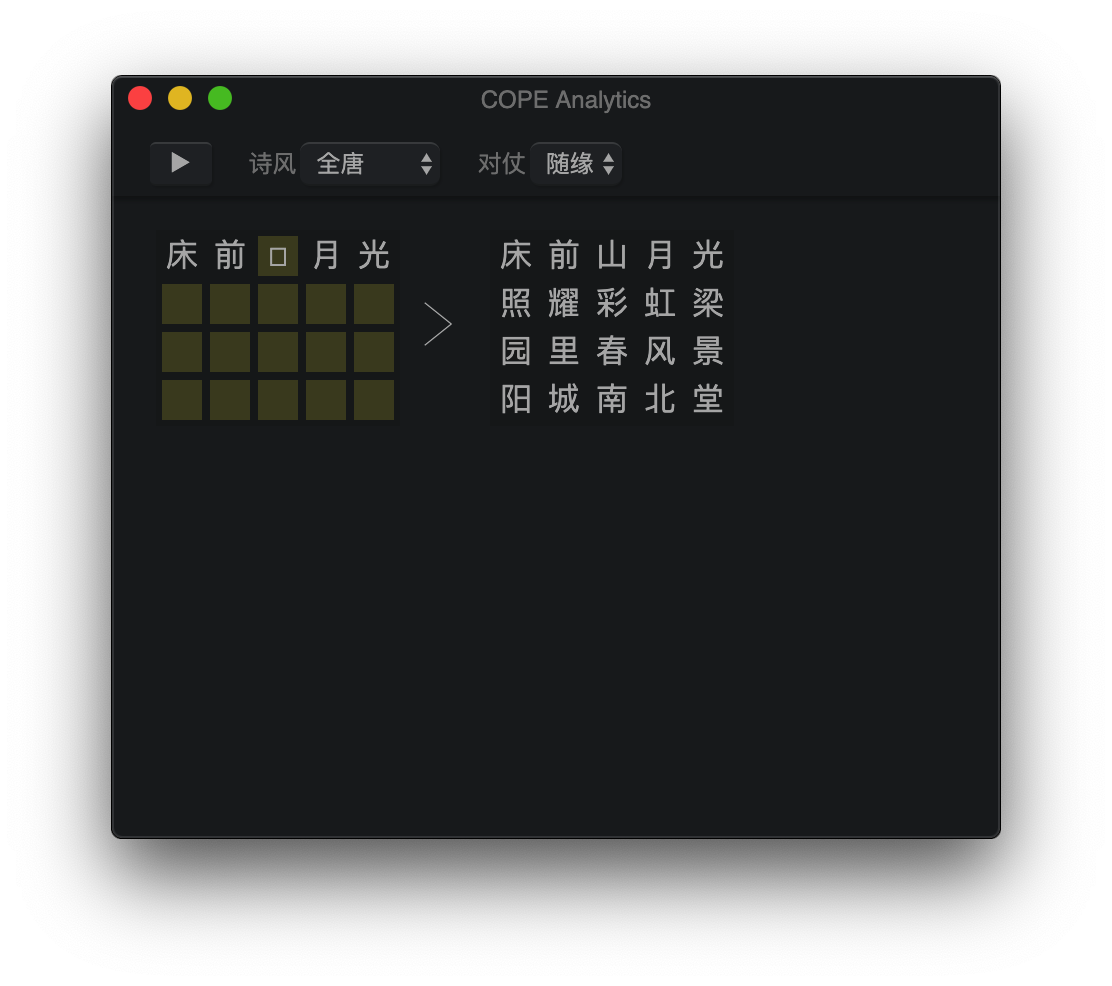 | 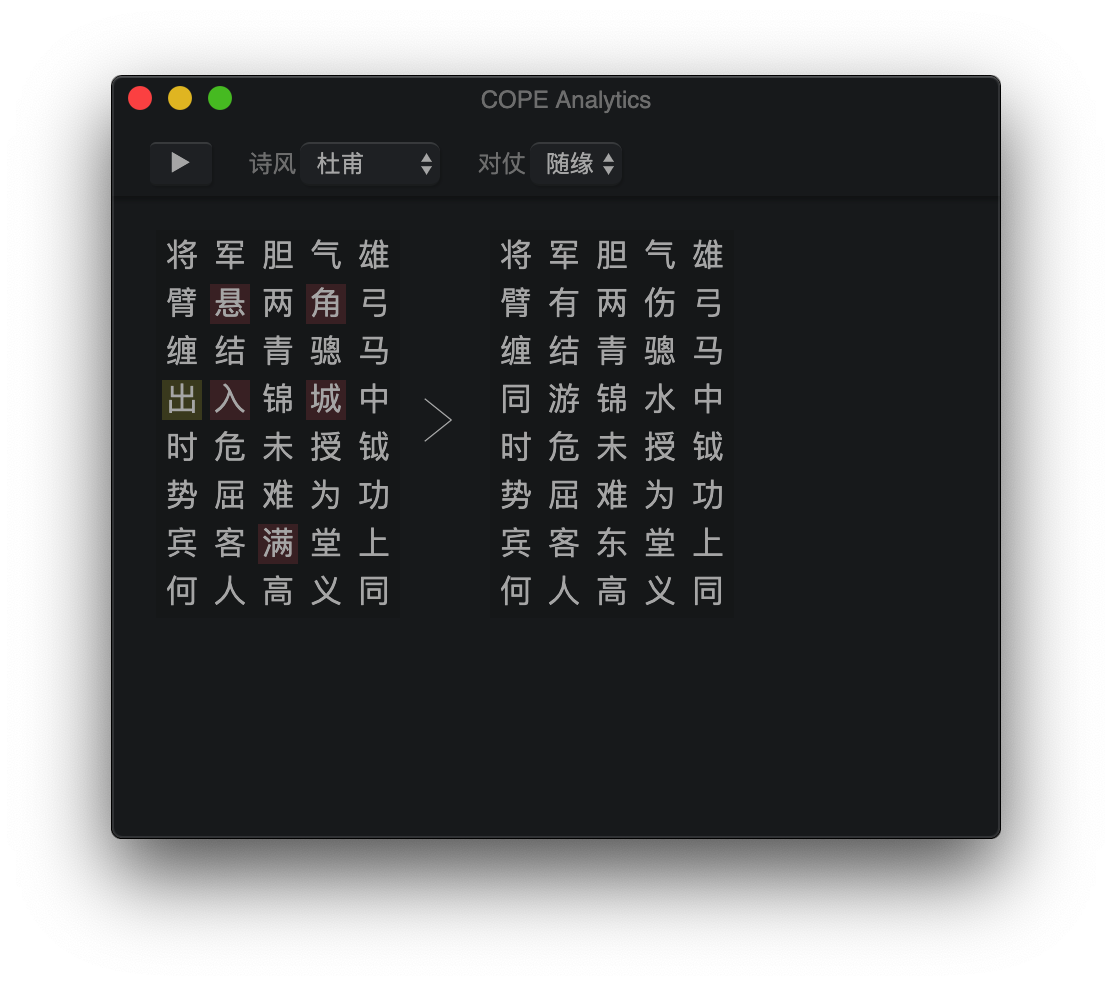 |
|---|---|
 |  |
すべての提案とプルリクエストは大歓迎です!


