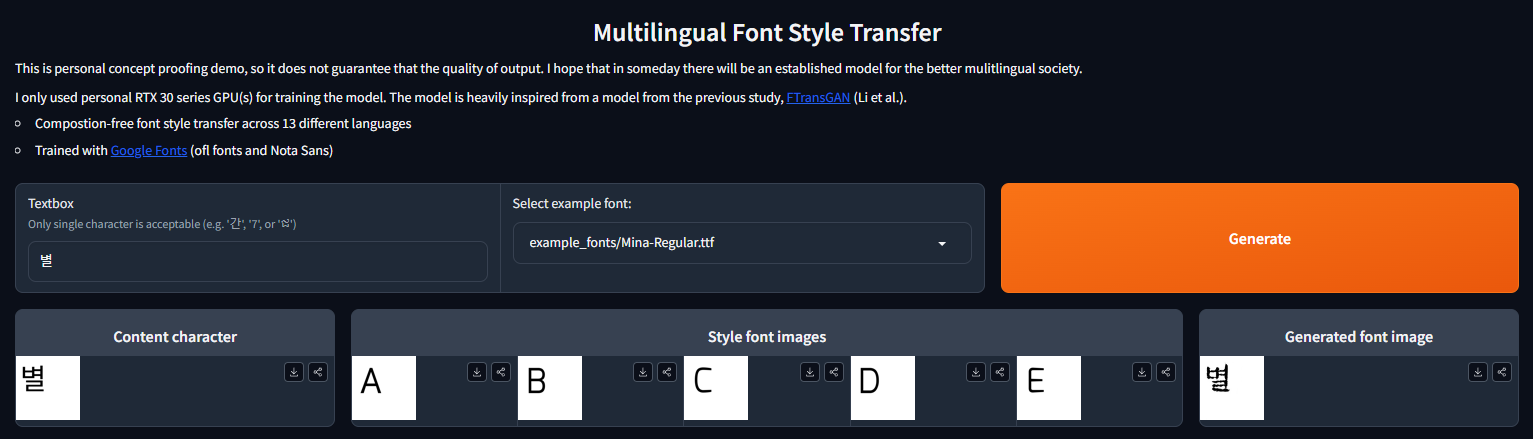
multilingual font style transfer
1.0.0
これは、異なる言語間のペーパー少ないショットフォントスタイルの転送のための非公式の実装です。著者からの元の実装はここにあります。
deepkyu/multiingual-font-font-style-transfer
2023.09.29コードを新たに更新し、韓国語、日本語、漢字をサポートするようにモデルをトレーニングします。このコードと統合する時間がないため、トレーニングコードはこのレポでまだ更新されていません。しかし、私は、現在の「多言語フォントスタイルの転送」が理にかなっているかどうかを示すために、抱きしめる顔のスペースを作りました。可能な限り、次の多言語社会をサポートできる、より確立されたフォントスタイルの転送モデルを取得できるまで更新します!
requiress.txtを参照してください
評価のために、事前に処理されたチェックポイントをpretrainedのディレクトリにダウンロードします。
Ftransganの元のデータの場合、公式リポジトリからダウンロードできます。
多言語データセットの場合、Google Driveリンクからダウンロードできます。
それぞれのdata/ftgan-fontsおよびdata/google-fontsで見つけてください。
python trainer.py
ftrasnganとそのデータの結果については、
bash evaluate-ftgan.sh
デフォルトのオプションは、 test_unknown_contentを使用しています。値をTrueからFalseに切り替えることにより、 config/datasets/ftgan.yamlで変更できます。 ( Falseの場合、 test_unknown_styleで評価します。)
Googleフォントデータの結果については、
bash evaluate-google-font.sh
2022.12.04
このコードは、コンピューターサイエンスの特別なトピックにおける私の最終学期プロジェクトの一部です - ディープラーニングの紹介(CS492i) (2022 Fall、Kaist)。
私の提案の目標は、特定の言語の新しいフォントを生成することです。そのスタイルは、他の言語のフォントから転送されます。
このプロジェクトでは、Google/Fontリポジトリを使用して、10の異なる言語のフォント画像を含むGoogle Fonts Datasetを定義しました。
しかし、目に見えない言語のフォント生成モデルを導入することに失敗しました。代わりに、このプロジェクトのコアコンセプトを説明するために、トレーニングデータセットでいくつかの結果を共有します。
数日でこのプロジェクトをうまく終えることができることを願っています:)