mentals ai
1.0.0
Mentals AIは、.gen拡張機能を備えた簡単なmarkdownファイルを介して、 loops 、 memory 、およびさまざまなtoolsを備えたエージェントを作成および操作するために設計されたツールです。エージェントファイルを実行可能ファイルと考えてください。エージェントの論理に完全に焦点を当て、Pythonまたはその他の言語で足場コードを作成する必要性を排除します。基本的に、将来のAIアプリケーションの基礎フレームワークを再定義しますか?
注記
LLMによって制御されたセルフループのワードチェーンゲーム: 
NLOP - 自然言語操作
またはより複雑なユースケース:
| マルチエージェントの相互作用 | ? Space Invadersジェネレーターエージェント | ? 2Dプラットフォーマージェネレーターエージェント |
|---|---|---|
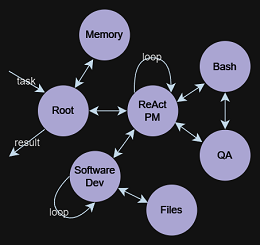 |  |  |
またはコンテンツを手伝ってください:
上記の例はすべて、エージェントフォルダーにあります。
注記
LLAMA3サポートは、互換性のあるOpenAI APIを使用してプロバイダーが利用できます。
OpenAIアカウントの作成を通じてOpenAI APIキーを保護することから始めます。既にAPIキーがある場合は、この手順をスキップしてください。
前提条件
プロジェクトを構築する前に、次の依存関係がインストールされていることを確認してください。
オペレーティングシステムによっては、次のコマンドを使用してこれらをインストールできます。
Linux
sudo apt-get update
sudo apt-get install libcurl4-openssl-dev libfmt-dev libpoppler-devmacos
brew update
brew install curl fmt popplerWindows
Windowsの場合、VCPKGまたは同様のパッケージマネージャーを使用することをお勧めします。
vcpkg install curl fmt popplerPGVectorのインストール
注記
mainブランチでは、この手順をスキップできます
リポジトリをクローンします
git clone https://github.com/turing-machines/mentals-ai
cd mentals-ai構成
config.tomlファイルにAPIキーを配置します。
[llm]
# OpenAI
api_key = " "
endpoint = " https://api.openai.com/v1 "
model = " gpt-4o "プロジェクトを構築します
make走る
./build/mentals agents/loop.gen -dメンタルAIは、3つの重要な方法で他のフレームワークと区別します。
Agent Executor ?再帰ループを介して動作します。 LLMは、次のステップを決定します。これは、以前のループに基づいて、指示(プロンプト)の選択(プロンプト)とデータの管理です。この再帰的意思決定プロセスは、Mentals_system.promptで概説されているシステムに不可欠ですMarkdownを使用して作成でき、従来のプログラミング言語の必要性を排除できます。ただし、Pythonは、必要に応じてエージェントのMarkdownスクリプトに直接統合できます。Tree of Thoughts 、 ReAct 、 Self-Discovery 、 Auto-CoTなど、既存のフレームワークを含む独自の推論フレームワークの作成と統合が可能になります。また、これらのフレームワークをより複雑なシーケンスに結び付けて、さまざまな推論フレームワークのネットワークを作成することもできます。 エージェントファイルは、 .gen拡張機能を備えたエージェント命令のテキスト説明です。
指導は、メンタルにおけるエージェントの基本的なコンポーネントです。エージェントは、互いに参照できる1つ以上の指示で構成できます。
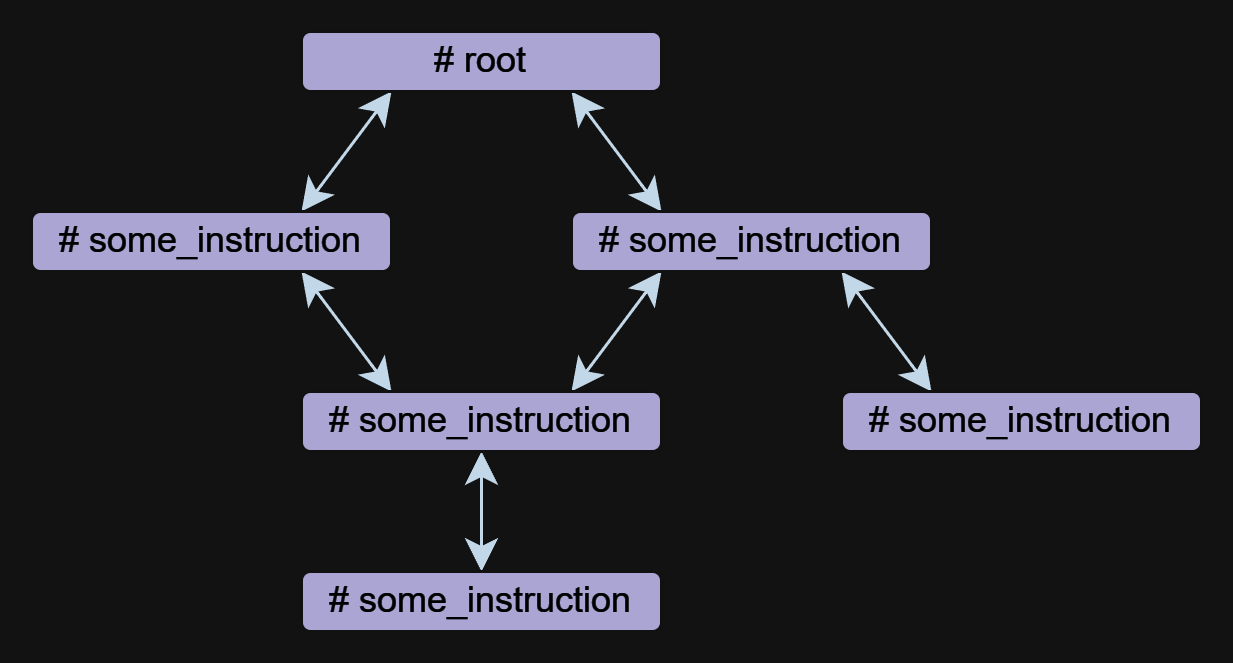
手順は自由形式で書くことができますが、それらは常に#シンボルから始まる名前を持っています。 ## use:ディレクティブは、他の命令への参照を指定するために使用されます。複数の参照がコンマで区切られています。
以下は、2つの命令をrootとmeme_explain含む例です。
# root
## use: meme_explain
1. Create 3 memes about AGI;
2. Then do meme explain with meme per call;
3. Output memes and their explanations in a list.
# meme_explain
Explain the gist of the meme in 20 words in medieval style.
Return explanation.
この例では、 root命令はmeme_explain命令を呼び出します。 MEME_EXPLAINからの応答は、それが呼ばれた命令、つまりルートに戻されます。
命令は、命令が呼び出されたときにコンテキストに基づいて自動的に生成されるinputパラメーターを取得できます。入力データをより正確に指定するには、JSONオブジェクトやnullなどの## input:ディレクティブでフリーフォームプロンプトを使用できます。
入力にドキュメントの使用:
# some_instruction
## input: design document only
JSONオブジェクトを入力として使用します。
# duckduckgo
## input: { search_query: search query, search_limit: search limit }
Write a Python script to search in DuckDuckGo.
Simulate request headers correctly e.g. user-agent as Mozilla and Linux.
注記
命令呼び出しは、OpenAIでの機能またはツール呼び出しとは独立して実装されており、LLAMA3などのモデルを使用してエージェントの動作を可能にします。命令呼び出しの実装は透明であり、Mentals_system.promptファイルに含まれています。
ツールは一種の指示です。 Mentalsには、メッセージ出力、ユーザー入力、ファイル処理、Pythonインタープリター、BASHコマンド、および短期メモリを処理するための一連のネイティブツールがあります。
ユーザーの例:
# root
## use: user_input
Ask user name.
Then output: `Welcome, user_name!`
ファイル処理例:
# root
## use: write_file, read_file
Write 'Hello world' to a file.
Then read and output file content.
ネイティブツールの完全なリストは、ファイルnative_tools.tomlにリストされています。
各命令には、コンテキストという独自の作業記憶があります。命令を終了して再入力するとき、コンテキストはデフォルトで保持されます。命令を終了するときにコンテキストをクリアするには、 ## keep_context: falseディレクティブを使用できます。
# meme_explain
## keep_context: false
Explain the gist of the meme in 20 words in medieval style.
Return explanation.
デフォルトでは、命令コンテキストのサイズに限定されません。コンテキストを制限するには、ディレクティブ## max_context: number最新のメッセージのnumberのみを保存する必要があることを指定する番号があります。古いメッセージはコンテキストから押し出されます。この機能は、古いデータが推論のチェーンに影響を与えないように、最新のデータをコンテキストに保持したい場合に役立ちます。
# python_code_generation
## input: development tasks in a list
## use: write_file
## max_context: 5
Do all development tasks in a loop: task by task.
Save the Python code you implement in the main.py file.
短期メモリにより、エージェントのアクティビティから中間結果を保存することができ、さらに推論するために使用できます。このメモリの内容は、すべての命令コンテキストでアクセスできます。
memoryツールは、データを保存するために使用されます。データが保存されると、コンテンツのキーワードと説明が生成されます。以下の例では、 meme_recall命令は、以前にメモリに保存されていたため、MEMEを認識しています。
# root
## use: memory, meme_recall
Come up with and memorize a meme.
Call meme recall.
# meme_recall
## input: nothing
What the meme was about?
条件、命令コール、ループ( ReAct 、 Auto-CoTなど)を含む制御フローは、自然言語で完全に表現されます。この方法により、データストリームの分岐を指示するsemantic conditionsの作成が可能になります。たとえば、エージェントにループでワードチェーンゲームを自律的に再生するように要求するか、曖昧な出口条件を確立することができます。 exit the loop if you are satisfied with the result 。ここで、言語モデルとそのコンテキストは、継続するか停止するかを決定します。これはすべて、Pythonまたはその他のプログラミング言語でフローロジックを定義する必要なく達成されます。
## use: execute_bash_command, software_development, quality_assurance
...
You run in a loop of "Thought", "Action", "Observation".
At the end of the loop return with the final answer.
Use "Thought" to describe your thoughts about the task
you have been asked. Use "Action" to run one of the actions
available to you. Output action as: "Action: action name to call".
"Observation" will be the result of running those actions.
Your available actions:
- `execute_bash_command` for util purposes e.g. make directory, install packages, etc.;
- `software_development` for software development and bug fixing purposes;
- `quality_assurance` for QA testing purposes.
...
TOTの背後にあるアイデアは、問題を解決するために複数のアイデアを生成し、その価値を評価することです。貴重なアイデアは保持され、開発されており、他のアイデアは破棄されます。
24ゲームの例を見てみましょう。 24パズルは、最終結果が24になるように4つの整数を操作する方法を見つけることである算術パズルです。最初に、ツリーデータ構造を作成および操作する命令を定義します。モデルは、ツリーが何であるかを知っており、プレーンテキストからXML/JSONまたは任意のカスタム形式まで、あらゆる形式で表現できます。
この例では、プレーンテキスト形式を使用します。
# tree
## input: e.g. "add to node `A` child nodes `B` and `C`", "remove node `D` with all branches", etc.
## use: memory
## keep_context: false
Build/update tree structure in formatted text.
Update the tree structure within the specified action;
Memorize final tree structure.
次に、最初のデータでツリーを初期化する必要があります。ルート命令から始めましょう。
# root
## use: tree
Input: 4 5 8 2
Generate 8 possible next steps.
Store all steps in the tree as nodes e.g.
Node value 1: "2 + 8 = 10 (left: 8 10 14)"
Node value 2: "8 / 2 = 4 (left: 4 8 14)"
etc.
ルート命令を呼び出すと、最初の2つの数値で計算し、これらの手順をツリーノードとして保存する8つの可能な次のステップが示唆されます。エージェントによるさらなる作業により、モデルが最終的な答えを理解し、推測するのに便利なツリーの構築が行われます。
4 5 8 2
├── 4 + 5 = 9 (left: 9, 8, 2)
│ └── discard
├── 4 + 8 = 12 (left: 12, 5, 2)
│ └── discard
├── 4 + 2 = 6 (left: 6, 5, 8)
│ └── discard
├── 5 + 8 = 13 (left: 13, 4, 2)
│ └── discard
├── 5 + 2 = 7 (left: 7, 4, 8)
│ └── (7 - 4) * 8 = 24
├── 8 + 2 = 10 (left: 10, 4, 5)
│ └── discard
├── 4 * 5 = 20 (left: 20, 8, 2)
│ └── (20 - 8) * 2 = 24
└── 4 * 8 = 32 (left: 32, 5, 2)
└── discard
Based on the evaluations, we have found two successful paths to reach 24:
1. From the node "5 + 2 = 7 (left: 7, 4, 8)", we have the equation: (7 - 4) * 8 = 24.
2. From the node "4 * 5 = 20 (left: 20, 8, 2)", we have the equation: (20 - 8) * 2 = 24.
Thus, the final equations using all given numbers from the input are:
1. (5 + 2 - 4) * 8 = 24
2. (4 * 5 - 8) * 2 = 24
エージェント/tree_structure.genには完全な例が含まれています
この概念は、精神分析の執行機能に関する研究、中央幹部、Alan Baddeley、Alan Baddeley、1996年の研究に由来しました。彼は、認知プロセスと作業記憶を調整するシステムを説明し、長期記憶からの検索を促進しました。 LLMは、 System 1として機能し、固有の動機付けや目標設定なしで命令を処理し、実行します。それでは、 System 2とは何ですか?歴史的な洞察から描画され、現在は科学的なレンズを通して再考されています。
中央エグゼクティブ、またはエグゼクティブ機能は、作業メモリでの制御処理に不可欠です。注意の指示、タスクの目的の維持、意思決定、メモリの取得などのタスクを管理します。
これは興味深い可能性を引き起こします。 System 1とSystem 2統合することにより、より洗練されたエージェントを構築することです。 Cognitive Exector System 1としてのLLMは、LLMを管理および制御する中央エグゼクティブSystem 2と連携して機能します。このパートナーシップは、メンタルAIの基礎となる二重関係を形成します。


