mentals ai
1.0.0
Mentals AI est un outil conçu pour la création et les agents d'exploitation qui comportent loops , memory et divers tools , tout au long du fichier markdown simple avec une extension .Gen. Considérez un fichier d'agent comme un fichier exécutable. Vous vous concentrez entièrement sur la logique de l'agent, éliminant la nécessité d'écrire du code d'échafaudage dans Python ou dans toute autre langue. Essentiellement, il redéfinit les cadres fondamentaux des futures applications d'IA?
Note
Jeu de chaîne de mots dans une boucle d'auto-boucle contrôlée par LLM: 
NLOP - opération de langue naturelle
Ou des cas d'utilisation plus complexes:
| Toutes les interactions multi-agents | ? Agent générateur des envahisseurs d'espace | ? Agent de générateur de plateforme 2D |
|---|---|---|
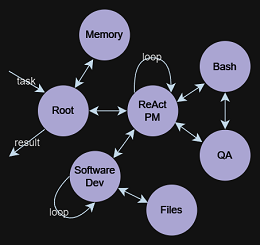 |  |  |
Ou aide avec le contenu:
Tous les exemples ci-dessus sont situés dans le dossier Agents.
Note
Le support LLAMA3 est disponible pour les fournisseurs utilisant une API OpenAI compatible.
Commencez par sécuriser une clé API OpenAI par la création d'un compte Openai. Si vous avez déjà une clé API, sautez cette étape.
Condition préalable
Avant de construire le projet, assurez-vous que les dépendances suivantes sont installées:
Selon votre système d'exploitation, vous pouvez les installer en utilisant les commandes suivantes:
Linux
sudo apt-get update
sudo apt-get install libcurl4-openssl-dev libfmt-dev libpoppler-devmacos
brew update
brew install curl fmt popplerFenêtre
Pour Windows, il est recommandé d'utiliser VCPKG ou un gestionnaire de packages similaire:
vcpkg install curl fmt popplerInstallation de PGVector
Note
Dans la branche main vous pouvez sauter cette étape
Cloner le référentiel
git clone https://github.com/turing-machines/mentals-ai
cd mentals-aiConfiguration
Placez votre touche API dans le fichier config.toml :
[llm]
# OpenAI
api_key = " "
endpoint = " https://api.openai.com/v1 "
model = " gpt-4o "Construire le projet
makeCourir
./build/mentals agents/loop.gen -dMentals AI se distingue des autres cadres de trois façons importantes:
Agent Executor ? fonctionne à travers une boucle récursive. Le LLM détermine les étapes suivantes: sélectionner les instructions (invites) et gérer les données en fonction des boucles précédentes. Ce processus de prise de décision récursif fait partie intégrante de notre système, décrit dans mentals_system.promptMarkdown , éliminant le besoin de langages de programmation traditionnels. Cependant, Python peut être intégré directement dans le script Markdown de l'agent si nécessaire.Tree of Thoughts , ReAct , Self-Discovery , Auto-CoT et autres. On peut également relier ces cadres vers des séquences plus complexes, créant même un réseau de divers cadres de raisonnement. Le fichier d'agent est une description textuelle des instructions de l'agent avec une extension .gen .
L'instruction est le composant de base d'un agent dans les mentaux. Un agent peut être composé d'une ou plusieurs instructions, qui peuvent se référer les unes aux autres.
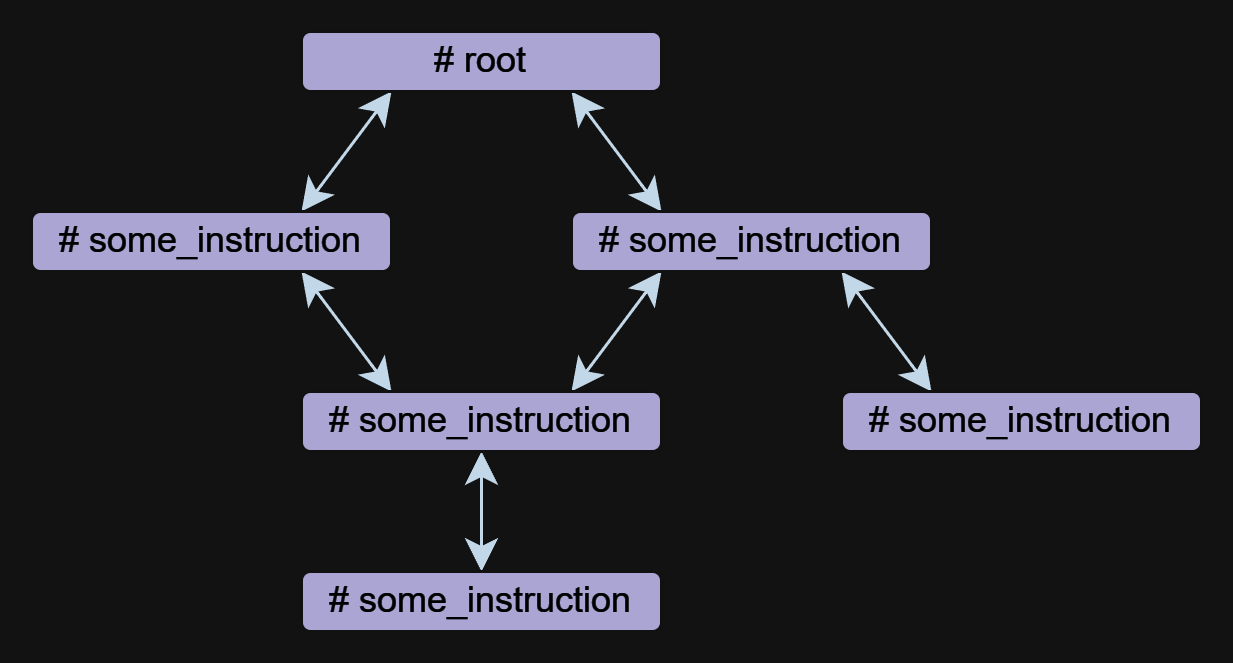
Les instructions peuvent être écrites sous forme gratuite, mais elles ont toujours un nom qui commence par le symbole # . La directive ## use: est utilisée pour spécifier une référence à d'autres instructions. Plusieurs références sont répertoriées séparées par des virgules.
Vous trouverez ci-dessous un exemple avec deux instructions root et meme_explain avec une référence:
# root
## use: meme_explain
1. Create 3 memes about AGI;
2. Then do meme explain with meme per call;
3. Output memes and their explanations in a list.
# meme_explain
Explain the gist of the meme in 20 words in medieval style.
Return explanation.
Dans cet exemple, l'instruction root appelle l'instruction meme_explain . La réponse de meme_explain est ensuite retournée à l'instruction à partir de laquelle elle a été appelée, à savoir la racine.
Une instruction peut prendre un paramètre input , qui est automatiquement généré en fonction du contexte lorsque l'instruction est appelée. Pour spécifier plus précisément les données d'entrée, vous pouvez utiliser une invite de forme libre dans la directive ## input: telle qu'un objet JSON ou null .
Utilisation d'un document pour l'entrée:
# some_instruction
## input: design document only
Utilisation d'un objet JSON comme entrée:
# duckduckgo
## input: { search_query: search query, search_limit: search limit }
Write a Python script to search in DuckDuckGo.
Simulate request headers correctly e.g. user-agent as Mozilla and Linux.
Note
Les appels d'instructions sont implémentés indépendamment de la fonction ou des appels d'outils à OpenAI, permettant le fonctionnement d'agents avec des modèles comme LLAMA3. La mise en œuvre des appels d'instruction est transparente et incluse dans le fichier mentals_system.prompt.
L'outil est une sorte d'instruction. Mentals a un ensemble d'outils natifs pour gérer la sortie du message, l'entrée utilisateur, la gestion des fichiers, l'interprète Python, les commandes bash et la mémoire à court terme.
Demandez à l'exemple de l'utilisateur:
# root
## use: user_input
Ask user name.
Then output: `Welcome, user_name!`
Exemple de traitement des fichiers:
# root
## use: write_file, read_file
Write 'Hello world' to a file.
Then read and output file content.
La liste complète des outils natives est répertoriée dans le fichier native_tools.toml .
Chaque instruction a sa propre mémoire de travail - contexte. Lors de la sortie d'une instruction et de la rentrée, le contexte est conservé par défaut. Pour effacer le contexte lors de la sortie d'une instruction, vous pouvez utiliser le ## keep_context: false directive:
# meme_explain
## keep_context: false
Explain the gist of the meme in 20 words in medieval style.
Return explanation.
Par défaut, la taille du contexte d'instruction n'est pas limitée. Pour limiter le contexte, il existe une directive ## max_context: number qui spécifie que seul le number des messages les plus récents doit être stocké. Les messages plus anciens seront expulsés du contexte. Cette fonctionnalité est utile lorsque vous souhaitez conserver les données les plus récentes en contexte afin que les données plus anciennes n'affectent pas la chaîne de raisonnement.
# python_code_generation
## input: development tasks in a list
## use: write_file
## max_context: 5
Do all development tasks in a loop: task by task.
Save the Python code you implement in the main.py file.
La mémoire à court terme permet le stockage des résultats intermédiaires des activités d'un agent, qui peuvent ensuite être utilisées pour un raisonnement supplémentaire. Le contenu de cette mémoire est accessible dans tous les contextes d'instructions.
L'outil memory est utilisé pour stocker les données. Lorsque les données sont stockées, un mot-clé et une description du contenu sont générés. Dans l'exemple ci-dessous, l'instruction meme_recall est consciente du mème car elle était précédemment stockée en mémoire.
# root
## use: memory, meme_recall
Come up with and memorize a meme.
Call meme recall.
# meme_recall
## input: nothing
What the meme was about?
Le flux de contrôle, qui comprend des conditions, des appels d'instructions et des boucles (tels que ReAct , Auto-CoT , etc.), est entièrement exprimé en langage naturel. Cette méthode permet la création de semantic conditions qui dirigent la ramification des flux de données. Par exemple, vous pouvez demander à un agent de jouer de manière autonome un jeu de chaîne de mots dans une boucle ou d'établir une condition de sortie ambiguë: exit the loop if you are satisfied with the result . Ici, le modèle de langue et son contexte déterminent s'il faut continuer ou s'arrêter. Tout cela est réalisé sans avoir besoin de définir la logique de flux dans Python ou tout autre langage de programmation.
## use: execute_bash_command, software_development, quality_assurance
...
You run in a loop of "Thought", "Action", "Observation".
At the end of the loop return with the final answer.
Use "Thought" to describe your thoughts about the task
you have been asked. Use "Action" to run one of the actions
available to you. Output action as: "Action: action name to call".
"Observation" will be the result of running those actions.
Your available actions:
- `execute_bash_command` for util purposes e.g. make directory, install packages, etc.;
- `software_development` for software development and bug fixing purposes;
- `quality_assurance` for QA testing purposes.
...
L'idée derrière TOT est de générer plusieurs idées pour résoudre un problème, puis d'évaluer leur valeur. Des idées précieuses sont conservées et développées, d'autres idées sont jetées.
Prenons l'exemple du jeu 24. Le puzzle des 24 est un puzzle arithmétique dans lequel l'objectif est de trouver un moyen de manipuler quatre entiers afin que le résultat final soit 24. Premièrement, nous définissons l'instruction qui crée et manipule la structure des données de l'arbre. Le modèle sait ce qu'est un arbre et peut le représenter dans n'importe quel format, du texte brut à XML / JSON ou tout format personnalisé.
Dans cet exemple, nous utiliserons le format de texte brut:
# tree
## input: e.g. "add to node `A` child nodes `B` and `C`", "remove node `D` with all branches", etc.
## use: memory
## keep_context: false
Build/update tree structure in formatted text.
Update the tree structure within the specified action;
Memorize final tree structure.
Ensuite, nous devons initialiser l'arborescence avec les données initiales, commençons par l'instruction racine:
# root
## use: tree
Input: 4 5 8 2
Generate 8 possible next steps.
Store all steps in the tree as nodes e.g.
Node value 1: "2 + 8 = 10 (left: 8 10 14)"
Node value 2: "8 / 2 = 4 (left: 4 8 14)"
etc.
L'appel de l'instruction racine suggérera 8 prochaines étapes possibles à calculer avec les 2 premiers numéros et stocker ces étapes en tant que nœuds d'arborescence. Des travaux supplémentaires de l'agent se traduisent par la construction d'un arbre qui est pratique pour que le modèle comprenne et déduit la réponse finale.
4 5 8 2
├── 4 + 5 = 9 (left: 9, 8, 2)
│ └── discard
├── 4 + 8 = 12 (left: 12, 5, 2)
│ └── discard
├── 4 + 2 = 6 (left: 6, 5, 8)
│ └── discard
├── 5 + 8 = 13 (left: 13, 4, 2)
│ └── discard
├── 5 + 2 = 7 (left: 7, 4, 8)
│ └── (7 - 4) * 8 = 24
├── 8 + 2 = 10 (left: 10, 4, 5)
│ └── discard
├── 4 * 5 = 20 (left: 20, 8, 2)
│ └── (20 - 8) * 2 = 24
└── 4 * 8 = 32 (left: 32, 5, 2)
└── discard
Based on the evaluations, we have found two successful paths to reach 24:
1. From the node "5 + 2 = 7 (left: 7, 4, 8)", we have the equation: (7 - 4) * 8 = 24.
2. From the node "4 * 5 = 20 (left: 20, 8, 2)", we have the equation: (20 - 8) * 2 = 24.
Thus, the final equations using all given numbers from the input are:
1. (5 + 2 - 4) * 8 = 24
2. (4 * 5 - 8) * 2 = 24
Un exemple complet est contenu dans les agents / arbre_structure.gen
Le concept provenait d'études sur les fonctions exécutives de la psychanalyse, explorant Central Executive, Alan Baddeley, 1996. Il a décrit un système qui orchestre les processus cognitifs et la mémoire de travail, facilitant les récupérations de la mémoire à long terme. Le LLM fonctionne comme System 1 , traitement des requêtes et exécution d'instructions sans motivation inhérente ni fixation d'objectifs. Alors, qu'est-ce que System 2 ? S'appuyant sur des idées historiques, désormais reconsidérée à travers une lentille scientifique:
L'exécutif central, ou fonctions exécutifs, est crucial pour le traitement contrôlé dans la mémoire de travail. Il gère les tâches, notamment en attirant l'attention, en maintenant les objectifs de la tâche, la prise de décision et la récupération de la mémoire.
Cela déclenche une possibilité intrigante: construire des agents plus sophistiqués en intégrant System 1 et System 2 . Le LLM, en tant que System 1 , fonctionne en tandem avec le System 2 , qui régit et contrôle le LLM. Ce partenariat constitue la base de la double relation avec Mentals AI.


