mentals ai
1.0.0
Mentals AI ist ein Tool, das zum Erstellen und Betriebsagenten mit loops , memory und verschiedenen tools erstellt und durch eine unkomplizierte markdown -Datei mit einer Gen -Erweiterung verfügt. Stellen Sie sich eine Agentendatei als ausführbare Datei vor. Sie konzentrieren sich vollständig auf die Logik des Agenten und beseitigen die Notwendigkeit, Gerüstcode in Python oder einer anderen Sprache zu schreiben. Im Wesentlichen definiert es die grundlegenden Frameworks für zukünftige AI -Anwendungen neu?
Notiz
Wortkettenspiel in einer von LLM kontrollierten Selbstschleife: 
NLOP - Operation natürlicher Sprache
Oder komplexere Anwendungsfälle:
| Alle Multi-Agent-Interaktionen | ? Space Invaders Generator Agent | ? 2D Platformer Generator Agent |
|---|---|---|
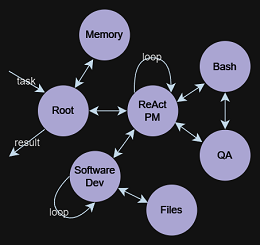 |  |  |
Oder helfen Sie mit dem Inhalt:
Alle oben genannten Beispiele befinden sich im Agentenordner.
Notiz
LLAMA3 -Unterstützung ist für Anbieter mit einer kompatiblen OpenAI -API verfügbar.
Beginnen Sie mit der Sicherung eines OpenAI -API -Schlüssels durch die Erstellung eines OpenAI -Kontos. Wenn Sie bereits einen API -Schlüssel haben, überspringen Sie diesen Schritt.
Voraussetzungen
Stellen Sie vor dem Erstellen des Projekts sicher, dass die folgenden Abhängigkeiten installiert sind:
Abhängig von Ihrem Betriebssystem können Sie diese mit den folgenden Befehlen installieren:
Linux
sudo apt-get update
sudo apt-get install libcurl4-openssl-dev libfmt-dev libpoppler-devmacos
brew update
brew install curl fmt popplerFenster
Für Windows wird empfohlen, VCPKG oder einen ähnlichen Paketmanager zu verwenden:
vcpkg install curl fmt popplerPGVector -Installation
Notiz
Im main können Sie diesen Schritt überspringen
Klonen Sie das Repository
git clone https://github.com/turing-machines/mentals-ai
cd mentals-aiKonfiguration
Platzieren Sie Ihren API -Schlüssel in der Datei config.toml :
[llm]
# OpenAI
api_key = " "
endpoint = " https://api.openai.com/v1 "
model = " gpt-4o "Bauen Sie das Projekt auf
makeLaufen
./build/mentals agents/loop.gen -dMentals AI unterscheidet sich auf drei bedeutende Weise von anderen Frameworks:
Agent Executor ? arbeitet durch eine rekursive Schleife. Das LLM bestimmt die nächsten Schritte: Auswählen von Anweisungen (Eingabeaufforderungen) und Verwalten von Daten basierend auf früheren Schleifen. Dieser rekursive Entscheidungsprozess ist ein wesentlicher Bestandteil unseres Systems, das in Mentals_System.prompt beschrieben wirdMarkdown erstellt werden, wodurch die Notwendigkeit herkömmlicher Programmiersprachen beseitigt wird. Python kann jedoch bei Bedarf direkt in das Markdown -Skript des Agenten integriert werden.Tree of Thoughts , ReAct , Self-Discovery , Auto-CoT und andere. Man kann diese Frameworks auch mit komplexeren Sequenzen verknüpfen und sogar ein Netzwerk verschiedener Argumentations -Frameworks erstellen. Die Agentendatei ist eine Textbeschreibung der Agentenanweisungen mit einer .gen .
Der Anweisungen ist die Grundkomponente eines Agenten in Mentals. Ein Agent kann aus einer oder mehreren Anweisungen bestehen, die sich aufeinander beziehen können.
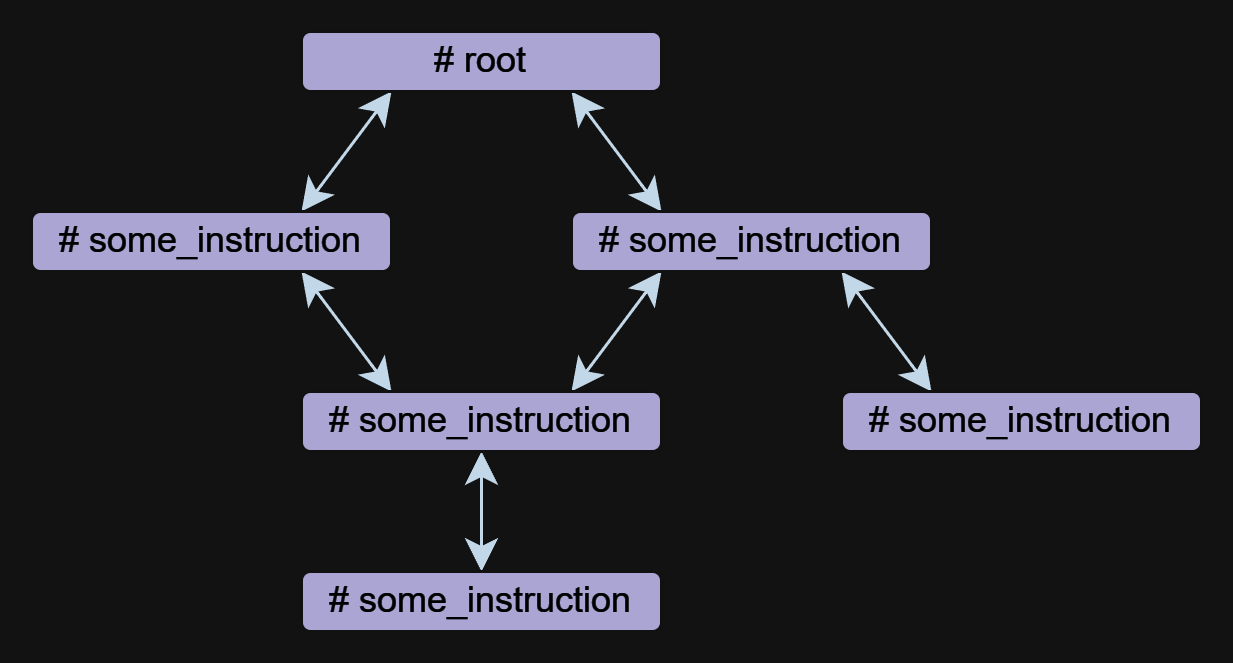
Anweisungen können in freier Form geschrieben werden, aber sie haben immer einen Namen, der mit dem # Symbol beginnt. Die ## use: Die Anweisung wird verwendet, um einen Verweis auf andere Anweisungen anzugeben. Mehrere Referenzen werden durch Kommas getrennt aufgeführt.
Unten finden Sie ein Beispiel mit zwei Anweisungen root und meme_explain mit einer Referenz:
# root
## use: meme_explain
1. Create 3 memes about AGI;
2. Then do meme explain with meme per call;
3. Output memes and their explanations in a list.
# meme_explain
Explain the gist of the meme in 20 words in medieval style.
Return explanation.
In diesem Beispiel ruft der root -Befehl die Anweisung meme_explain auf. Die Antwort von meme_explain wird dann an den Anweisungen zurückgegeben, von dem sie genannt wurde, nämlich die Wurzel.
Eine Anweisung kann einen input erfolgen, der automatisch auf dem Kontext generiert wird, wenn der Anweisungen aufgerufen wird. Um die Eingabedaten genauer anzugeben, können Sie in der ## input: Richtlinie wie ein JSON-Objekt oder null eine Freiform-Eingabeaufforderung verwenden.
Verwenden eines Dokuments zur Eingabe:
# some_instruction
## input: design document only
Verwenden eines JSON -Objekts als Eingabe:
# duckduckgo
## input: { search_query: search query, search_limit: search limit }
Write a Python script to search in DuckDuckGo.
Simulate request headers correctly e.g. user-agent as Mozilla and Linux.
Notiz
Anweisungsanrufe werden unabhängig von Funktions- oder Toolsanrufen bei OpenAI implementiert, sodass Agenten mit Modellen wie LLAMA3 3. Die Implementierung von Anweisungsanrufen ist transparent und in der Datei mentals_system.prompt aufgenommen.
Tool ist eine Art Anweisung. Mentals verfügt über eine Reihe von nativen Tools, um die Nachrichtenausgabe, die Benutzereingabe, die Dateihandhabung, den Python-Interpreter, die Bash-Befehle und der Kurzzeitspeicher zu verarbeiten.
Fragen Sie das Benutzer Beispiel:
# root
## use: user_input
Ask user name.
Then output: `Welcome, user_name!`
Beispiel für Dateibehandlungen:
# root
## use: write_file, read_file
Write 'Hello world' to a file.
Then read and output file content.
Die vollständige Liste der nativen Tools ist in der Datei native_tools.toml aufgeführt.
Jede Anweisung hat einen eigenen Arbeitsgedächtnis - Kontext. Beim Verlassen einer Anweisung und beim erneuten Eintritt wird der Kontext standardmäßig gehalten. Um den Kontext zu löschen, wenn Sie einen Anweisungen beenden, können Sie die ## keep_context: false -Anweisung verwenden:
# meme_explain
## keep_context: false
Explain the gist of the meme in 20 words in medieval style.
Return explanation.
Standardmäßig ist die Größe des Anweisungskontexts nicht begrenzt. Um den Kontext zu begrenzen, gibt es eine Anweisung ## max_context: number , die angibt, dass nur die number der neuesten Nachrichten gespeichert werden sollte. Ältere Nachrichten werden aus dem Kontext herausgedrückt. Diese Funktion ist nützlich, wenn Sie die neuesten Daten im Kontext aufbewahren möchten, damit ältere Daten die Argumentationskette nicht beeinflussen.
# python_code_generation
## input: development tasks in a list
## use: write_file
## max_context: 5
Do all development tasks in a loop: task by task.
Save the Python code you implement in the main.py file.
Der Kurzzeitgedächtnis ermöglicht die Speicherung von Zwischenergebnissen aus den Aktivitäten eines Agenten, die dann zur weiteren Argumentation verwendet werden können. Der Inhalt dieses Speichers ist über alle Anweisungskontexte zugänglich.
Das memory wird zum Speichern von Daten verwendet. Wenn Daten gespeichert werden, werden ein Schlüsselwort und eine Beschreibung des Inhalts generiert. Im folgenden Beispiel ist der meme_recall -Befehl des Meme bekannt, da sie zuvor im Speicher gespeichert wurde.
# root
## use: memory, meme_recall
Come up with and memorize a meme.
Call meme recall.
# meme_recall
## input: nothing
What the meme was about?
Der Kontrollfluss, der Bedingungen, Anweisungsaufrufe und Schleifen (z. B. ReAct , Auto-CoT usw.) umfasst, wird in der natürlichen Sprache vollständig ausgedrückt. Diese Methode ermöglicht die Erstellung semantic conditions , die die Verzweigung von Datenströmen leiten. Beispielsweise können Sie einen Agenten auffordern, in einer Schleife autonom ein Wortkettenspiel zu spielen oder eine mehrdeutige Ausstiegsbedingung zu erstellen: exit the loop if you are satisfied with the result . Hier bestimmen das Sprachmodell und sein Kontext, ob sie fortgesetzt oder anhalten sollen. All dies wird erreicht, ohne die Flusslogik in Python oder anderen Programmiersprachen zu definieren.
## use: execute_bash_command, software_development, quality_assurance
...
You run in a loop of "Thought", "Action", "Observation".
At the end of the loop return with the final answer.
Use "Thought" to describe your thoughts about the task
you have been asked. Use "Action" to run one of the actions
available to you. Output action as: "Action: action name to call".
"Observation" will be the result of running those actions.
Your available actions:
- `execute_bash_command` for util purposes e.g. make directory, install packages, etc.;
- `software_development` for software development and bug fixing purposes;
- `quality_assurance` for QA testing purposes.
...
Die Idee hinter TOT ist es, mehrere Ideen zu generieren, um ein Problem zu lösen und dann ihren Wert zu bewerten. Wertvolle Ideen werden aufbewahrt und entwickelt, andere Ideen werden verworfen.
Nehmen wir das Beispiel des 24 -Spiels. Das 24 -Puzzle ist ein arithmetisches Puzzle, in dem das Ziel darin besteht, einen Weg zu finden, vier Ganzzahlen zu manipulieren, damit das Endergebnis 24 ist. Erstens definieren wir die Anweisung, die die Baumdatenstruktur erzeugt und manipuliert. Das Modell weiß, was ein Baum ist und kann es in jedem Format darstellen, vom einfachen Text bis zu XML/JSON oder einem beliebigen benutzerdefinierten Format.
In diesem Beispiel werden wir das einfache Textformat verwenden:
# tree
## input: e.g. "add to node `A` child nodes `B` and `C`", "remove node `D` with all branches", etc.
## use: memory
## keep_context: false
Build/update tree structure in formatted text.
Update the tree structure within the specified action;
Memorize final tree structure.
Als nächstes müssen wir den Baum mit anfänglichen Daten initialisieren. Beginnen wir mit der Wurzelanweisung:
# root
## use: tree
Input: 4 5 8 2
Generate 8 possible next steps.
Store all steps in the tree as nodes e.g.
Node value 1: "2 + 8 = 10 (left: 8 10 14)"
Node value 2: "8 / 2 = 4 (left: 4 8 14)"
etc.
Das Aufrufen der Wurzelanweisung schlägt 8 mögliche nächste Schritte vor, um mit den ersten 2 Zahlen zu berechnen und diese Schritte als Baumknoten zu speichern. Weitere Arbeiten des Agenten führt zur Konstruktion eines Baumes, der für das Modell zweckmäßig ist, um die endgültige Antwort zu verstehen und zu schließen.
4 5 8 2
├── 4 + 5 = 9 (left: 9, 8, 2)
│ └── discard
├── 4 + 8 = 12 (left: 12, 5, 2)
│ └── discard
├── 4 + 2 = 6 (left: 6, 5, 8)
│ └── discard
├── 5 + 8 = 13 (left: 13, 4, 2)
│ └── discard
├── 5 + 2 = 7 (left: 7, 4, 8)
│ └── (7 - 4) * 8 = 24
├── 8 + 2 = 10 (left: 10, 4, 5)
│ └── discard
├── 4 * 5 = 20 (left: 20, 8, 2)
│ └── (20 - 8) * 2 = 24
└── 4 * 8 = 32 (left: 32, 5, 2)
└── discard
Based on the evaluations, we have found two successful paths to reach 24:
1. From the node "5 + 2 = 7 (left: 7, 4, 8)", we have the equation: (7 - 4) * 8 = 24.
2. From the node "4 * 5 = 20 (left: 20, 8, 2)", we have the equation: (20 - 8) * 2 = 24.
Thus, the final equations using all given numbers from the input are:
1. (5 + 2 - 4) * 8 = 24
2. (4 * 5 - 8) * 2 = 24
Ein vollständiges Beispiel ist in den Agenten/Tree_structure.gen enthalten
Das Konzept stammte aus Studien zu Psychoanalyse-Exekutivfunktionen, die zentrale Exekutive Alan Baddeley, 1996 untersuchten. Er beschrieb ein System, das kognitive Prozesse und Arbeitsgedächtnisse orchestriert und das Abruf aus dem Langzeitgedächtnis erleichtert. Die LLM fungiert als System 1 , Verarbeitung von Abfragen und Ausführungsanweisungen ohne inhärente Motivation oder Zielsetzung. Also, was ist dann System 2 ? Ausgehend von historischen Erkenntnissen, jetzt durch eine wissenschaftliche Linse überprüft:
Die zentrale Exekutiv- oder Exekutivfunktionen sind für die kontrollierte Verarbeitung im Arbeitsspeicher von entscheidender Bedeutung. Es verwaltet Aufgaben, einschließlich Aufmerksamkeit, Aufrechterhaltung von Aufgabenzielen, Entscheidungsfindung und Speicherabruf.
Dies löst eine faszinierende Möglichkeit aus: Konstruktion entwickelterer Wirkstoffe durch Integration von System 1 und System 2 . Das LLM als kognitives Executor System 1 arbeitet zusammen mit dem zentralen System 2 zusammen, das die LLM regelt und kontrolliert. Diese Partnerschaft bildet die doppelte Beziehung grundlegend für Mentals AI.


