surpriver
1.0.0

異常検出と機械学習を使用して移動する前に、高い移動在庫を見つけます。 Sustriverは機械学習を使用してボリューム +価格アクションを調べ、在庫の大きな動きをもたらす可能性のある異常なパターンを推測します。
| パス | 説明 |
|---|---|
| 驚き | メインフォルダー。 |
| └辞書 | 後で使用するためにデータ辞書を保存するフォルダー。 |
| └図 | このgithubリポジトリの数字。 |
| stocks株 | 分析したいすべての株式のリスト。 |
| data_loader.py | Yahoo Financeのデータを読み込むためのモジュール。 |
| Detection_Engine.py | データで異常検出を実行し、最も異常な価格とボリュームパターンの在庫を見つけるためのメインモジュール。 |
| feature_generator.py | 価格とボリュームのリターン機能、および多くの技術的指標を生成します。 |
モデルをトレーニングおよびテストするには、次のパッケージをインストールする必要があります。
次のコマンドを使用してすべてのパッケージをインストールできます。スクリプトはPython3を使用して記述されたことに注意してください。
pip install -r requirements.txt
また、Dockerが何であるかを知っている場合は、使用方法について知識を持つこともできます。 Dockerを使用してツールを実行する手順は次のとおりです。
docker build . -t surpriver<C:\path\to\this\dir>に置き換えます。docker-compose up -dを実行してコンテナを実行しますdocker exec -it surpriver Your Command Lineを準備して、以下のコマンドのいずれかを実行します。先に進み、今日の最も異常な在庫を直接取得したい場合は、次のコマンドを簡単に実行して、最も珍しいパターンで在庫を取得できます。次のセクションでは、コマンドをさらに深く掘り下げます。
python detection_engine.py --top_n 25 --min_volume 5000 --data_granularity_minutes 60 --history_to_use 14 --is_load_from_dictionary 0 --data_dictionary_path 'dictionaries/data_dict.npy' --is_save_dictionary 1 --is_test 0 --future_bars 0
このコマンドは、60分のろうそくの最後の14バーで最も高い異常スコアを持っていた上位25の株を提供します。また、辞書/data_dict.npyフォルダーで予測を作成するために使用したすべてのデータを保存します。以下は、各パラメーターのより詳細な説明です。
python detection_engine.py --top_n 25 --min_volume 5000 --data_granularity_minutes 60 --history_to_use 14 --is_load_from_dictionary 1 --data_dictionary_path 'dictionaries/data_dict.npy' --is_save_dictionary 0 --is_test 0 --future_bars 0 --output_format 'CLI'
is_save_dictionaryとis_load_from_dictionaryの変更に注意してください。
ここに、単一の予測がどのように見えるかの出力があります。負のスコアは、より高い異常で異常なパターンを示し、正のスコアは正常なパターンを示します。低いほど良い。
Last Bar Time: 2020-08-25 11:30:00-04:00
Symbol: SPI
Anomaly Score: -0.029
Today Volume (Today = Date Above): 313.94K
Average Volume 5d: 206.53K
Average Volume 20d: 334.14K
Volatility 5bars: 0.013
Volatility 20bars: 0.038
Future Absolute Sum Price Changes: 72.87
取引における機械学習と人工知能の使用を疑っている場合は、このツールからの予測を履歴データで実際にテストできます。テストの2つの最も重要なコマンドライン引数は、 is_testとfuture_barsです。前者が1に設定され、後者が5を超えるものに設定されている場合、ツールは実際に分析のためにその量のデータを残し、それ以前に異常な予測にデータを使用します。次に、残りのデータを見て、予測がどれだけうまく機能したかを確認します。以下は、次のコマンドからの散布図の例です。
python detection_engine.py --top_n 25 --min_volume 5000 --data_granularity_minutes 60 --history_to_use 14 --is_load_from_dictionary 0 --data_dictionary_path 'dictionaries/data_dict.npy' --is_save_dictionary 1 --is_test 1 --future_bars 25
既にデータ辞書を生成している場合は、次のコマンドを使用して、 is_load_from_dictionaryを1に設定し、 is_save_dictionaryを0に設定できます。
python detection_engine.py --top_n 25 --min_volume 5000 --data_granularity_minutes 60 --history_to_use 14 --is_load_from_dictionary 1 --data_dictionary_path 'dictionaries/data_dict.npy' --is_save_dictionary 0 --is_test 1 --future_bars 25
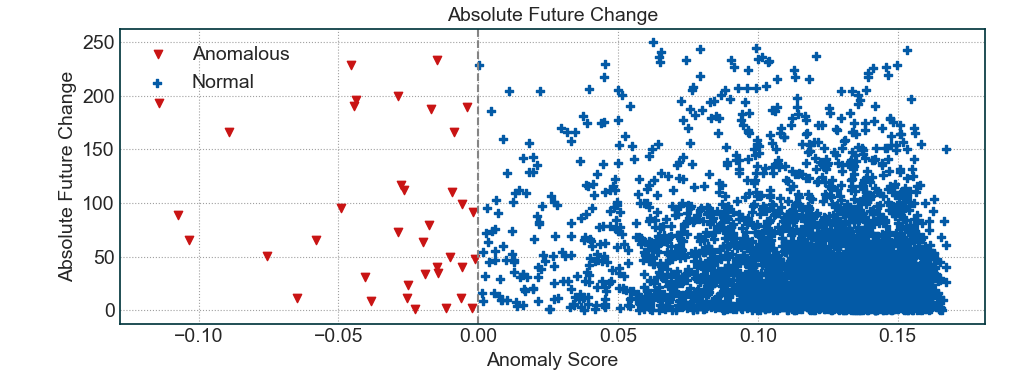
上の画像でわかるように、異常な在庫(スコア<0)は通常、平均して将来の絶対的な変化が高くなります。これは、予測が実際には、今後数時間/日で平均以上移動した株式に対するものであることを証明しています。ここでは、ツールが最高のボラティリティ在庫を選択しているだけで、将来の絶対変化が高いために1つの疑問が生じます。そうではないことを証明するために、上記のコマンドから得た統計のより詳細な説明を以下に示します。
--> Future Performance
Correlation between future absolute change vs anomalous score (lower is better, range = (-1, 1)): **-0.23**
Total absolute change in future for Anomalous Stocks: **89.660**
Total absolute change in future for Normal Stocks: **43.000**
Average future volatility of Anomalous Stocks: **0.332**
Average future volatility of Normal Stocks: **0.585**
Historical volatility for Anomalous Stocks: **2.528**
Historical volatility for Normal Stocks: **2.076**
通常の在庫と異常な在庫の歴史的なボラティリティはそれほど違いはないことがわかります。ただし、絶対的な将来の総変化の違いは、通常の株と比較して、異常な株の2倍です。
これで、使用する株式リストとともに使用するデータソースを指定できるようになりました。
python detection_engine.py --top_n 25 --min_volume 500 --data_granularity_minutes 60 --history_to_use 14 --is_load_from_dictionary 0 --data_dictionary_path 'dictionaries/feature_dict.npy' --is_save_dictionary 1 --is_test 0 --future_bars 0 --data_source binance --stock_list cryptos.txt
毎週、単一のパラメーターセットの上位25の結果を掲載しようとします。
このツールは、価格とボリュームアクションを組み合わせて異常な動作を持つ株のみを見つけます。在庫がどの方向に移動するかを予測しません。それは私が将来実装する機能かもしれませんが、今のところ、チャートを見て、それを理解するためにDDを実行する必要があります。
Tradyticsによる製品
Copyright(c)2020-Present、tradytics.com


