VectorDB Plugin for LM Studio
v6.11.0 - bug fixes
Persyaratan • Instalasi • Menggunakan Program • Meminta fitur atau melaporkan bug • Kontak
Repositori ini memungkinkan Anda untuk membuat dan mencari database vektor untuk konteks yang relevan di berbagai dokumen dan kemudian mendapatkan respons dari model bahasa besar yang lebih akurat. Ini umumnya disebut sebagai "pengambilan generasi augmented" (RAG) dan secara drastis mengurangi halusinasi dari LLM! Anda dapat menonton video pengantar atau membaca artikel menengah tentang program ini.
| Fitur | Detail |
|---|---|
| Ekstraksi Teks Umum | .pdf .docx .epub .txt .html .enex .eml .msg .csv .xls .xlsx .rtf .odt |
| Model "visi" untuk membuat ringkasan gambar | .png .jpg .jpeg .bmp .gif .tif .tiff |
| Transkripsi file audio ke teks | .mp3 .wav .m4a .ogg .wma .flac dan banyak lagi ... |
| Ketik atau ucapkan pertanyaan Anda | Menggunakan perekam suara WhisperS2T yang kuat |
| Dapatkan tanggapan dari LLM | LM Studio Local Models Chat GPT (segera hadir) |
| Teks untuk pemutaran ucapan dari respons LLM | Bark WhisperSpeech ChatTTS Google TTS |
Dukungan GPU CPU dan Nvidia | Mencari penguji atau kontributor untuk AMD dan Intel GPU serta Metal/MPS/MLX |
| ? Python 3.11 •? Git •? GIT LFS • Pandoc • Kompiler |
|---|
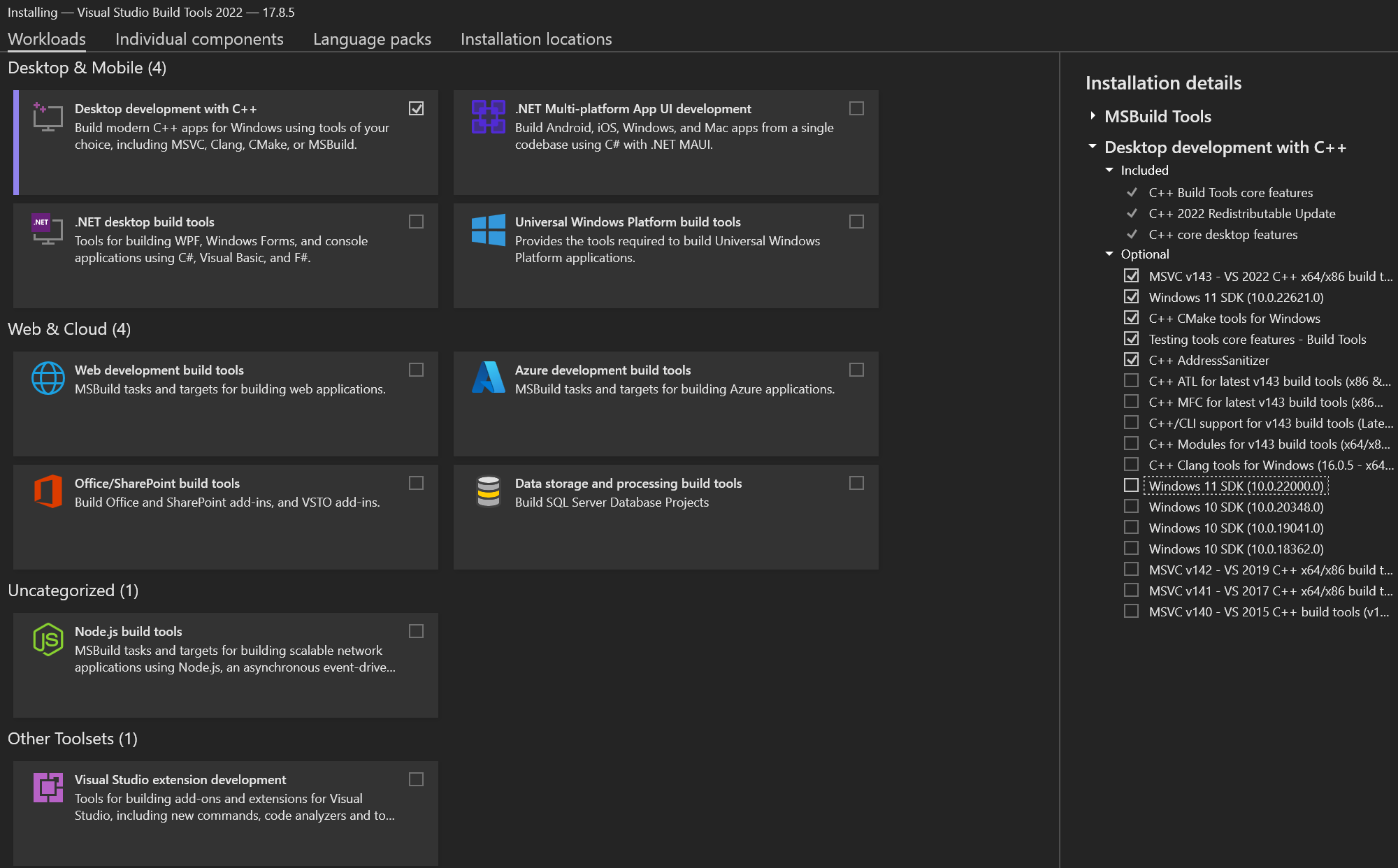
Tautan di atas mengunduh Visual Studio sebagai contoh. Pastikan untuk menginstal SDK yang diperlukan.
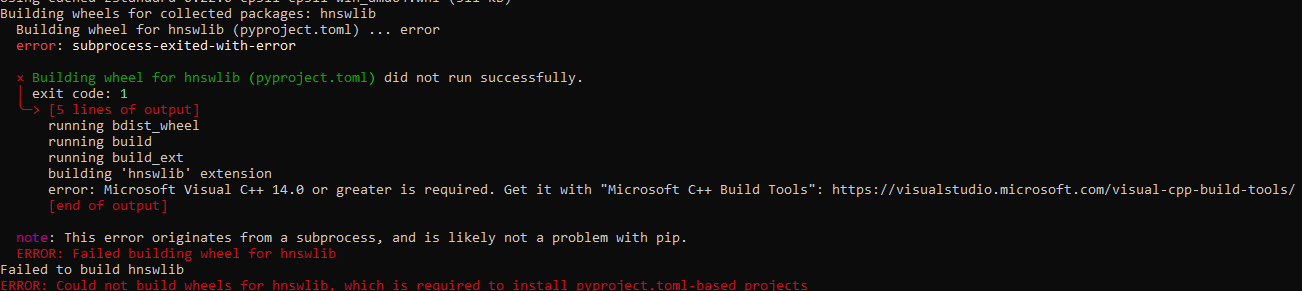
Contoh kesalahan saat tidak ada kompiler yang diinstal:
Contoh menginstal SDK yang benar:
Kembali ke atas
Unduh "rilis" terbaru, ekstrak isinya, dan buka folder "SRC":
Upaya terakhir untuk mendukung? Linux dan? MacOS adalah rilis v3.5.2. Pastikan dan ikuti instruksi
readme.mddi sana.
Di dalam folder src , buat lingkungan virtual:
python -m venv .
Aktifkan lingkungan virtual:
.Scriptsactivate
Jalankan skrip pengaturan:
Hanya untuk
Windowsuntuk saat ini.
python setup_windows.py
Untuk menggunakan fungsionalitas Ask Jeeves Anda harus:
Assets ;koboldcpp_nocuda.exe ;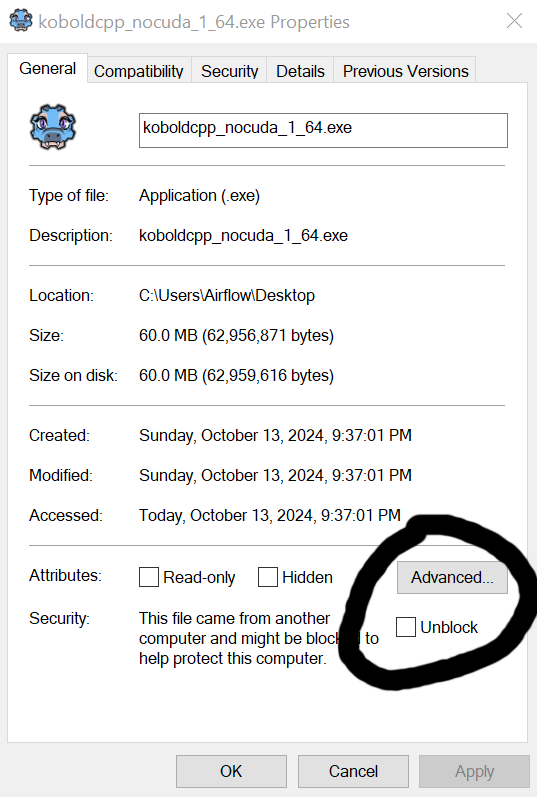
Jika kotak centang "unblock" tidak terlihat karena alasan apa pun, opsi lain adalah untuk doubleclick koboldcpp_nocuda.exe , pilih file .gguf dalam direktori Assets , dan mulai program. Ini harus (setidaknya pada Windows) berusaha untuk memulai program Kobold, yang akan memicu opsi untuk "mengizinkan" dan/atau membuat pengecualian untuk "Windows Defender" di komputer Anda. Pilih "Izinkan" atau pesan apa pun yang Anda terima, yang akan memungkinkannya untuk semua interaksi di masa depan. Harap dicatat bahwa Anda harus melakukan ini sebelum mencoba menjalankan fungsionalitas Ask Jeeves dalam program ini; Kalau tidak, itu mungkin tidak berhasil.
Kirimkan
IssueGitHub jika Anda mengalami masalah karenaAsk Jeevesadalah fitur yang relatif baru.
Kembali ke atas
Penting untuk instruksi yang lebih rinci, tanyakan saja pada Jeeves!
Setiap kali Anda ingin menggunakan program, Anda harus mengaktifkan lingkungan virtual:
.Scriptsactivate
python gui.py
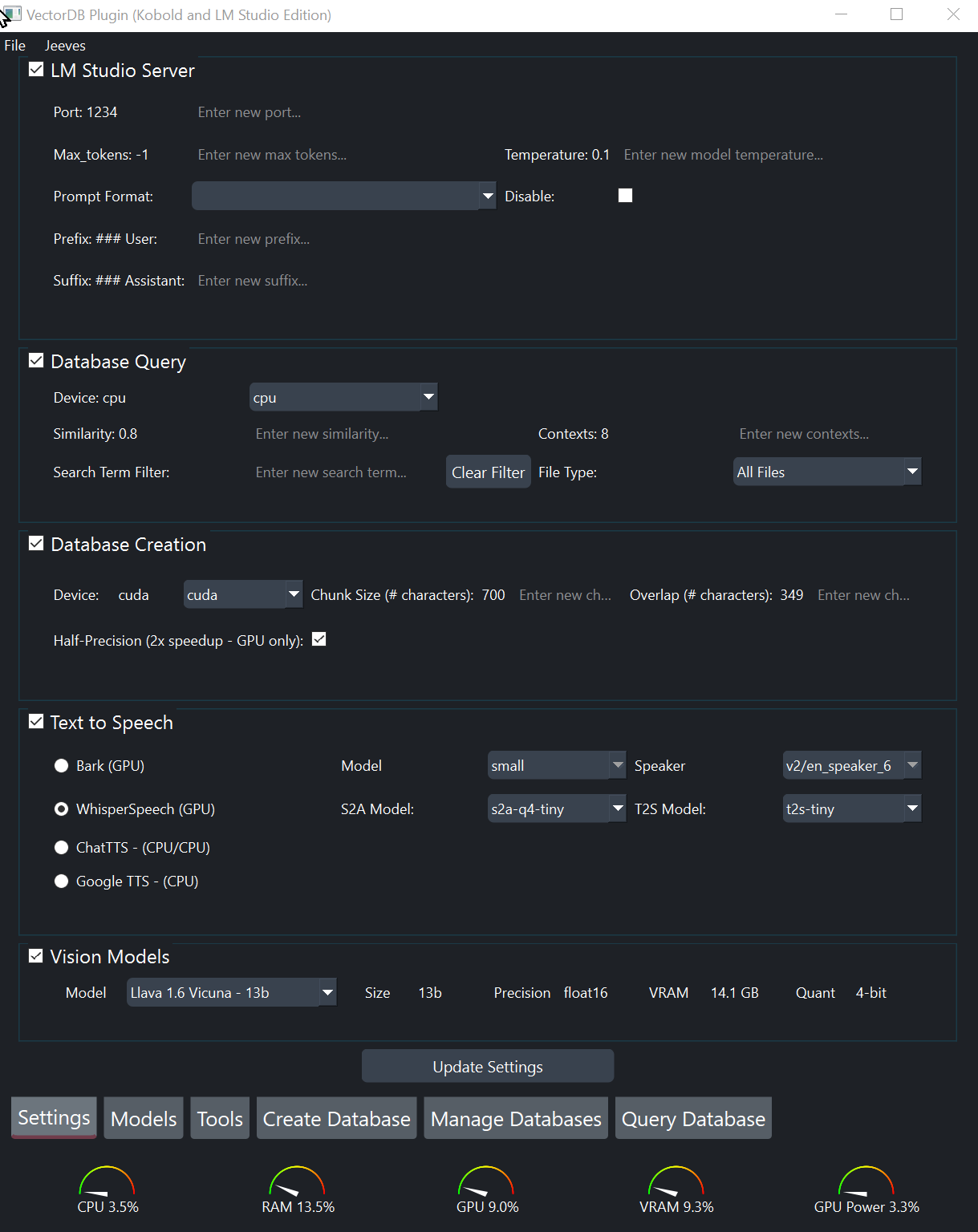
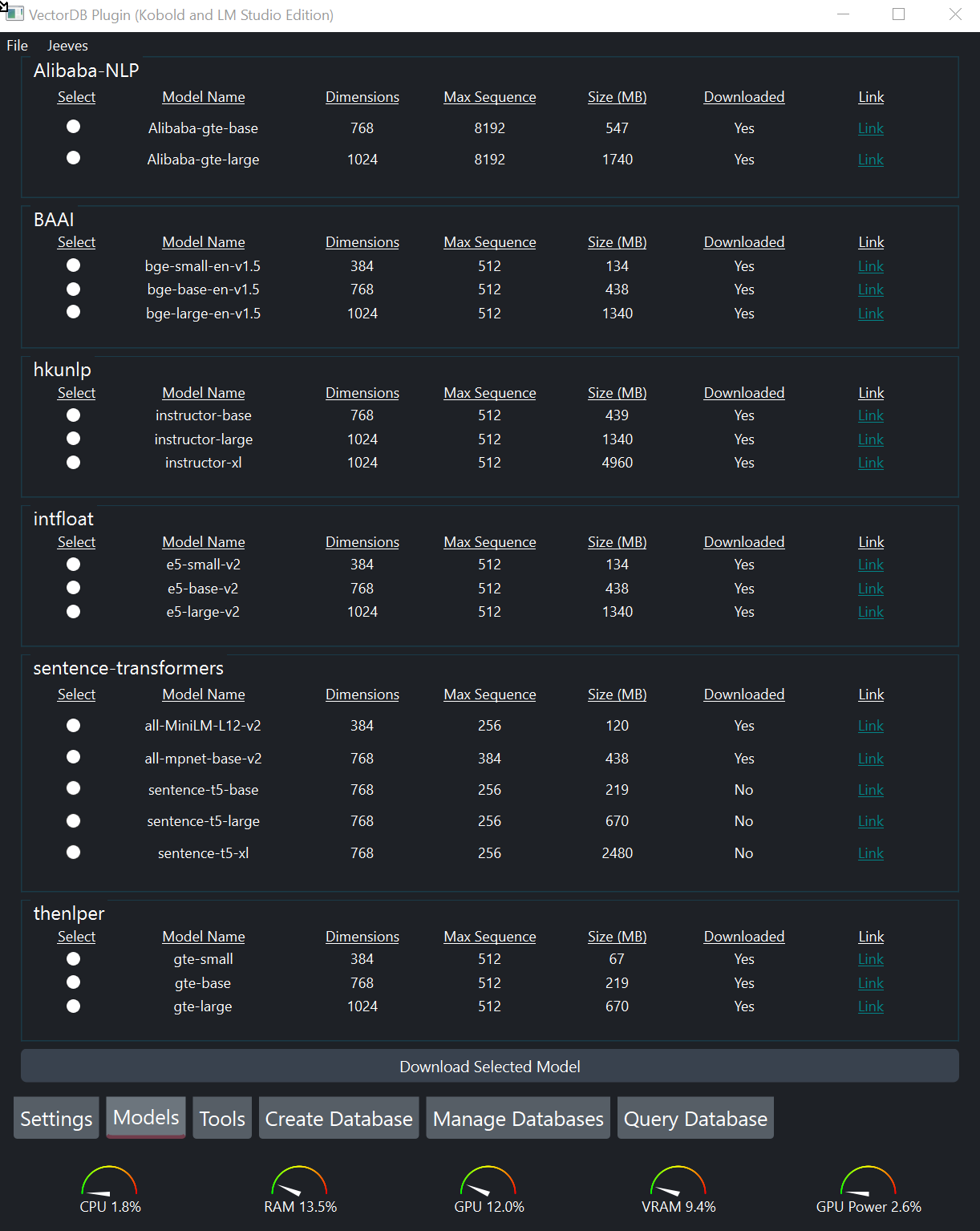
Models Tab .Program ini mengekstrak teks dari berbagai jenis file dan menempatkannya ke dalam database vektor. Ini juga memungkinkan Anda untuk membuat meringkas gambar dan transkripsi file audio untuk dimasukkan ke dalam database.
Di tab Create Database , pilih file yang ingin Anda tambahkan ke database. Anda dapat mengklik tombol Choose Files sebanyak yang Anda inginkan.
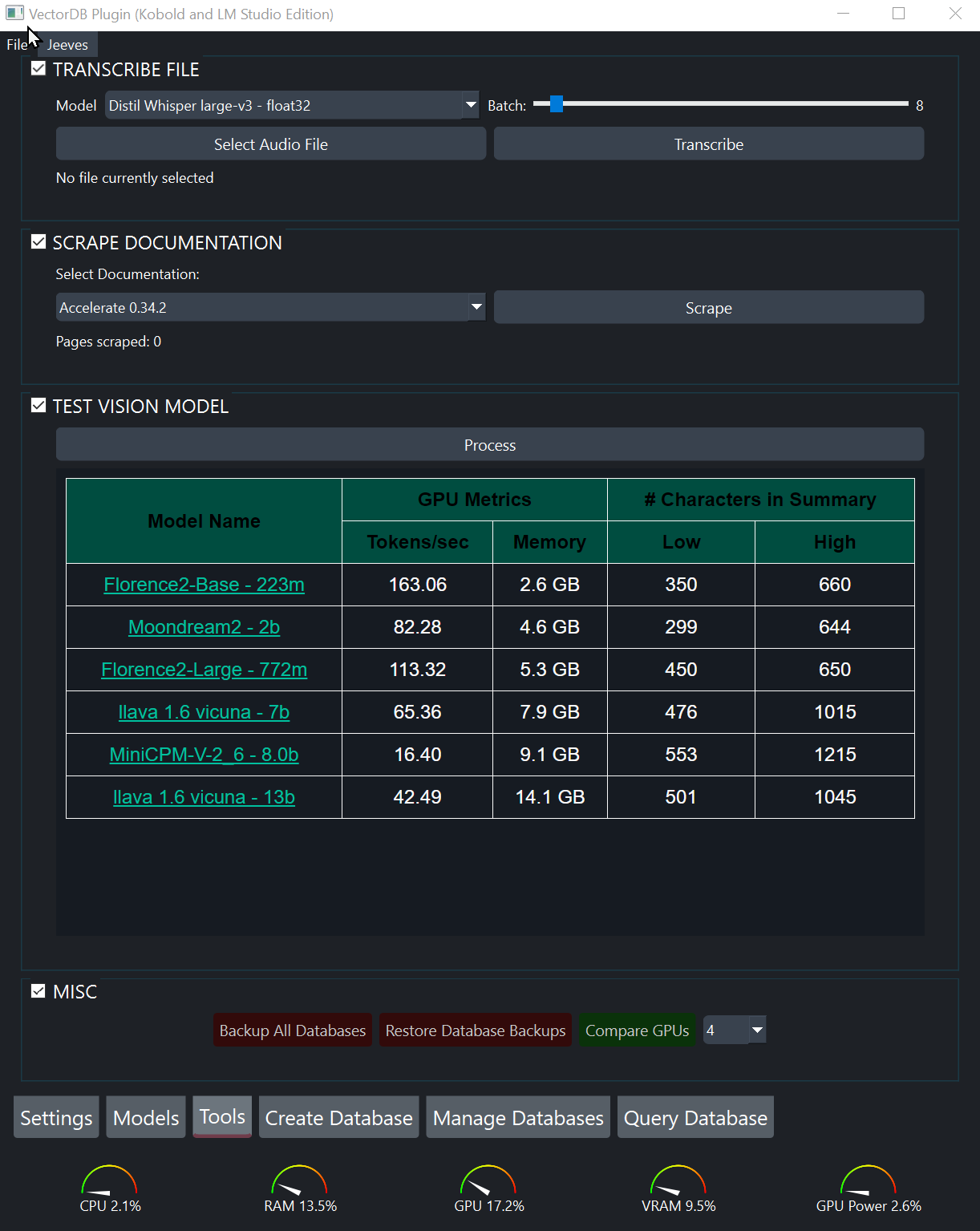
Program ini menggunakan model "visi" untuk membuat ringkasan gambar, yang kemudian dapat dimasukkan ke dalam database dan dicari. Sebelum memasukkan gambar, saya sangat menyarankan Anda menguji berbagai model visi untuk yang paling Anda sukai.
Untuk menguji model visi:
Create Database , pilih satu atau lebih gambar.Settings , pilih model visi yang ingin Anda uji.Tools , proses gambar. Setelah menentukan model visi mana yang Anda sukai, tambahkan gambar ke database dengan memilihnya dari tab Create Database seperti file lainnya. Ketika Anda akhirnya membuat database, mereka akan diproses secara otomatis.
File audio dapat ditranskripsi dan dimasukkan ke dalam database untuk dicari. Sebelum menyalin file audio yang panjang, saya sangat merekomendasikan menguji berbagai model Whisper pada file audio yang lebih pendek serta bereksperimen dengan pengaturan batch yang berbeda. Tujuan Anda adalah menggunakan model Whisper sebesar yang didukung GPU Anda dan kemudian menyesuaikan ukuran batch untuk menjaga penggunaan VRAM dalam VRAM yang tersedia.
Untuk menguji pengaturan optimal:
Tools , pilih file audio pendek.Whisper .Create Database , DoubleClick transkripsi yang baru saja dibuat.page content untuk memahami apakah transkripsi cukup akurat untuk kasus penggunaan Anda atau jika Anda perlu memilih model Whisper yang lebih akurat.Setelah Anda mendapatkan pengaturan optimal untuk sistem Anda, saatnya untuk menuliskan file audio ke dalam database:
Create Database , hapus transkripsi apa pun yang tidak ingin Anda masukkan ke dalam database.Pemrosesan batch belum tersedia.
Models .Create Database , buat database.Manage Database memungkinkan Anda untuk melihat konten semua database yang telah Anda buat dan hapus jika Anda mau. Query Database , pilih database yang ingin Anda gunakan dari menu pulldown.Record Question .chunks only untuk hanya menerima konteks yang relevan.Submit Question .Settings , Anda dapat mengubah beberapa pengaturan mengenai permintaan database. Informasi lebih lanjut dapat ditemukan di panduan pengguna. Program ini mendapatkan potongan yang relevan dari database vektor dan meneruskannya - bersama dengan pertanyaan Anda - ke LM Studio untuk jawaban!
Chunks Only tidak terkendali.Apply Prompt Formatting ke "off."Prompt Format , pastikan semua pengaturan berikut kosong:System Message PrefixSystem Message SuffixUser Message PrefixUser Message SuffixGPU Offload sesuai keinginan Anda.Settings , pilih format prompt yang sesuai untuk model yang dimuat di LM Studio, klik Update Settings .Start Server.Query Database , klik Submit Question .Kembali ke atas
Jangan ragu untuk melaporkan bug atau meminta peningkatan dengan membuat masalah di GitHub atau menghubungi saya di LM Studio Discord Server (lihat tautan di bawah)!
Semua saran (positif dan negatif) dipersilakan. "[email protected]" atau jangan ragu untuk mengirimi saya pesan di LM Studio Discord Server.