TuoTuo
Stable 0.2.7 release
Tuotuo une bibliothèque de modélisation de sujets écrite en python. Tuotuo est aussi un garçon mignon, mon fils, qui a maintenant 6 mois.
Utilisez le Package Manager PIP pour installer Tuotuo. Vous pouvez trouver la distribution PYPI ici.
pip install TuoTuo --upgradeActuellement, la bibliothèque ne prend en charge que la modélisation de sujets via l'allocation latente Dirichlet (LDA). Comme nous le savons, LDA peut être implémenté en utilisant l'échantillonnage de Gibbs et l'inférence variationnelle, nous choisissons ce dernier car c'est mathématiquement plus sophistiqué
import torch as tr
from tuotuo . generator import doc_generator
gen = doc_generator (
M = 100 ,
# we sample 100 documents
L = 20 ,
# each document would contain 20 pre-defined words
topic_prior = tr . tensor ([ 1 , 1 , 1 , 1 , 1 ], dtype = tr . double )
# we use a exchangable Dirichlet Distribution as our topic prior,
# that is a uniform distribution on 5 topics
)
train_docs = gen . generate_doc () from tuotuo . lda_model import LDASmoothed
import matplotlib . pyplot as plt
lda = LDASmoothed (
num_topics = 5 ,
)
perplexes = lda . fit (
train_docs ,
sampling = False ,
verbose = True ,
return_perplexities = True ,
)
plt . plot ( perplexes )
= >= >= >= >= >= >= >= >
Topic Dirichlet Prior , Alpha
1
Exchangeable Word Dirichlet Prior , Eta
1
Var Inf - Word Dirichlet prior , Lambda
( 5 , 40 )
Var Inf - Topic Dirichlet prior , Gamma
( 100 , 5 )
Init perplexity = 84.99592157507153
End perplexity = 45.96696541539976 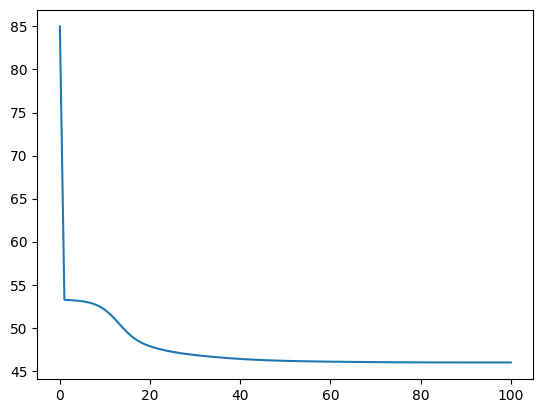
for topic_index in range ( lda . _lambda_ . shape [ 0 ]):
top5 = np . argsort ( lda . _lambda_ [ topic_index ,:],)[ - 5 :]
print ( f"Topic { topic_index } " )
for i , idx in enumerate ( top5 ):
print ( f"Top { i + 1 } -> { lda . train_doc . idx_to_vocab [ idx ] } " )
print ()
= >= >= >= >= >= >= >= >
Topic 0
Top 1 -> physical
Top 2 -> quantum
Top 3 -> research
Top 4 -> scientst
Top 5 -> astrophysics
Topic 1
Top 1 -> divorce
Top 2 -> attorney
Top 3 -> court
Top 4 -> bankrupt
Top 5 -> contract
Topic 2
Top 1 -> content
Top 2 -> Craftsmanship
Top 3 -> concert
Top 4 -> asymmetrical
Top 5 -> Symmetrical
Topic 3
Top 1 -> recreation
Top 2 -> FIFA
Top 3 -> football
Top 4 -> Olympic
Top 5 -> athletics
Topic 4
Top 1 -> fever
Top 2 -> appetite
Top 3 -> contagious
Top 4 -> decongestant
Top 5 -> injectionComme nous pouvons le voir dans les 5 premiers mots, nous pouvons facilement réaliser la cartographie suivante:
Sujet 0 -> Science Sujet 1 -> LOI SUJET 2 -> ART SUJET 3 -> Sport Sujet 4 -> Santé
Les demandes de traction sont les bienvenues. Pour les changements majeurs, veuillez d'abord ouvrir un problème pour discuter de ce que vous souhaitez changer.
Comme il n'y a pas de bibliothèque de modélisation de sujets matures disponibles, nous recherchons également des collaborateurs qui souhaitent contribuer dans les instructions suivantes:
La plupart des travaux sont terminés pour cette partie, nous devons toujours travailler:
Étendre la bibliothèque pour soutenir l'inférence variationnelle neurale suivant ce document ICML: inférence variationnelle neurale pour le traitement du texte
Étendre la formation pour soutenir l'apprentissage du renforcement suivant ce document ACL: modèle de sujet neuronal avec apprentissage par renforcement
Mit


