voicefixer_main
1.0.0
2021-11-06: Je viens de mettre à jour la structure du code pour le rendre plus facile à comprendre. Il peut avoir un bug potentiel maintenant. Je ferai une formation de test plus tard.
2021-11-01: Je mettrai à jour le code et je vais le faciliter l'utilisation plus tard.
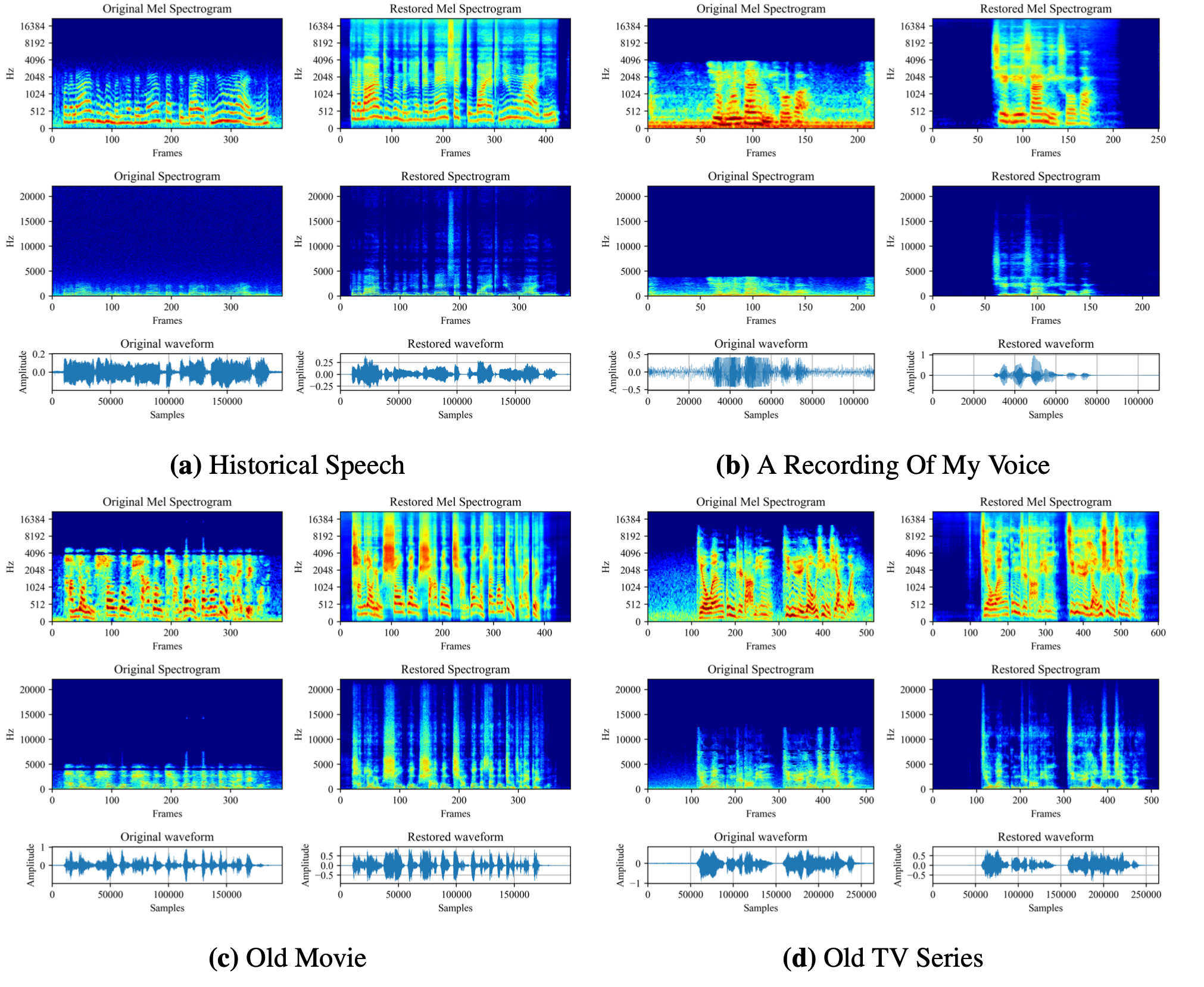
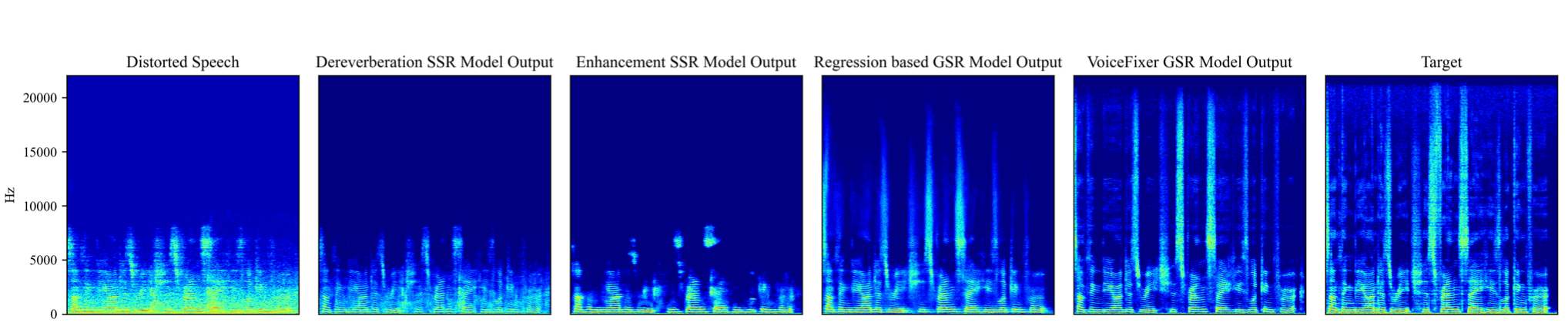
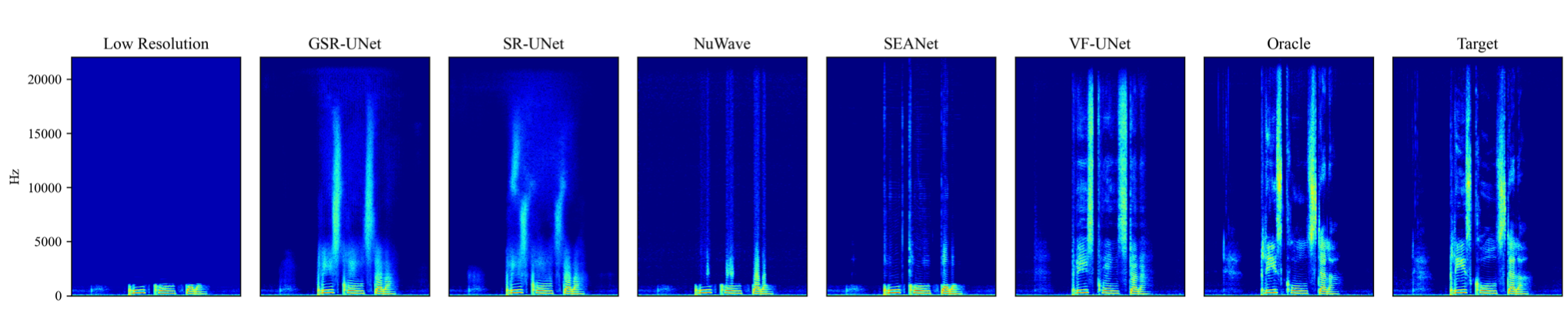
VoiceFixer est un cadre de restauration générale de la parole. Nous visons la restauration d'un discours gravement dégradé et d'un discours historique.
# Download dataset and prepare running environment
git clone https://github.com/haoheliu/voicefixer_main.git
cd voicefixer_main
source init.sh Ici, nous prenons VF_unet (VoiceFixer avec unet comme module d'analyse) comme exemple.
# pass in a configuration file to the training script
python3 train_gsr_voicefixer.py -c config/vctk_base_voicefixer_unet.json # you can modify the configuration file to personalize your trainingVous pouvez vérifier le répertoire des journaux pour les points de contrôle, les résultats de la journalisation et de la validation.
Évaluation automatique et génération de fichiers .csv sur tous les ensembles de tests.
Par exemple, si vous aimez évaluer tous les tests de test (par défaut).
python3 eval_gsr_voicefixer.py
--config < path-to-the-config-file >
--ckpt < path-to-the-checkpoint > Par exemple, si vous voulez juste évaluer sur le test GSR.
python3 eval_gsr_voicefixer.py
--config < path-to-the-config-file >
--ckpt < path-to-the-checkpoint >
--testset general_speech_restoration
--description general_speech_restoration_eval Il y a généralement sept ensembles de tests auxquels vous pouvez passer - TestSet :
Et si vous souhaitez évaluer sur une petite partie des données, par exemple 10 énoncé. Vous pouvez transmettre le numéro à - limit_numbers l'argument.
python3 eval_gsr_voicefixer.py
--config < path-to-the-config-file >
--ckpt < path-to-the-checkpoint >
--limit_numbers 10 Les résultats de l'évaluation seront présentés dans le dossier exp_results .
# pass in a configuration file to the training script
python3 train_gsr_voicefixer.py -c config/vctk_base_voicefixer_unet.jsonVous pouvez vérifier le répertoire des journaux pour les points de contrôle, les résultats de la journalisation et de la validation.
python3 eval_ssr_unet.py
--config < path-to-the-config-file >
--ckpt < path-to-the-checkpoint >
--limit_numbers < int-test-only-on-a-few-utterance >
--testset < the-testset-you-want-to-use >
--description < describe-this-test >Entraînement
# pass in a configuration file to the training script
python3 train_ssr_unet.py -c config/vctk_base_ssr_unet_denoising.json # pass in a configuration file to the training script
python3 train_ssr_unet.py -c config/vctk_base_ssr_unet_dereverberation.json # pass in a configuration file to the training script
python3 train_ssr_unet.py -c config/vctk_base_ssr_unet_super_resolution.json # pass in a configuration file to the training script
python3 train_ssr_unet.py -c config/vctk_base_ssr_unet_declipping.jsonVous pouvez vérifier le répertoire des journaux pour les points de contrôle, les résultats de la journalisation et de la validation.
python3 eval_ssr_unet.py
--config < path-to-the-config-file >
--ckpt < path-to-the-checkpoint >
--limit_numbers < int-test-only-on-a-few-utterance >
--testset < the-testset-you-want-to-use >
--description < describe-this-test > @misc { liu2021voicefixer ,
title = { VoiceFixer: Toward General Speech Restoration With Neural Vocoder } ,
author = { Haohe Liu and Qiuqiang Kong and Qiao Tian and Yan Zhao and DeLiang Wang and Chuanzeng Huang and Yuxuan Wang } ,
year = { 2021 } ,
eprint = { 2109.13731 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.SD }
}