VITS Pytorch
1.0.0
Chinois simplifié | Anglais
Ce projet est un projet de synthèse de la parole basé sur Pytorch, à l'aide de VITS. Les VITS (inférence variationnelle avec l'apprentissage adversaire pour le texte à la fin à la parole de bout en bout) est une méthode de synthèse de la parole. Ce modèle de bout en bout est très simple à utiliser et ne nécessite pas de processus trop complexes tels que l'alignement du texte. Il est directement formé et généré en un seul clic, ce qui réduit considérablement le seuil d'apprentissage.
Tout le monde est invité à scanner le code pour entrer la planète de connaissances ou le groupe QQ pour discuter. Knowledge Planet fournit des fichiers de modèle de projet et d'autres fichiers de modèles de projets liés des blogueurs, ainsi que d'autres ressources.
| Ensemble de données | Langue (dialecte) | Nombre de conférenciers | Nom de conférencier | Adresse de téléchargement |
|---|---|---|---|---|
| Bznsyp | mandarin | 1 | Voix féminine standard | Cliquez pour télécharger |
| Ensemble de données cantonais | Cantonais | 10 | Voix masculine 1 Filles 1 ··· | Cliquez pour télécharger |
conda install pytorch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 pytorch-cuda=11.6 -c pytorch -c nvidiaUtilisez PIP pour installer la commande comme suit:
python -m pip install mvits -U -i https://pypi.tuna.tsinghua.edu.cn/simpleIl est recommandé d'installer le code source , qui peut garantir l'utilisation du dernier code.
git clone https://github.com/yeyupiaoling/VITS-Pytorch.git
cd VITS-Pytorch/
pip install . Le projet prend en charge la génération directe des listes de données BZNSYP et Aishell3. Prenant l'exemple de BZNSYP, téléchargez BZNSYP dans le répertoire dataset et décompressez. Exécutez ensuite le programme create_list.py et générez une table de données dans le format suivant, le format est <音频路径>|<说话人名称>|<标注数据> . Notez que les données d'étiquetage nécessitent un langage d'étiquetage. Par exemple, en mandarin, vous devez envelopper le texte en [ZH] . D'autres langues soutiennent le japonais: [JA] , l'anglais: [en], 한국어: [KO]. Des ensembles de données personnalisés peuvent être générés dans ce format.
Le projet fournit deux méthodes de traitement de texte, différentes méthodes de traitement de texte et prend en charge différentes langues, à savoir cjke_cleaners2 et chinese_dialect_cleaners . Cette configuration est modifiée sur dataset_conf.text_cleaner . cjke_cleaners2 prend en charge les langues {"普通话": "[ZH]", "日本語": "[JA]", "English": "[EN]", "한국어": "[KO]"} , chinese_dialect_cleaners prend en charge les langues {"普通话": "[ZH]", "日本語": "[JA]", "English": "[EN]", "粤语": "[GD]", "上海话": "[SH]", "苏州话": "[SZ]", "无锡话": "[WX]", "常州话": "[CZ]", "杭州话": "[HZ]", ·····} , pour plus de langues, vous pouvez voir le code source linguistique_marks.
dataset/BZNSYP/Wave/000001.wav|标准女声|[ZH]卡尔普陪外孙玩滑梯。[ZH]
dataset/BZNSYP/Wave/000002.wav|标准女声|[ZH]假语村言别再拥抱我。[ZH]
dataset/BZNSYP/Wave/000003.wav|标准女声|[ZH]宝马配挂跛骡鞍,貂蝉怨枕董翁榻。[ZH]
Après avoir eu la liste des données, vous devez générer une liste de données Phonème. Exécutez simplement preprocess_data.py --train_data_list=dataset/bznsyp.txt pour générer une liste de données phonèmes. À ce stade, les données sont toutes prêtes.
dataset/BZNSYP/Wave/000001.wav|0|kʰa↓↑əɹ`↓↑pʰu↓↑ pʰeɪ↑ waɪ↓swən→ wan↑ xwa↑tʰi→.
dataset/BZNSYP/Wave/000002.wav|0|tʃ⁼ja↓↑ɥ↓↑ tsʰwən→jɛn↑p⁼iɛ↑ ts⁼aɪ↓ jʊŋ→p⁼ɑʊ↓ wo↓↑.
dataset/BZNSYP/Wave/000003.wav|0|p⁼ɑʊ↓↑ma↓↑ pʰeɪ↓k⁼wa↓ p⁼wo↓↑ lwo↑an→, t⁼iɑʊ→ts`ʰan↑ ɥæn↓ ts`⁼ən↓↑ t⁼ʊŋ↓↑ʊŋ→ tʰa↓.
Vous pouvez maintenant commencer à former le modèle. Les paramètres du fichier de configuration n'ont généralement pas besoin d'être modifiés. Le nombre de haut-parleurs et le nom du haut-parleur seront modifiés par preprocess_data.py . La seule chose qui peut devoir être modifiée est train.batch_size . Si la mémoire vidéo est insuffisante, ce paramètre peut être réduit.
# 单卡训练
CUDA_VISIBLE_DEVICES=0 python train.py
# 多卡训练
CUDA_VISIBLE_DEVICES=0,1 torchrun --standalone --nnodes=1 --nproc_per_node=2 train.pyJournal de sortie de la formation:
[2023-08-28 21:04:42.274452 INFO ] utils:print_arguments:123 - ----------- 额外配置参数 -----------
[2023-08-28 21:04:42.274540 INFO ] utils:print_arguments:125 - config: configs/config.yml
[2023-08-28 21:04:42.274580 INFO ] utils:print_arguments:125 - epochs: 10000
[2023-08-28 21:04:42.274658 INFO ] utils:print_arguments:125 - model_dir: models
[2023-08-28 21:04:42.274702 INFO ] utils:print_arguments:125 - pretrained_model: None
[2023-08-28 21:04:42.274746 INFO ] utils:print_arguments:125 - resume_model: None
[2023-08-28 21:04:42.274788 INFO ] utils:print_arguments:126 - ------------------------------------------------
[2023-08-28 21:04:42.727728 INFO ] utils:print_arguments:128 - ----------- 配置文件参数 -----------
[2023-08-28 21:04:42.727836 INFO ] utils:print_arguments:131 - dataset_conf:
[2023-08-28 21:04:42.727909 INFO ] utils:print_arguments:138 - add_blank: True
[2023-08-28 21:04:42.727975 INFO ] utils:print_arguments:138 - batch_size: 16
[2023-08-28 21:04:42.728037 INFO ] utils:print_arguments:138 - cleaned_text: True
[2023-08-28 21:04:42.728097 INFO ] utils:print_arguments:138 - eval_sum: 2
[2023-08-28 21:04:42.728157 INFO ] utils:print_arguments:138 - filter_length: 1024
[2023-08-28 21:04:42.728204 INFO ] utils:print_arguments:138 - hop_length: 256
[2023-08-28 21:04:42.728235 INFO ] utils:print_arguments:138 - max_wav_value: 32768.0
[2023-08-28 21:04:42.728266 INFO ] utils:print_arguments:138 - mel_fmax: None
[2023-08-28 21:04:42.728298 INFO ] utils:print_arguments:138 - mel_fmin: 0.0
[2023-08-28 21:04:42.728328 INFO ] utils:print_arguments:138 - n_mel_channels: 80
[2023-08-28 21:04:42.728359 INFO ] utils:print_arguments:138 - num_workers: 4
[2023-08-28 21:04:42.728388 INFO ] utils:print_arguments:138 - sampling_rate: 22050
[2023-08-28 21:04:42.728418 INFO ] utils:print_arguments:138 - speakers_file: dataset/speakers.json
[2023-08-28 21:04:42.728448 INFO ] utils:print_arguments:138 - text_cleaner: cjke_cleaners2
[2023-08-28 21:04:42.728483 INFO ] utils:print_arguments:138 - training_file: dataset/train.txt
[2023-08-28 21:04:42.728539 INFO ] utils:print_arguments:138 - validation_file: dataset/val.txt
[2023-08-28 21:04:42.728585 INFO ] utils:print_arguments:138 - win_length: 1024
[2023-08-28 21:04:42.728615 INFO ] utils:print_arguments:131 - model:
[2023-08-28 21:04:42.728648 INFO ] utils:print_arguments:138 - filter_channels: 768
[2023-08-28 21:04:42.728685 INFO ] utils:print_arguments:138 - gin_channels: 256
[2023-08-28 21:04:42.728717 INFO ] utils:print_arguments:138 - hidden_channels: 192
[2023-08-28 21:04:42.728747 INFO ] utils:print_arguments:138 - inter_channels: 192
[2023-08-28 21:04:42.728777 INFO ] utils:print_arguments:138 - kernel_size: 3
[2023-08-28 21:04:42.728808 INFO ] utils:print_arguments:138 - n_heads: 2
[2023-08-28 21:04:42.728839 INFO ] utils:print_arguments:138 - n_layers: 6
[2023-08-28 21:04:42.728870 INFO ] utils:print_arguments:138 - n_layers_q: 3
[2023-08-28 21:04:42.728902 INFO ] utils:print_arguments:138 - p_dropout: 0.1
[2023-08-28 21:04:42.728933 INFO ] utils:print_arguments:138 - resblock: 1
[2023-08-28 21:04:42.728965 INFO ] utils:print_arguments:138 - resblock_dilation_sizes: [[1, 3, 5], [1, 3, 5], [1, 3, 5]]
[2023-08-28 21:04:42.728997 INFO ] utils:print_arguments:138 - resblock_kernel_sizes: [3, 7, 11]
[2023-08-28 21:04:42.729027 INFO ] utils:print_arguments:138 - upsample_initial_channel: 512
[2023-08-28 21:04:42.729058 INFO ] utils:print_arguments:138 - upsample_kernel_sizes: [16, 16, 4, 4]
[2023-08-28 21:04:42.729089 INFO ] utils:print_arguments:138 - upsample_rates: [8, 8, 2, 2]
[2023-08-28 21:04:42.729119 INFO ] utils:print_arguments:138 - use_spectral_norm: False
[2023-08-28 21:04:42.729150 INFO ] utils:print_arguments:131 - optimizer_conf:
[2023-08-28 21:04:42.729184 INFO ] utils:print_arguments:138 - betas: [0.8, 0.99]
[2023-08-28 21:04:42.729217 INFO ] utils:print_arguments:138 - eps: 1e-09
[2023-08-28 21:04:42.729249 INFO ] utils:print_arguments:138 - learning_rate: 0.0002
[2023-08-28 21:04:42.729280 INFO ] utils:print_arguments:138 - optimizer: AdamW
[2023-08-28 21:04:42.729311 INFO ] utils:print_arguments:138 - scheduler: ExponentialLR
[2023-08-28 21:04:42.729341 INFO ] utils:print_arguments:134 - scheduler_args:
[2023-08-28 21:04:42.729373 INFO ] utils:print_arguments:136 - gamma: 0.999875
[2023-08-28 21:04:42.729404 INFO ] utils:print_arguments:131 - train_conf:
[2023-08-28 21:04:42.729437 INFO ] utils:print_arguments:138 - c_kl: 1.0
[2023-08-28 21:04:42.729467 INFO ] utils:print_arguments:138 - c_mel: 45
[2023-08-28 21:04:42.729498 INFO ] utils:print_arguments:138 - enable_amp: True
[2023-08-28 21:04:42.729530 INFO ] utils:print_arguments:138 - log_interval: 200
[2023-08-28 21:04:42.729561 INFO ] utils:print_arguments:138 - seed: 1234
[2023-08-28 21:04:42.729592 INFO ] utils:print_arguments:138 - segment_size: 8192
[2023-08-28 21:04:42.729622 INFO ] utils:print_arguments:141 - ------------------------------------------------
[2023-08-28 21:04:42.729971 INFO ] trainer:__init__:53 - [cjke_cleaners2]支持语言:['日本語', '普通话', 'English', '한국어', "Mix": ""]
[2023-08-28 21:04:42.795955 INFO ] trainer:__setup_dataloader:119 - 训练数据:9984
epoch [1/10000]: 100%|██████████| 619/619 [05:30<00:00, 1.88it/s]]
[2023-08-25 16:44:25.205557 INFO ] trainer:train:168 - ======================================================================
epoch [2/10000]: 100%|██████████| 619/619 [05:20<00:00, 1.93it/s]s]
[2023-08-25 16:49:54.372718 INFO ] trainer:train:168 - ======================================================================
epoch [3/10000]: 100%|██████████| 619/619 [05:19<00:00, 1.94it/s]
[2023-08-25 16:55:21.277194 INFO ] trainer:train:168 - ======================================================================
epoch [4/10000]: 100%|██████████| 619/619 [05:18<00:00, 1.94it/s]
Les journaux de formation seront également enregistrés à l'aide de VisualDL. Vous pouvez utiliser cet outil pour afficher les changements de perte et les effets de synthèse en temps réel. Exécutez simplement visualdl --logdir=log/ --host=0.0.0.0 dans le répertoire racine du projet et visitez http://<IP地址>:8040 pour ouvrir la page. L'effet est le suivant.
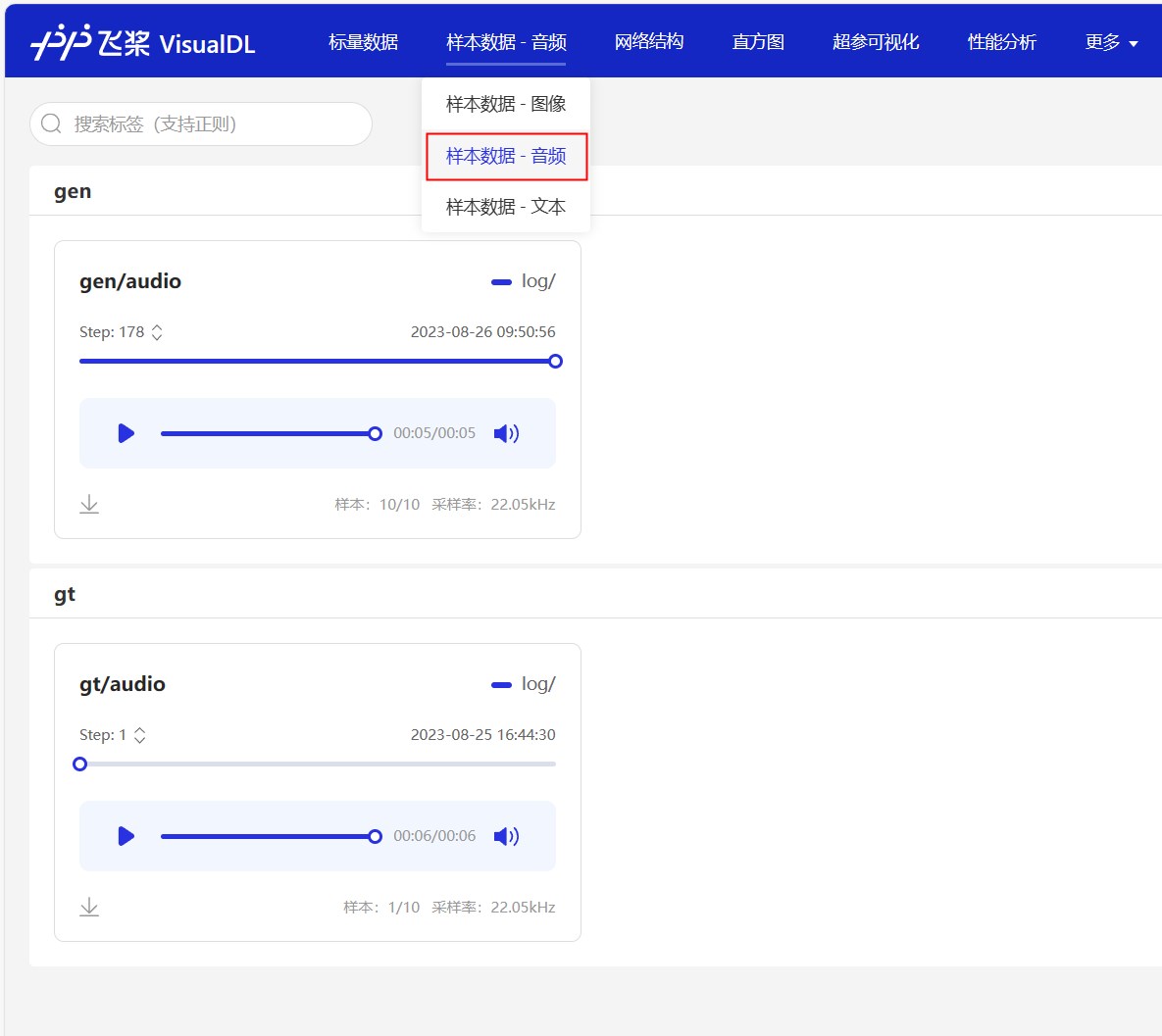
Après une formation à un certain niveau, vous pouvez commencer à utiliser le modèle de prononciation. La commande est la suivante. Il y a trois paramètres principaux, à savoir --text spécifie le texte qui doit être synthétisé. --language spécifie la langue du texte composite. Si la langue est spécifiée comme Mix , elle est en mode mixte. L'utilisateur doit envelopper manuellement le texte de revenu avec une étiquette linguistique. Enfin, spécifiez le paramètre du haut-parleur --spk . Allez et essayez rapidement.
python infer.py --text= "你好,我是智能语音助手。 " --language=普通话 --spk=标准女声Récompensez un dollar pour soutenir l'auteur


